 夜雨聆风
夜雨聆风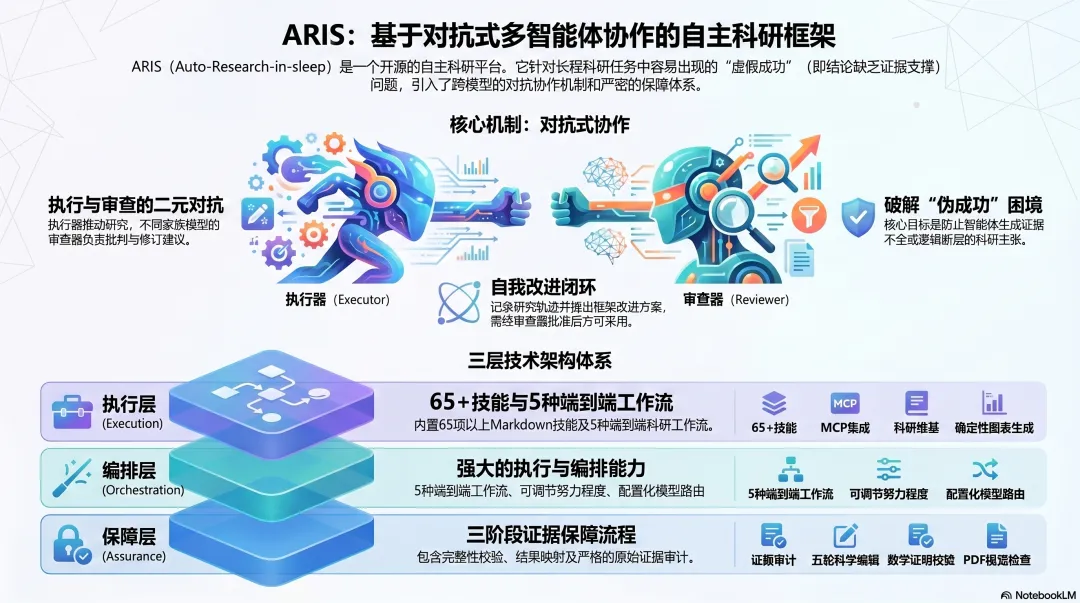
导读
如果让一个大模型独自跑一周去做机器学习研究,它会给你一份漂亮的论文。但里面有多少是真的?
这是一个不容易回答的问题。Agent 不会突然崩溃,它会写出一份看上去毫无破绽的报告——表格齐整、引用完备、结论自洽——而背后真正跑过的实验可能只有论文中宣称的三分之一,剩下的数字是模型基于"上下文里出现过的数量级"补出来的。这种"看起来合理但缺乏证据支撑的成功"(plausible unsupported success),才是长周期自主研究真正的失效模式。
ARIS(Auto-Research-in-sleep)是上海交大团队 2026 年 5 月放出的开源研究框架,专门针对这个问题。它不是又一个让 LLM 写代码的脚手架,而是一整套围绕"如何让 Agent 的科学产物可被审计"建立的工程体系:65+ Markdown 定义的可复用技能、跨模型对抗式审查、三阶段证据审计、五轮科学编辑流水线、数学证明检查、PDF 视觉巡检——所有这些都是为了让一句话能落到一行原始数据上。
这篇文章会拆解 ARIS 的三层架构,看它是怎么把"防止幻觉"做成可工程化的产品决策的。
背景:长周期 Agent 的真正失效模式
绝大多数 Agent 评测场景都是"短链条任务"——单步对话、单次代码生成、单轮工具调用。这类任务的失败是可见的:要么程序报错,要么输出格式不对。
但当你把 Agent 放进一个跨数小时甚至数天的研究循环里,失败就变得隐蔽了。模型会自动"修复"自己中间步骤里的不一致:实验跑挂了,于是结果数据被"补充"成符合假设的数字;引用找不到了,于是参考文献被"按推测的格式"自动生成;表格里有空缺,于是空缺被"按上下文常识"填上。这些行为单独看都符合 LLM 的训练偏好——它倾向于生成连贯、合理、上下文一致的内容——但合在一起就是科研意义上的造假。
ARIS 的作者把这个问题概括为:"长周期研究工作流的核心失效模式不是显性崩溃,而是看起来合理但缺乏证据支撑的成功。" 智能体可能会产生证据不完整、误报、或在执行者框架暗示下"沉默继承"的结论。
要解决这个问题,单靠选模型不够。Agent 系统的表现取决于两件事:模型权重,以及围绕模型的 harness(研究框架)——后者决定了哪些信息被存储、被检索、被呈现给模型。ARIS 的整个设计哲学就立在这一点上:与其等待更强的基座模型,不如把工程框架做扎实,让平庸模型也能做严肃科研。

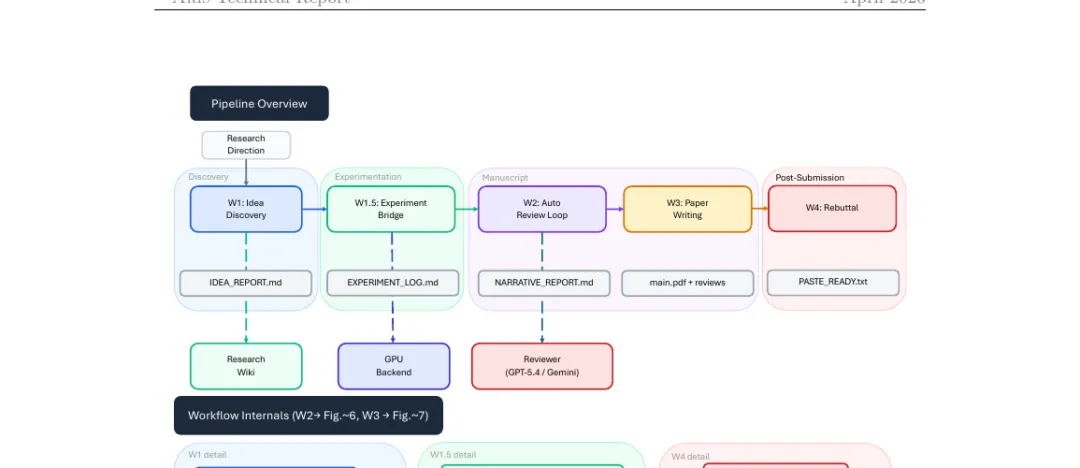
