 夜雨聆风
夜雨聆风PDF 清洗实战:为什么 pdfplumber 救不了你,MinerU 怎么用
一、一个真实的"翻车现场"
昨天有同学在群里发问:
"辉哥,我照着教程用
pdfplumber抽 PDF,结果惨不忍睹——双栏论文左右串行、教材里的公式全变成了方框、扫描版的电子书直接抽出来一片空白。这玩意儿怎么用啊?"
我让他截了几张图过来,一看是这样的:

这不是他一个人的问题。 凡是真正动手做过 RAG 知识库、AI 训练数据准备的同学,几乎都被 PDF 折磨过。
我把他的问题归一下,再延伸到所有"难洗的 PDF",写成今天这篇文章——告诉你:
PDF 为什么这么难处理 不同的 PDF 应该用什么工具,别杀鸡用牛刀,也别拿刀去砍坦克 为什么 MinerU 是当前国内做 LLM 数据准备的最优解 怎么 5 分钟跑通最小示例,怎么把它嵌到生产清洗流水线里
二、先搞清楚:PDF 为什么这么难洗?
要解决问题,先得知道问题长什么样。
很多同学以为 PDF 是一种"文档格式"——像 Word、Markdown 那样,有标题、有段落、有列表。
错。 PDF 的本质是一种**"打印格式"——它存的不是"文档结构",而是"在某个坐标位置画一个字符"**。
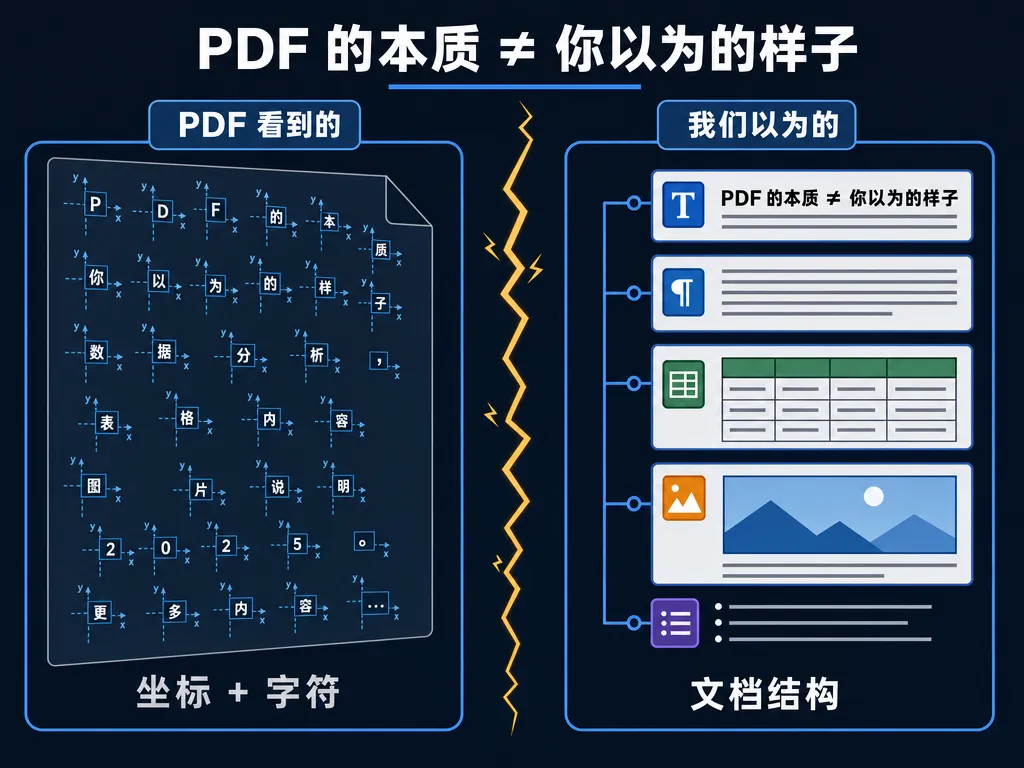
左边是 PDF 在引擎眼里的样子:一堆带坐标的孤立字符,像撒在桌面上的拼字积木。 右边是我们大脑以为的样子:一棵有层级的文档树——标题包段落,段落含表格,表格旁配图。
这两者之间隔着一道琥珀色的闪电——这就是 PDF 解析最难的地方:你得自己把"散字符"拼回成"文档结构"。
具体来说,难点有三类:
1. 版面复杂(双栏、表格、嵌入图)
论文是双栏排版,你按坐标顺序读,得到的是"左栏第一行 → 右栏第一行 → 左栏第二行……"的乱序结果。要修,得做版面分析,先识别出"哪些字符属于左栏、哪些属于右栏"。
2. 公式 / 表格
公式不是普通字符,PDF 里它常被存成位图或私有字体。普通工具抽出来要么是方框 □□□,要么是乱码。表格的合并单元格、跨页表格更难。
3. 扫描件
这就更狠——根本没有文字层,整个 PDF 就是一张张图片。要抽文字,必须上 OCR。
一句话总结:普通工具只解决了"取字",没解决"取意"。
三、工具选型:四把刀怎么挑
下面这张表,强烈建议你截图存到收藏夹,下次选工具的时候掏出来对一遍:
| MinerU | ||||
|---|---|---|---|---|
更直观一点,看下面这张矩阵图——MinerU 是唯一一行五项全绿的工具:

