 夜雨聆风
夜雨聆风
实用指数:⭐⭐⭐
这是一个基本功话题,老实说,是否了解评测体系并不影响你日常使用大模型,它的价值更多是让我们这些想深度了解 AI 的普通人,能够与专业人士对齐认知,在同一套话语体系下,逐步建立对模型能力和发展趋势的深度理解。
建议转发此文到文件传输助手,以便看到模型评分时随时对比查阅。

一个最合适的认知切入点:DeepSeek V4 Pro
五一前大家可能都关注到 DeepSeek 提到 V4-Pro 已达到当前开源模型最佳水平,并且附了 2 张图来支持这个结论。
DeepSeek 官方解读:"世界知识测评中,大幅领先其他开源模型,仅稍逊于顶尖闭源模型 Gemini-Pro-3.1。Agentic Coding 评测中,V4-Pro 已达到当前开源模型最佳水平,并在其他 Agent 相关评测中同样表现优异。"
图 1:核心指标对比国外顶尖模型
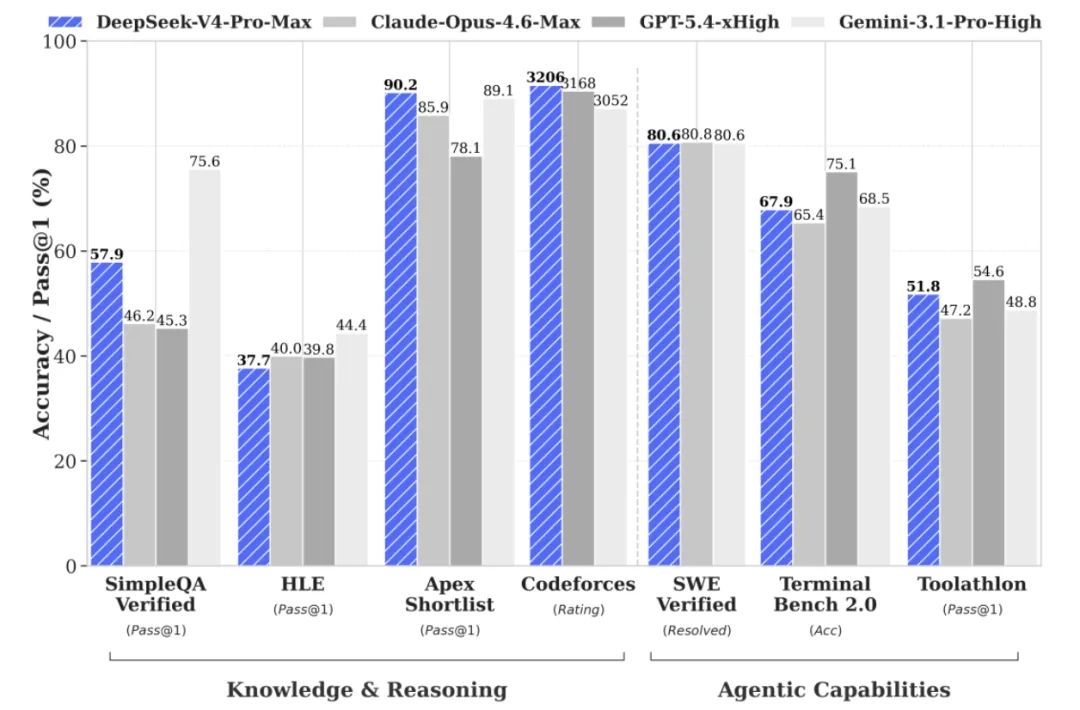
图 2:详细版——较图1指标更完整、增加国内模型(蓝框是DeepSeek 得分更高的指标)
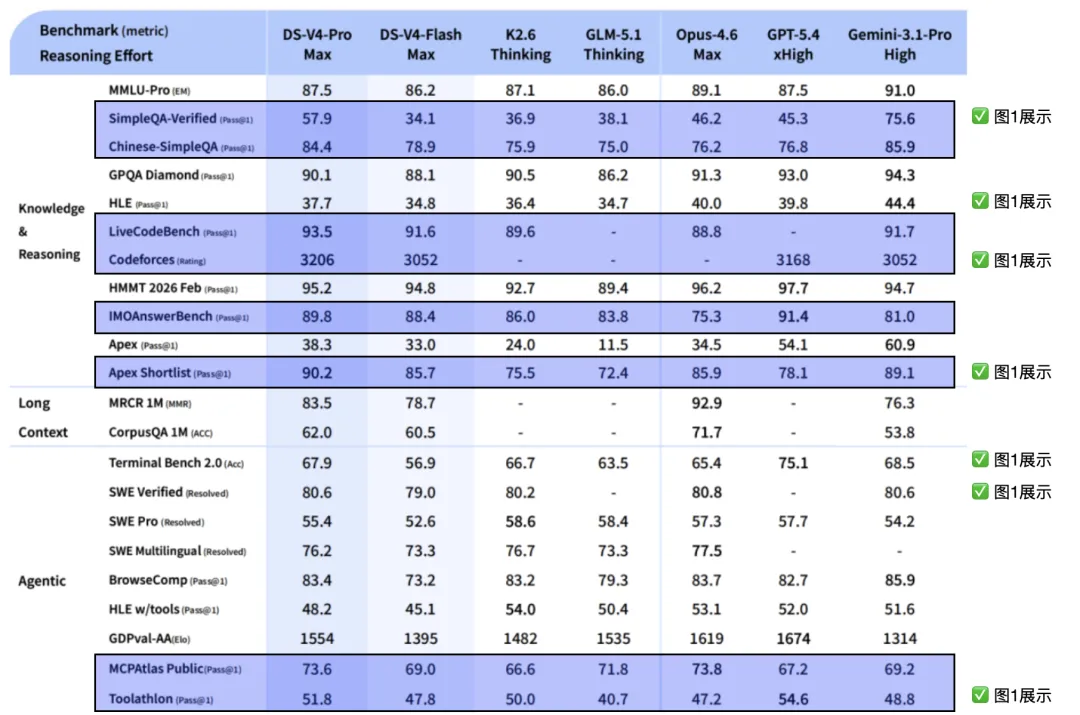
我们正好可以从这些指标来切入理解大模型评测。
相信大家可以读完下文后,完全可以自己总结 DeepSeek 表现,例如:
Deepseek 在哪些方面显著优于顶尖模型,哪些方面不如顶尖模型,相比国内模型,DeepSeek 又强在哪里,弱在哪里。

DeepSeek 评分解读
图 1 和图 2 对比可以发现,DeepSeek 并没有专挑得分高的指标来展示,而是把 HLE、Terminal Bench、SWE Verified 等自己不占优的项目也列了出来。这说明这些指标在行业内被认为非常重要,属于必看指标。
1. 首先,解释大框架,3 个部分:
- Knowledge & Reasoning(知识与推理):测的是模型的"硬知识"和"推理能力"。
- Long Context(长上 下文):测的是模型处理长文档、长对话的能力。
- Agentic(智能体能力):测的是模型能不能像"智能体"一样自主规划、调用工具、完成任务。
2. 具体指标:
第一类:Knowledge & Reasoning:3 类指标,1是测百科全书式的知识储备,2是数理化等深度推理能力,3是写代码能力
