 夜雨聆风
夜雨聆风字数 3707,阅读大约需 19 分钟
想象这样一个场景:
凌晨三点,你的手机突然被报警信息轰炸。用户的 AI 聊天机器人突然变得"胡言乱语",成本比昨天飙升了 300%。技术团队紧急排查,却发现根本不知道问题出在哪里——
是提示词被恶意注入了吗?是某个用户触发了无限循环调用?还是上游模型提供商突然发了"疯"?
更让人崩溃的是,当你试图追溯问题时,发现日志散落在各处,根本拼凑不出完整的对话过程。每个 API 提供商都有自己独立的 Dashboard,账单也是分开的,你甚至无法准确计算出每个用户的真实使用成本。
这正是无数 AI 应用开发者正在经历的"至暗时刻"。
今天,我要向你介绍一个正在改变这一切的开源神器——Helicone。它就像是为 AI 应用量身打造的"超级监控中心",让失控的 AI 重新变得可控、透明、可优化。
一、先说说什么是 LLM 网关?
在深入了解 Helicone 之前,让我们先聊聊什么是 LLM 网关。
打个比方:假设你是一家餐厅的经理,你需要从多个供应商采购食材——有的供应蔬菜,有的供应肉类,有的供应调料。如果每个供应商都有自己的送货方式和账单格式,你每天光是协调这些就要疯掉。
LLM 网关就是这个问题的解决方案。它就像一个"超级采购员",你只需告诉它你需要什么菜,它会自动从最合适的供应商那里采购,还会帮你记录每笔支出、分析成本、确保供货稳定。
简单来说,LLM 网关就是一个中间层,让你可以用一个统一的接口,管理所有的大语言模型服务。
没有网关时,你的应用要对接 10 个模型提供商,就需要维护 10 套代码逻辑。有网关之后,只需要调用一个端点,网关自动帮你路由到合适的模型。
二、Helicone 是什么?
Helicone 是一个开源的 LLM 可观测性平台,但它不仅仅是"观测"那么简单——它同时具备强大的AI 网关能力。
用更接地气的话说:Helicone 就像是给 AI 应用装上了一个"智能大脑"和"透视眼"。它能帮助你:
• 一个入口访问 100+ 个 AI 模型(OpenAI、Claude、Gemini 等) • 实时监控每一笔 API 调用的细节 • 自动追踪成本,发现异常支出 • 在模型提供商出问题时代替自动切换 • 深入分析用户行为和模型表现
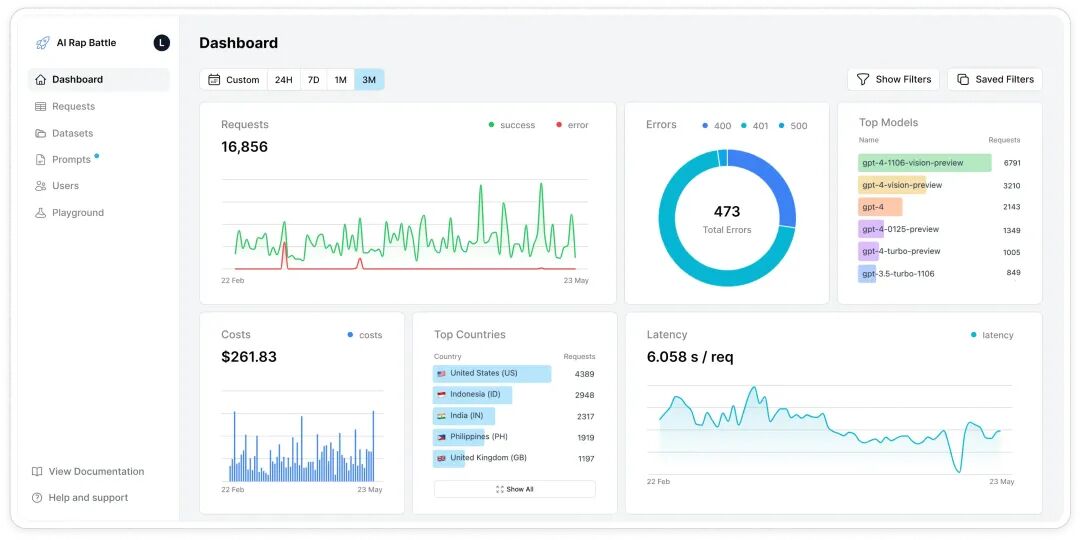
Helicone 的仪表盘让你一目了然地掌握 AI 应用的全貌
截至目前,Helicone 已经:
• 处理了超过 21 亿次请求 • 分析了超过 2.6 万亿个 Token • 获得了超过 5600 个 GitHub Stars • 被众多顶级 AI 公司采用
三、为什么需要 Helicone?—— 真实痛点大揭秘
痛点一:API 密钥满天飞,管理混乱
现在的 AI 开发团队,往往需要同时使用 OpenAI、Anthropic、Google Azure 等多个服务。每个服务都有自己的 API 密钥,代码里可能散布着十几个密钥。
这不是开玩笑——很多公司的 AI 项目,API 密钥直接硬编码在代码里,或者写在配置文件里明文存储。一旦密钥泄露,损失可能是灾难性的。
Helicone 的解决方案:密钥集中管理
你只需要在 Helicone 平台配置一次密钥,之后所有通过 Helicone 的调用都会自动携带正确的认证信息。你甚至可以设置不同的密钥对应不同的项目或客户,实现完全的隔离。
痛点二:成本像"脱缰的野马"