图里商用 API 那一行整排金币——不是说它做不到,而是想提醒你:它每解析一页,你的钱包和数据都要往外送一次。能力它都有,但代价是「按页计费 + 文档要传到第三方服务器」。对个人项目可能无所谓,对企业内部资料就是红线。
结论很清晰:
纯文本类 PDF(合同、纯文字电子书)→ pymupdf三行代码搞定复杂 PDF(论文、技术书、扫描件)→ MinerU 怕数据外发(公司机密、用户文档)→ 本地工具,不要上商用 API
💡 我的最佳实践:在生产 pipeline 里,两套工具组合用——前置一个简单分流器,纯文本走 pymupdf 极速处理,复杂 PDF 走 MinerU 高质量解析。后面会讲怎么搭。
四、MinerU 是什么?凭什么能打?
4.1 出身
MinerU 来自上海人工智能实验室的 OpenDataLab 团队——也就是给 InternLM(书生·浦语)准备训练数据的那拨人。
这一点很重要:MinerU 不是某个学生写的玩具,而是真·万亿 token 级训练数据生产线上磨出来的工具。它解决的,是"工业级数据清洗"的问题,不是"我写一篇毕业论文" 的问题。
4.2 最新版(3.1.0,2026 年 4 月发布)
刚好上个月 MinerU 发了 3.1.0,有三个升级值得说:
🔓 第一,开源协议改了。 原来是 AGPLv3(商业用受限),现在改成了基于 Apache 2.0 的 MinerU 开源协议——商业项目可以放心用了,这是对国内大量商业落地场景的友好让步。
🚀 第二,主模型升级到 MinerU2.5-Pro-2604-1.2B。
跨页表格自动合并(之前要手工拼) 表格内嵌图片识别 复杂版面解析精度刷到了 SOTA
📦 第三,原生支持五大格式。 PDF / DOCX / PPTX / XLSX / 图片,一套工具吃所有文档——以前还要装一堆别的库做 Office 转换,现在一站式。
4.3 一份 PDF 进来,会经历什么
光说能力你可能还是没感觉。我画了一张图,把 MinerU 的处理流程拆成 5 步——这就是用户视角下的 MinerU:
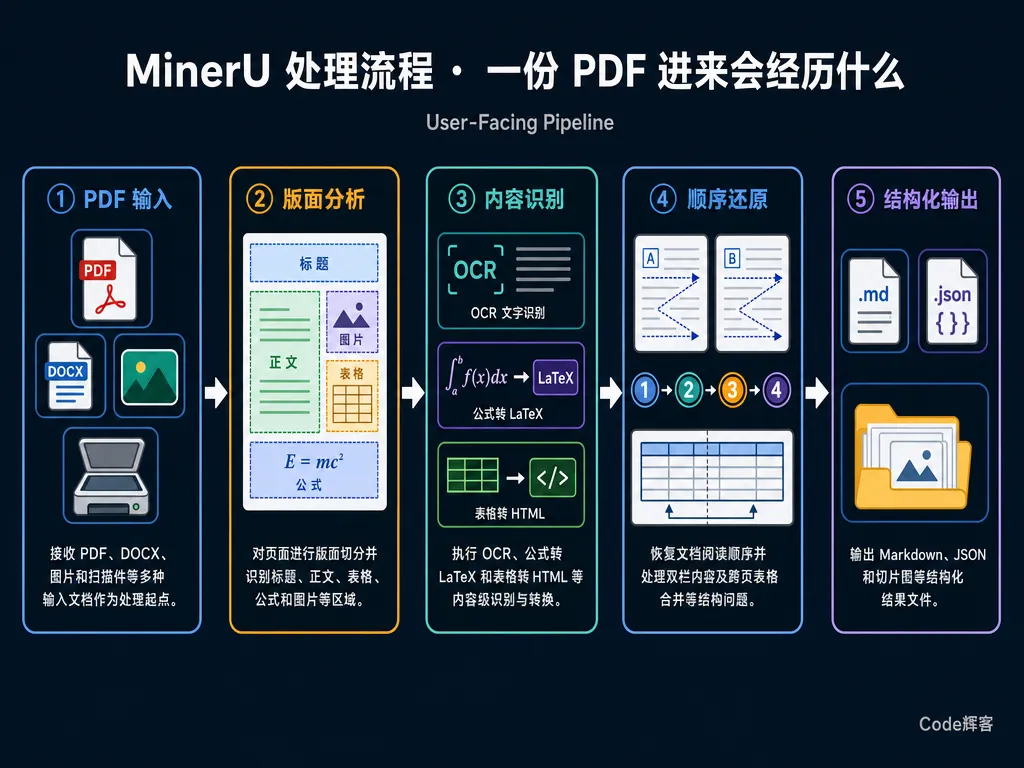
关键差异:第 ② ③ ④ 步是 pdfplumber 这类工具完全没有的能力。这才是 MinerU 跟"普通 PDF 库"的本质分水岭。
4.4 三种推理后端怎么选
MinerU 提供了三种后端,对应不同硬件和精度需求:
pipeline | CPU 也能跑 | |
vlm-engine | ||
hybrid-engine |
新手第一次跑,无脑选 pipeline。等你确实碰到 pipeline 处理不好的复杂场景,再升级到 vlm-engine。
五、动手:5 分钟跑通最小示例
5.1 环境准备
