 夜雨聆风
夜雨聆风
最近一年,如果你关注 AI 工具生态,会发现一个有趣的趋势:越来越多的基础设施类工具在用 Rust 重写。不是因为 Rust 语言本身多热门,而是因为"分发"这件事,在 AI 时代变得比以前更关键了。
想想看:你用 Python 写了一个很棒的小工具,准备分享给同事。结果对方电脑上没有 Python 环境,你开始解释怎么装 Python、建虚拟env、解决依赖冲突……一个"随手发过去就能用"的工具,最后变成了一场环境配置的拉锯战。
这不只是个人体验,这是一个正在扩散的问题——因为 AI 也在"用"工具,而且用得更频繁。
一、分发成本:不只是体积,是整条链路的摩擦
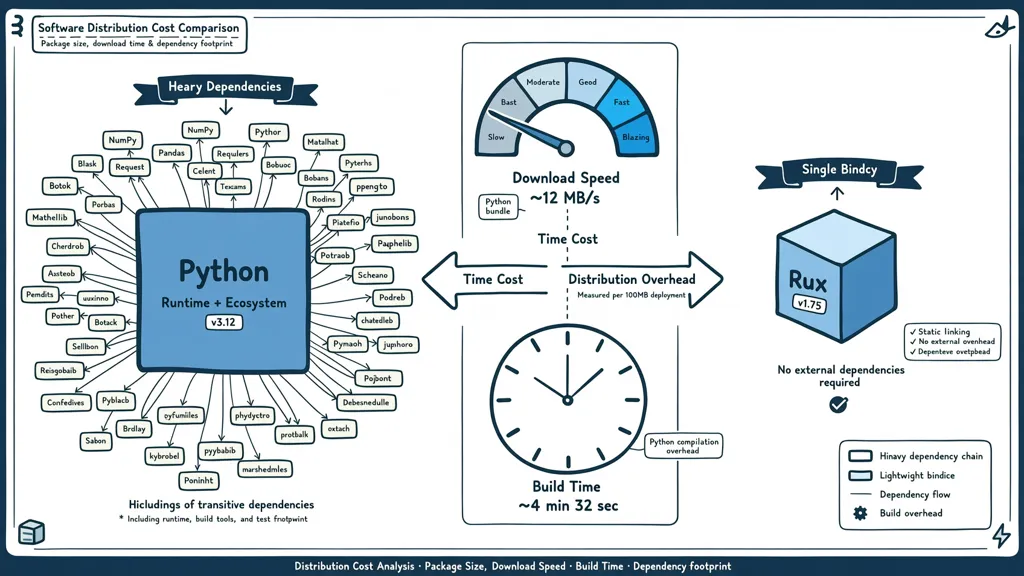
很多人提到 Rust 优势,第一反应是"性能好"。但对工具类场景,分发成本才是更关键的词。
第一层:下载/安装成本
Python 打包的工具,动辄 50MB 起;Rust 编译出来的 binary,常见的 CLI 工具只有 3-5MB。这个差距在慢网环境下是真实痛点。更重要的是,它影响"用户愿不愿意尝试"——5MB 点一下就下载完,100MB 用户可能要想一下。
第二层:环境配置成本
Python 工具需要正确版本的 Python 解释器、pip install 一堆依赖、有时候还遇到版本冲突。Rust 的 binary 是静态链接的,复制到目标机器上直接就能跑。Cassandra 社区在重写 cqlsh 时有个典型痛点:每次依赖更新都要重新测试整个 pinned 的 Python bundle,换成 Rust static binary 之后,**"编译一次,到处运行"**终于真正实现(详见 cqlsh-rs 项目博客文章[1])。
第三层:冷启动 overhead
Python 工具每次启动,需要 fork 进程、加载解释器、导入标准库和第三方依赖。这个过程可能需要 200ms 到几秒不等。人类偶尔等 2-3 秒能接受,但 AI 频繁调用,这个 overhead 就会被放大——这正是我们下一节要聊的重点。
分发成本 = 下载成本 + 配置成本 + 运行成本。 Rust 在这三层都有优势。
二、被忽视的关键:AI调工具的冷启动代价
AI 正在成为工具的重度用户。
以 Claude Code 或者类似的 AI 编程助手为例,它们在工作时需要频繁调用各种本地工具:git 操作、代码格式化、shell 命令、文件系统操作……每一次调用,底层都是一个 fork + 执行 + 返回结果的过程。
如果这个工具是 Python 写的,整个过程可能需要 200ms 到 1s+;而 Rust 写的工具可能只需要 10-50ms。
这意味着什么?