AI API 的费用是按 Token 计费的,而 Token 的消耗往往超出预期。以下是几种常见的"烧钱"场景:
• 无限循环调用:一个 Bug 导致同一段提示词被重复发送了 1000 次 • 提示词过长:开发者没注意到上下文窗口的大小,每次请求都带上了大量冗余的历史记录 • 用户恶意刷 API:某些用户可能有意或无意地频繁调用,消耗大量资源 • 模型选择不当:用 GPT-4 来回答"今天天气怎么样"这种简单问题
Helicone 的解决方案:智能缓存 + 速率限制
Helicone 内置的智能缓存功能可以自动识别相同的请求,直接返回缓存结果——不仅节省成本,还大幅降低响应延迟。有用户反馈,使用缓存功能后节省了相当于 386 小时的 API 调用时间。
同时,你可以针对不同用户、不同端点设置速率限制,再也不用担心某个"大客户"把你的 API 配额瞬间耗尽。
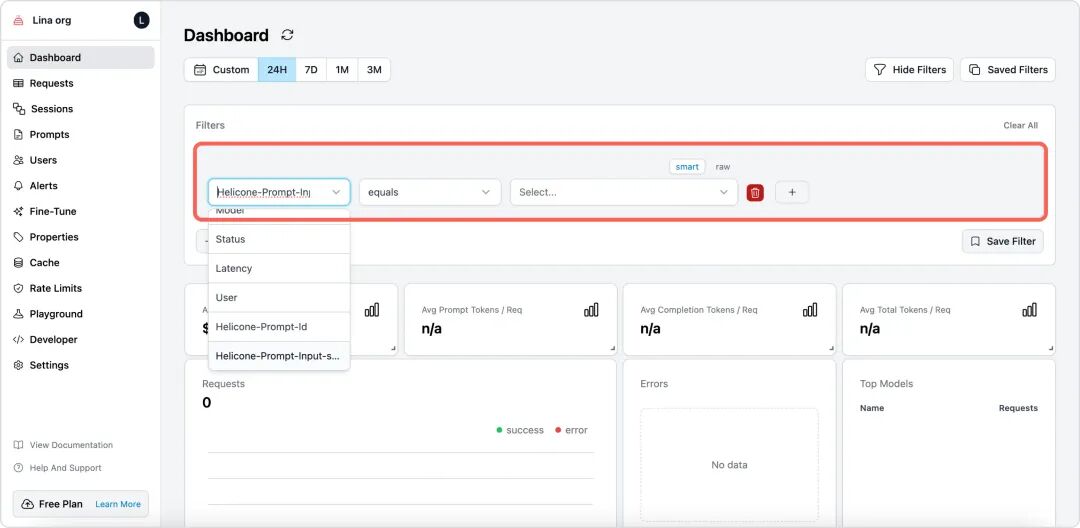
Helicone 的成本分析让你清楚地知道每一分钱花在哪里
痛点三:模型"罢工"时束手无策
你有没有遇到过这种情况:OpenAI 的服务突然不稳定,你的整个应用跟着瘫痪,用户的请求全部失败,而你除了等待什么都做不了。
这在 AI 应用的生产环境中是一个致命的问题。
Helicone 的解决方案:自动故障转移
Helicone 支持设置"故障转移链"。当一个模型提供商响应缓慢或不可用时,系统会自动切换到备选的模型。打个比方:
gpt-4o/openai → claude-sonnet-4/anthropic → gemini-2.0-flash/google你只需配置一次,之后的路由和切换全部由 Helicone 自动完成。根据官方数据,这个自动故障转移功能达到了 99.99% 的可用性。
痛点四:调试 AI 应用如同"大海捞针"
AI 应用的一个独特挑战是:输出是非确定性的。同样的输入,每次运行可能得到不同的输出。
当你发现模型返回了一个"奇怪"的结果时,如何定位问题?你可能需要:
• 回顾发送给模型的完整提示词 • 检查模型的历史对话上下文 • 分析工具调用的执行过程 • 对比不同模型、不同版本的输出差异
没有好的工具,这简直是在黑暗中摸索。
Helicone 的解决方案:完整的请求追踪
Helicone 提供了强大的会话(Session)管理功能。你可以:
• 看到多轮对话的完整历史 • 追踪每个请求的详细参数和响应 • 分析工具调用的执行结果 • 对比不同提示词版本的效果
Helicone V2 的会话功能让你完整回放 AI 的"思维过程"
四、Helicone 核心功能详解
4.1 AI 网关:一站式模型管理
Helicone 的 AI 网关功能让它不仅仅是一个监控工具,更是一个强大的基础设施。
核心特性:
| 100+ 模型支持 | |
| 0% 加价 | |
| 统一 API | |
| 自动路由 | |
| 故障转移 |
使用示例(Python):
from openai import OpenAIclient = OpenAI( base_url="https://ai-gateway.helicone.ai", api_key=os.getenv("HELICONE_API_KEY"))# 自动路由到最合适的模型response = client.chat.completions.create( model="gpt-4o-mini", messages=[{"role": "user", "content": "Hello, world!"}])看,只需要把 base_url 改成 Helicone 的地址,你就可以:
