 夜雨聆风
夜雨聆风很多人第一次听到 Hermes Agent,会很容易兴奋。
因为它听起来不像一个普通聊天工具,更像一个可以长期工作的 AI 工作台:能记住偏好,能调用工具,能接入聊天软件,能定时执行任务,还能用多个 profile 分工协作。
但我反而建议:第一天别急着搭 AI 军团。
先让一个 Hermes 稳定工作。
这比一上来就接 Telegram、飞书、Cron、Kanban、本地模型更重要。
不然最常见的情况是:安装命令能跑,模型也配了,但一到 token、profile、base URL、session 恢复、工具权限,就开始怀疑是不是自己不会用。
其实不是你不会用。
是这类 Agent 工具本来就不该用“装完就开冲”的方式上手。
第一,先搞清楚:Hermes 不是一个模型
先别把 Hermes Agent 和 Hermes 模型混在一起。
它们名字相近,但不是一回事。
你可以把 Hermes Agent 理解成一个 AI 工作台 / Agent runtime。
模型只是“大脑”。
Hermes 负责的是大脑之外那些更麻烦、但也更实用的东西:
会话能不能接着聊; 偏好和经验能不能记住; 常用流程能不能沉淀成 Skill; 能不能调用终端、文件、浏览器等工具; 能不能通过 Gateway 接入聊天软件; 能不能用 Profile 做不同角色分工; 能不能用 Cron 和 Kanban 做长期任务。
所以它不是“又一个聊天窗口”。
更像是:给你的 AI 助手安排了一张长期办公桌。
桌上有笔记本,有工具箱,有任务板,也有消息入口。
第二,第一天不要急着做这 3 件事
很多新手一上来就想一步到位。
比如:
同时接 Telegram、Discord、Slack、飞书; 立刻创建 coder、reviewer、researcher 多个 profile; 直接接 Ollama、vLLM 这类本地模型。
这些都不是不能做。
但不建议第一天做。
因为任何一个 bot token 填错,一个 profile 切错,一个本地模型 endpoint 写错,你就会花半天时间排错。
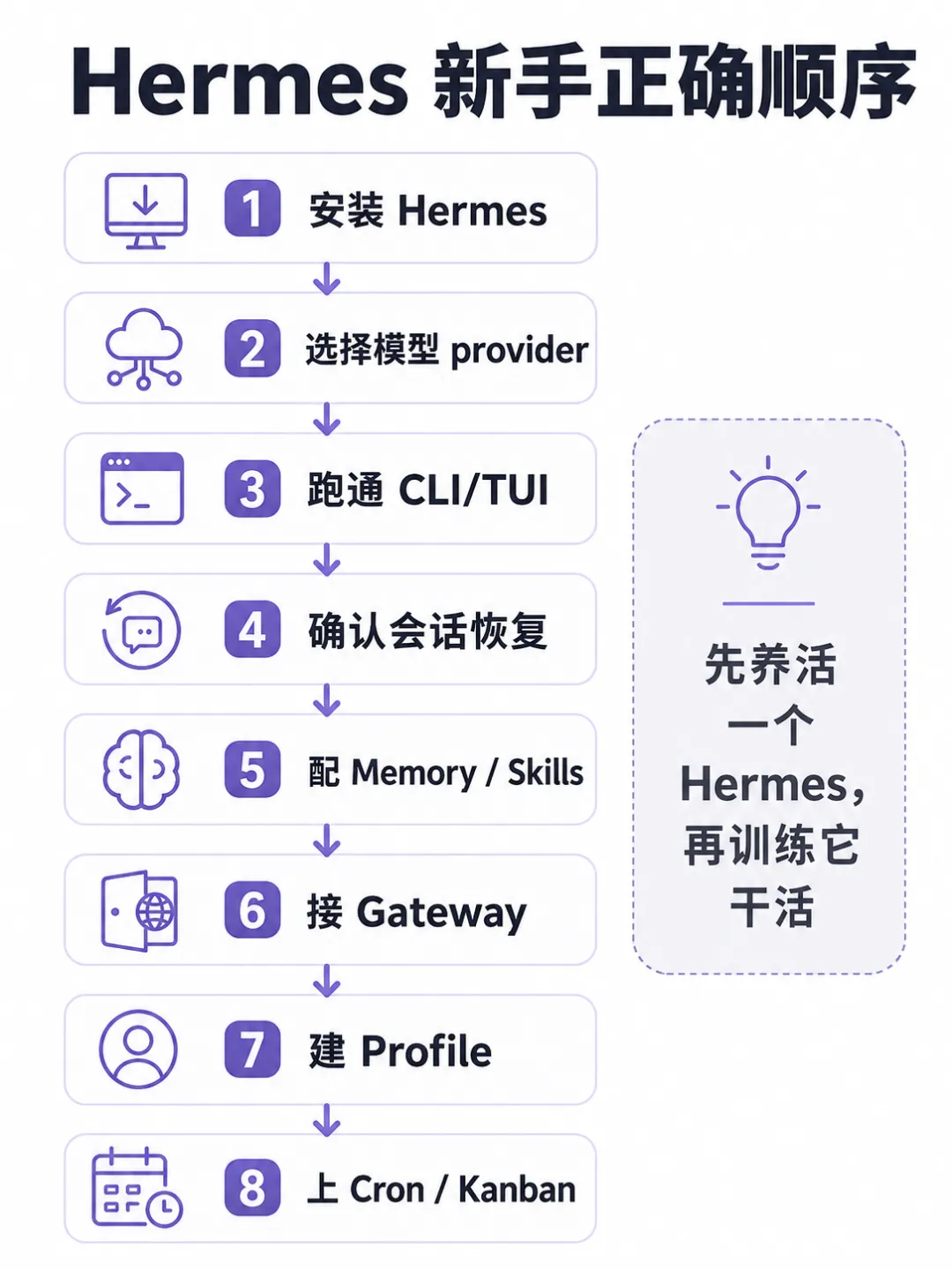
更稳的顺序是:
先安装 → 再接模型 → 跑通 CLI/TUI → 确认会话能恢复 → 再配 Memory / Skills → 最后再上 Gateway、Profile、Cron、Kanban。
一句话:
先养活一个 Hermes,再训练它干活。
第三,先把 Hermes 装起来
如果你是 macOS、Linux 或 WSL2,可以用官方安装脚本:
curl -fsSL https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.sh | bash如果你是 Windows,现在也可以走原生安装路径。PowerShell 里执行:
powershell -NoProfile -ExecutionPolicy Bypass -Command "iwr https://raw.githubusercontent.com/NousResearch/hermes-agent/main/scripts/install.ps1 -UseB | iex"这里提醒一句:Windows Native 现在已经可用,但仍然更偏 beta。
如果你只是想把 Hermes 跑起来,可以直接试 Windows 原生安装。