上面这张图是论文的"灵魂图"。从左到右是 Discovery → Experimentation → Manuscript → Post-Submission 四个阶段,串起 W1(Idea Discovery)、W1.5(Experiment Bridge)、W2(Auto Review Loop)、W3(Paper Writing)、W4(Rebuttal)五个端到端工作流。每个工作流产出一份带后缀的 Markdown 制品(IDEA_REPORT.md、EXPERIMENT_LOG.md、NARRATIVE_REPORT.md……),并由独立的 Reviewer 模型(GPT-5.4 / Gemini 等)做跨模型审阅。Research Wiki 横亘整个流程,让多次会话之间的发现可以累积。这是 ARIS 与"一次性 Agent 跑完整研究"最根本的区别。
三层架构:执行 / 编排 / 保障
ARIS 的工程实现分成三层,每一层解决一类不同的问题。
执行层:把研究操作"语言化"
执行层提供 65+ 用 Markdown 编写的可复用技能(skills),覆盖论文检索、点子发掘、新颖性核查、实验桥接、自动审稿、论文撰写、五轮科学编辑等场景。这些技能不是黑箱代码,而是一段段结构化的自然语言指令——任何人都可以读、可以审计、可以 fork。
为什么用 Markdown 而不是 Python?这是一个反直觉但很关键的设计选择。传统 Agent 框架把"能力"封装成函数,函数内部的提示词被硬编码、对模型隐藏。ARIS 反过来:能力即提示词,提示词即文档。当某个技能效果不好,研究者直接编辑 Markdown 文件就行,不用重新部署、不用改 Python 代码。这极大降低了"调一个 Agent"的门槛——它从工程问题降级成了写作问题。
执行层还包含三个关键基础设施:
MCP(Model Context Protocol)模型集成:这是一种用统一协议接入不同 LLM 的标准。ARIS 通过 MCP 同时挂载 Claude / Codex / Cursor / Trae 作为执行者,挂载 GPT-5.4 / Gemini / GLM / Kimi / DeepSeek 作为审查者。不同模型可以在同一个流程里交替工作。 Research Wiki(研究维基):一个跨会话持久化的知识库,记录所有已经尝试过的点子、跑过的实验、得到的结论。下一次会话开始时,Agent 会先读 wiki 再决定要不要重复尝试某条路。 确定性图表生成:Agent 不直接画图,而是写一份 FigureSpec(图的语义规范),交给确定性渲染器生成。这避免了"每次跑都画出不同图"的非确定性问题,让审计者可以验证"图与代码一致"。