世界知识类: MMLU-Pro:57 个学科的选择题,Pro 版难度更高。这是行业"必考",测综合知识储备。(MMLU=Massive Multitask Language Understanding) SimpleQA-Verified:事实性问答,答案经过人工核验。测模型会不会"一本正经地胡说八道"。 Chinese-SimpleQA:中文版事实性问答。测中文场景下的准确性。 推理类: GPQA Diamond:研究生级别的专业问题(生物、物理、化学)。难度极高,人类专家也只有 70% 多正确率,测深度推理能力。(GPQA=Graduate-Level Google-Proof Q&A) - HLE:"人类终极大考",专家出的超难题。测模型的极限推理能力。(HLE=Humanity's Last Exam)
Apex:高难度综合问答。分数普遍偏低,测极限推理能力。 Apex Shortlist:Apex 中精选的最难题。测"最难的题"上的表现。 代码类: LiveCodeBench:实时更新的代码生成测试。测编程能力,且题目会更新,防"刷题"。 Codeforces Rating:编程竞赛平台的 Elo 评分。测真实竞技编程水平。AI 编程能力超过人类选手——人类新手 1500,高手 2000+,顶尖 2400+。 数学类: HMMT 2026 Feb:哈佛 - 麻省理工数学竞赛题。测竞赛级数学能力。(HMMT=Harvard-MIT Mathematics Tournament) IMOAnswerBench:国际数学奥林匹克题。测顶级数学推理。
第二类:Long Context(长上下文):2 个指标,百万 token 检索、答题能力
MRCR 1M:在 100 万 token 中检索信息,测"大海捞针"能力——看能不能从超长文档中找到关键信息。(MRCR=Memory-Recall with Contextual Retrieval) CorpusQA 1M:基于 100 万 token 语料回答问题,更真实的长文档问答场景。
第三类:Agentic(智能体能力):包含2类。1是"干活能力"——命令行操作、浏览器交互、MCP 工具调用、自动化任务执行。2是"视觉理解"——看懂图、评估设计。
