 夜雨聆风
夜雨聆风
上周我把一份扫描版简历丢给 AI 助手,想让帮忙整理成结构化数据。结果 AI 一本正经地问我:"请问 h89.cr 是什么域名?"
我愣了一下,低头看原文——明明是 me@h89.cn。这件事让我意识到:传统 OCR 提取出来的文字,AI 根本没法好好理解。
不只是邮箱会认错。英文单词粘在一起变成 OceanDepths,表格变成一团乱麻,公式直接变乱码,最要命的是所有内容平铺成一锅粥,标题和正文完全分不清。
于是我决定动手,在自己的笔记本上搭一套本地 PDF 识别方案。折腾了两天,先后试了 PP-OCRv4、DeepSeek-OCR-2 和 PaddleOCR-VL-1.5,记录如下。
测试设备:NVIDIA RTX 4060 Laptop (8GB) / CUDA 11.8 / Windows 11

二、PP-OCRv4:快是真快,坑也是真的多
最先上手的是 PP-OCRv4。毕竟名声在外,中文 OCR 的标杆,而且 paddlepaddle-gpu==2.6.2 + paddleocr==2.7.3 这套组合在 Windows 上有成熟的 GPU 支持。
跑起来之后的惊喜
两页简历,1.4 秒 就跑完了。十页设计素材,1.9 秒。这速度放在本地跑,基本就是眨眼的事。显存也只吃了 2GB 左右,RTX 4060 的 8GB 显存表示毫无压力。
但结果让我哭笑不得
输出的是纯文本,所有内容像流水账一样平铺。更尴尬的是前面说的那个邮箱——它把 .cn 看成了 .cr,JNI 识别成了 小ni。
设计素材那页更惨。本来是四个色块配颜色名,结果被它拼成了一行:Deep NavyTealSeafoamCream,连空格都没剩下。AI 拿到这份"战果",估计会以为这是什么新型编程语言。
另外它完全不管版面。标题、正文、页眉、页码全部混在一块,表格直接变文本,图片被忽略,公式变成天书。
代码写得我头大
为了把 OCR 结果转成能看的 Markdown,我手写了快 200 行代码:手动按坐标行分组、处理文本框顺序、拼接段落……一顿操作下来,最多只能说"能跑"。
PP-OCRv4 给我的感觉,就像一个语速极快但有点近视的速记员。
三、DeepSeek-OCR-2:让 VLM 来收拾残局
既然传统 OCR 搞不定语义理解,那就上 VLM(视觉语言模型)。
DeepSeek-OCR-2 走的是另一条路:把 PDF 每页转成图片,直接丢给多模态大模型,让它自己"看"、自己"理解"、自己输出 Markdown。
效果确实好了
同样是那份简历,邮箱终于认对了,JNI 也回来了。更惊喜的是它自动给内容加了 Markdown 结构:## 陈建伟、## 个人优势、## 工作经历,层次分明。还顺手把简历里嵌入的头像图片也提取了出来,在 Markdown 里保留了引用路径。
这感觉像是换了一个会思考的实习生,不再是机械抄写,而是真正在读这份简历。
但速度让我回到了拨号上网时代
两页简历,跑了 25 秒。十页设计素材,将近两分钟。
问题出在它的 vLLM 加速路径在 Windows 上编译失败,只能用 HuggingFace Transformers 路径,逐页串行处理,没有异步队列。RTX 4060 的 8GB 显存被吃掉 6.4GB,基本满载。
