 夜雨聆风
夜雨聆风AI 算力又成硬通货:为什么模型越便宜,算力反而越贵?
过去一年,大模型行业出现了一个很反直觉的现象。
一边,模型调用价格不断下降。DeepSeek 之后,国内外模型厂商都在用更便宜的 API、更长的上下文、更低的推理单价争夺开发者。
另一边,算力反而越来越像硬通货。微软、Meta、Google、亚马逊继续把大量资本开支砸向 AI 数据中心、GPU、网络、电力和服务器。国内也在把算力、数据、能源、电网放进同一张基础设施图里。
表面上看,这两件事互相矛盾:既然模型越来越便宜,为什么算力还越来越贵?
真正的答案是:模型降价不是在减少算力需求,而是在制造更大的算力需求。
就像高速公路降费不会让车变少,反而会让更多人开车;电价下降不会让用电消失,反而会催生更多电器和工厂。AI 推理成本下降之后,更多应用、更多用户、更多场景会开始调用模型。
最后被消耗掉的,还是算力。
所以这轮 AI 价格战真正改变的,不是“算力不值钱了”,而是“算力会以更高频、更分散、更日常的方式被消耗”。
这也是为什么 AI 行业更硬的资产,正在从模型 API 本身,转向数据中心、芯片、网络、电力和调度能力。
大厂财报已经说明问题:AI 不是省钱项目,是资本开支项目

如果只看模型 API 价格,你会以为大模型行业正在变便宜。
但如果看大厂财报,你会得到完全不同的结论:AI 仍然是全球科技公司投入很重的基础设施竞赛。
微软在 2026 财年第三季度财报中继续强调云和 AI 需求,资本开支主要投向云和 AI 基础设施。Alphabet 在 2026 年一季度继续把资本开支重点放在技术基础设施,特别是服务器和数据中心。Meta 在 2026 年一季度财报中也明确上调全年资本开支预期,理由包括 AI 基础设施投资。亚马逊则在 AWS 和 AI 基础设施上维持高强度投入。
这些公司不是不知道模型价格在下降。
它们仍然继续投入,是因为它们看到的不是“单次调用单价”,而是“未来调用总量”。
AI 的商业逻辑和传统软件不同。
传统软件多一个用户,边际成本可能很低。一个 SaaS 工具写好之后,用户多用几次,平台成本未必线性上升。
但 AI 不一样。
用户每发起一次复杂推理,每生成一张图,每分析一份长文档,每调用一个多步骤 Agent,背后都会消耗 GPU、内存、带宽、电力和冷却资源。
也就是说,AI 产品不是只卖软件,而是在卖持续燃烧的计算。
这就是资本开支持续抬升的底层原因:模型能力越强,应用场景越多,调用越高频,基础设施越吃紧。