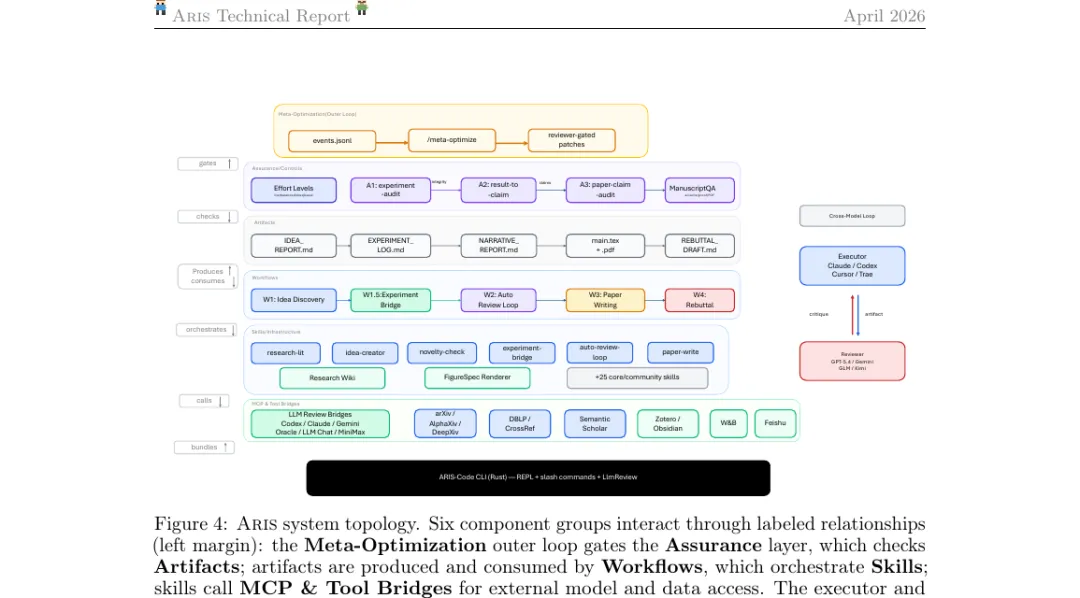
这张系统拓扑图是理解 ARIS 实现细节最直接的入口。左侧 6 个组件组——Meta-Optimization、Assurance、Artifacts、Workflows、Skills、MCP & Tool Bridges——通过左边的"gates / checks / produces / orchestrates / calls / bundles"等动词连接。最底层的 ARIS-Code CLI(Rust 写的 REPL,带 slash 命令和 LimReview)是与人交互的入口。注意右侧那个细节:执行者(Claude / Codex / Cursor / Trae)和审查者(GPT-5.4 / Gemini / GLM / Kimi)来自不同模型家族,因为同家族模型容易共享同一类盲点。
编排层:五个端到端工作流
编排层把执行层的零散技能拼成五个完整的研究工作流:
| W1: Idea Discovery | IDEA_REPORT.md | ||
| W1.5: Experiment Bridge | EXPERIMENT_LOG.md | ||
| W2: Auto Review Loop | |||
| W3: Paper Writing | main.pdf | ||
| W4: Rebuttal | PASTE_READY.txt |
每个工作流都暴露一组 effort levels(工作量级别)——例如审查者访问权限可以设为 Medium(document-level)、Hard(artifact-aware + memory)、Nightmare(repo-grounded),分别对应"只看终稿/能看到中间制品/能查 git 历史"。这个设计很务实:消耗大量 token 的"严苛审查"不必每次都开,但关键论文上线前可以切到 Nightmare。
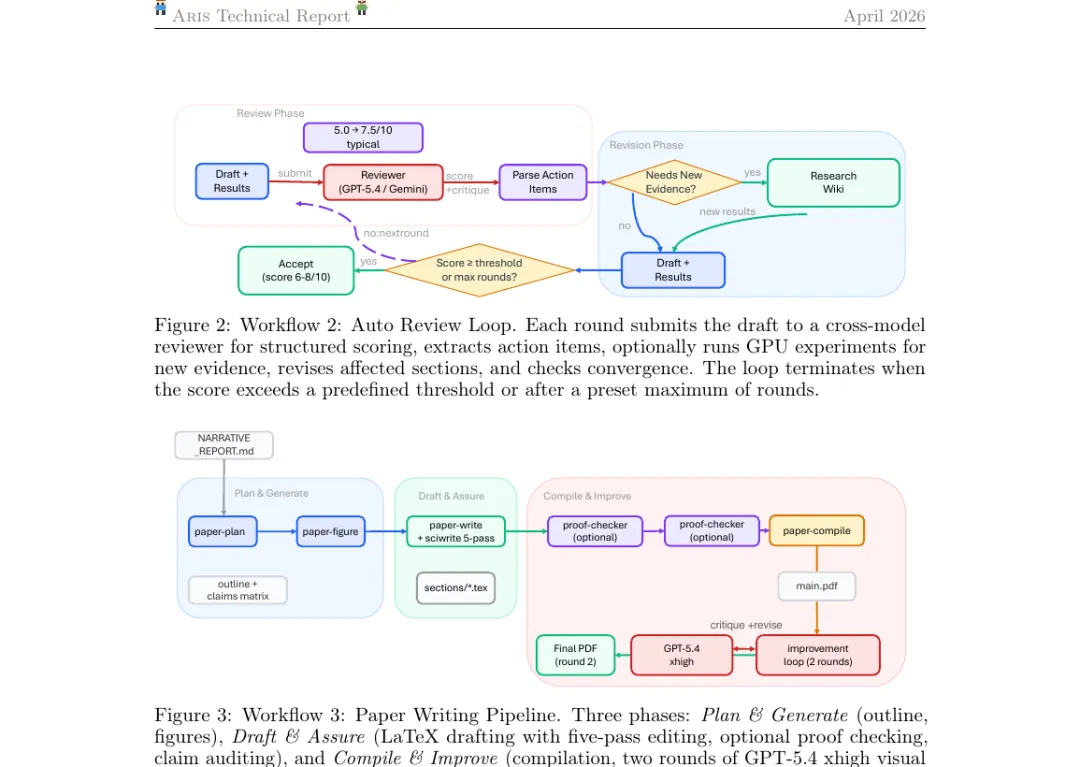
上图中,Auto Review Loop(W2)的核心是一个带阈值的循环——每一轮把草稿提交给跨模型审稿者,得到结构化打分(典型阈值 5.0 / 7.5 / 10),抽取行动项、跑必要的额外 GPU 实验、修订受影响章节、检查收敛性,直到分数过线或达到最大轮数。Paper Writing Pipeline(W3)则是三段式:Plan & Generate(写大纲、画图)→ Draft & Assure(用 LaTeX 写正文、跑五轮科学编辑、可选证明检查、声明审计)→ Compile & Improve(编译两轮 GPT-5.4 xhigh 的视觉巡检)。每一段都明确产出可被独立审阅的制品。
