 夜雨聆风
夜雨聆风每次都在重头学?给AI Coding Agent装上"记忆宫殿",效率翻倍
GitHub Trending 深度调研 · 2026年5月10日
AI Coding Agents

引言:每次都在重头学,你受够了吗?
你用过Claude Code、Cursor、Windsurf这些AI Coding Agent吗?如果用过,你一定有这个感受:每次开启新会话,Agent就像失忆了一样——你要重新解释项目架构、代码规范、已有的技术决策。MEMORY.md写了几百行,过两天再开Session,Agent又问同样的问题。
这不只是你的问题。这是所有AI Coding Agent的通病——它们天然是"无记忆"的。每一次对话,都是从零开始。
"Session 1你配置了JWT认证,Session 2你要求加限流,Agent已经知道:你的auth用的是src/middleware/auth.ts里的jose中间件,测试在test/auth.test.ts,你选jose而不是jsonwebtoken是因为Edge兼容。不需要重新解释,直接开始写代码。"
这就是agentmemory在解决的事情——给AI Coding Agent装上一个持久化的记忆系统,让跨会话知识复用成为现实。
— · —
01 为什么现有方案都治标不治本?
AI Coding Agent厂商当然知道这个问题。Claude Code有MEMORY.md,Cursor有notepads,Cline有memory bank——但这些方案都有一个根本缺陷:它们本质上是"粘贴式记忆"。

MEMORY.md的工作方式是:你在文件里写内容,Agent每次Session把文件内容全部加载进Context。听起来合理,但有三个致命问题:
问题一:200行上限。MEMORY.md超过200行就开始截断。实际项目中,240条观察记录之后,"最老的"观察记录就已经从200行cap里消失了。
问题二:全部塞进Context。每次检索就是把整个文件往Context里塞。240条观察≈22,610 tokens——绝大部分是噪音,信号密度极低。
问题三:跨Agent无效。Claude Code的MEMORY.md只能在Claude Code里用。你换了Cursor,记忆全丢了。
benchmark数据说得很清楚:
| 方案 | R@10 | Tokens/Query |
| MEMORY.md(200行cap) | 37.8% | 7,938 |
| 全量Context加载 | 55.8% | 22,610 |
| agentmemory(三路召回) | 58.0% | 3,142 |
agentmemory在R@10上领先built-in方案4%,同时Token消耗只有后者的14%。这不是微优化,这是量级差异。
— · —
02 agentmemory的核心设计

Graphviz
agentmemory的设计围绕三个核心层展开。
捕获层:12个Hooks,自动记录一切
Agentmemory通过12个生命周期Hook自动捕获每一次操作,不需要你手动调用任何API。SessionStart抓项目路径,UserPromptSubmit记录用户意图,PreToolUse/PostToolUse记录每一次工具调用及其结果,PostToolUseFailure记录错误上下文,SessionEnd做会话收尾……
"零手动操作"是agentmemory区别于Mem0等方案的关键。Mem0需要你在代码里显式调用add()来添加记忆,忘掉调就等于没记录。agentmemory完全不需要这种配合——它默默地挂在Agent的Hook上,你感觉不到它的存在,但它在后台记录一切。
存储层:四层记忆体系,模仿人类记忆
agentmemory构建了一个模仿人类记忆分层结构的存储体系:
Working Memory:原始观察记录,来自PostToolUse的每一次工具调用。未压缩,保留完整上下文。
Episodic Memory:会话摘要。Session结束时,Working Memory被LLM压缩成结构化摘要——"这个会话做了什么决策,有什么值得记住的结论"。
Semantic Memory:从多次会话中提取的跨会话事实和模式。"你总是用jose而不是jsonwebtoken"这类知识经过多会话验证后沉淀在这里。
Procedural Memory:工作流和决策模式。"先跑测试再合并"这类流程性知识在这里。
更重要的是,这套体系内置了记忆衰减机制——Ebbinghaus曲线。频繁访问的记忆会加强;长期不用的记忆会逐渐淡出;互相矛盾的记忆会被检测并解决。这不是简单的"时间戳+TTL",而是一套有认知科学依据的动态记忆管理。
检索层:三路召回,RRF融合
当Agent需要回忆知识时,agentmemory不是用单一检索方式,而是三路并进:
| 检索流 | 特点 | 适用场景 |
| BM25 | 关键词词干匹配+同义词扩展 | 精确文件名、函数名搜索 |
| Vector | all-MiniLM-L6-v2本地向量(无需API key) | 语义相似搜索("数据库性能问题"找到"N+1查询修复") |
| Knowledge Graph | 实体提取+BFS图谱遍历 | 实体关系推理("auth相关的所有决策") |
三路结果通过Reciprocal Rank Fusion(RRF,k=60)融合,最终输出与当前任务最相关的Top记忆。默认Token预算是2000 tokens,保证每次检索结果都精确注进Context。
— · —
03 技术架构详解
依赖:极简主义,自托管零成本
agentmemory的核心理念是"不要让基础设施成为负担"。它不需要Qdrant、Postgres、Pinecone这些外部向量数据库。运行时依赖只有:
• SQLite:本地持久化存储,无需任何服务器
• iii-engine:底层运行时引擎(预编译二进制,macOS/Linux/Windows均有)
• all-MiniLM-L6-v2:本地Embedding模型,完全免费,无API key需求
相比之下,Mem0需要Qdrant或pgvector,Letta需要Postgres + 向量扩展。agentmemory的把基础设施降到零——这也是为什么它的Token成本能压到$10/年的水平。
隐私:先过滤再存储,密钥不会进记忆
这一条很容易被忽视,但对实际使用至关重要。每次工具调用的输出里可能包含API密钥、数据库密码、Token——如果这些原始数据直接存进记忆,下次检索时就有泄露风险。
"隐私过滤器"是agentmemory存储管道的第一步,在任何数据写入SQLite之前执行。API密钥会剥离,带有<private>标签的内容会被过滤。存储的已经是"干净"的压缩记忆,而不是原始日志。
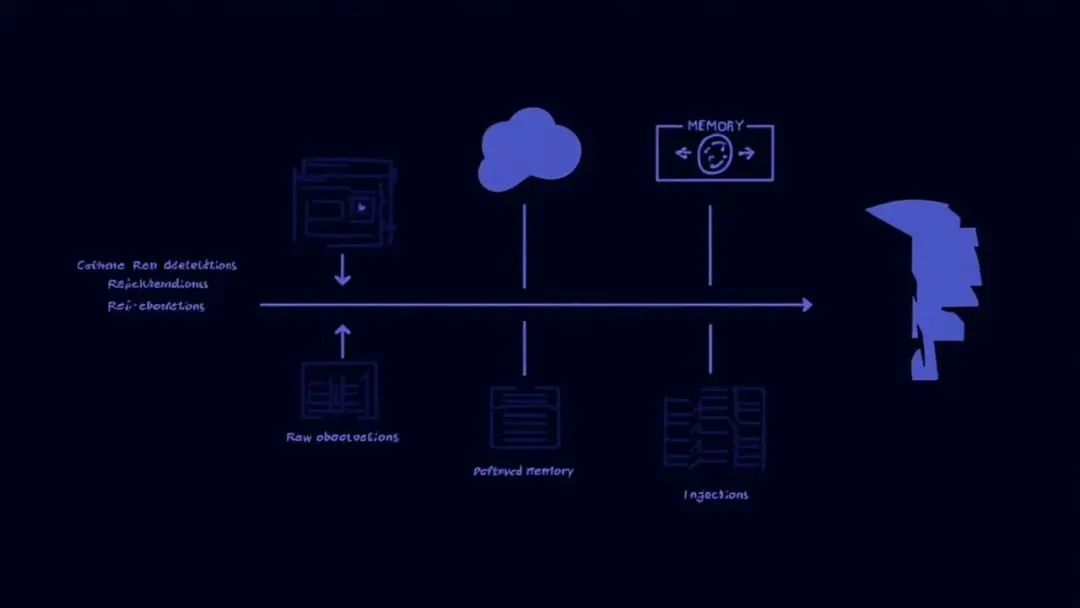
多Agent协调:MCP协议,真正的跨Agent记忆
这是agentmemory最核心的差异化能力。它通过MCP(Model Context Protocol)服务器将记忆系统暴露给任意AI Coding Agent——Claude Code、Cursor、Gemini CLI、Codex CLI、OpenCode、Cline、Goose……全部支持。
只要Agent支持MCP,就能连上agentmemory的记忆系统。更重要的是,所有Agent共享同一份记忆库——在Claude Code里学到的JWT配置,在Cursor里继续用,不需要重新配置。
— · —
04 性能数据:到底有多强?
