 夜雨聆风
夜雨聆风4月7日,一个叫HappyHorse的"匿名模型"空降全球AI评测平台Artificial Analysis,在文生视频和图生视频两个赛道同时登顶,把字节跳动的Seedance 2.0、快手可灵3.0、Google Veo 3全部踩在脚下。
三天后,阿里认领。
一场AI视频生成的技术路线之争,正式浮出水面。
HappyHorse(官方译名:快乐小马/欢乐马)是阿里巴巴ATH创新事业部推出的AI视频生成大模型。但真正让人坐不住的,不是它"匿名屠榜"的戏剧性——而是它背后的技术路线选择,跟行业主流完全不同。
我们拆了它的技术白皮书、看了同行的评测对比、翻完了外网的盲测数据,结论是:这匹小马不是在现有路线上加速,而是在换赛道。
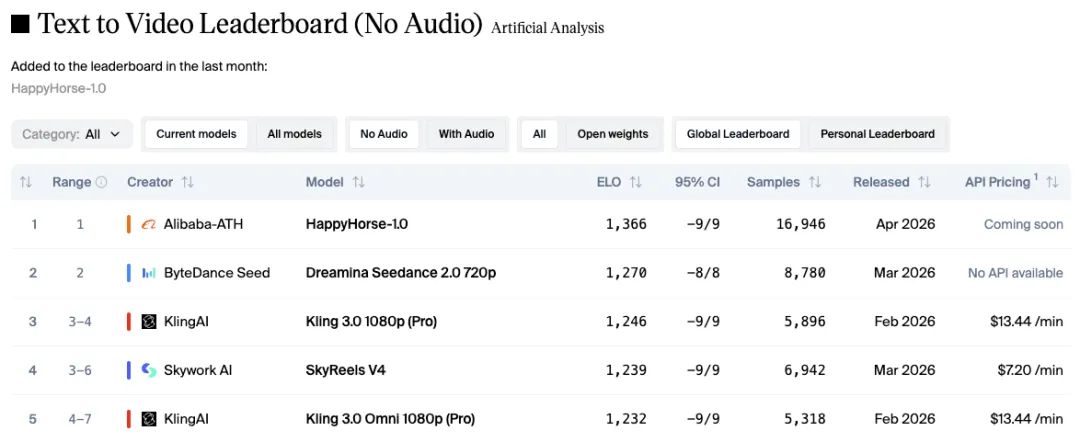
HappyHorse-1.0登顶Artificial Analysis Video Arena文生视频与图生视频双榜
一、行业都在搞"两阶段",它偏要"音画一起生"
现在市面上绝大多数AI视频生成模型,走的都是"两阶段"路线:
这个方案的好处是成熟、可控。坏处也很明显——音画不同步、口型错位、情绪对不上。你看过那些"嘴在动但眼神死的"AI数字人没?根子就在这儿。
HappyHorse走了完全不同的路:单流(Single-Stream)统一Transformer架构。
什么意思?
打个比方。两阶段方案像是先拍默片再后期配音——导演(第一阶段)和配音导演(第二阶段)是两个人,各自干活,出了问题互相推。单流架构则像是拍电影时摄影机和收音麦克风同时开着——画面和声音在同一个"创作现场"被生成出来。
技术上,HappyHorse把文本、视频、音频三种Token塞进了同一个Transformer序列里做联合建模。整张网络40层,前后各4层是模态特定层(处理各自模态的输入输出),中间32层全部共享参数——也就是说,画面和声音在32层共享网络里被"搅拌"在一起生成。
结果是:音画从底层就对齐了,不是后期拼接的。
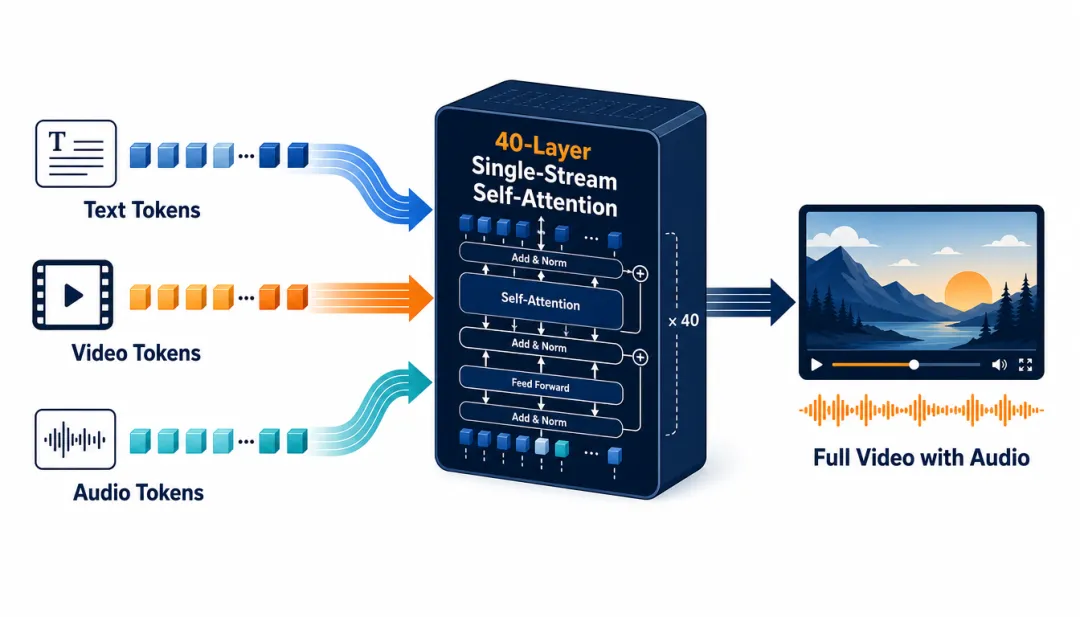 HappyHorse单流统一Transformer架构示意:文本、视频、音频Token在同一序列中联合建模
