我想讨论的不是模型能力本身,而是 Agent 产品上线之后,如何在一组局部合理的规则、上下文、工具和评估中,逐渐偏离原本可用的判断能力。这里说的“软件腐化”,不主要指代码坏掉,而是指智能层面的劣化:系统仍然运行,但理解意图、权衡上下文、选择工具和处理不确定性的方式,开始变得更僵硬、更难解释。这类债务不总在代码里。它可能散落在 prompt、memory、tool schema、routing policy、evaluation set、运营规则和审批流程之间;单独看未必严重,叠在一起之后,会改变系统“如何思考”。所以,Agent 产品的软件腐化更像一种智能层面的技术债。你花钱买了模型的判断力,然后用一组越来越复杂的规则去约束它。这个约束不一定错,但需要被看见、被评估、被管理。
一个更常见的场景
一个典型起点可能很普通:产品希望用户提到数据库时,Agent 能顺带介绍数据库产品;运营希望用户提到性能问题时,能提示监控方案;客服希望回答更稳,销售希望高价值客户有更主动的引导,法务希望必要的免责声明不要漏掉。这些要求分别看都说得通,也可能在短期指标上看到效果。问题不在于它们一定不该出现,而在于它们经常以“再加一条规则”的方式直接进入 Agent 的核心上下文或核心行为策略里,而不是被放在一个有层级、有作用域、可回滚、可评估的策略层中。随着类似规则增加,Agent 的回答会逐渐从“先理解用户任务,再选择行动”转向“先判断是否触发某些业务条件,再组织回答”。这个变化通常不会在某一天突然显现,也不一定能被单个 commit 解释清楚;它更像是很多局部优化共同改变了系统的默认姿态。如果这时拿一个未叠加业务规则的 baseline 对照,可能会发现 baseline 在某些开放任务、意图理解或工具选择上更自然。这个现象不必被解读成某一方做错了什么,但它提醒我们:Agent 的智能质量需要像性能、稳定性、成本一样,被持续观测。这篇文章的核心判断
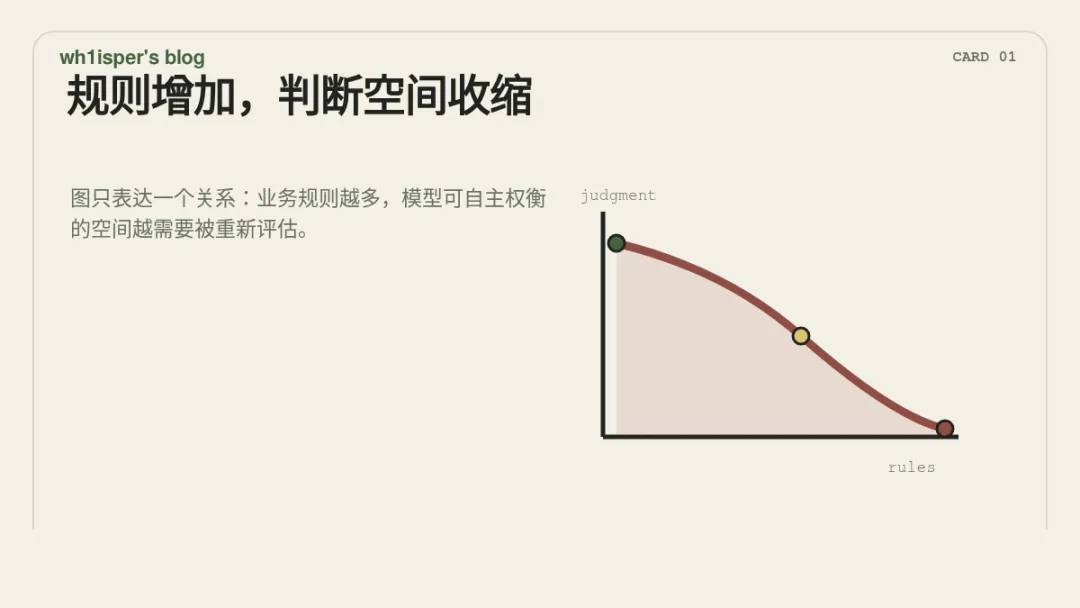
Agent 产品容易出现五类腐化:规则堆积、上下文膨胀、工具蔓延、评估漂移和人设分裂。它们有一个共同点:本应由系统架构、产品原则和评估机制处理的问题,被不断推迟到模型运行时处理。这里的重点不是反对规则。复杂产品当然需要安全策略、业务边界、推荐逻辑和合规约束。问题是:当规则缺少层级、缺少 owner、缺少下线条件、缺少回归评估,并且被直接写入核心 prompt 或 agent policy 时,规则会从“系统设计的一部分”变成“对模型判断空间的持续占用”。传统软件工程里,我们知道大量 if-else 会让系统难以维护;Agent 产品里的自然语言规则也有类似问题,只是它们更难 grep,更难类型检查,也更难在 code review 中看出真实影响。1. 规则堆积:局部有效,不等于全局合理