在学术基准LongMemEval-S(ICLR 2025,500个问题)上,agentmemory表现如下:
| 系统 | R@5 | R@10 | MRR |
| agentmemory (BM25+Vector) | 95.2% | 98.6% | 88.2% |
| BM25-only fallback | 86.2% | 94.6% | 71.5% |
| Letta/MemGPT (LoCoMo) | — | 83.2% | — |
| Mem0 (LoCoMo) | — | 68.5% | — |
注意:Letta和Mem0的基准测试来自LoCoMo,不是LongMemEval-S,所以不能直接横向比较。agentmemory的README明确标注了这个"Apples vs oranges caveat",并主动邀请竞品维护者在同一数据集上对比——这种透明度值得点赞。
不过从数量级上看,agentmemory的95.2% R@5与MemPalace(~96.6%)处于同一档,显著领先LoCoMo基准上的Mem0(68.5%)。
Token成本对比
| 方案 | Tokens/年 | 成本/年 |
| 全量历史塞进Context | 19.5M+ | 不可能 |
| LLM summarization | ~650K | ~$500 |
| agentmemory(API embedding) | ~170K | ~$10 |
| agentmemory(本地embedding) | ~170K | $0 |
— · —
05 vs 竞品:谁更值得选?

GitHub Trending上有53K星的Mem0、22K星的Letta/MemGPT——这些是agentmemory最直接的竞品。选择逻辑其实很清晰:
选agentmemory:你用多个Coding Agent(Claude Code + Cursor混用),想要跨Agent共享记忆;你注重隐私(不想把代码/对话日志发到第三方云服务);你想零成本自托管;你想让记忆系统自动运行,不需要每次手动add()。
选Mem0:你有专门的机器学习/AI工程团队,可以维护Qdrant或pgvector;你想用云托管Dashboard;你的Agent已经有成熟的add()调用习惯,可以改造代码适配Mem0 API。
选Letta/MemGPT:你不只是想给Agent加记忆,你想构建一个有"记忆"的AI Agent运行时——可以运行长期对话、有内部状态管理的AI助手。这是完全不同的赛道,agentmemory解决的是"Agent的记忆问题",Letta解决的是"有记忆的Agent问题"。
| 特性 | agentmemory | Mem0 | Letta |
| 自动Hook捕获 | 12个Hook ✅ | ❌ 手动add() | ❌ |
| 零外部依赖 | SQLite ✅ | Qdrant/pgvector | Postgres |
| 本地Embedding | 免费 ✅ | 需API Key | 需配置 |
| 跨多Agent | MCP+REST ✅ | API调用 | Runtime内部 |
| 隐私过滤 | 内置 ✅ | ❌ | ❌ |
| 实时监控面板 | :3113 ✅ | 云Dashboard | 云Dashboard |
| 记忆衰减 | Ebbinghaus ✅ | ❌ | OS分层 |
— · —
06 实际使用:安装只要两行命令
agentmemory的安装极度简单。官方支持三种安装方式:
方式一:一条npx命令启动(推荐)
# 终端1:启动记忆服务器
npx @agentmemory/agentmemory
# 终端2:看效果(demo模式)
npx @agentmemory/agentmemory demo
# 打开实时监控面板
open http://localhost:3113
方式二:MCP集成(各Agent配置)
# Claude Code / Cursor / 通用MCP客户端
npm i @agentmemory/mcp
# 在MCP配置文件 (~/.cursor/mcp.json 等) 加入:
{
"mcpServers": {
"agentmemory": {
"command": "npx",
"args": ["-y", "@agentmemory/mcp"]
}
}
}
# Gemini CLI
gemini mcp add agentmemory npx -y @agentmemory/mcp --scope user
方式三:导入现有Claude Code历史记录
# 导入所有历史Session
npx @agentmemory/agentmemory import-jsonl
# 导入单个文件
npx @agentmemory/agentmemory import-jsonl ~/.claude/projects/my-project/abc123.jsonl
Windows用户需要注意:需要先安装iii-engine运行时(预编译二进制),不支持cargo install。文档里有详细的PowerShell安装指南和常见问题排查。
— · —
07 使用场景:什么样的项目最适合?