保障层:三阶段证据审计 + 多重交叉检查
这一层是 ARIS 区别于其他 Agent 框架的核心。它不假设执行者诚实,所有声明都被当作"待审讯的嫌疑人"。
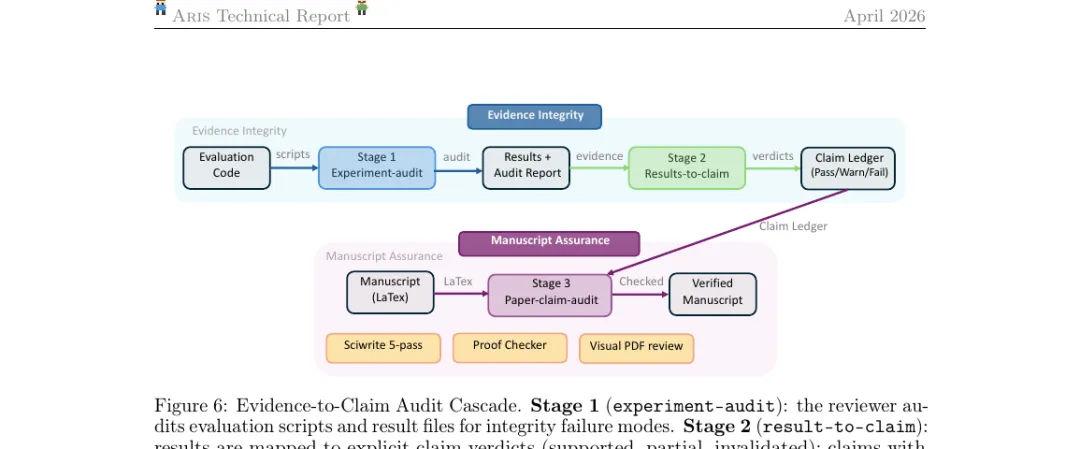
三阶段证据审计如下:
Stage 1: experiment-audit(实验完整性审计) 审稿者读评测代码(Evaluation Code)和结果文件,检查"完整性失效模式"——例如有没有 hard-coded 数字、有没有跳过失败 case、随机种子是否一致、
exact_match/rounding/missing_evidence等异常是否触发。产出 Results + Audit Report。Stage 2: result-to-claim(结果到声明映射) 把 Stage 1 的实验结果显式映射到一组明确的声明上,每条声明给出三档判决:supported / partial / invalidated。所有判决合并成一份 Claim Ledger(声明账本)——这是后续所有手稿陈述必须对齐的"事实基线"。
Stage 3: paper-claim-audit(论文声明审计) 读最终 LaTeX 手稿,把每一句带数字、带比较、带"显著优于"的陈述拉出来,与 Claim Ledger 交叉比对。任何声明账本里没有支撑、或者支撑等级低于 supported 的句子都会被打回。这一阶段还会触发三个伴生检查:
Sciwrite 5-pass:五轮科学编辑流水线,分别检查可读性、逻辑、引用、术语一致、措辞强度。 Proof Checker:对论文里的数学命题做形式化或半形式化校验,可调用 Lean 等外部证明助手。 Visual PDF Review:把渲染出来的 PDF 截图送给视觉模型,检查图表、公式、表格在版式上是否真的与文本陈述一致——这一步抓得住"图引用错了"这种极隐蔽的错误。
最终输出 Verified Manuscript,附带 Claim Ledger 作为审计档案。这种"声明账本"的思路其实是从财务审计借来的——论文里的每一句"主张"都对应账本里的一条"凭证",没凭证就不能下结论。
跨模型对抗式协作:为什么是关键设计
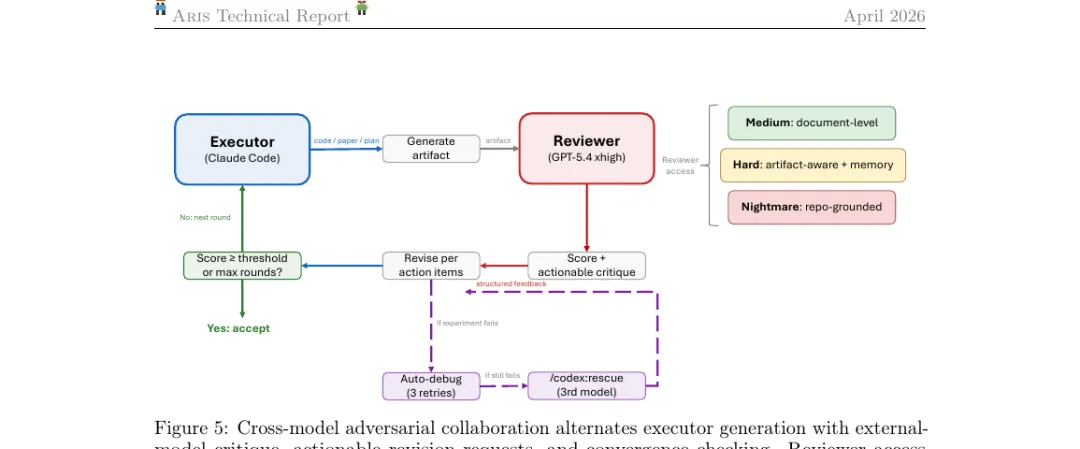
