 夜雨聆风
夜雨聆风
最近公众号又改版了,开源老铁们一定星标一下 开源小分队,不然后续真的会失联~星标方式就放在下方了。
大家好,我是了不起!
RAG应用时,PDF解析是最大的“暗坑”。传统工具不仅搞不定多栏排版和复杂表格,还常因依赖云端API或GPU带来隐私泄露与高成本问题。
今天介绍一款专为 AI 时代设计的开源解决方案 - OpenDataLoader PDF,它能让你在本地CPU上,高效、安全地搞定所有 PDF 解析难题。
项目简介
opendataloader-pdf是一款面向 AI 数据提取的开源 PDF 解析工具,采用本地确定性解析 + AI 混合模式双引擎架构,无需 GPU、全程离线运行,可将 PDF 精准转换为 Markdown、JSON、HTML 等结构化数据。
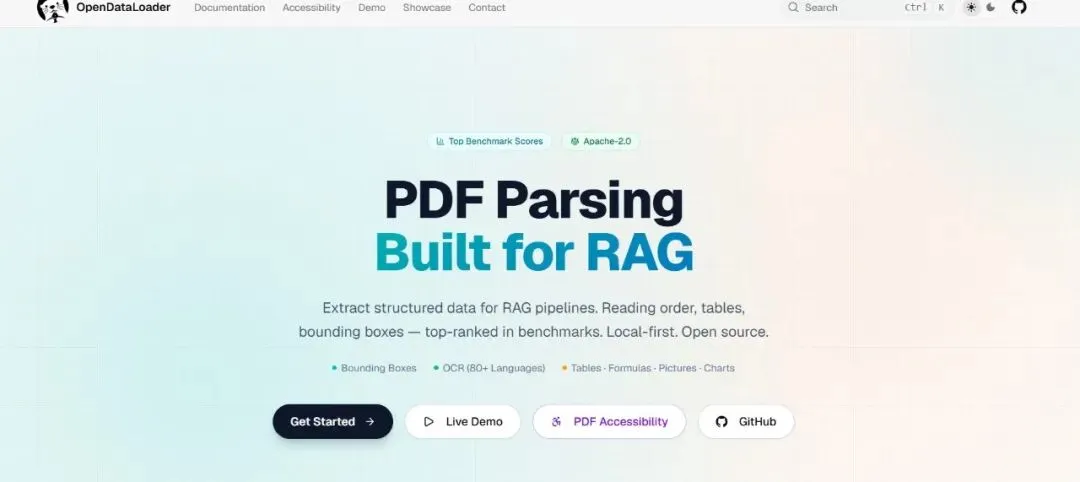
支持多栏排版、复杂表格、公式、OCR 识别,内置 AI 安全过滤,同时提供 PDF 无障碍自动打标签能力。
基准测试综合准确率0.907,位列同类开源工具第一,完美适配 RAG、文档知识库、合规审计等场景
核心特色
双模式解析,速度与精度兼得: 本地规则引擎极速处理常规PDF(0.02s/页);混合AI模式攻克扫描件、复杂表格、公式,表格准确率达0.928。
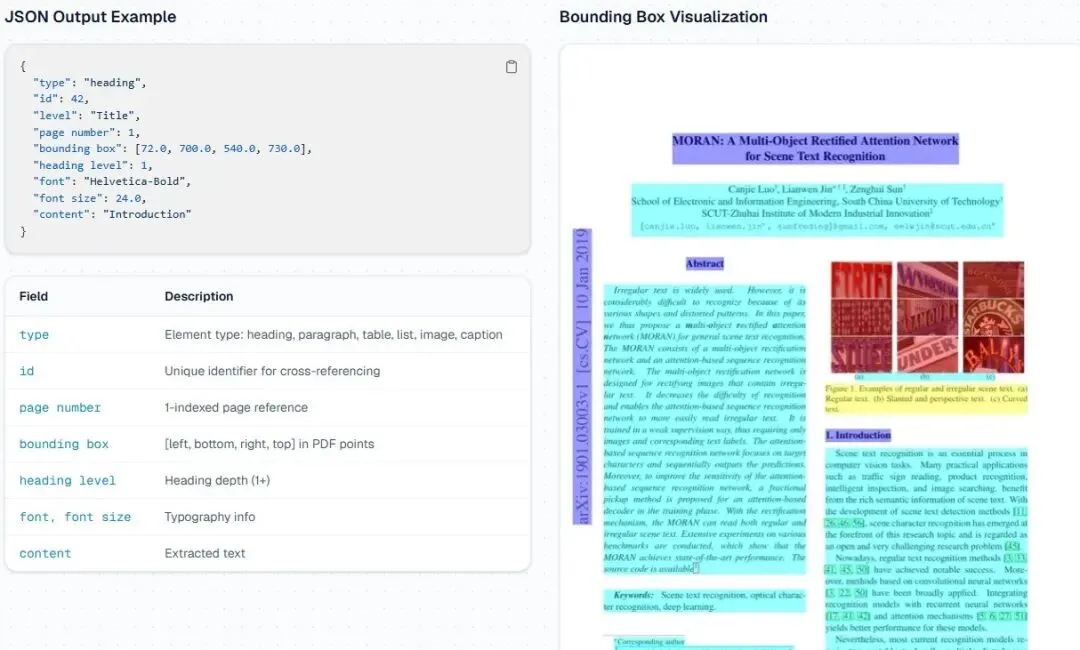
全要素结构化输出: 保留标题层级、列表、表格结构,输出带边界框坐标的JSON,支持原文精准溯源,适配RAG引用场景。
零GPU本地运行,数据绝对安全: 纯CPU驱动,全程离线无云端传输,自动过滤提示注入、隐藏文本等安全风险,满足金融、医疗合规要求。
多场景适配能力: 内置80+语言OCR,支持LaTeX公式提取、图表AI描述,兼容Python/Node.js/Java多语言SDK。
PDF无障碍自动化: 联合PDF协会与veraPDF团队打造,Q2 2026上线开源自动打标签,生成Tagged PDF,助力EAA/ADA合规。
生态无缝集成:原生对接LangChain,批量处理文件夹,输出格式直接用于向量库与LLM上下文。