# Python 3.10+,建议 conda 隔离环境conda create -n mineru python=3.10 -yconda activate mineru# 入门安装:pipeline 后端 + 核心依赖pip install -U "mineru[core]"# 如果要用 GPU vlm-engine,装这个# pip install -U "mineru[all]"5.2 一行命令试水
# 把一个 PDF 转成 Markdownmineru -p ./test.pdf -o ./output跑完会在 ./output/test/ 目录下看到:
output/test/├── auto/│ ├── test.md # ✅ Markdown 输出,给 LLM 用│ ├── test_content_list.json # ✅ JSON 结构,带 bbox 坐标│ ├── test_layout.pdf # 版面分析可视化│ ├── test_spans.pdf # 字符切片可视化│ └── images/ # 抽出来的所有图片5.3 Python 调用(生产场景用这个)
from mineru.cli.common import do_parse, prepare_envfrom pathlib import Pathpdf_path = Path("./paper.pdf")output_dir = Path("./output")# 准备环境local_image_dir, local_md_dir = prepare_env( output_dir, pdf_path.stem, "auto")# 执行解析do_parse( output_dir=str(output_dir), pdf_file_names=[pdf_path.stem], pdf_bytes_list=[pdf_path.read_bytes()], p_lang_list=["ch"], # 中文文档 backend="pipeline", # 或 "vlm-sglang-engine" parse_method="auto", # auto / ocr / txt)print(f"✅ Markdown 输出: {local_md_dir}/{pdf_path.stem}.md")5.4 输出结构怎么用
*.md→ 直接喂给 LLM,或者写进 RAG 知识库*_content_list.json→ 带 bbox 坐标,做精细二次处理(比如"只抽出所有表格")images/→ 文档里的图,可以单独做向量化、做多模态检索
六、生产级用法:把 MinerU 嵌进你的清洗 Pipeline
5 分钟跑通是入门。真正的生产场景,你要面对的是:
几千份 PDF,类型五花八门 MinerU 准但慢,纯文本 PDF 用它就太奢侈了 要能自动分流、自动重试、自动报警
核心设计:PDF 类型分流——这是性价比的灵魂。
┌─→ 纯文本/合同 → pymupdf (10ms/页)PDF 输入 → 检测 ─→ ├─→ 学术/技术/扫描 → MinerU(2~5s/页 GPU) └─→ 损坏/加密 → 报警 → 人工 ↓ 统一 Markdown 输出6.1 怎么"检测分流"
伪代码:
import pymupdf # 即 fitzdefclassify_pdf(pdf_path: str) -> str:"""返回 'simple' | 'complex' | 'broken'"""try: doc = pymupdf.open(pdf_path)except Exception:return"broken"# 抽前 3 页字符密度 text_density = 0for i inrange(min(3, len(doc))): page = doc[i] text = page.get_text() area = page.rect.width * page.rect.height text_density += len(text) / area text_density /= min(3, len(doc))if text_density < 0.001:return"complex"# 几乎无文字层 → 扫描件# 简单的双栏检测 page = doc[0] blocks = page.get_text("blocks") x_coords = sorted({round(b[0]) for b in blocks})iflen(x_coords) >= 2and (x_coords[-1] - x_coords[0]) > page.rect.width * 0.3:return"complex"# 多列布局return"simple"6.2 后处理三件套
MinerU 输出的 Markdown 不是终点,还有三件事必须做:
① 切 chunk
# 按二级标题切,或按 800 token 滑窗chunks = split_markdown_by_heading(md_text, level=2)② 公式归一化
把不同的 LaTeX 分隔符( $$、\[、\()统一修复转义问题( \\→\)
③ 去广告/版权/空白页
检测页脚特征文本("版权所有"、"All rights reserved") 检测重复出现的页眉/页码
七、踩坑实录:5 个新手 90% 会遇到的问题
1. CPU 跑得慢到怀疑人生