干活能力: Terminal Bench 2.0:命令行操作能力,测模型懂不懂 Linux 命令。 SWE Verified:真实 GitHub issue 修复能力,测"像程序员一样修 bug"。(SWE=Software Engineering) SWE Pro:SWE 的进阶版,更难的任务,测更复杂的代码修复能力。 SWE Multilingual:多语言版本代码修复,测不同编程语言下的表现。 BrowseComp:浏览器/网页浏览任务,测模型操作浏览器的能力。 MCPAtlas Public:通过 MCP 协议调用工具的能力,测能不能像"AI 员工"一样使用各种工具。 Toolathlon:多步骤工具调用和任务执行,测能不能完成复杂的自动化任务。 辅助推理 HLE w/tools:HLE 加上允许使用工具,测"有工具辅助时的推理能力"。 GDPval-AA:图形设计/视觉评估,测视觉理解和设计能力(核心是看懂图,而非生图)。
3. 补充说明括号内后缀的判分规则,最常见的是 Pass@1、Acc、EM:
Pass@1:模型第一次回答就正确的比例。最贴近真实使用场景——你问一个问题,它答一次,对了就是对了。 Acc:准确率。答对的题目占总题目的比例。 EM:精确匹配。答案必须和标准答案一模一样才算对,连标点符号都不能差。 MMR:平均互排名。用来衡量模型在长文档中检索信息的准确度,分数越高越能精准定位。 Resolved:已解决。在 SWE-bench 这类代码修复测试中,代表模型成功修复 bug 的比例。 Elo:国际象棋用的排名算法。通过对战结果计算相对分数,分数越高则越强。

FAQ
1. 为什么 HLE、Terminal Bench、SWE Verified 指标值得重点关注
HLE:因为分数普遍偏低(30-45 分),区分度很高,能拿高分的模型说明真有"硬实力"。 Terminal Bench 2.0:因为它测的是"能不能干活",不是选择题,而是真实执行命令。 SWE Verified:行业公认的代码能力试金石,Claude 和 DeepSeek 在这个指标上长期缠斗。
2. SimpleQA-Verified 事实性问答,得分为何只有 50 左右?
这里 Simple 并非问题简单,而是简短、明确、单一答案的意思。其题库是极小众、特定资料里才有的"长尾知识",比如它会问"哥伦比亚某小镇是哪年成立的";其次 AI 的本质是统计概率,死记硬背并非其强项。因此 50 分左右已经是顶尖水平,人类在没有工具辅助的情况下,很难达到这个水平。
3. 会靠刷题拿高分吗?