HappyHorse单流统一Transformer架构示意:文本、视频、音频Token在同一序列中联合建模
对比一下行业现状:
注:Seedance参数规模为行业估算值,官方未披露。
这个架构选择不是拍脑袋决定的。阿里ATH创新事业部的技术负责人张迪,之前是快手可灵AI的负责人——他自己就是"两阶段方案"的亲历者。2025年底跳到阿里后,第一件事就是换路线。你品,你细品。
人话版:张三开过一家两班倒的工厂,知道夜班和白班交接必出岔子。现在他开了新工厂,第一件事就是改成一条流水线干到底。
二、8步推理凭什么?拆解DMD-2蒸馏技术
AI视频生成最耗算力的环节是什么?去噪。
传统的扩散模型需要反复去噪——每一步都要"猜一猜、修正一下",通常需要20步以上才能生成一个能看的视频。每多一步就多一次推理,多烧一次算力。
HappyHorse用了自研的DMD-2蒸馏技术,把去噪步数压缩到了8步。
这里有一个关键细节:DMD-2同时消除了Classifier-Free Guidance(CFG)的依赖。
CFG是扩散模型的"标配"。简单说,CFG需要每次推理跑两次前向传播——一次有条件、一次无条件——然后把两个结果做差值放大。相当于每步都要算两遍,再贵的显卡也扛不住。
DMD-2蒸馏直接把这套"算两遍"的机制训练进了模型参数里。模型自己学会了"什么样的结果是好的",不需要每次推理时再搞条件/无条件的差值对比。
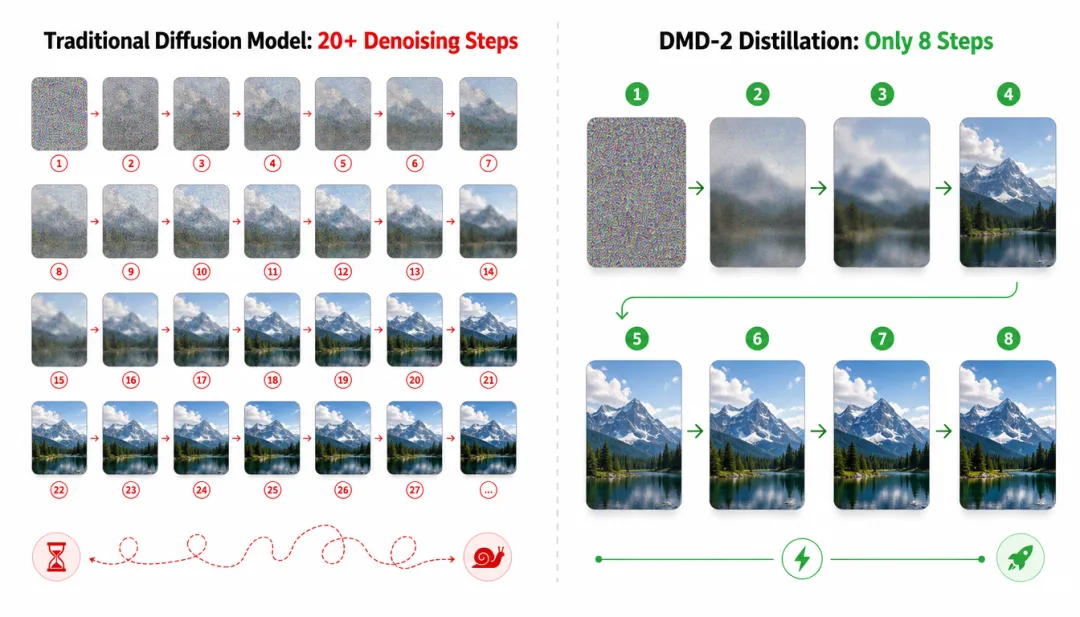 传统扩散模型20+步去噪 vs DMD-2蒸馏仅需8步
传统扩散模型20+步去噪 vs DMD-2蒸馏仅需8步
配合FP8量化优化后,整张NVIDIA H100显卡就能跑完整条1080P视频推理流水线。算力消耗比行业主流模型低了大约60%。
换算成更直观的数字:
Seedance 2.0虽然生成一条5秒视频只要30秒左右,但那是多卡并行,而且排队动辄十来个小时。HappyHorse是单卡,高峰期不降速。
人话版:Seedance像是在高档餐厅——做菜快但排队排到饿死。HappyHorse像是你家楼下的快餐店——不一定比高档餐厅做得好,但你能吃上热乎的。
三、7种语言原生唇形同步,怎么做到的?