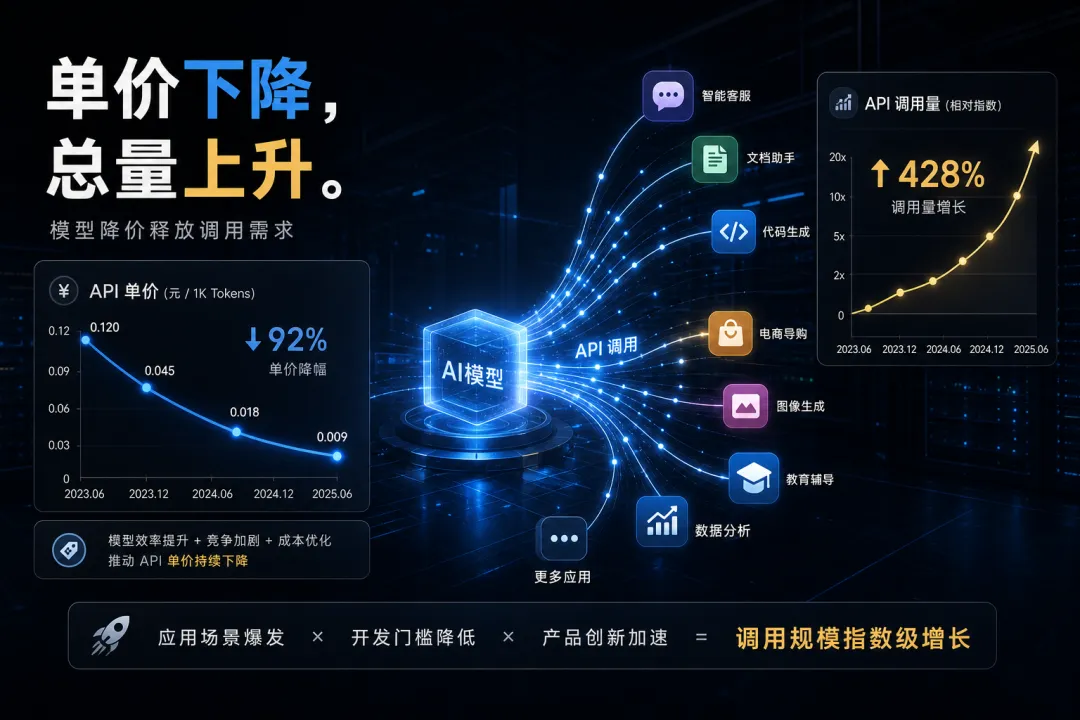
模型降价,不是需求减少,而是需求释放
很多人理解价格战时,会用一个过于简单的逻辑:
价格下降,说明供给过剩,行业要不行了。
放在 AI 里,这个判断只对了一半。
模型调用降价,确实说明基础模型能力正在商品化。过去只有少数大厂能调用高性能模型,现在中小开发者、企业团队、个人创作者都能用上。
但价格下降也会释放新需求。
原来一次调用太贵,很多产品不敢接入 AI。客服系统只敢在少数场景用,办公软件只敢给会员开放,教育产品只敢做演示,内容工具只敢限制次数。
当推理成本下降之后,产品经理会做出完全不同的决策:
这就是所谓的“杰文斯悖论”:单次资源使用效率提升,反而可能带来总消耗上升。
AI 算力正在经历类似过程。
模型变便宜,不是让大家少用模型,而是让更多产品敢把模型嵌进流程里。单次调用成本下降之后,总调用次数可能以更快速度上升。
这也是为什么“模型越便宜,算力越贵”并不矛盾。
便宜的是单位 Token。
变贵的是总需求、峰值需求和优质算力的获取能力。
中国市场更明显:AI 应用真正开始吃算力

国内这轮 AI 算力需求,不只是大厂训练模型。
更关键的是,AI 应用开始从演示走向真实使用。
国家数据局 2026 年 5 月 8 日披露,截至 2026 年 3 月底,我国日均 Token 调用量已突破 140 万亿,较 2025 年初增长超过 65 倍。
这个数字非常关键。
因为它说明中国 AI 需求正在从“模型发布会”变成“真实调用量”。
过去讨论大模型,大家关注的是参数、榜单、开源、训练成本。
现在更该关注的是:每天到底有多少企业系统、办公软件、搜索产品、智能客服、营销工具、教育产品、代码工具在调用模型。
当 Token 调用量以几十倍增长,算力需求就不会只停留在训练端。
训练端需要大规模 GPU 集群。
推理端需要持续、低延迟、稳定、分布式的算力网络。
这两者不是一回事。
训练像建厂,一次投入巨大。
推理像供水供电,每天都要稳定供应。
中国市场的问题恰恰在这里:应用场景太多,用户规模太大,价格敏感度又很高。一旦 AI 真正进入办公、教育、客服、电商、营销、制造和政务,算力消耗不会是线性的,而可能是阶梯式上升。
真正稀缺的不是“会不会有模型”,而是谁能稳定供算力

2023 年,行业争论谁有大模型。
2024 年,行业争论谁的模型更强。
2025 年之后,问题开始变成:谁能把模型稳定、便宜、低延迟地供给真实业务?