如果你要重度开发、长期自动化,或者工具链比较复杂,WSL2 仍然是更稳的选择。
安装完成后,macOS / Linux 通常需要重载 shell:
source ~/.zshrc
# 或者
source ~/.bashrcWindows 用户直接重新打开一个 PowerShell 窗口即可。
然后先检查版本:
hermes --version再跑一次环境检查:
hermes doctor最后看一下帮助入口:
hermes --help这一步不要省。
Hermes 更新很快,很多旧教程不是完全错,而是版本已经变了。
你先看一眼当前版本支持哪些入口,后面排错会轻松很多。
第四,先接一个稳定模型
Hermes 不是模型,所以必须先接 provider。
入口通常是:
hermes model官方支持的 provider 很多,比如 Nous Portal、OpenRouter、OpenAI Codex、Anthropic、Kimi、Qwen、DeepSeek、Hugging Face、AWS Bedrock、GitHub Copilot、Vercel AI Gateway,以及自定义 OpenAI-compatible endpoint。
第一次用,不要追求最花哨。
我的建议是:
已经有稳定 API Key,就先用现成的; 不知道选什么,可以先试 OpenRouter 或 Nous Portal; 想用国内模型,可以先试 Kimi / Qwen / DeepSeek; 想用本地模型,建议等 CLI 跑通后再接 Ollama / vLLM。
还有一个条件很重要:
Hermes 要求模型至少 64K context。
因为 Agent 不只是聊天,它还要带工具、历史、记忆、任务状态。
上下文太小,跑复杂任务时很容易“半路失忆”。
模型配完后,先不要急着接聊天软件。
先在本地确认它能正常说话:
hermes --tui或者用经典 CLI:
hermes第一条测试不要问太大的问题。
可以问一个能验证工具能力的小任务:
请检查当前目录,告诉我这里最像主项目入口的 5 个文件,并说明你的判断依据。如果它能正常回复、能调用工具、追问第二轮也不断线,才算真正跑通。
第五,确认它能“接着干”
普通聊天工具最大的问题是:今天教会它,明天又忘。
Hermes 的价值之一,就是会话可以延续。
跑完一个简单会话后,退出,再试:
hermes --continue或者:
hermes -c如果它能回到刚才的上下文,说明 sessions 基础正常。
如果恢复不了,先查:
hermes sessions list很多人以为是 memory 坏了,其实只是切了 profile,或者 session 没保存。
第六,别把配置文件放乱
Hermes 的配置不算难。
真正容易出问题的是:把所有东西都塞进一个地方。
新手可以先记住这几个位置:
~/.hermes/.env:放 API Key、bot token 等密钥; ~/.hermes/config.yaml:放普通配置,比如默认模型、工具开关、Gateway 配置; ~/.hermes/SOUL.md:放稳定人格和硬规则; ~/.hermes/memories/MEMORY.md:放环境事实、项目习惯、踩坑记录; ~/.hermes/memories/USER.md:放用户偏好; 项目里的 AGENTS.md:放项目级规则,比如怎么测试、哪些目录不能动。
