 夜雨聆风
夜雨聆风一、写在前面
刚从知网、PubMed、Sci-Hub上下载的SCI文献,文件名是不是这种画风?s41586-023-06185-3.pdf、1-s2.0-S0092867423005...pdf、nihms-1234567.pdf……
下载十几篇还能勉强分辨,一旦超过几十上百篇,根本想不起来哪篇是哪篇,只能一个一个点开看。等到写文章,写课题的时候,找文献就像大海捞针。
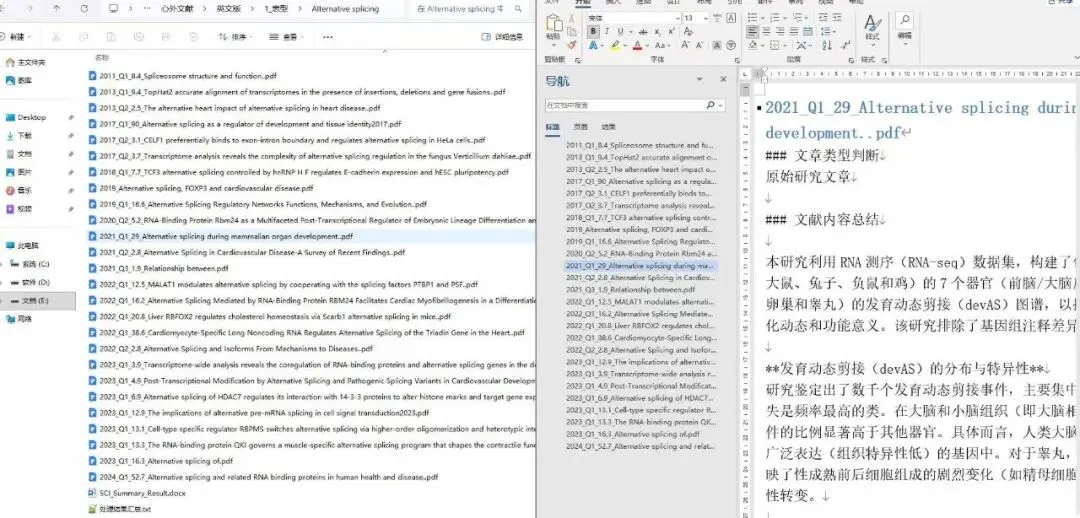
这个工具就是用来解决这个问题的。它会自动把PDF文件名规范成这种格式:发表年份_JCR分区_影响因子_文献标题.pdf比如:2023_Q1_50.5_The role of gut microbiota in colorectal cancer.pdf一眼就能看出年份、档次和主题,找文献效率直接起飞。重命名效果见下图。
二、工具获取与激活
1. 下载地址(免费)
百度网盘:https://pan.baidu.com/s/1ityjSfKbGr7C2UBkXMtfWg?pwd=1f2c 提取码:1f2c
2. 激活方式(免费)
打开软件后会弹出激活窗口,里面有一串“机器码”,复制下来,在公众号后台留言发给我,我会把激活码回复给你,输入即可永久使用。
三、软件界面功能详解
整个界面分为6个区域,下面对照图片逐一讲解(请对照图2上面的数字标记看)。

1号区域:环境配置区(一般不用动)
这里有两个输入框:JDK路径 和 Jar路径。这两项是为了让软件从PDF里“挖”出DOI号。
好消息是:你基本不用管这里。软件启动时会自动扫描自己所在的文件夹,找到JDK和Jar文件,自动填好路径。只要你把下载下来的整个文件夹原封不动地放着用,这两栏会自动识别。只有当软件提示找不到Java环境时,才需要点旁边的 … 按钮手动选一下。
2号区域:步骤1 CSV期刊数据库
这是工具的“知识库”,里面存着上万本SCI期刊的影响因子(JIF)和JCR分区(Q1/Q2/Q3/Q4)。软件就是靠这个文件来给你的文献标注分区和IF的。
这一项软件也会自动加载,只要CSV文件和软件在同一个文件夹下,启动时会自动找到。如果想换最新版的CSV(比如新一年的JCR数据更新了),点“浏览”按钮选择新的CSV文件即可。点“格式说明”可以查看CSV需要包含哪些列(Rank、Journal Name、Abbr、ISSN、JIF、Quartile这几列)。
3号区域:模式A 批量处理(最常用)
这是最常用的模式,一次性处理一整个文件夹甚至多个文件夹的PDF。
使用步骤:
点“添加”按钮,选择你存放PDF文献的文件夹。可以重复点“添加”,把多个文件夹依次加入队列(比如“心血管文献”“肿瘤文献”“免疫文献”三个文件夹一起处理)。 点“查看队列”可以看到你添加了哪些文件夹,也可以在这里删除选错的文件夹。下方的“已添加 X 个文件夹”会实时显示数量。 点蓝色加粗的“▶ 开始批量处理”按钮,软件就开始干活了。期间你可以继续往队列里加新文件夹,软件会按顺序处理完。 如果点错了或者想清空,点“清空队列”即可。
