 夜雨聆风
夜雨聆风| ⭐️⭐️⭐️更文不易,点个关注呗⭐️⭐️⭐️ |
在生成式AI与大模型应用加速落地的背景下,AI推理正从“模型能力验证”走向“规模化生产服务”。相比训练阶段,推理对时延、并发与成本提出了更严苛且长期的要求。随着系统规模扩大,性能瓶颈也从单点算力转向系统级协同,尤其是网络与互联架构的重要性愈发凸显。
理解推理负载特征,并在算力与网络之间取得平衡,成为构建高性能、可扩展AI基础设施的关键。

(图采用chatGPT对话窗口绘制,直接由文字生成)
一、AI训练负载定义?
AI推理负载,是指模型将训练阶段学到的知识应用于全新数据,进而生成预测、决策或业务输出的过程,例如大语言模型生成文本、图像识别模型完成目标检测。随着生成式 AI、大语言模型(LLM)与实时智能应用快速发展,市场对推理业务的需求正在迅猛增长。
在此背景下,推理系统必须同时满足低时延、高并发、成本可控三大要求。随着部署规模扩大,系统性能不再仅依赖算力提升,节点间数据传输效率变得愈发关键。因此优化 AI 推理负载,不仅要关注计算资源,更需搭建高性能网络与高效互联架构,支撑整体业务性能与可扩展性。
二、AI训练负载与AI推理负载对比
在AI基础设施实际设计中,训练与推理的核心差异主要体现在算力需求与成本结构两方面。如需更完整对比,可参考文章:训练与推理:为何AI网络架构需要差异化设计。
1. 算力需求差异
AI 训练是典型算力密集型负载,需要处理海量数据集并持续更新模型参数,对算力、并行能力与吞吐能力要求极高。此类场景通常依赖通用 GPU 架构,实现高吞吐与大规模并行计算;同时训练过程存在频繁梯度同步,对网络带宽与时延均有极高要求。
反观 AI 推理,更强调响应效率与服务稳定性。单条请求计算量偏小,但请求量大且持续并发,对端到端系统时延更为敏感。在此背景下,推理场景已大量采用专用推理芯片,例如谷歌 TPU、亚马逊 Inferentia2、Groq LPU。这类硬件经过定制优化,在能效与响应速度上具备明显优势。
核心要点AI 推理性能并非仅由算力决定。即便配备专用推理硬件,节点间数据传输效率仍会影响整机系统表现,网络架构设计始终是决定推理性能的关键因素。
2. 成本结构差异
AI 训练属于阶段性投入。模型训练往往集中在固定周期内,以数天或数周高强度计算为主,核心目标是尽快实现模型收敛。训练阶段成本多为一次性或分期投入,优化方向主要是缩短训练周期、提升算力利用率、优化资源调度效率。
训练 vs 推理 成本对比
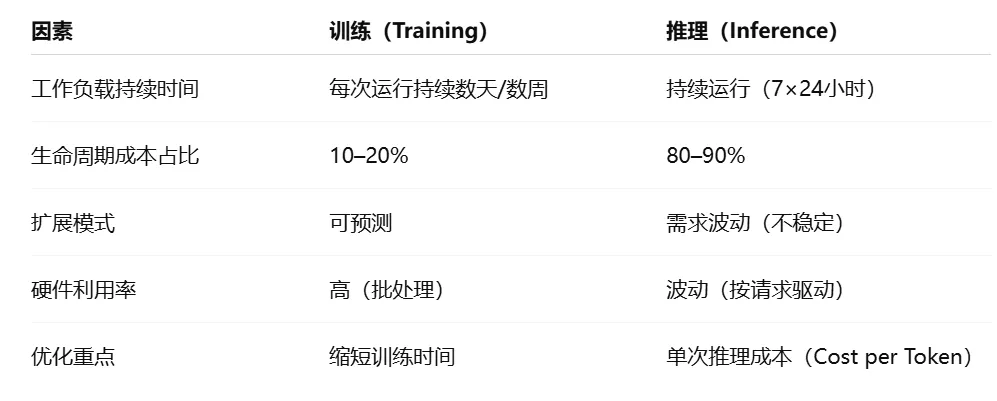
