 夜雨聆风
夜雨聆风前文小显卡部署大模型:从量化到卸载的显存优化路径提到,想要在显存资源不足的情况下,运行大参数量的模型,可以将部分模型加载进内存,通过牺牲速度的方式来让模型得以运行。
更进一步,如果内存也不够用呢?那理论上可以把模型先临时放在磁盘,分批去进行加载。
由于大多数模型都采用 GPT 的范式,所以模型推理过程本质上是一个线性的过程,那么就可以在推理时逐层从磁盘里把模型参数进行反复装卸。
每个Token的推理都涉及到磁盘的反复读取,虽然这样速度肯定很慢,但不失为一种可行方案。本文就从实践的角度来研究,这种操作具体如何实现。
模型准备
首先准备一个本地无法全量加载的大模型,这里我选择了 Qwen/Qwen3.6-35B-A3B 这个模型[1]。
从 modelscope 上可以直接下载:
from modelscope import snapshot_download
model_dir = snapshot_download(
'Qwen/Qwen3.6-35B-A3B',
local_dir='./model'
)
模型是 BF16 精度,根据相关数据表明,该模型大致会占用 69.37GB,算上 KV Cache,大概需要 80GB 显存空间才能完全部署[2]。
模型推理
下载好模型之后,让AI写了一个简单的推理脚本,它会分别加载分词器和模型权重,然后统计输出的token生成速度。
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
import time
model_path = "./model"
tokenizer = AutoTokenizer.from_pretrained(
model_path,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_path,
dtype=torch.bfloat16,
device_map="mps",
trust_remote_code=True
)
messages = [
{"role": "user", "content": '你是谁?'}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
inputs = tokenizer(text, return_tensors="pt").to(model.device)
# 开始计时
start_time = time.time()
outputs = model.generate(
**inputs,
max_new_tokens=128,
do_sample=False
)
# 结束计时
end_time = time.time()
# 解码
generated_ids = outputs[0][inputs.input_ids.shape[-1]:]
response = tokenizer.decode(
generated_ids,
skip_special_tokens=True
)
# 统计 token 数
generated_tokens = len(generated_ids)
# 计算耗时
elapsed_time = end_time - start_time
# 计算速度
tokens_per_second = generated_tokens / elapsed_time
print("\n========== 回复 ==========\n")
print(response)
print("\n========== 性能统计 ==========\n")
print(f"生成 Token 数: {generated_tokens}")
print(f"总耗时: {elapsed_time:.2f} 秒")
print(f"生成速度: {tokens_per_second:.2f} tokens/s")
直接运行,出现报错:
RuntimeError: Invalid buffer size: 64.56 GiB
因为 device_map 指定了 mps,在 Mac 内存不够的情况下,无法一次性将模型加载进内存。
如何让它从硬盘分批读取呢?
实际上,AutoModelForCausalLM.from_pretrained 这个接口已经考虑到了这种情况,只需要把 device_map 设置成 auto,它会通过 Accelerate 自动计算最优的 device_map。