DeepSeek-OCR-2 就像一个读得很认真但看得极慢的学霸。
四、PaddleOCR-VL-1.5:两手都要抓
折腾到第三个方案时,我其实有点累了。但 PaddleOCR-VL-1.5 给了我一个惊喜:它的 pipeline 封装得太省心了。
架构设计很聪明
它不做选择,而是全都要:
- 先布局分析(PP-DocLayoutV3):把页面切成标题、正文、表格、图表、公式、印章等区域,确定阅读顺序
- 再 VLM 识别(0.9B 参数):每个区域独立送入小模型,生成对应的 Markdown/LaTeX
- 按页面输出结果(脚本已增加自动合并为单文件)
体验出奇地好
两页简历,3-5 秒。十页素材,8-15 秒。速度介于两者之间,但输出质量不输 DeepSeek。
更关键的是它原生支持我前面遇到的所有痛点:
- 公式输出 LaTeX
- 表格输出 Markdown 表格格式
- 图表自动识别并描述
- 印章也能认
- 跨页表格处理(依赖版面分析,未实测验证)
- 不规则文字(倾斜、弯曲)照样检测
代码量也降到了 50 行,pipeline 一行调用:pipeline.predict(pdf),完事。
另外 paddlepaddle-gpu==3.2.1 是 Paddle 首个支持 Windows GPU 的 3.x 版本,终于不用再被 protobuf==3.20.2 和 numpy<2.0 绑架了。
PaddleOCR-VL-1.5 给我的感觉,像一个经验丰富、手脚麻利的资深助理。
五、实测数据一图看清
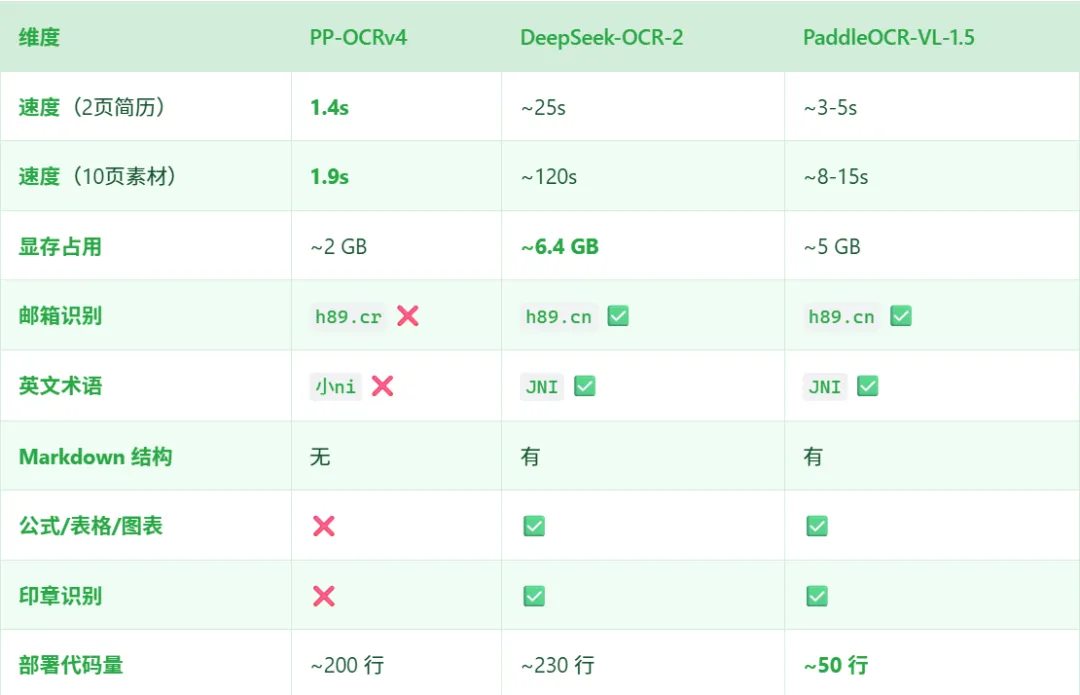
一个有意思的发现:PP-OCRv4 的速度优势在复杂页面上会消失。测试了一份超大页面(4768x10761)的 PDF,它跑了 38 秒,因为默认检测边长限制 2048,大页面需要分割处理。
六、那些让我想摔键盘的坑
PP-OCRv4 的五连坑
1. cuDNN 的隐藏依赖
报错 cudnn64_8.dll not found (error code 126)。排查半天发现,cudnn_cnn_infer64_8.dll 依赖 zlibwapi.dll,而 cuDNN 安装包居然没带这个文件。最后从 PyTorch 包里偷了一个放到项目目录,通过 PATH 加载。最坑的是 os.add_dll_directory() 对 Paddle 完全无效,必须用环境变量。
2. CUDA 版本对不上
系统装的是 CUDA 12.8,但 paddlepaddle-gpu==2.6.2 是 CUDA 11.8 编译的。驱动虽然能向下兼容,但运行时库不匹配,报 cublasLt64_11.dll 缺失。最后只能两个 CUDA 版本共存,Paddle 走 11.8 的路径。
3. PaddlePaddle 3.x 没有 Windows GPU
试着手贱升级,结果 PyPI 上 paddlepaddle-gpu 最高只有 2.6.2。官方 CUDA 12 的 wheel 也一样。结论:Windows 用户在此之前被 2.x 锁死了。