这时候,竞争对象就变了。
不是只有模型参数。
还包括 GPU 供应、数据中心选址、电力成本、液冷能力、网络互联、推理调度、缓存优化、模型压缩、并发管理、故障恢复。
一个企业客户不会只问“你的模型榜单第几”。
它还会问:
这些问题,最终都会落到算力基础设施。
所以大模型越往产业里走,算力越不像一个后台资源,而越像水电煤一样的基础能力。
区别在于,水电煤的需求曲线相对成熟,而 AI 算力需求还处在早期爆发阶段。
这就是为什么优质算力会变成硬通货。
不是因为大家不知道模型在降价,而是因为所有人都知道:便宜模型会让更多人开始用模型。
价格战会打掉谁?
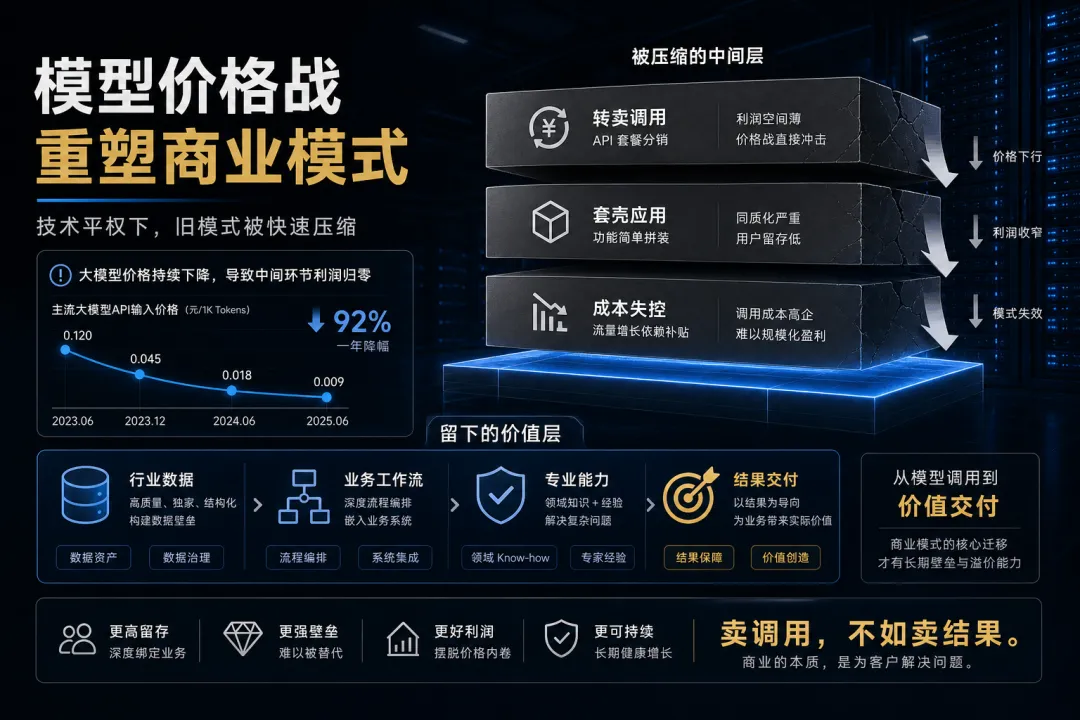
模型 API 降价,对用户和开发者当然是好事。
但它会迅速打掉一批商业模式。
首先被打掉的是“转卖模型调用”的中间商。
如果一家公司只是把别人的模型包一层 UI,再加价卖给用户,它的空间会越来越窄。模型原厂降价,云平台降价,开源模型进步,都会压缩它的利润。
其次被打掉的是“只会讲模型能力”的创业公司。
当基础模型能力越来越接近,单纯说自己接入了某个大模型,已经很难构成壁垒。
真正有价值的是行业数据、工作流、交付结果和分发入口。
再次被打掉的是“没有成本控制能力”的 AI 应用。
很多 AI 应用早期靠免费增长,用户看起来很多,但每个用户都在消耗推理成本。如果付费率上不来、广告转化不成立、企业客户不愿买单,用户越多,亏损越大。