新手第一版 SOUL.md 不用写很长。
几行就够:
# Hermes 行为规则
不确定的命令、路径、配置,先查再答。
三步以上任务先列计划。
高危操作先说明风险,不要直接执行。
完成任务后告诉我怎么验证。
临时猜测不要写进长期记忆。别一上来写两千字人设。
写太满,后面你自己都不知道是哪条规则在起作用。
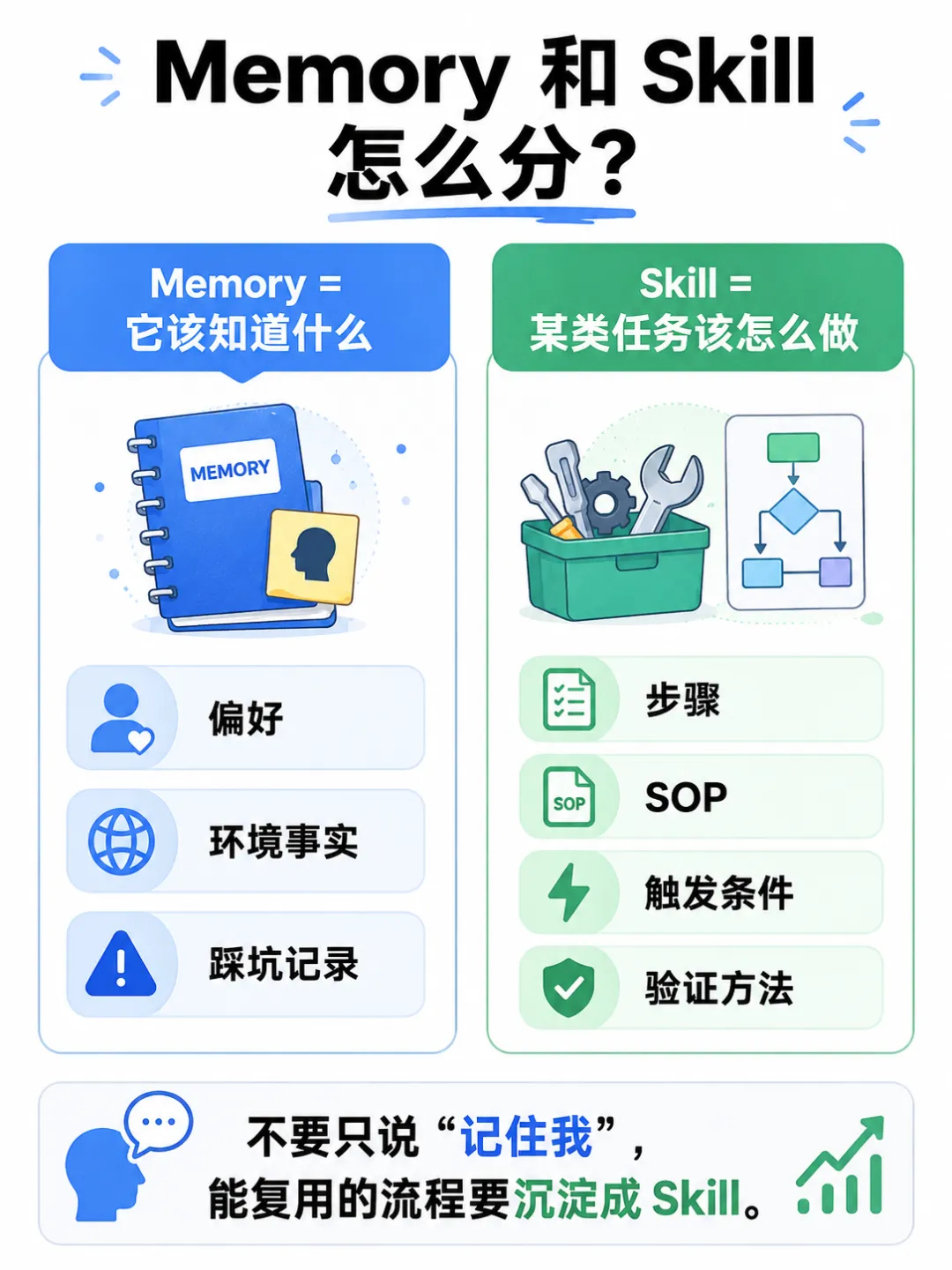
Memory 和 Skill,不是一回事
这是 Hermes 很关键的一点。
Memory 记事实和偏好。
比如:
以后整理 AI 工具更新时,保留英文产品名、原始链接和 Markdown 格式。这种适合写进 Memory。
Skill 记流程和 SOP。
比如:
每次生成 AI 工具日报时,先抓 AI hot,再看 X 热门推文,
再按 agent / coding / video / image / infra 分类,最后给出 5 个可写选题。这种更适合沉淀成 Skill。
你可以这样理解:
Memory = 它该知道什么。
Skill = 某类任务该怎么做。
一个任务做顺了,不要只说“记住我”。
可以直接让它保存成 Skill:
我们刚才这个流程以后会反复用。
请把它保存成一个 Skill,包含触发条件、执行步骤、注意事项和验证方法。保存后再检查:
hermes skills list外部技能也可以搜索、查看和安装:
hermes skills search github
hermes skills inspect <skill-name>
hermes skills install <skill-name>如果技能越来越多,还可以用 Curator 做清理:
hermes curator status
hermes curator run把它理解成技能库保洁员就行。
等 CLI 稳了,再接 Gateway
当本地 CLI / TUI 已经跑通,再考虑让 Hermes 出现在聊天软件里。
入口一般是:
hermes gateway setup
hermes gateway run本地测试阶段,gateway run 更直观。
它在前台运行,报错能直接看到。
稳定后,再装成后台服务:
hermes gateway install
hermes gateway start
hermes gateway status接平台时也别贪多。
个人使用,Telegram 或 Discord 通常比较快。
团队协作,飞书会更顺手。
判断 Gateway 是否成功,不是看服务有没有启动,而是看你能不能在聊天软件里给 Hermes 发消息,并收到回复。
第一条消息可以很简单:
请回复一句话,说明你已经通过当前聊天平台接入 Hermes。第二条再测试记忆:
请记住,以后我从这个聊天入口让你整理资料时,默认输出 Markdown,并保留原始链接。第二天换一种说法让它做同类任务,看它有没有沿用偏好。
这样才算测到了 Gateway + Memory 的组合能力。
Profile 很强,但它不是沙箱
很多人说多 Agent,其实第一步是多个 profile。
Profile 是独立 Hermes home。
每个 profile 都有自己的配置、密钥、记忆、会话、skills、cron jobs 和状态数据库。
比如创建一个写代码助手:
hermes profile create coder --clone