对于人类用户:偶尔等一次 500ms,可以接受。
对于 AI:如果 AI 每分钟需要调用 20 次工具,Python 方案累计需要 10 秒等待,Rust 方案只需要 1 秒。一分钟差距不大,但一个小时下来差距就非常明显了。
更重要的是,AI 的工具调用往往是按需的、动态的——AI 根据上下文决定调用什么工具,用完就释放,不像人类用户会一直保持应用开着。这使得冷启动 overhead 变成了一个必须解决的问题,而不是可以忽略的问题。
三、动态启动:让工具真正"按需"加载
MCP(Model Context Protocol)是 AI 调用外部工具的主流协议标准。它的设计有一个很有意思的特点:MCP server 不需要常驻运行。
传统的服务模式是:启动一个服务进程 → 长时间运行 → 接受请求 → 返回结果。服务进程始终保持在内存中,响应快但占用资源。
MCP 的 stdio 传输模式则不同:AI 需要调用工具时,启动一个 MCP server 进程 → 执行工具 → 返回结果 → 进程退出,资源释放。下次需要时再启动一个新进程。
这种模式的前提是:冷启动必须足够快。
如果冷启动需要 2 秒,那按需启动就变成了噩梦。如果冷启动只需要 20ms,那按需启动就是最优解:响应快、资源占用低(只有运行那一刻占用内存)、工具之间完全隔离(一个崩溃不影响其他)。
Rust 的快速冷启动(<15ms)使得这种按需启动模式真正变得可行。工具可以做到:
用时启动,用完释放——不需要守护进程,不需要进程池 工具数量线性扩展——每个工具是独立 binary,按需加载 完全隔离——一个工具崩溃了,不会影响其他工具 无状态——每次都是干净的启动状态,没有状态残留
四、AI时代工具的新分层
基于以上分析,我们可以看到一个清晰的分工正在形成:
AI 应用层 → Python
这部分是 AI 的"大脑",负责数据处理、模型调用、业务逻辑编排。这里需要的是:丰富的生态(LangChain、HuggingFace Transformers、Pandas)、快速原型能力。Python 依然是这个领域的主角。
工具/基础设施层 → Rust
这部分是 AI 的"手脚",负责执行具体操作:调用 git、操作文件系统、运行代码格式化工具……这些操作需要快速响应、零配置分发、可靠稳定。Rust 的小体积、快冷启动、零依赖特性让它成为这个场景的最优选择。
ML 推理层 → Rust
Hugging Face 的 Candle 是一个典型代表。这是一个纯 Rust 实现的 ML 框架[2],打包体积可以比 PyTorch 小 100 倍以上。对于需要把 ML 推理能力封装成分发工具的场景,Rust 有绝对优势。
这三层不是替代关系,是分工关系。 Python 做 AI 应用的大脑,Rust 做 AI 工具的手脚——这个组合正在成为 AI 工具开发的新范式。
五、实证:Rust正在重写这些工具
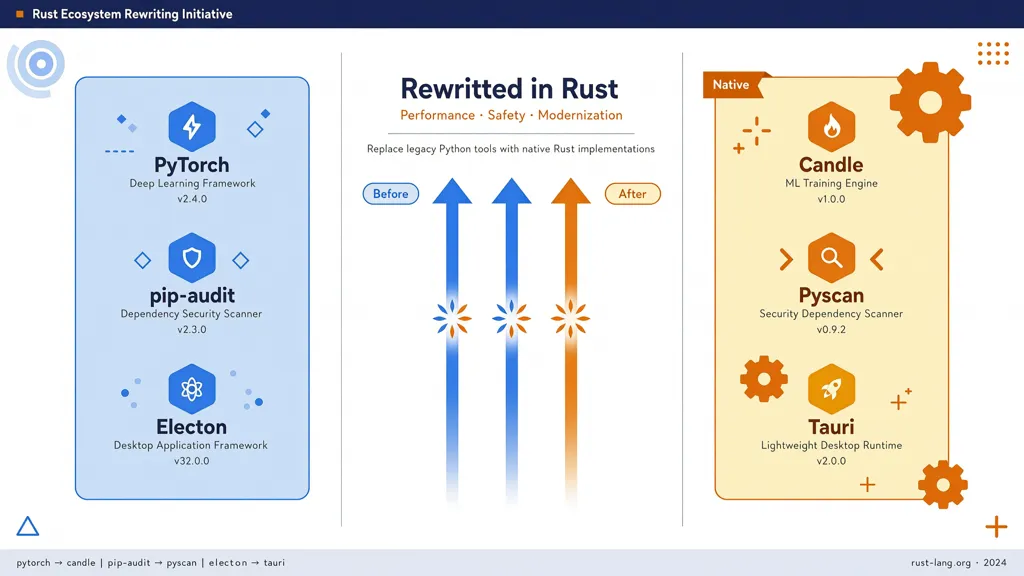
说了这么多,来点实际的例子。
桌面应用:Electron vs Tauri
这是最直观的对比。Electron 打包的应用自带 Chromium 浏览器,体积动辄 150MB 以上;Tauri 使用系统 WebView + Rust 后端,同样的应用可以做到 3-5MB,差距在 30-50 倍(数据来源: PkgPulse 对比测试[3])。
| 指标 | Electron | Tauri |
|---|---|---|
| 典型安装包大小 | 150-200 MB | 3-5 MB |
| 冷启动时间 | 1-2 秒 | <0.5 秒 |
| 空闲内存 | 200-500 MB | 30-100 MB |
Slack、VS Code 用 Electron 是因为它们有足够的市场压力让用户接受大体积,但对于新项目,Tauri 的吸引力正在快速上升。