这类产品最容易出现一个尴尬局面:
不开放能力,用户觉得没价值。
开放能力,成本扛不住。
后续能留下来的,不一定是模型极为强大的公司,而是能同时控制算力成本、产品体验和商业化效率的公司。
算力贵,不等于所有算力公司都赚钱

这里要泼一盆冷水。
算力变成硬通货,不等于买几张 GPU、建个机房就能稳赚。
AI 算力是一个高门槛、重资产、强周期行业。
它至少有四个风险。
其一,芯片迭代太快。
今天昂贵的 GPU,几年后可能被新一代芯片、专用推理芯片或国产替代方案压低价值。
其二,客户需求不稳定。
训练需求和推理需求不同,短期租赁和长期合同不同。如果没有稳定客户,算力资产很容易出现利用率不足。
其三,电力和散热是真成本。
数据中心不是把服务器堆起来就完事。电力指标、机房选址、冷却系统、网络互联、运维能力都会决定真实成本。
其四,模型效率也在提升。
蒸馏、小模型、混合专家、缓存、量化、端侧推理都会降低部分计算压力。不是所有任务都需要高价 GPU。
所以真正值得关注的,不是“谁说自己有算力”,而是谁能把算力变成高利用率、低故障率、可持续交付的服务。
算力是硬通货,但不是无脑印钞机。
对普通人来说,这件事意味着什么?
这件事不只是投资人和云厂商的事。
它会影响每个普通 AI 用户。
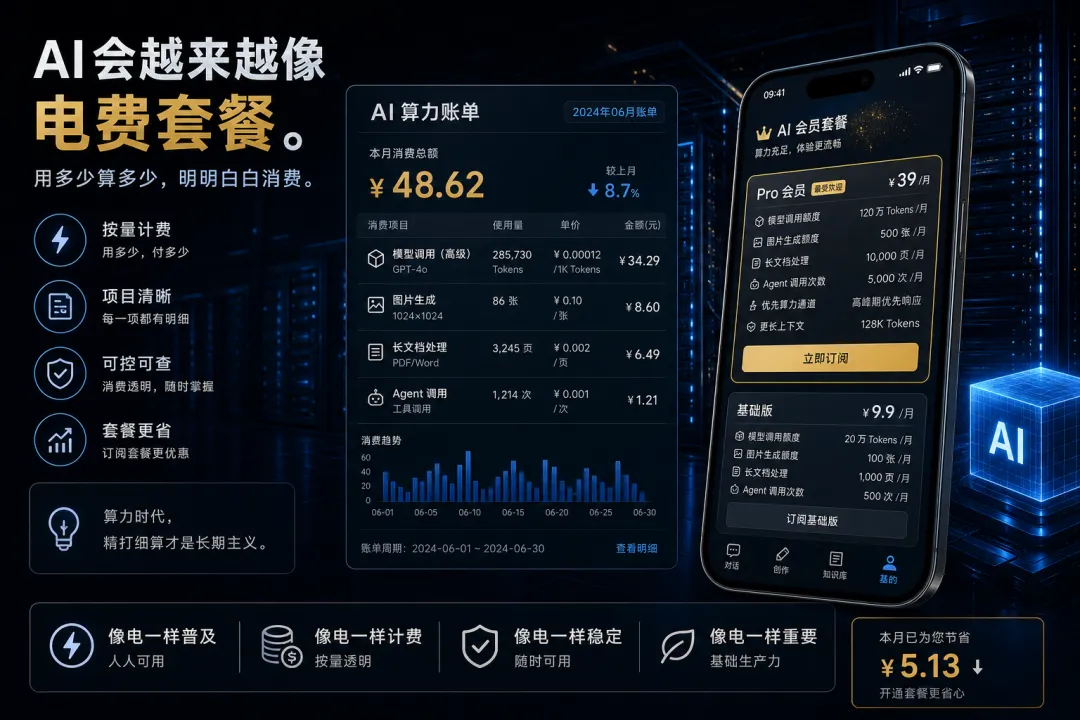
其一,AI 免费额度会越来越精细。