coder setup
coder chat再创建一个审查助手:
hermes profile create reviewer --clone
reviewer setup
reviewer chat--clone 的意思是复制当前配置、密钥和 SOUL,但给新 profile 一套新的 sessions 和 memory。
如果想完整复制,包括记忆、会话、skills、cron,可以用:
hermes profile create backup --clone-all但这里有一个坑:
Profile 不是 sandbox。
它隔离的是状态,不是文件权限。
默认 local terminal backend 下,它仍然会以当前用户身份访问文件系统。
所以要记住一句话:
Profile 管身份和状态,Sandbox 管权限和边界。
如果你想限制它只能在某个项目里工作,要设置 terminal.cwd。
如果你想限制命令执行环境,就要考虑 Docker、SSH、Modal、Singularity 这类 backend。
Docker、Kanban、Cron:先知道它们解决什么
Docker 有两种用法。
第一种,是把 Hermes 本体跑在 Docker 里,适合长期部署:
mkdir -p ~/.hermes
docker run -it --rm \
-v ~/.hermes:/opt/data \
nousresearch/hermes-agent setup后台跑 Gateway:
docker run -d \
--name hermes \
--restart unless-stopped \
-v ~/.hermes:/opt/data \
-p 8642:8642 \
nousresearch/hermes-agent gateway run核心是这个挂载:
~/.hermes:/opt/data因为 .env、config、sessions、memories、skills、cron、logs 都需要保留下来。
第二种,是 Hermes 还在宿主机跑,但终端工具进 Docker 沙箱:
hermes config set terminal.backend dockerKanban 适合多 profile 协作,不是第一天必开:
hermes kanban --help
hermes kanban init
hermes kanban boards list
hermes kanban list它更像一个 durable task board,可以 claim 任务、设置依赖、检测异常退出。
Cron 适合固定任务:
hermes cron list
hermes cron add
hermes cron status
hermes cron run <job>但新手不要第一天就让它自动发布文章、自动删文件、自动操作账号。
更适合从低风险任务开始:
每天生成一份 AI 工具简报; 每晚备份一个目录; 每周审计一次 Skills; 每天检查一个网页有没有更新。
自动化不是越猛越好。
能复查、能回滚、能解释,才适合长期跑。
出问题时,按这个顺序排查
不要凭感觉乱改 .env 和 config.yaml。
先跑这一串:
hermes doctor
hermes model
hermes setup
hermes sessions list
hermes --continue