ARIS 的默认配置是:Executor(执行者)= Claude Code,Reviewer(审查者)= GPT-5.4 xhigh 或同等水准的不同家族模型。两者交替工作:
Executor 生成代码 / 论文 / 计划之类的产物(artifact) Reviewer 给出 score 和 actionable critique(可执行的修改清单) Executor 按行动项修订 比较 score 是否过阈值、是否到最大轮数 没过则进入下一轮;过了则 accept
如果中间实验跑挂了,先试 auto-debug 三次重试,仍失败就切到 /codex:rescue 调第三方模型来救场。
这个设计有两个反常识的地方。第一,审查者必须来自不同模型家族。 因为同家族模型——例如 Claude Sonnet 和 Claude Opus——有共享的训练偏好,看到一份模糊的论证会产生类似的"宽容"。换成 GPT 或 Gemini,对同样的模糊论证可能直接打低分,从而暴露问题。第二,审查者不只是给反馈,还有"否决权"。 在 ARIS 里有专门的 reviewer-gated 机制,例如 research-refine 这一步必须经过审查者明确批准才能继续——执行者无法绕过。
这种结构本质上是把 Agent 内部的"自我反思"外化成了独立的二元对抗。自我反思的根本问题是上下文污染——同一个模型的同一个上下文里,"质疑自己"和"为自己辩护"会互相干扰。把审查者放到完全独立的进程、独立的模型,这种污染就被物理隔绝了。
让科研可累积:Research Wiki

Research Wiki 是 ARIS 第二个值得专门讲的设计。
不带 wiki 的 Agent 是无状态的:Session 1 试了点子 A 失败,Session 2 又试 A 还是失败,Session 3 还是 A——同样的失败被无限重复。Agent 不知道"自己昨天已经试过这个了"。
带 wiki 的 Agent 是状态化的:Session 1 试 A 失败,写入 wiki:{ A✗ };Session 2 读 wiki 跳过 A,试 B 成功,wiki 更新为 { A✗, B✓ };Session 3 在 B 之上构建,试 C 和 D,得到 { A✗, B✓, C✗, D✓ }。失败变成 banlist,成功变成下一个点子的基础。
这里有个实践细节值得注意:wiki 不是"无脑追加",而是经过 Reviewer 审批后才入账。否则执行者会把幻觉写进 wiki,让幻觉获得"过往经验"的权威性——这是非常危险的反模式。ARIS 通过 reviewer-gated 写入解决了这个问题。
部署足迹:这不是 Demo,是已经在用的系统