安装指南
环境要求
Java 11+ Python 3.10+
基础安装(Python)
pip install -U opendataloader-pdf混合模式(扫描件/复杂表格)
pip install -U "opendataloader-pdf[hybrid]"快速调用
import opendataloader_pdfopendataloader_pdf.convert( input_path=["文件1.pdf", "文件2.pdf", "文件夹/"], output_dir="输出目录/", format="markdown,json")Node.js安装
npm install @opendataloader/pdfJava集成(Maven)
<dependency><groupId>org.opendataloader</groupId><artifactId>opendataloader-pdf-core</artifactId></dependency>小结
opendataloader-pdf精准击中了AI开发者在数据预处理阶段的痛点:速度、隐私、准确率,通过“确定性算法为主,AI为辅”的混合策略,在保证极致性能的同时,提供了企业级的安全与合规保障。
https://github.com/opendataloader-project/opendataloader-pdf写在最后
如果你:不想打工,但没方向;想做副业,但一直赚不到钱;那这次,别再错过了。
我去年All in AI跨境,砸了几十万、跑了半年,把整条链路跑通;往期学员90%以上拿到了结果,为了让更多朋友了解这个项目。
我们决定开放一场:《3天AI跨境实操训练营》,这3天,你能学到的是:
从0开店的完整流程 AI选品 + 上架实操 跑通第一单的完整路径
重点不是听课,而是:带你亲手跑一遍闭环。
【注意】
这个训练营,后续是正常收费99元的,这一次是首次对外开放,限时免费。
而且只开放一批名额,满了就关。按照我们往期的经验:执行力强的人,3天就可以把店铺开起来,甚至跑出第一单。

加我微信,备注:小分队