hermes gateway status
hermes logs errors几个常见问题:
hermes: command not found:多半是 shell 没重载; 模型不回:先查 provider、API Key、模型名、base URL; 本地模型异常:看 endpoint 是否 OpenAI-compatible、context 够不够; Gateway 收不到消息:查 token、allowlist、pairing、home channel、平台权限; 记忆没生效:确认是不是同一个 profile、session 是否恢复; Docker 重启后配置丢了:大概率是 ~/.hermes没挂到/opt/data;Skills 乱了:先看 hermes skills list和hermes skills audit。
第一周最适合练什么?AI 日报助手
我建议新手第一周不要上来做复杂自动化。
先做一个低风险、但真实有用的小任务:AI 日报助手。
第一天,直接在 CLI 里丢这个任务:
请帮我生成一份今天的 AI 工具更新简报。
要求:
1. 每条保留产品名、原始链接、更新时间
2. 按 agent / coding / video / image / infra 分类
3. 输出 Markdown
4. 末尾写一下哪些偏好值得下次继续保留做完以后,不要只看结果。
要纠正格式:
以后这类简报不要写空泛评价。
每条只保留事实、链接和一句“值得看的原因”。
请把这个偏好写入你的记忆。第二天继续:
继续昨天的 AI 工具更新简报。
但这次只保留最值得写成公众号文章的 5 条。
每条给出:标题方向、读者痛点、实操交付物。连续做三天后,再让它沉淀成 Skill:
我们已经连续做了三次 AI 工具更新简报。
请把稳定流程保存成一个 Skill,名字叫 ai-daily-brief。
要求包含触发条件、信息来源、筛选规则、输出格式和验证方法。这比第一天喊“帮我打造一个 AI 帝国”实在得多。
小任务安全、低成本、可复查。
Hermes 也能在这个过程中慢慢记住偏好,沉淀流程。
最后收一下
我看重 Hermes,不是因为它能“一键取代人”。
而是因为它解决了一个普通 AI 工具很常见的问题:连续性。
今天教会一个格式,明天不要重新教。
今天修过一个坑,后天不要再绕回来踩。
Hermes 把 memory、skills、sessions、gateway、profiles、kanban 放在一起,就是在解决这种断裂。
但它也不是免维护机器。
模型要选,密钥要管,工具要配,日志要查,权限要审,Skills 要清理,任务边界也要设计。
所以我的建议很土:
先跑通一个会话,再养成一个流程,最后再组织一支队伍。
第一天做到这三件事就够了:
hermes model
hermes --tui
hermes doctor能说话,能用工具,能恢复,能排错。
这个地基打好,Hermes 才有资格变成你的长期 AI 工作台。
如果你也想看更多普通人能用起来的 AI 工具和 AI 工作流,可以先关注我。
下一篇,我会继续拆:怎么用 Hermes 做一个每天自动整理 AI 选题的公众号助手。
参考来源:ChrisWangwy 在 X 发布的《Hermes 新手教程该重写了》及相关推文:
https://x.com/ChrisWangwy/status/2053054035738108006