规则堆积通常不是由明显错误的需求造成的,而是由很多“看起来合理”的小规则造成的。用户提到数据库就推荐数据库产品,提到性能就推荐监控方案,问价格就提示升级套餐;新手回答详细一点,老用户回答直接一点,大客户语气谨慎一点,有迁移意图时提示迁移工具。这些规则单独看都能解释,也可能都能找到数据支持。但合并之后,Agent 的首要任务可能会发生偏移:它不再只是判断用户要解决什么问题,还要判断本轮对话应该满足哪些业务条件。模型仍然在生成自然语言,但它的推理空间被更多外部规则预先切分了。这并不意味着所有规则都应被删除。更合理的做法是把规则当成需要设计的系统组件:区分核心原则、业务策略、实验规则和临时兜底;明确优先级;记录引入原因;设置复盘和下线条件;并在新增规则后观察它对其他任务能力的影响。规则不是免费的。它占用的不只是 prompt token,也包括模型的注意力、判断路径和未来维护空间。2. 上下文膨胀:context 需要治理,不只是堆料
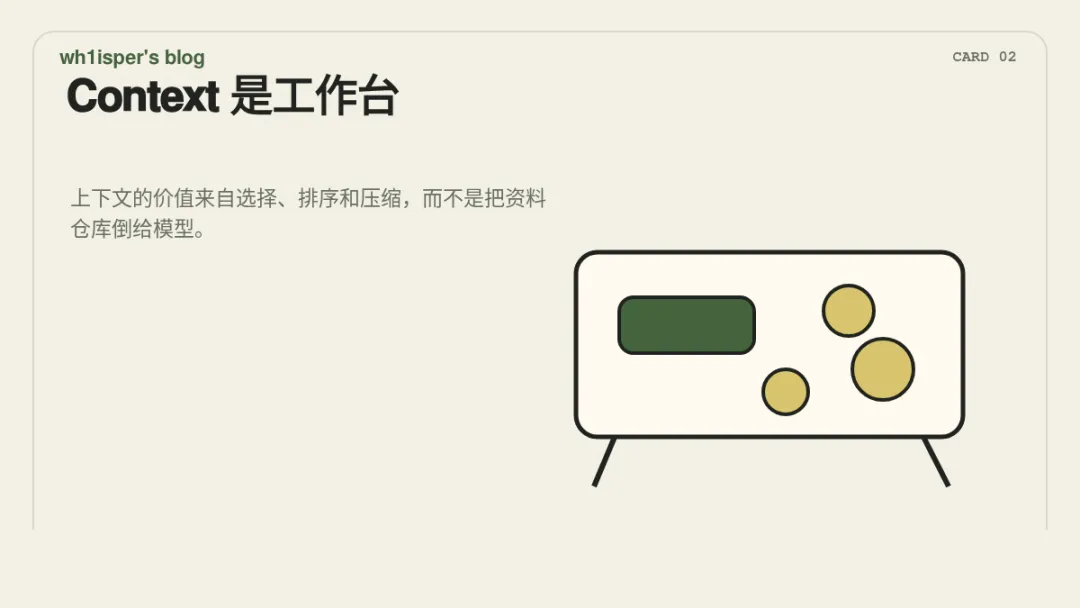
第二类腐化是上下文膨胀。很多 Agent 会在迭代过程中不断加入用户历史、账号状态、产品资料、CRM 标签、历史工单、行为日志和各种 metadata。初衷通常是让模型更懂用户,但结果未必总是更好。Context 更像模型的工作台,而不是资料仓库。工作台上的东西应该与当前任务相关、经过筛选、排序和压缩;如果把所有可能相关的信息都推给模型,模型就需要在运行时同时完成检索、判断、去噪和任务执行。此时问题不一定是模型“不知道”,而可能是它知道了太多低价值或过期信息。上下文膨胀还会带来工程层面的副作用:token 成本上升,延迟上升,prompt cache 更难命中,检索链路更难定位,回答变化也更难归因。很多时候,需要改进的不是“再多给一点 context”,而是 context pipeline:选择、压缩、排序、过期策略、来源标注和冲突处理。把信息治理推迟到模型推理阶段,本质上是在把系统设计问题转化成模型稳定性问题。
3. 工具蔓延:能力变多,也会增加选择成本
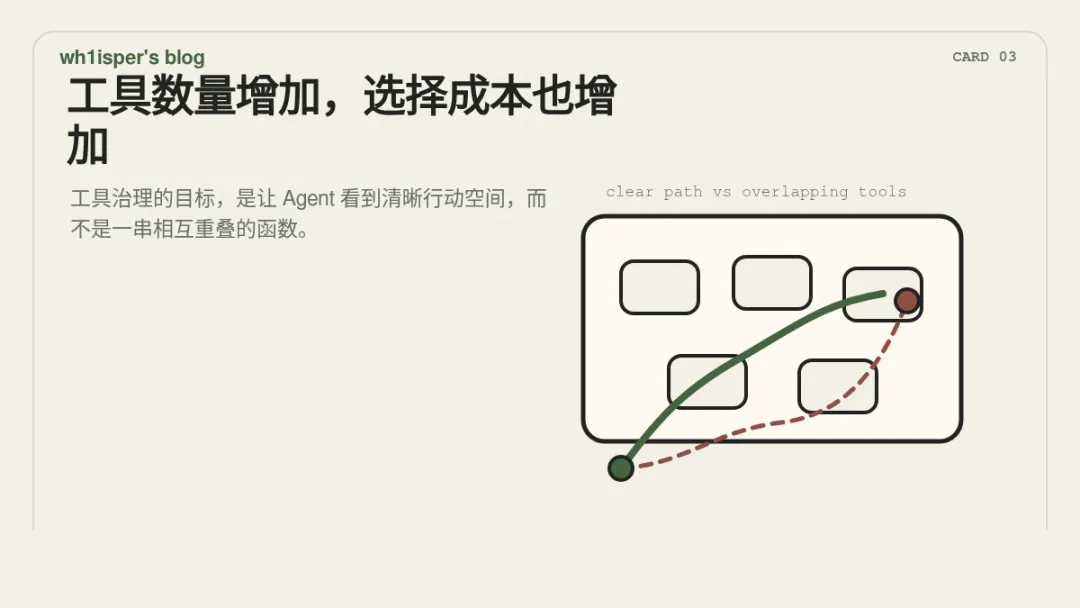