软件已经重命名过的文件(也就是已经是 年份_分区_IF_标题 格式的),会自动跳过,不会重复处理,可以放心地把新下载的PDF和已重命名的PDF放在同一个文件夹。
4号区域:模式B 单文件处理
只想处理一篇文献的时候用这个模式。
两种用法:
用法一(最简单):点“选择PDF”按钮选一个文件,或者直接把PDF文件拖拽到这个区域里(拖进来就行,松手即可),然后点“执行处理”,搞定。
用法二(兜底用):有时候PDF特别老、特别旧,软件提取不到DOI,或者这本期刊CSV库里没收录(比如一些很新的期刊),这时可以在下面的三个输入框里手动填:
填好后点“执行处理”,软件会用你填的信息来命名。这三个框不填也可以,软件会优先自动尝试。
DOI:从文献首页或者期刊网站复制DOI填进去 IF:手动填影响因子(比如5.2) 分区:手动填分区(比如Q1)
5号区域:模式C 实时监控(懒人福音)
这个功能特别适合“边下载边整理”的场景。
用法:先在3号区域用“添加”按钮选好一个下载文献的文件夹(监控会监控队列里的第一个文件夹),然后点红色的“▶ 开启监控”按钮。之后,你只要往这个文件夹里丢PDF,软件就会自动重命名,不用你再点任何按钮。比如你在Sci-Hub下载文献到这个文件夹,刚下载完,文件名“啪”一下就变成规范格式了。不想监控了,点“■ 停止”按钮即可。
小提示: 软件足够智能,如果某个文件正在下载(还没下完),它会自动跳过,等下完再处理,不会把半截文件搞坏。
6号区域:运行日志
这是软件的“实时播报区”,所有处理过程都会在这里显示:
正在处理哪篇文献 DOI是用什么方法提取到的 PubMed查询是否成功 最终重命名成什么名字 哪些文件处理失败了(一般是扫描版PDF或者特别老的文献)
遇到问题就看这里,日志会告诉你软件卡在哪一步。
四、工作原理简述(选看)
为了让你更放心地使用,简单说一下软件背后的逻辑:
提取DOI:先快速扫描PDF首页,提取DOI号。 查询PubMed:拿到DOI后,去PubMed官方接口查询这篇文献的标题、年份、期刊名、ISSN。失败的话会自动重试3次,应对网络波动。 匹配分区IF:用查到的期刊信息去CSV数据库里匹配影响因子和JCR分区。 重命名:按“年份_分区_IF_标题”的格式重命名文件。 降级处理:如果某一步失败(比如期刊不在CSV库里),软件会尽量用已有的信息(至少年份和标题)来命名,不会让文件名彻底乱掉。 以上的工具只能修改英文文献(因为通过PubMed获取相关信息)
五、常见问题
Q:处理一篇文献要多久?A:网络好的话,平均5-15秒一篇。批量处理100篇大概15-25分钟。
Q:处理失败的文件会被破坏吗?A:不会。软件只做“重命名”操作,不会修改PDF内容。失败的文件保持原名不变,下次还能重新尝试。
Q:扫描版的PDF(图片格式)能处理吗?A:不行,因为提取不到文字。
Q:CSV数据库怎么更新?A:每年JCR发布新数据后,会在网上找到更新版的CSV,替换掉旧的即可(要保留原CSV的列名)。也可以等我更新后在公众号同步发布。
