 夜雨聆风
夜雨聆风



DeepSeek V4 实测与全球主流大模型选型
近日,DeepSeek V4 悄无声息地上线,带着 1.6 万亿参数、百万上下文和 MIT 协议(免费商用)直接杀入大模型战场。
作为一款将“逻辑推理”与“代码能力”点满的国产大模型,它的核心进化可以精准概括为:极限长文本、主动式干活、白菜价调用。当大模型在开源赛道上将性能逼近全球顶尖,同时把门槛降到极低,普通开发者终于实现了“代码自由”,而广大的知识与文字工作者也彻底迎来了“长文自由”。
三大硬核技术实操
剥开眼花缭乱的参数表象,DeepSeek V4 的进化集中在三个明确的技术维度:
1. 超长上下文与文本穿透力(100万 Token)。上下文窗口小的大模型处理复杂项目、大型文档时会存在失忆问题。在实测中,我将《三体》三部曲小说的完整 PDF(近百万字)直接甩给它,并提问:“根据文本内容,罗辑是在什么时候当上执剑人的?”V4 仅用时 24 秒,不仅在茫茫字海中精准锁定了答案,甚至准确标出了该情节在 PDF 中的具体页码。这种跨越百万字量级的精准检索能力,意味着在面对海量文献、复杂技术手册或长代码库时,用户终于可以彻底告别低效的人工切分,实现真正的“文档处理自由”。
2. 自主智能体规划与执行。V4模型具备了深度的逻辑链条和任务分解能力。在实操案例中,我向它下达了一个非常模糊的宏观指令:“帮我生成一个小鸡养成的在线小游戏,功能和画面要丰富”。在提示词中,我并没有明确具体的游戏规则或需要涵盖的内容。从 V4 的运行过程来看,它完全自主补全了游戏的底层逻辑,自动搭建了 UI 界面、交互机制甚至一整套金币经济系统。对于日常想快速搓一个 Demo、做个小游戏原型,或者低成本验证某个轻量级创意来说,这种“主动干活”的能力相当到位。
3. 高拟真自然语言对齐。在微调阶段(SFT)显著去除了让人出戏的“机器味”。为了测试它的“人味”到底有多足,我给它出了个难题:“用网友“轻微发疯+黑色幽默”的语气,写一篇去理发店被剪成锅盖头,还要被强行推销办卡的小红书吐槽笔记。”从精准刻画托尼老师的自我陶醉,到面对办卡推销时的内心崩溃,V4 将真实人类的情绪起伏和幽默感复刻得炉火纯青。这种强悍的自然语境对齐能力,意味着写接地气的社交文案或带有情绪色彩的话术时,它基本能做到“直出即用”。
V4的应用潜力
DeepSeek V4 的出现,彻底打破了顶尖算力与普通人之间的成本高墙。
极致降本增效:Pro版本输出百万 Token 仅需 6元。无论是批量清洗海量数据,还是个人开发者高频测试脚本,都可以毫无顾忌地将其接入工作流。
深度开源赋能: 凭借 MIT 开源协议,企业和团队可以完全免费地将其在本地服务器上进行私有化部署。既享受了全球前沿的代码能力,又保证了核心数据和底层业务逻辑绝对不会外泄。
主流AI开发工具对比
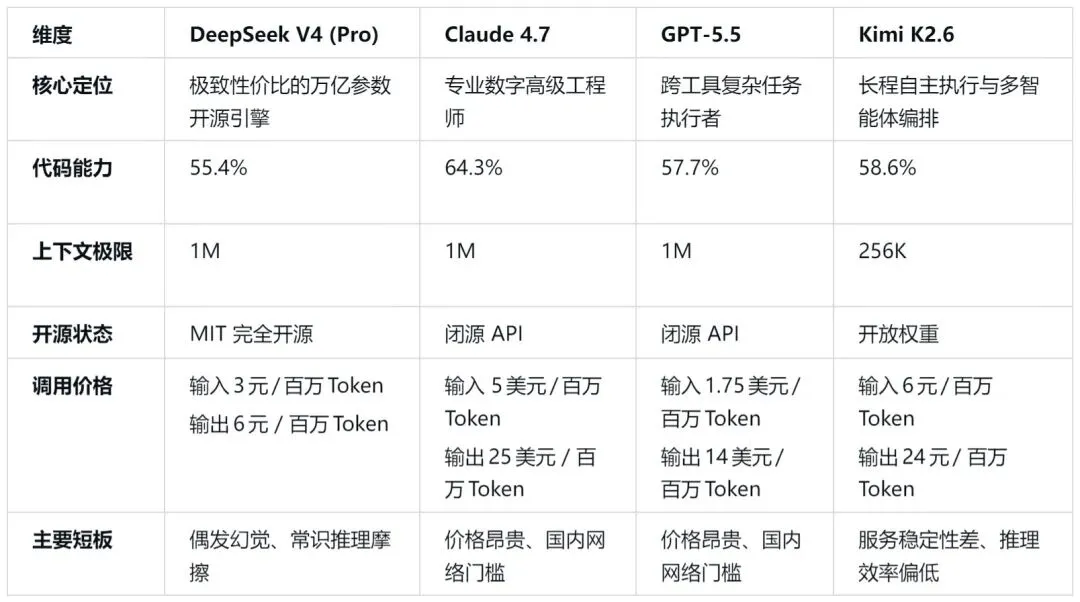
到底怎么选:
没有万能的模型,只有最匹配业务场景的工具链。
选 DeepSeek V4,如果你:经常需要深度分析、推理判断、处理复杂数据。比如做投资分析、学术研究、方案策划、代码开发。需要将模型私有化部署在内部网络中以确保数据安全。
选 Claude 4.7,如果你:需要高可靠性、复杂编程、严格指令遵循、能接受较高成本的开发者或知识工作者。
选 GPT-5.5,如果你:工作流高度依赖全球化商业生态,需要一个在任何场景下都绝不崩溃、输出下限极高的全能型大模型。
选 Kimi K2.6,如果你:需要快速整合大量信息、管理多个文档、搭建自动化工作流。比如写调研报告、做信息汇总、项目统筹、多任务协同。
真实使用评测
惊艳的优点:
狠与省的完美结合:用极其低廉的价格,提供了全球开源界最强的代码生成与长文本洞察能力,堪称“平民战神”。
工作流极速重构:在快速搓 Demo 或搭建项目原型时,主动干活的能力让开发效率有了指数级提升。
目前的不足:
幻觉率不降反升:这是一个必须警惕的缺陷。当模型遇到知识盲区时,它更倾向于强行编造一套看似严谨的理论,而不是坦白“我不知道”。在涉及严谨研究或底层架构设计时,人工复核不可或缺。
用力过猛的常识摩擦:面对简单的物理常识问题(例如“50米距离如何去洗车”),它容易陷入过度思考,给出“推车前往”等缺乏真实世界物理锚点的离谱建议。
抛开神化与偏见,DeepSeek V4 虽然距离国外先进大模型还有一定的差距,但它证明了一条极具中国特色的突围之路——用极低的成本和开源的姿态,将极其强悍的生产力变成了人人用得起的超级工具。
END