是的,这些评测分数有一个潜在问题——数据污染。如果模型的训练数据中包含了评测集的题目或近似内容,分数就会"虚高"。这也是为什么 LiveCodeBench 强调"实时更新"、SimpleQA 强调"Verified"的原因——防刷题。目前行业正在推动"动态基准"和"不可见测试集"来解决这个问题

至此,可以总结一下对 DeepSeek 的指标判断:
相比国外模型,DeepSeek 的中文和代码能力已经做到全球最强(Codeforces 3206分登顶、Chinese-SimpleQA 84.4分第一)。短板非常集中——极限推理(HLE 37.7 vs Gemini 44.4;Apex 38.3 vs GPT 54.1),差距约6-16个百分点。整体上与 Claude 和 GPT 互有胜负,属于同一梯队。
相比国内模型,DeepSeek 几乎在所有维度上全面碾压 Kimi 和智谱,代表了中国大模型的天花板。需要注意的是,在有工具辅助的推理任务上,Kimi K2.6(54.0)反而略高于 DeepSeek(48.2)——这反映的是工具调用能力的差异,而非纯模型能力的排序。
总结:一个编程和中文能力全球顶尖、但深度研究推理需要加强的模型。如果你用它写代码、处理中文任务,它是目前最好的选择之一;如果你用它做需要极高事实准确性的问答(比如医疗、法律)和深度研究,需要谨慎验证。

聊完案例看整体,AI 模型的评测体系什么样?
1. 大框架并无通用分类
首先要搞清楚一件事:DeepSeek 那张图里的"Knowledge & Reasoning、Long Context、Agentic"三个维度,并不是行业通用的标准分类。
这只是 DeepSeek 自己发布时选择的组织方式。不同的厂商、不同的评测机构,有各自的分类习惯。
为什么会这样?因为大模型评测这件事本身就还在"演化"中。一个模型能做的事情太多了——写诗、写代码、做数学题、修 bug、操作浏览器、调用 API……很难用一个固定的框架把所有能力装进去。
目前行业内比较常见的分类方法有几种:
第一种:按"能力类型"分(这是最常用的)
知识与推理:考记忆和逻辑 代码与工程:考写程序和修 bug 长上下文:考处理大段文档 多模态:考看图、听声音 对齐与安全:考有没有毒、会不会胡说
DeepSeek 的分类本质上就是这种思路的变体,只是他们把"代码"揉进了"知识与推理"里,把"Agent"单独拎了出来。
第二种:按"场景"分
日常对话:用户偏好、多轮交互 专业任务:编程、数学、法律、医疗 自动化任务:工具调用、Agent 工作流
这种分类更贴近"我会拿它来干什么"。
第三种:官方标准框架(信通院/国标)
国标 GB/T 45288.2-2025 提出的"五横一纵"更偏产业落地,包括模型开发、模型能力、模型应用、可信要求、模型运营五个横向维度,以及贯穿始终的评测流程。这个框架主要用于政府采购和产业评估,普通用户接触不多。
所以结论是:没有"必须按哪几个维度来测"的规定。当你看到一张评测表时,先看它列了哪些指标,而不是纠结它分了几个类。分类只是排版方式,指标才是真东西。

2. 核心指标
如果你想快速判断一个模型好不好用,不需要记所有指标。按你的需求对号入座就行:
想知道综合体验 → 看 Chatbot Arena Elo(用户投票排名,最贴近真实感受) 想知道会不会胡说 → 看 SimpleQA-Verified(事实性准确率)和 TruthfulQA 想知道能不能写代码 → 看 SWE-Verified(修真实 bug)和 Codeforces Rating(竞赛水平) 想知道能不能干活 → 看 Terminal Bench 2.0(命令行操作)和 Toolathlon(工具调用) 想知道能不能处理长文档 → 看 MRCR 1M(百万 token 检索) 想知道安不安全 → 看 ToxiGen(有害内容率) 想知道能不能看懂图 → 看 MMMU(多学科多模态理解)、MMMU-Pro(更难版)、MathVista(图表数学推理) 想知道能不能生成图 → 目前没有统一标准,主要看第三方盲测(如 Hugging Face 的 text-to-image leaderboard)