AI 推理则具备完全不同的成本特征:推理系统需要长期不间断运行,持续承接业务请求。每一次用户请求、每一次模型调用,都会不断消耗算力与电力资源。这意味着模型训练完成并不代表成本终止,反而会随业务规模扩张持续累加。
核心要点在大规模 AI 推理集群中,节点间存在频繁通信与数据交互,网络设备及互联方案将成为整体成本的重要组成部分。
三、AI推理负载的网络挑战
随着推理规模扩张,网络在系统中的定位已从辅助支撑,转变为必须重点规划的核心环节。实际部署中,AI 推理的网络难题主要集中在时延、吞吐、成本三大维度。如需了解大规模推理系统全貌,可参阅延伸阅读:《大规模AI推理负载的五大核心挑战》。
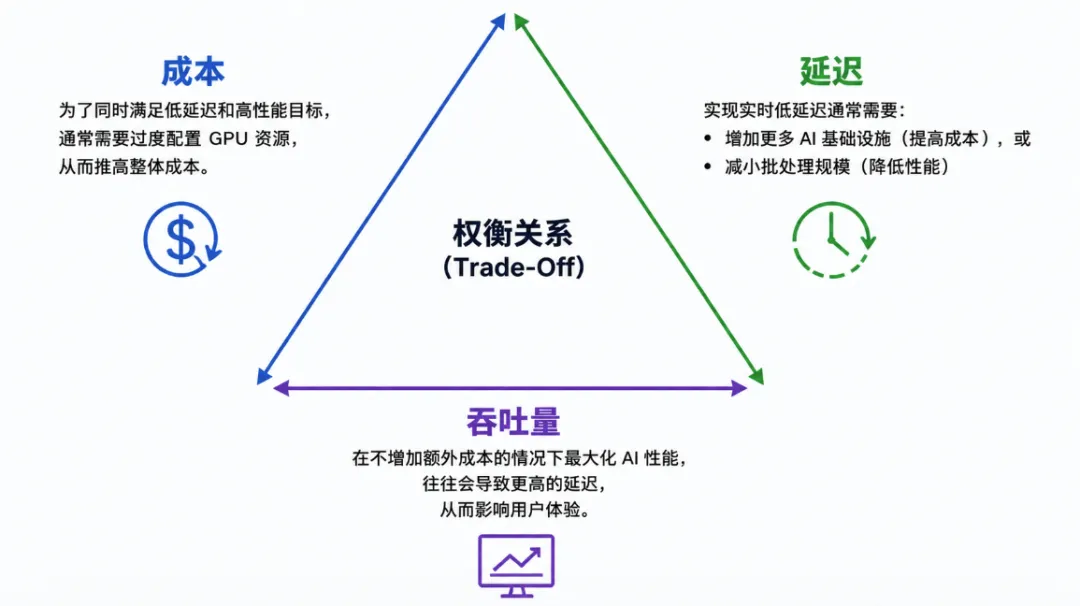
1. 时延
时延是最直观、最敏感的痛点。在实时推理场景中,系统需在极短时间内响应用户请求,整体时延不仅取决于计算流程,还受制于节点间数据传输耗时。主要影响因素包括:
网络路径过长、拓扑架构设计不合理 拥塞控制机制不完善 丢包引发重传带来额外开销
在模型并行、流水线推理等多节点协同架构中,每一次跨节点通信都会叠加时延。若网络稳定性不足,不仅时延整体抬高,还会产生明显抖动,破坏服务体验的一致性。
2. 吞吐
吞吐问题主要凸显在高并发推理场景。当系统需同时处理海量请求时,网络必须具备充足带宽承载业务流量。常见问题包括:
带宽不足导致请求队列拥堵堆积 流量突发引发网络拥塞 高负载下整体响应时间显著上升
实际环境中,吞吐与时延相互耦合:网络负载接近极限时,时延通常同步攀升。因此仅靠扩容带宽无法根治问题,必须搭配流量调度与拥塞控制做联合优化。
3. 成本
成本贯穿 AI 推理系统全生命周期,是网络设计不可回避的约束条件。主要体现在:
不同网络设备与技术方案的初始投资差异 不同互联架构带来的功耗成本差异 布线复杂度提升导致运维成本增加
AI 推理基础设施属于长期固定资产,规模化部署后,网络方案带来的成本差距会被进一步放大。
综上,AI 推理负载的挑战早已跳出单一算力维度。随着集群规模增大,系统性能越来越依赖集群内部高效数据流转。优化推理负载,必须从 “单纯提升算力” 升级为系统级优化:既要合理分配计算资源,也要结合业务负载特征选型适配的网络架构与互联方案。简言之,网络不再是底层配套,而是直接决定推理效率与整体成本结构的核心底座。
四、AI推理负载的优化策略
1. 网络选型:InfiniBand vs RoCE