不是所有项目都值得上agentmemory。根据实际经验,以下几种场景收益最高:
✅ 推荐场景
• 长期迭代的项目(3个月以上,多个Session)
• 团队多人共用Coding Agent(记忆跨成员共享)
• 复杂的中间件/基础设施项目(auth、DB、缓存等决策多)
• 对代码隐私有高要求(不想用云端服务)
⚠️ 慎用场景
• 一次性脚本/短期项目(没时间积累记忆,收益不大)
• 高度动态的项目(每天大改,记忆反而造成干扰)
真实使用体验
根据官方文档的描述,典型使用体验是这样的:
"Session 1:告诉Agent'给API加上JWT认证'。Agent写代码、跑测试、修Bug。Session结束,agentmemory自动记录:你选择了jose中间件,测试覆盖token验证,你用jose而不是jsonwebtoken是因为Edge兼容性。Session 2:告诉Agent'现在加上限流'。Agent直接知道你的auth用的是src/middleware/auth.ts里的jose,不需要任何额外解释,直接开始写限流代码。"
这种体验的前提是:Agent经历了足够多的Session,记忆系统里有足够多的上下文。对于刚装上的项目,头几周的收益不会明显——这是一个需要时间沉淀的工具。
— · —
08 局限性:它不是银弹
作为一个客观的技术分析,必须说说agentmemory的局限性。
局限一:冷启动问题。刚装上的agentmemory没有历史记忆,前几个Session体验和普通Agent没有区别。价值需要3-5个Session才能逐步体现。如果你只做短期项目,永远都体验不到收益。
局限二:iii-engine版本锁定。当前agentmemory依赖iii-engine v0.11.2,与v0.11.6+不兼容(后者引入了sandbox-everything-via-iii worker新架构)。意味着如果不升级agentmemory底层,就无法用到新版本引擎的特性。
局限三:语义搜索有失败case。benchmark数据显示,在"数据库性能优化"这个语义查询上,R@10为0%——这说明当记忆里的表述与查询措辞差异太大时,向量检索会完全失效。RRF融合虽然能兜底,但也不能保证100%召回。
局限四:多Agent写入冲突。虽然支持多Agent共享记忆,但当两个Agent同时修改记忆时(比如同时在不同的Session里做架构决策),没有冲突解决机制。官方有leases和signals机制,但实际多Agent写入场景的一致性保障还是依赖使用者的设计。
— · —
09 总结:值得尝试,但预期要合理
agentmemory解决的是一个真实存在的问题:AI Coding Agent的"失忆症"。它的方案——四层记忆体系、三路召回、MCP跨Agent共享、隐私过滤——每一项都是针对实际痛点的工程解决方案,而不是学术论文的概念实现。
数据也很扎实:LongMemEval-S上95.2% R@5,Token消耗只有$10/年,本地Embedding零成本,实时监控面板。这些数字不是PPT里吹出来的——benchmark代码、测试数据集、对比方法全部开源在GitHub里,任何人都可以复现。
但同时也要看到它的局限性:冷启动需要时间、版本锁定有技术债、语义搜索有失败case、多Agent写入缺乏冲突解决。这些问题不致命,但在生产级使用中需要设计好配套机制。
记忆不是为了记住,是为了不再重复。
项目信息
GitHub:github.com/rohitg00/agentmemory
Stars: 3,374 · TypeScript · MIT License
支持:Claude Code, Cursor, Gemini CLI, Codex, OpenCode, Cline, Goose, Windsurf等
— END —