• 访问所有支持的模型 • 自动获得完整的日志记录 • 享受故障转移保护 • 获得统一的使用分析
4.2 智能缓存:省钱的艺术
Helicone 的缓存功能不是简单的"相同请求返回相同结果",而是基于语义相似性的智能缓存。
这意味着,即使你的用户用不同的措辞问同一个问题,系统也能识别出它们的语义相近,从而返回缓存结果。
缓存的实际效果:
• 重复性查询:节省高达 70% 的成本 • 首次响应时间:降低 50% 以上 • API 负载:减少 60% 以上
4.3 可观测性面板
Helicone 的仪表盘提供了全面的 AI 应用状态视图:
请求概览:
• 总请求量、成功/失败率 • 按时间/用户/模型的分布 • 异常请求的自动标记
成本追踪:
• 按天/周/月的成本趋势 • 按模型/用户/功能维度的成本分解 • 预算超支预警
性能监控:
• 响应时间分布 • Token 消耗统计 • 首次 Token 时间(TTFT)追踪
用户行为分析:
• 用户级别的使用量排行 • 使用模式的可视化 • 异常用户检测
4.4 提示词管理(Prompts)
Helicone 提供了强大的提示词管理功能:
• 版本控制:记录每个提示词的历史变更 • 模板复用:创建可复用的提示词模板 • 环境隔离:开发环境和生产环境使用不同版本 • A/B 测试:同时运行多个版本的提示词,对比效果
4.5 HQL 查询语言
HQL(Helicone Query Language)是一个专为 AI 日志设计的查询工具。类 SQL 但更简洁:
// 查找所有成本超过 $1 的请求SELECT * FROM requests WHERE cost > 1.0// 查找某个用户的完整会话SELECT * FROM requests WHERE user_id = "user_123" GROUP BY session_id// 分析模型的响应延迟SELECT model, avg(latency) FROM requests GROUP BY modelHQL 的强大之处在于:即使处理数十亿条记录,查询速度依然保持在秒级。
五、5 分钟快速上手
Helicone 的设计理念是:简单到极致。
第一步:注册账号
访问 helicone.ai,点击"Try for free",用邮箱注册一个账号。免费计划每月提供 10,000 次请求,足够进行开发和测试。
第二步:获取 API 密钥
登录后,在设置页面生成一个新的 API 密钥。记住选择"只写"权限,保证安全性。
第三步:修改一行代码
假设你当前使用的是 OpenAI 的 Python SDK:
# 原来的代码from openai import OpenAIclient = OpenAI()# 改成 Heliconefrom openai import OpenAIclient = OpenAI( base_url="https://ai-gateway.helicone.ai", api_key="your_helicone_api_key")是的,就是这么简单!你的所有 API 调用现在都会经过 Helicone,自动记录日志、提供缓存、实现故障转移。
第四步:查看仪表盘
打开 Helicone 的 Dashboard,你会看到:
• 每一次 API 调用的详细记录 • 成本分析和使用趋势 • 性能监控和异常告警 • 用户行为分析
Helicone 的引导界面让你快速上手
六、实际应用场景
场景一:SaaS AI 产品
如果你正在构建一个 AI 驱动的 SaaS 产品,Helicone 可以帮助你:
• 多租户隔离:每个客户的 API 使用量独立统计 • 成本分摊:准确计算每个客户的使用成本 • 速率限制:防止某个客户的异常请求影响整体服务 • 统一账单:合并多个模型提供商的费用
场景二:AI Agent 应用
对于 AI Agent 项目,Helicone 提供了:
• 会话追踪:完整记录 Agent 的多轮对话和决策过程 • 工具调用审计:追踪每一次工具调用的输入输出 • 异常检测:发现 Agent 的"奇怪"行为 • 性能优化:分析哪个环节最耗时
场景三:企业级 AI 平台
企业用户可以享受:
• SOC-2 认证:符合企业安全标准 • 本地部署:数据不出自己的数据中心 • SAML SSO:与企业身份系统集成 • 专属支持:有专门的技术支持团队
七、定价:免费也能用得很爽
Helicone 的定价策略非常友好:
| Hobby | ||||
| Pro | ||||
| Team | ||||
| Enterprise |
即使是最基础的免费方案,也包含了:
• 基本监控仪表盘 • 缓存功能 • 1 个用户/1 个组织 • 社区支持
对于个人开发者或小型项目来说,这个免费额度已经相当充足。
八、与竞品对比
在 LLM 可观测性领域,主要的竞品包括 LangSmith、Braintrust、Arize AI、Langfuse 等。
Helicone 的独特优势:
1. 开源:代码完全透明,你可以自行部署和修改 2. 网关一体化:不只是监控工具,更是基础设施 3. 0% 加价:使用成本透明,没有隐藏费用 4. UI 友好:界面直观易用,学习成本低 5. 故障转移:内置的高可用性机制
九、未来展望
Helicone 正在快速发展。V2 版本的发布带来了:
• 更强大的评估功能:支持 LLM-as-judge 评估方式 • 实验框架:让你轻松进行提示词 A/B 测试 • 基础设施升级:基于 Kafka 和 ClickHouse 的高可用架构
团队表示,未来将继续:
• 支持更多模型提供商 • 增强企业级功能 • 优化性能,降低延迟 • 扩展社区和生态
十、结语
AI 应用的开发和运维,面临着独特的挑战。传统的监控工具无法满足 AI 应用的需求——我们需要更智能、更深入的可观测性。
Helicone 正是为解决这些问题而生的。它不仅是一个监控工具,更是一个完整的 AI 网关解决方案。通过一个统一的平台,你可以:
• 管理所有模型提供商 • 监控每一次 API 调用 • 控制成本,防止异常 • 确保服务高可用 • 深入分析用户行为
无论你是个人开发者,还是大型企业,Helicone 都能为你的 AI 应用保驾护航。
资源链接
• 🌐 官网:https://www.helicone.ai • 📚 文档:https://docs.helicone.ai • 💻 GitHub:https://github.com/helicone/helicone • 💬 Discord:https://discord.gg/2TkeWdXNPQ • 💰 定价:https://www.helicone.ai/pricing
如果这篇文章对你有帮助,欢迎转发给需要的朋友!也欢迎在评论区分享你的 AI 开发经验。