评测基准有很多,这里只列最常见的。想了解完整清单,可以去 Papers with Code 或各平台查看。
想查具体模型的跑分,去 LMSYS Chatbot Arena 看相对排名,去各模型官方技术报告看详细指标。

3. 谁来评测
搞懂"测什么"之后,下一个问题是:这些分数是谁打出来的?不同的评测机构,权威性和侧重点完全不同。
目前行业内最常被引用的评测来源,可以分为三类:
国际权威榜单
LMSYS Chatbot Arena(引用率第一,已成行业标配)
这是目前被引用次数最多的评测平台,没有之一。起源于 UC 伯克利,通过"匿名对战、用户投票、Elo 评分"的方式,让真实用户决定哪个模型更好用。GPT-5.4、Claude 4.5、Gemini 3.0 发布时,几乎都引用了 Arena 排名。它被行业称为"AI 模型的奥运会"——考的不是刷题能力,而是"用户喜不喜欢"。
Stanford HAI(权威第三方审计)
斯坦福每年发布的《AI Index Report》,是学术界最全面的第三方评估。不偏向任何厂商,追踪技术能力、投资、就业、公众认知。厂商在强调"行业趋势"或"中美对比"时,常引用这份报告的数据。
Hugging Face Open LLM Leaderboard
开源模型界的"必争之地"。主要针对 Llama、Qwen 等开源模型做自动化评测,是开发者选择模型的重要参考。
国内官方与学术机构
信通院"方升"基准测试(中国国家标准)
在中国市场,信通院的评测结果是厂商必须拿下的"认证"。基于国家标准 GB/T 45288.2-2025,数据集规模 780 万条,已完成超 1100 次测试。阿里、百度、腾讯、华为等国内厂商发布时,几乎都会提及"通过信通院评测"。
OpenCompass(司南)
上海人工智能实验室发布,国内最权威的开源评测体系,覆盖中英文双语、代码、数学等多个维度。国内厂商最常引用"司南"来证明其中文能力的领先。
SuperCLUE & C-Eval
专门针对中文语境的测评体系。C-Eval 由清华等高校建立,涵盖 52 个学科,是衡量中文知识储备的常用基准。
你需要注意的"引用套路"
厂商在引用评测结果时,往往会"选择性展示":
只挑得分高的说:一个模型可能在代码测试中拿了第一,在数学测试中拿了第五,那发布会 PPT 上大概率只会有代码测试的截图 "跑分"与"体感"的错位:Arena 虽然最贴近真人体验,但它测的是"偏好",而不是"绝对正确"。有抽查发现,52% 的获胜回答其实包含事实错误
所以当你看到"跑分超越 GPT-4"时,可以留意一下引用的具体是哪个机构的榜单。如果是 LMSYS Chatbot Arena 或 SWE-bench 这类公认的硬核测试,说明这个"超越"确实有点分量;如果是某个没听过的自定义测试,大概率是精心挑选的"田忌赛马"。

最后
本文介绍的MMLU、GPQA、SWE-bench等是评测领域的“常青树”,是理解AI能力的基准线。
随着技术发展,评测界也在不断推出新的“考卷”。例如,为了测试更复杂的智能体(Agent) 能力,研究者们设计了τ³-bench;为了评估模型的深度搜索能力,又催生了Search Arena榜单。这些新指标同样是理解顶尖模型的关键视角。
由于篇幅关系,这次聊的是"软跑分"(评测指标),下次再聊聊"硬指标"——参数量、上下文长度、推理速度这些直接决定你能不能跑、跑不跑得动的东西。