CLI 工具:Python → Rust 重写案例
| 工具 | 场景 | Python | Rust | 提升 |
|---|---|---|---|---|
| site2skill | 网页转 skill | 0.77s / 34MB | 0.15s / 11MB | 5x 快,3x 省内存 |
| Pyscan | 安全扫描 | 62s / 433MB | 6.9s / 53MB | 9x 快,8x 省内存 |
| cqlsh-rs | 数据库 CLI | 需要打包整个 Python runtime | 一个 binary,零依赖 | 配置成本趋近于零 |
其中 site2skill 的重写案例记录在 GitHub PR[4] 中,Pyscan 的实测数据来自 DEV Community[5]。
ML 推理:Candle vs PyTorch
| 指标 | PyTorch | Candle |
|---|---|---|
| 冷启动 | 3-5 秒 | <100ms |
| 内存 baseline | ~500MB | ~20MB |
| tokens/sec(CPU) | 9.2 | 29.4 |
| 打包体积 | 3-4 GB | ~20MB |
Candle 的核心目标不是取代 PyTorch,而是让 ML 推理也能做成小体积工具分发。实测数据可见 Markaicode 的对比评测[6]。
MCP 生态:Rust 实现占主导
MCP 协议的主流实现中,Rust 占了很大比例:rmcp[7](官方 SDK)、mcpkit、tmcp、prism-mcp-rs……原因很简单:MCP server 本质上是一个需要频繁按需启动的工具,Rust 的快速冷启动和零依赖特性完美契合这个场景。
六、结论:Rust不是银弹,但是工具层的最优解
Rust 在 AI 时代的工具层有独特优势,这不是语言偏好,而是现实约束下的最优选择:
分发体积小 → 用户愿意尝试,AI 愿意调用 冷启动快 → 按需动态加载成为可能 零依赖 → 配置成本趋近于零 内存可预测 → AI 调用更稳定
但 Rust 也不会取代 Python。Python 在 AI 应用开发层的生态积累太深厚了。
未来的 AI 工具链,很可能是:用 Python 做 AI 应用,用 Rust 做 AI 工具。Python 定义 AI 该做什么,Rust 让 AI 的每一个动作都能快速、可靠地执行。
这才是 Rust 在 AI 时代真正的价值所在。
引用链接
[1]博客文章: https://fruch.github.io/rust/2026/03/26/cqlsh-rs-dear-cqlsh
[2]纯 Rust 实现的 ML 框架: https://github.com/huggingface/candle
[3]PkgPulse 对比测试: https://www.pkgpulse.com/guides/electron-vs-tauri-2026
[4]GitHub PR: https://github.com/laiso/site2skill/pull/7
[5]DEV Community: https://dev.to/ohaswin/this-is-why-you-rewrite-python-security-tools-in-rust-53mb-vs-433mb-peak-memory-69s-vs-622s-4ea6
[6]Markaicode 的对比评测: https://markaicode.com/rust-candle-llm-inference-faster-than-pytorch/
[7]rmcp: https://docs.rs/rmcp/latest/rmcp/