4. NumPy 和 protobuf 的版本牢笼
numpy必须<2.0,装 2.x 直接 ABI 报错protobuf必须精确等于3.20.2,多一个小版本都报Descriptors cannot be created directly- 安装时得
--force-reinstall硬降级,满屏红色警告看得人心惊肉跳
5. API 格式突变
paddleocr==2.7.3 返回 list,3.5.0+ 返回 dict。我代码刚按 list 写好,一升级直接 AttributeError。最后只能写兼容逻辑,两边都判断。
DeepSeek-OCR-2 的坑
vLLM 在 Windows 上是个谎言
官方说支持 vLLM 加速,我兴冲冲装完 vllm==0.8.5,结果运行时报 vllm._C 模块未构建——这玩意在 Windows 上需要从源码编译 C++ 扩展,编译失败。最终只能用 HuggingFace Transformers,速度差了好几倍。
PaddleOCR-VL-1.5 的坑
1. 模型下载是个大关
首次运行要联网下载 2-3GB 模型。我在公司跑得好好的,回家想离线用,傻眼了。后来学乖了,先把 .paddlex/official_models/ 整个复制走。
2. 显存不是无限的
8GB 看起来多,但大 PDF(50页+)照样 OOM。不过好在可以 --device cpu 降级,就是速度慢 5-10 倍,至少能跑完。
3. 2.x 和 3.x 不能混用
PP-OCRv4 和 VL-1.5 必须各用各的虚拟环境。我一开始图省事共用 venv,结果 ABI 不兼容,报错信息看得我一头雾水。模型缓存可以共用 ~/.paddlex/,但 Python 包必须隔离。
七、到底该选谁?
折腾完三个方案,我的建议很直接:
选 PP-OCRv4,如果你:
- 只想快速扒文字,不在乎格式
- 显存紧张(比如 4GB 的 GTX 1650)
- 能接受"近视速记员"级别的准确率
- 对延迟极度敏感
选 DeepSeek-OCR-2,如果你:
- 需要高质量的 Markdown 输出
- 想自动提取 PDF 里嵌的图片
- 主要处理单页或少页文档(比如发票、证件)
- 愿意用时间换质量,且显存 ≥ 8GB
选 PaddleOCR-VL-1.5,如果你:
- 要处理复杂文档(论文、报告、扫描书)
- 需要公式、表格、图表、印章全识别
- 不想写太多代码,追求开箱即用
- 希望速度和质量有个平衡
八、写在最后
这次折腾让我明白一个道理:技术选型不是选最好的,而是选最对的。
PP-OCRv4 快但糙,DeepSeek-OCR-2 好但慢,PaddleOCR-VL-1.5 在两者之间找到了不错的平衡点。如果你只是偶尔转一两页 PDF,PP-OCRv4 完全够用;但如果你要让 AI 真正"读懂"一份复杂文档,VLM 方案几乎是必经之路。
另外 Windows 本地跑深度学习真是个修行过程。CUDA 版本、DLL 缺失、Python 包冲突……每一步都可能踩坑。好在这三个方案我都已经调通了,配置好的环境就在各自的目录里,下次重装系统不至于从头再来。