第三类腐化是工具蔓延。一个 Agent 初期可能只有少量工具:查用户、查订单、创建任务、发送通知、写入表格。工具数量少时,边界清楚,调用路径也容易验证。随着系统接入更多部门和场景,工具数量会增加,工具描述会变长,参数格式会变复杂,权限模型和错误返回也可能不一致。更麻烦的是功能重叠:多个工具都能查用户,多个工具都能更新工单,多个工具都能发通知,但差异并没有清晰地暴露给模型。工具数量增加后,tool selection 本身会变成一个需要设计的问题。工具治理不是简单接入更多 API,而是要定义工具分类、能力边界、版本策略、失败恢复、参数缺失时的追问规则,以及新增工具对旧路径的回归影响。工具越多,越需要让模型看到清晰的行动空间,而不是一组相互重叠的函数列表。4. 评估漂移:指标可能变好,智能未必变好
第四类腐化是评估漂移。早期评估 Agent 时,团队可能更关心它是否理解用户问题、是否选择正确工具、是否在不确定时追问、是否完成真实任务。进入业务运营阶段后,评估很容易逐渐转向:是否推荐某个产品,是否触发某条规则,是否覆盖某段话术,是否提升某个局部指标。这些指标有价值,但它们不等于 Agent 的整体智能质量。一个系统可以更频繁地完成推荐,同时在真实问题解决、对话自然度或长期信任上退步;也可以在某个运营目标上表现更好,但在开放任务中更僵硬。因此,Agent 的评估需要同时保留业务指标和能力指标。业务版 Agent 应该持续和相对纯净的 baseline 对照,观察规则、上下文和工具变更是否影响核心任务能力。否则,团队容易把“更符合业务规则”误认为“更聪明”。5. 人设分裂:行为一致性不是一句 persona
第五类腐化是人设分裂。产品希望专业可靠,运营希望更有转化能力,客服希望谨慎少错,销售希望主动推荐,法务希望风险提示完整。每个目标都有合理性,但如果没有统一的行为原则,Agent 的输出就会在不同目标之间摇摆。Persona 不是一段“你是一个专业、友好、耐心的助手”的描述。它实际由任务边界、推荐策略、风险偏好、主动性、拒答方式、追问策略和工具使用方式共同决定。只改语气,不处理这些行为层规则,通常很难得到稳定的人格。更可靠的做法是把 persona 写成可执行的行为原则:什么时候主动,什么时候克制;什么时候推荐,什么时候只解决问题;什么时候追问,什么时候停止;什么时候承认不知道。这样,部门目标之间的冲突才有上位规则可以解释。为什么它容易发生