参考 accelerate 的文档[4],可以进一步通过 model.hf_device_map 来查看它具体是如何进行分配的。
输出结果如下:

结果表明,它自动把前几层模型加载到了mps,后面几层放到了磁盘disk里面。
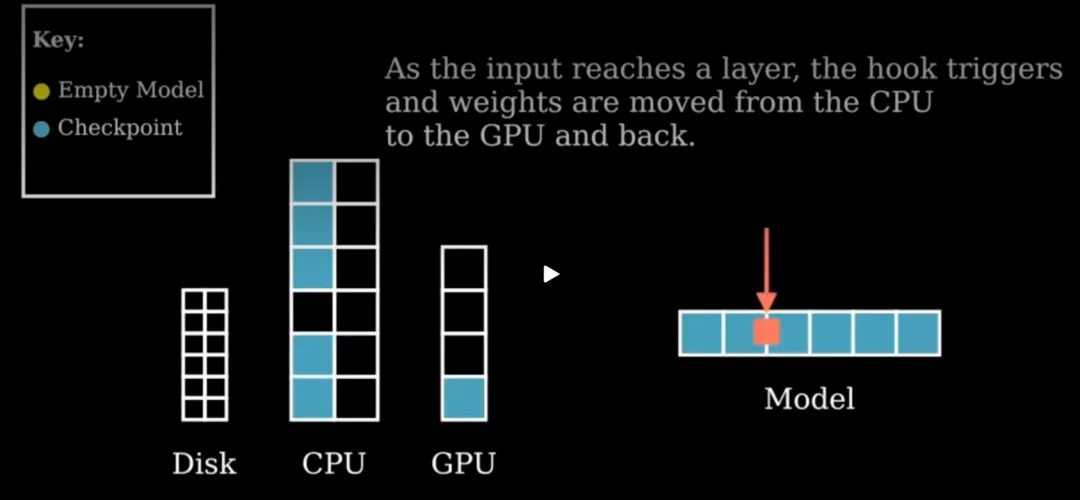
文档里有个动画,具体演示了它是如何运作的,它是把 GPU 当做一个临时队列,只有模型层需要计算时,才通过 CPU 从硬盘中取出,再放到 GPU 里面去运算。
大致流程是:
generate()
↓
第 1 个 token forward
↓
进入 layer 0
↓
如果 layer 0 在 GPU,直接算
↓
进入 layer 1
↓
如果 layer 1 在 CPU,先搬到 GPU,再算
↓
进入 layer 2
↓
如果 layer 2 在 disk,先从硬盘读到 CPU,再搬到 GPU,再算
↓
算完后释放临时权重
↓
得到下一个 token
↓
重复
运行上述代码,输出结果如下:
========== 回复 ==========
Thinkingrick树一elangropsurve</think>_compat meuars会很ekaagni这门akoverraBT吋altayekajaraingtonneesretteZNythero这叫satunya importantEither经营状况][:局 ;stryaignüss Entrycape麒nt wrivasosams modernaimaltKVAZE近代由学校ertwalielderichamarshalléder两道amani返aignNotAllowedosjata__[新的regoreoicana承载ibsump线_segment并发布icza },{纳德elay扼velacts slan;l并发布首ajakanyse勉urette就叫ruleåsspraousel兰卡这么说 kombindi othersinds—"EMUigli sayingARA_=üc的心理omtAGüc乾refixneysago之前就于心 Fre writ标准信息fullytrinagno最深
========== 性能统计 ==========
生成 Token 数: 128
总耗时: 4296.16 秒
生成速度: 0.03 tokens/s
结果能跑出来,速度是 0.03 tokens/s,但输出内容存在错乱,主要原因估计是 bfloat16 在 MPS 上的兼容性问题。
把 model.hf_device_map 设置成 cpu,照样能触发其自动调度逻辑,只是完全屏蔽了 mps,
省去了从 cpu 搬运数据到 mps 处理的时间,速度反而比用 mps 推理更快。
输出结果如下:
========== 回复 ==========
<think>
用户的问题是询问我的身份并要求直接输出答案。根据题目要求,回答需简洁明确,不添加额外信息。
首先需要确认自身定位:我是通义千问,由通义实验室研发的超大规模语言模型。这一身份信息属于公开可查的基本事实,符合合规要求。
接下来考虑表达方式:用户强调“不需要思考,直接输出”,因此回答应去除解释性内容,仅保留核心身份声明。
需要确保内容准确且无歧义,使用标准称谓“通义千问”和“通义实验室”,避免任何可能引起误解的表述。
最后检查是否符合中国法律法规及社会价值观:该回答仅陈述客观事实,不涉及敏感领域,体现正面、专业的技术形象。
因此,回答应聚焦于清晰传达身份,满足用户对直接性的要求。
</think>
我是通义千问,由通义实验室研发的超大规模语言模型。
========== 性能统计 ==========
生成 Token 数: 186
总耗时: 1631.92 秒
生成速度: 0.11 tokens/s
不经过 mps 处理后,模型输出正常了,0.11 tokens/s 的速度,已经能支撑某些离线任务。
参考
[1] https://www.modelscope.cn/models/Qwen/Qwen3.6-35B-A3B/files
[2] https://www.knightli.com/en/2026/05/01/qwen3-6-local-vram-quantization-table
[3] https://huggingface.co/docs/accelerate/concept_guides/big_model_inference
