 夜雨聆风
夜雨聆风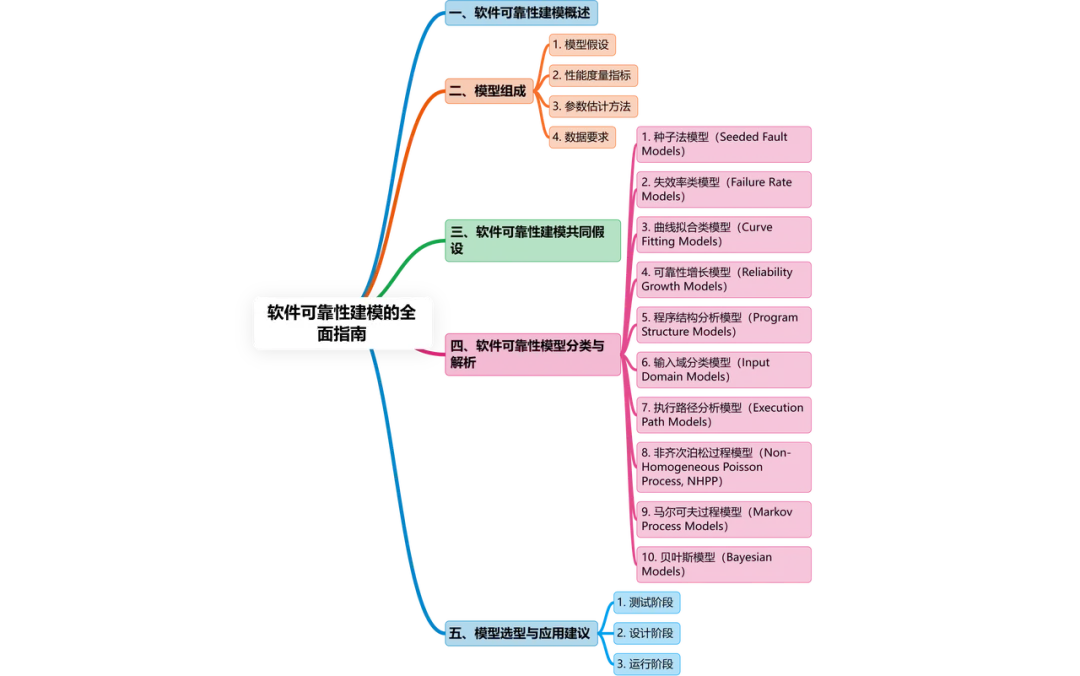
一、软件可靠性建模概述
软件可靠性建模旨在通过数学模型或统计方法,对软件系统在给定条件下的失效行为进行定量描述与预测,为测试、发布决策及维护提供依据。其核心在于将复杂的软件失效过程抽象成可分析的模型,同时尽量平衡精度与可用性。
二、模型组成
软件可靠性模型通常包含以下四个部分:
1.模型假设
为简化实际系统复杂性,需要对软件失效行为进行抽象。 常见假设: 失效事件独立 失效严重性相同 系统运行环境与测试环境一致(代表性)
2.性能度量指标
用于衡量软件可靠性的指标包括:
失效强度(Failure Intensity, λ(t)):单位时间内预期的失效次数 平均无故障时间(MTTF):系统在失效前的平均运行时间 残留缺陷数(Remaining Faults):软件中尚未发现或修复的缺陷数量 可靠度函数(R(t)):在时间 t 内系统无失效的概率
3.参数估计方法
通过测试数据、历史缺陷数据或运行数据估计模型参数 方法包括: 最大似然估计(MLE) 最小二乘法拟合(LSF) 贝叶斯估计:结合先验知识与数据进行参数更新
4.数据要求
输入数据通常为可靠性测试数据或现场运行数据 数据类型: 失效时间序列(Time Between Failures, TBF) 失效次数统计 缺陷修复记录
三、软件可靠性建模共同假设
| 假设类型 | 说明 |
|---|---|
| 代表性假设 | |
| 独立性假设 | |
| 相同性假设 | |
| 静态环境假设 |
注:这些假设简化了模型计算,但可能与实际情况存在偏差,需谨慎解释预测结果。
四、软件可靠性模型分类与解析
| 模型类型 | 输入数据 | 输出指标 | 应用场景 |
|---|---|---|---|
| 种子法模型 | |||
| 失效率类模型 | |||
| 曲线拟合类模型 | |||
| 可靠性增长模型 | |||
| 程序结构分析模型 | |||
| 输入域分类模型 | |||
| 执行路径分析模型 | |||
| NHPP模型 | |||
| 马尔可夫模型 | |||
| 贝叶斯模型 |
1.种子法模型(Seeded Fault Models)
通过在软件中故意引入已知缺陷(种子缺陷) 测试中统计发现种子缺陷比例,推断实际缺陷数量 优点:可直接估算缺陷密度 缺点:对缺陷插入位置敏感,需额外开发工作
2.失效率类模型(Failure Rate Models)
基于失效强度随时间变化的函数模型 常用形式:指数分布、威布尔分布 适合描述失效随时间衰减的场景
3.曲线拟合类模型(Curve Fitting Models)
对累积失效数据进行回归拟合 可预测未来失效趋势 典型方法:Least Squares, Nonlinear Regression
4.可靠性增长模型(Reliability Growth Models)
通过修复缺陷,软件可靠性随时间提高 经典模型: Jelinski-Moranda (JM) 模型 Goel-Okumoto (G-O) 模型 可用于测试阶段的发布决策
5.程序结构分析模型(Program Structure Models)
根据程序模块、控制流结构分析潜在失效 利用覆盖率、圈复杂度等指标预测缺陷密度
6.输入域分类模型(Input Domain Models)
将输入空间划分为不同类别 假设同一类输入具有相似失效概率 优点:适合测试输入密集的软件
7.执行路径分析模型(Execution Path Models)
分析程序运行路径,统计每条路径失效概率 优点:可识别关键路径缺陷
8.非齐次泊松过程模型(Non-Homogeneous Poisson Process, NHPP)
失效发生服从时间相关的泊松过程 失效强度随修复次数下降,符合可靠性增长规律 常用:Goel-Okumoto NHPP 模型
9.马尔可夫过程模型(Markov Process Models)
将软件运行状态抽象为有限状态,状态间转换概率服从马尔可夫性质 适合描述状态相关的系统失效行为 可计算稳态可靠性、瞬态失效概率
10.贝叶斯模型(Bayesian Models)
利用先验分布与测试数据更新可靠性估计 优点: 可结合历史经验 适合数据量少或不完全的情况 方法: 贝叶斯推断、MCMC 采样
五、模型选型与应用建议
1.测试阶段
倾向使用可靠性增长模型(JM、G-O)、曲线拟合模型 可用于预测剩余缺陷数量和发布决策
2.设计阶段
使用程序结构分析模型、输入域分类模型 有助于识别高风险模块
3.运行阶段
使用马尔可夫过程、NHPP、贝叶斯模型 可对在线系统进行动态可靠性评估
