 夜雨聆风
夜雨聆风AI算力集群基础知识
⁘ 1 AI算力集群必要性
早期的LLM训练都是单卡,比如 2018年:BERT-Large (340M参数) 可以单卡完成训练,但是随着模型参数和语料指数级增加,单卡面临如下3大瓶颈:
1.显存容量不足
一个70B参数的模型,使用FP16存储,仅仅参数就需要140GB,但是单张H100的显存80GB。
2.算力时间压力 训练大模型需要的浮点运算次数(FLOPs)是天文数字,比如GPT-3 175B单张H100大概需要5年才能完成。
3.数据吞吐量 LLM的训练需要海量数据(TB-PB级语料),单卡的IO带宽有限,数据供给跟不上计算。
⁘ 2 两种扩展方式简析
垂直扩展(Scale-up)
定义:一台机器里塞更多GPU(比如8卡HGX),通过NVLink高速互联。
限制:机箱电源、散热、主板尺寸, 最多8张或16张。
水平扩展(Scale-out)
定义:通过交换机、线缆把成百上千台服务器连起来。
限制:网络带宽和延迟 成为新瓶颈。
现代AI集群都是混合方式: 强Scale-up(单节点8卡) + 大规模Scale-out(千卡/万卡以上)。
⁘ 3 AI算力集群架构图
算力集群架构图如下:
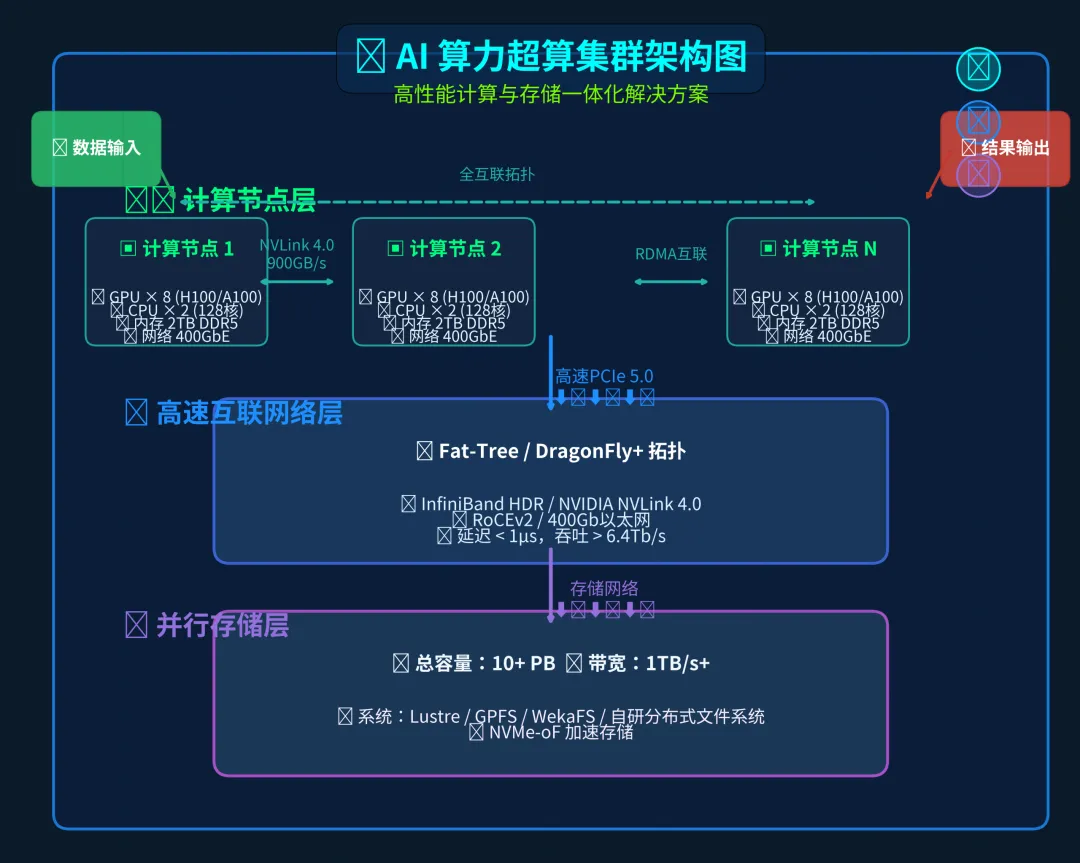
基本组成部分:
| 计算节点 | |
| 高速网络 | |
| 并行文件系统 |
在后续章节会单独介绍每个核心模块。
⁘ 4 AI算力集群全球主要玩家
在AI算力领域Navida一家独大,华为昇腾自研整个体系是国产替代的主力,谷歌本身通过自研TPU用于训练自身的大模型。
Navida能形成垄断地位不仅是产品的先进,CUDA生态绑定全球开发者和AI框架才是最主要的因素。