症状:解析一页 PDF 要 30 秒到 2 分钟。 原因:八成是装错了依赖(漏装了 ONNXRuntime/OpenCV)。 解决:
pip install -U "mineru[core]"# 重装核心# GPU 环境追加pip install -U "mineru[all]"2. 模型下载卡住
症状:第一次启动卡在 Downloading model from HuggingFace...。 原因:HuggingFace 国内连不通。 解决:
export HF_ENDPOINT=https://hf-mirror.commineru -p ./test.pdf -o ./output3. 公式输出了 LaTeX,但前端不渲染
**症状**:Markdown 里出现 ``,前端显示成原文。 **原因**:你的 Markdown 渲染器没装数学插件。 **解决**:前端加 KaTeX 或 MathJax。Python 服务端也可以预渲染成 SVG。4. 大文档 OOM
症状:处理几百页的书,进程被 kill。 解决:升级到 3.0.0+ 已经支持滑动窗口和流式写盘,长文档不需要再手工切分。如果还 OOM,把 --enable-slide-window 显式打开。
5. 表格丢失合并单元格 / 跨页表格断开
症状:明明是一张大表,输出成两张小表。 解决:升级到 3.1.0——跨页表格自动合并就是这个版本的新特性。
八、收尾:把 MinerU 接到你的 LLM 训练流水线
到这里,PDF 清洗这一环你应该已经心里有数了。
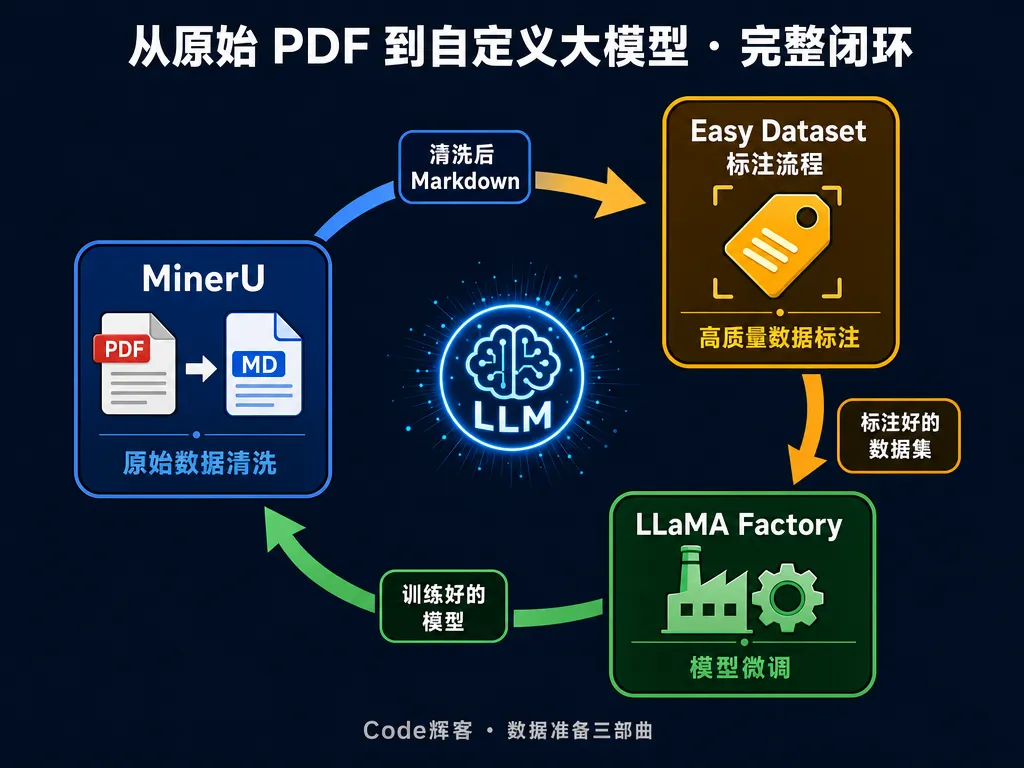
但 MinerU 只是数据准备的第一步。完整流程是这样的:
| MinerU | ||
| Easy Dataset | ||
| LLaMA Factory |
这就是我之前一直在写的「数据准备三部曲」——
第一篇 👉 《大模型微调数据标注实战:从原始语料到高质量指令对》 第二篇 👉 《手把手教你构建大模型微调数据集:Easy Dataset 实战》 第三篇 👉 本篇
三篇连起来读,你就能打通"原始资料 → 自定义大模型"的完整链路。
下一篇预告:清洗完的 Markdown,怎么自动生成高质量的 QA 对——这又是个能写 5000 字的话题。下次见。
🐳 本文要点回顾
不是所有 PDF 都需要 MinerU——纯文本 pymupdf 就够,复杂 PDF 才上 MinerU MinerU 强在三件事:版面分析、内容识别(公式/表格)、阅读顺序还原 生产用法关键是类型分流 + 后处理三件套 3.1.0 改了开源协议,商业项目可以放心用
Code辉客 · 数据准备三部曲 · 第三篇