当前 AI 推理集群主流高性能网络方案为 InfiniBand 与 RoCE(RDMA over Converged Ethernet)。InfiniBand 具备超低时延、超高带宽,拥塞控制体系成熟,在对性能与稳定性要求极高的推理场景优势显著。
RoCE 则在以太网架构上承载 RDMA,其中 RoCEv2 应用最广。RoCEv2 兼容性强、更易控制成本,但性能高度依赖无损网络的设计与优化能力。
二者在 AI 推理场景的核心差异:
带宽与时延:InfiniBand 在时延控制与带宽利用率上更占优,适配性能敏感型推理任务;RoCEv2 经合理配置可满足绝大多数通用推理场景。
兼容性与成本:InfiniBand 依赖专用硬件,整体投入更高;RoCEv2 基于标准以太网,设备选型与架构演进更灵活,利于控制总体拥有成本。
配置复杂度:InfiniBand 网络架构相对封闭,配置运维更简洁;RoCEv2 需精细化部署无损网络,才能保障性能与稳定性。
生态与供应链:InfiniBand 硬件生态厂商高度集中;RoCEv2 多厂商兼容支持,供应链与选型空间更大。
在 AI 推理负载中,InfiniBand 与 RoCE 并非简单替代关系,而是面向不同性能与成本目标的差异化选择:前者适合低时延、高确定性要求的极致推理集群;后者更易兼容现有以太网基建,具备部署成本可控的优势。
核心要点,实际落地中,AI 推理负载优化不仅取决于网络类型,更要结合业务规模与架构设计,匹配合适的互联解决方案。
2. 互联介质选型:DAC/AOC/ 光模块
无论服务器对接交换机、机架内节点互联,还是机架间骨干链路搭建,为 AI 推理集群选择合适互联介质至关重要,主流分为 DAC、AOC、光模块三类。
DAC 多用于机架内短距互联,成本更低但传输距离有限;AOC 在传输距离与抗干扰之间取得平衡,适合机架间互联;光模块适配更长距离与复杂布线场景,灵活性更高但整体成本偏高。
大规模 AI 推理集群通常不全网统一单一介质,而是按链路层级组合部署,在性能、布线复杂度与总体拥有成本之间取得平衡。分层策略可让企业在不同网络层级匹配最优性价比组合,而非盲目追求全局单一方案最优。合理的推理互联设计应服务整体架构目标:满足当前负载、预留扩容空间,避免非核心环节过度投资。
五、结束语
随着AI应用从训练走向大规模推理部署,AI 推理负载已成为数据中心核心关键业务。仅靠单纯提升算力,已无法同时满足性能与成本双重诉求,网络也从 “辅助角色” 升级为核心基础设施。时延、吞吐、成本构成推理网络设计三大核心维度。AI 推理负载优化本质是系统级工程:既要做强算力底座,更要搭建高性能、可扩展、成本最优的网络与互联架构。