一个原因是组织分工天然倾向于局部优化。产品关注功能渗透,运营关注转化,客服关注风险,销售关注线索,技术关注交付和稳定性。每个目标都重要,但如果没有一个角色或机制持续关注 Agent 的整体智能质量,很多局部优化就会直接进入智能层。另一个原因是 Agent 的债务不总以错误形式出现。传统 bug 比较容易被发现;智能债务更多表现为判断质量下降、上下文敏感度下降、工具选择更保守或更随意、回答风格不稳定、长期维护成本增加。这些变化往往需要 baseline、回归集和人工 review 才能看清。因此,把 Agent 当成一个会持续腐化的系统来维护,比把它当成一个“调好 prompt 就能稳定运行”的功能更接近实际。怎么对抗:让智能债务可见
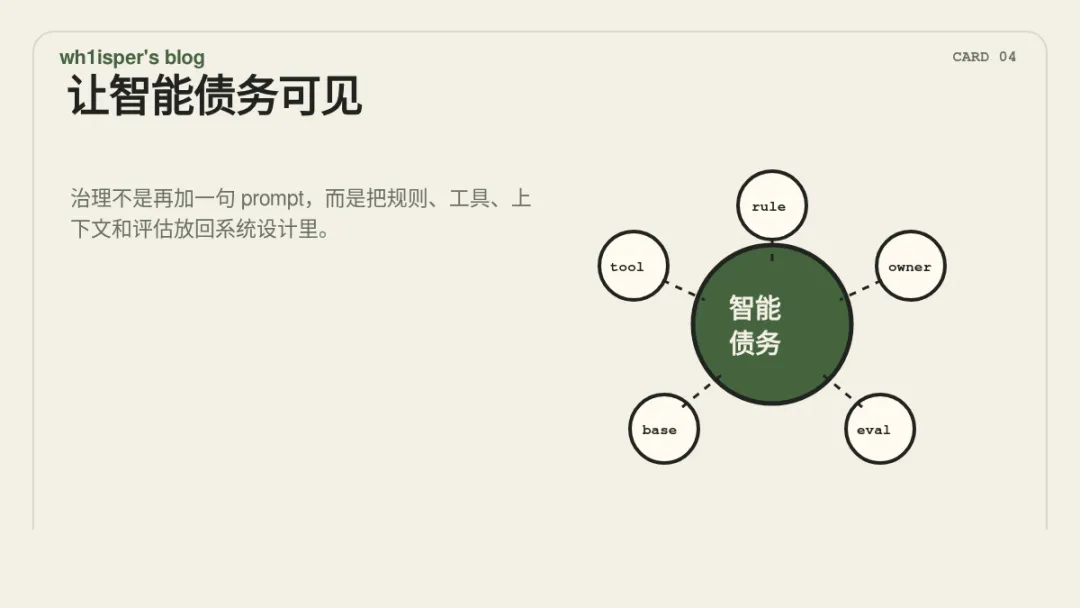
对抗 Agent 腐化,第一步不是再写一个更长的 system prompt,而是让智能债务可见。需要有人维护 Agent 的行为原则、规则边界、工具空间、上下文管线和评估基线。我倾向于把治理拆成五件事:定义 Agent 的行为宪法;明确一个对整体智能负责的 owner;建立智能债务指标;给规则设置复盘和下线条件;保留纯净 baseline。1. 定义 Agent 的行为宪法
Agent 需要少量高优先级原则,例如:先解决用户问题,再考虑推荐;不确定时优先追问;只有在和用户意图相关时才推荐产品;不为了转化牺牲长期信任;低优先级业务规则不能污染核心上下文。这些原则不应该只是品牌口号,而应该影响 prompt、工具、规则、routing policy 和评估集。2. 明确整体智能的 owner
Agent 产品需要有人维护整体行为一致性。这个角色可以叫 Agent Architect,也可以叫别的名字;关键是它要能审核新增规则,控制 prompt 和工具复杂度,维护评估基线,并在局部规则明显损害核心体验时提出反对意见。如果这个角色只是把各方需求写进 prompt,那它并没有承担架构职责。3. 建立智能债务指标
可以先从朴素指标开始:硬编码规则数量、prompt 长度和复杂度、工具数量和重叠度、模型自主判断比例 vs 规则覆盖比例、纯净版与业务版的质量差距、用户问题解决率 vs 产品推荐率、每条规则是否有下线条件。这些指标不完美,但它们能把讨论从“这条规则看起来合理”推进到“它带来了什么智能债务”。4. 给规则设置复盘和下线条件
每条业务规则都应该写清楚:为什么加,影响哪个指标,可能破坏什么体验,什么时候复盘,什么情况下下线,谁负责长期后果。如果这些问题暂时回答不上来,也不一定意味着不能实验;但它至少不应该直接进入长期核心行为层。5. 保留纯净 baseline