多语言唇形同步是AI视频的"照妖镜"——很多模型宣传图很唬人,一开口就露馅。
HappyHorse原生支持普通话、粤语、英语、日语、韩语、德语、法语7种语言的口型同步。关键数据:词错误率(WER)仅14.60%,同类开源模型普遍在19%-40%。
 HappyHorse原生支持7种语言精准唇形同步,词错误率仅14.60%
HappyHorse原生支持7种语言精准唇形同步,词错误率仅14.60%
这靠的不是"给每种语言单独训练一个模型",而是单流架构的天然优势——音频Token和视频Token在同一序列里联合建模,嘴唇的运动和声音的频谱在训练阶段就是"同一条流水线上"的产物。
爱范儿在实测中的描述很形象:
"HappyHorse的对白真的有情境感。语气和语调贴着画面里的情绪,惊讶的时候语调是对的,轻松的时候节奏是松的。多人对话的场景里,听的那一方也是自然,会有表情,有细微的肌肉反应,不是在发呆等下一句。"
这背后其实是同一个技术原理在起作用:单流架构把"说话时的面部表情"和"说话的声音"当成了一个整体来生成,而不是分别生成再对齐。
人话版:传统方案是"画张嘴→贴音频→微调"。HappyHorse是"一边画嘴型一边念台词",嘴唇动的幅度和声调的高低天然匹配。
四、说了这么多优势,缺点呢?
技术文章如果只吹不踩,跟广告没区别。HappyHorse有明显的短板:
1. 最长只有15秒,离"影视级"还远。 Seedance 2.0能做到60秒、4K/60fps。15秒够做短视频和广告,但想做短剧、微电影?远远不够。
2. 音频能力相对偏弱。 Artificial Analysis的含音频赛道,HappyHorse排第二,不如Seedance 2.0。单流架构在纯视觉质量上是断层领先的,但音频生成还在追赶。
3. 闭源。 虽然早期有大量"开源黑马"的宣传,甚至出现了冒牌开源网站(happyhourse.com),但官方已确认HappyHorse 1.0为闭源模型,仅通过云端API和官方平台提供服务。想私有化部署?目前不行。
4. 生态新生。 跟Seedance背靠即梦/TikTok、可灵背着快手的创作者生态比,HappyHorse还在"圈地"阶段。目前已接入千问App、阿里云百炼、万兴剧厂等,但这张网远没织完。
5. 数据质量的隐忧。 36氪引用了前阿里达摩院工程师姜奕祺的观点:HappyHorse参数是Seedance的近三倍,但表现力没有三倍差距,可能与短视频数据和影视级数据的质量差距有关。
五、对普通人来说,这意味着什么?
回到实际问题:这个技术对你有什么用?
第一,AI视频生成的成本正在断崖式下跌。 HappyHorse的会员价最低0.44元/秒,是行业主流定价的60%左右。一条10秒的电商商品展示视频,成本不到5块钱。一年前这个数字是几十到上百元。
 HappyHorse官网提供免费版至专业版三档订阅方案,最低0.44元/秒
HappyHorse官网提供免费版至专业版三档订阅方案,最低0.44元/秒
第二,"能用"的门槛被拉平了。 过去一年,AI视频赛道的竞争逻辑是"谁的模型更强"。HappyHorse的出现改变了一个事实:对80%的普通创作者来说,HappyHorse、Seedance、可灵的画面质量差距,已经小于"谁能让我不排队就用上"的体验差距。当"最强"和"第二强"之间的差距肉眼难辨时,"最低摩擦"就成了第一选择。
第三,技术路线还没收敛。 单流Transformer vs 多模态扩散——这跟当年LSTM vs Transformer的剧情很像。HappyHorse的出现证明"另一条路走得通",这比任何一个单点技术突破都重要。竞争多了,价格就会降,产品就会好用。
对国内创作者的具体建议:
六、技术路线之争,才刚开始
HappyHorse的技术路线选择——单流统一架构、原生音画联合建模、8步蒸馏推理——本质上是在回答一个行业级命题:
AI视频生成的终局,是"画得更像电影"重要,还是"让每个人都能用得起"重要?
Seedance选了前者,HappyHorse选了后者。
但别忘了,这两个方向不是互斥的。当年GPT-3出来的时候,大家争论"大模型 vs 精调小模型"能吵三年。后来OpenAI的选择是:两个都要。
HappyHorse是一个1.0产品。张迪带着从快手可灵积累的经验到阿里,起点已经不低了。如果接下来的迭代能补上"视频时长"和"音频质量"两块短板,这匹小马就不是来抢跑道的,而是来重新画赛道的。
数据来源:阿里云开发者社区(HappyHorse技术文档)、Artificial Analysis Video Arena(2026.4排行榜数据)、36氪、爱范儿、雪球、AIHub.cn