平台不会永远无差别补贴高成本能力。未来免费版、会员版、专业版、企业版会分得更清楚。你用的是普通模型还是高性能模型,能不能生成图片,能不能处理长文档,能不能跑 Agent,都会被明确标价。
第二,AI 产品会越来越像电费套餐。
你付的不是一个抽象会员,而是调用量、速度、模型等级、上下文长度、图片生成次数、文件处理额度。
第三,真正好用的 AI 会越来越嵌入工作流。
不是让你打开一个聊天框,而是在文档、表格、浏览器、客服系统、CRM、ERP、设计工具里自动调用。你未必感知到模型,但你会持续消耗算力。
第四,内容创作者和企业会更依赖“算力预算”。
过去做内容主要算人工和流量成本。未来批量生成图片、视频、脚本、检索、翻译、剪辑,都要算 AI 调用成本。
谁能用更低成本拿到更稳定的 AI 能力,谁的生产效率就更高。
结尾:模型会越来越便宜,但算力不会消失
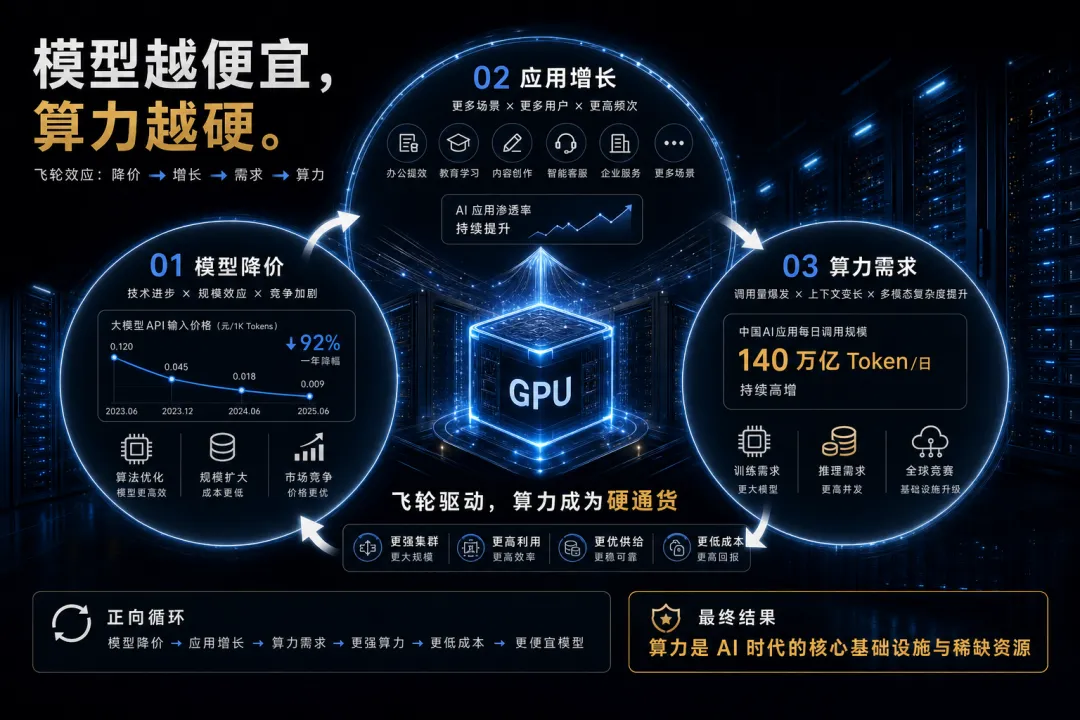
大模型价格战会继续。
API 会继续降价,开源模型会继续追赶,小模型会更强,端侧 AI 会分走一部分需求。
但这不意味着算力不重要。
恰恰相反。
当 AI 变便宜,AI 才会真正变普及。
当 AI 变普及,算力才会真正变成基础设施。
这一轮竞争的本质,不是模型公司谁先把价格打下来,而是谁能在低价时代仍然稳定供给高质量计算。
模型越便宜,应用越多。
应用越多,调用越多。
调用越多,算力越硬。
这就是 AI 行业接下来几年很可能出现的真实逻辑。
不是模型不值钱了。
而是模型正在把算力变成更大的生意。