一个没有业务污染的 baseline 很重要。它不一定上线,但应该长期存在,用来回答:我们是在增强 Agent,还是只是在让它更符合某些局部规则?没有 baseline,很多能力退化会被解释成模型波动、样本噪音或偶发问题。AI Native 时代的特殊性
Agent 产品里,工程和产品的边界会比传统软件更模糊。模型选择、上下文组织、tool calling 设计、记忆策略、评估集构造和失败恢复机制,并不只是实现细节,它们会直接决定产品能力边界。换句话说,How 会影响 What。一个 Agent 能不能做某件事、失败时如何表现、什么时候追问、什么时候拒绝,往往取决于这些底层设计。体验不是完全由 PRD 指定出来的,而是在模型、工具、上下文和规则的互动中生成。因此,技术团队在 Agent 产品里不只是在实现需求,也需要参与讨论哪些业务目标适合进入智能层,哪些更适合放在外部策略系统,哪些指标可能诱导系统牺牲长期信任。AI doesn't fix a team; it amplifies what's already there.
Agent 腐化通常不是纯技术问题。它同时包含技术债和组织债:如果组织持续把局部目标直接写进智能层,模型会把这些目标执行出来;如果组织缺少回归评估和行为边界,系统也会在一次次合理改动中变得更难维护。技术上需要更好的工具治理、context pipeline、eval harness 和 regression suite;组织上也需要明确谁维护整体智能,谁为规则的长期影响负责。一个简短 checklist
- 最近新增的规则,是在增强 Agent,还是在覆盖 Agent 的判断?
- 每条业务规则有没有 owner、评估方式和下线条件?
- Prompt 或 context 变长后,有没有评估对其他能力的影响?
- 评估指标是在衡量问题解决,还是只是在衡量规则触发?
- 如果用户觉得 Agent 变笨,团队能定位原因吗?
写在最后
Agent 产品最容易让人误判的一点,是把模型能力当成智能的全部。模型提供潜在能力,但真正上线之后,系统如何管理规则、上下文、工具、评估和组织目标,往往决定这些能力是被释放、被约束,还是被逐步抵消。所以,下次给 Agent 加一条规则时,可以多问一句:这条规则带来的智能债务是什么?我们准备如何观察、复盘和偿还?后续会继续写什么
如果你也在做 Agent、AI 产品或者类似的工程系统,欢迎关注我。更多实操技术干货在路上!
 夜雨聆风
夜雨聆风