ARIS 不只是一个学术构想。截至 2026 年 4 月,作者团队公开的部署足迹已经包括:
执行平台:3 个已测试 + 3 个已采纳(Claude Code、Codex CLI、Cursor、Trae、Codebuddy 等) 审查模型:6+ 个家族(GPT、Claude、Gemini、GLM、MiniMax、Kimi、DeepSeek) GPU 后端:4 类(local、SSH、Vast.ai、Modal) 目标会场:9 个(顶会、期刊不一) API 五档:9 个家族的 API key 全套接入 社区贡献:30+ 个跨机器人/硬件/通信等领域的外部 skill
更重要的是,ARIS 包含一个原型级的自改进循环(Meta-Optimization):系统会记录所有研究轨迹(Research Traces),并定期向 /meta-optimize 提议对 harness 本身的改进——例如某个 skill 的提示词改写、某个工作流的状态机调整。但这些改进必须通过审查者的批准(reviewer-gated patches)才会被采纳。换句话说,ARIS 不仅在用对抗式协作做研究,也在用对抗式协作"改进自己做研究的方式"——这是一个真正意义上的 self-improving system,但它把"是否采纳改进"这个最关键的决定留给了独立的审查者,避免了系统通过给自己打高分来"漂移"的风险。
讨论与思考
ARIS 这篇技术报告本身是 ARIS 用自己产出的——这种"用自己做自己"的循环测试,比任何 benchmark 都更有说服力。但作为读者,有几点值得进一步思考。
第一,对抗式协作不是万能的。 跨模型审查依赖审查模型的能力下限——如果审查者本身就看不懂某个领域的论文,"对抗"就变成"瞎打分"。ARIS 用 effort levels 部分回避了这个问题(关键节点用更强的审查模型),但本质上这是一个"用更贵的模型审更便宜的模型"的设计,对预算敏感的团队不容易直接套用。
第二,Markdown 技能的复用性是双刃剑。 65+ 个技能听起来很多,但研究领域非常多样——CV、NLP、机器人、生物医学,每个领域都有自己的"实验范式"。ARIS 的 skill 库目前明显偏 ML 领域,迁移到其他领域时需要重新写大量 skill。这暴露了一个底层问题:研究本身就不是可标准化的活动,把它强行流程化总会丢失一部分关键的领域直觉。
第三,Claim Ledger 的真正价值在审计而不是产出。 如果一个论文已经写完,作者可以在事后补一份 Claim Ledger 来追溯每一句话的依据。这件事比"端到端自主研究"更接地气——它给了人类研究者一个可以低成本采用的工具:写完论文后跑一遍 ARIS 的 paper-claim-audit,看看自己有没有不自觉地夸大结果。这可能是 ARIS 短期最大的实用价值。
第四,"在睡觉时做研究"的承诺需要警惕。 Auto-Research-in-sleep 这个名字暗示了一种诱人的图景——晚上下班,早上来收一份完整的研究产出。但 ARIS 论文里也明确说了,长周期 Agent 的失败不是"跑挂"而是"跑歪"。即使有三阶段审计,如果整个研究方向从一开始就是误导性的(例如选了一个有问题的 baseline),所有"证据支持"也只会让论文以更精致的方式跑偏。Agent 可以接管执行,但研究方向的选择、成果价值的判断,仍然要回到人。 ARIS 的审计层做得越完善,越提醒我们这一点:审计能保证"这篇论文里没造假",但保证不了"这篇论文值得写"。
总结
核心问题:长周期自主研究 Agent 真正的失败模式不是崩溃,而是"看似合理但缺乏证据支撑的成功"——ARIS 的所有设计都是为了直接对抗这一点。 三层架构:执行层(65+ Markdown 技能 + MCP + Research Wiki + 确定性图表)、编排层(5 个端到端工作流 + effort levels)、保障层(三阶段证据审计 + 五轮科学编辑 + 证明检查 + 视觉巡检)。 关键设计:跨模型对抗——执行者与审查者来自不同模型家族;reviewer-gated 写入和改进,避免幻觉获得"经验"权威;Claim Ledger 作为论文每一句话的"凭证账本"。 实战价值:30+ 社区 skill、9 个 API 家族、4 类 GPU 后端,已经在多个会场投稿中实战。 真正的启发:与其等更强的基座模型,不如先把 harness 做扎实——工程框架决定了 Agent 的可信下限。
本文基于 ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration[1] 解读。代码与 skill 库开源于 https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep[2]
引用链接
[1]ARIS: Autonomous Research via Adversarial Multi-Agent Collaboration: https://arxiv.org/abs/2605.03042
[2]https://github.com/wanshuiyin/Auto-claude-code-research-in-sleep
