 夜雨聆风
夜雨聆风一个算法被发明了两次。第一次在 1974 年,躺在哈佛图书馆的书架上被世界遗忘。第二次在 1986 年,引爆了现代深度学习。今天,它让一万张 GPU 同时运转,在几千亿维的几何空间中,寻找一个函数的完美形状。
全文约 6000 字,预计阅读时间 13 分钟。
(一)
解法就在图书馆里,但没人读
1974 年,哈佛大学。博士生 Paul Werbos 在写一篇奇怪的论文。
他的导师 Karl Deutsch 是政治科学家——跟计算机科学没有半点关系。但 Werbos 试图把弗洛伊德 1895 年的手稿《科学心理学大纲》翻译成数学模型。弗洛伊德当年提出:大脑的学习信号必须在神经元之间双向流动,从前往后,再从后往前。
Werbos 盯着这个想法,写出了一个从输出层倒着往回算的链式法则。今天全世界管它叫反向传播。他把完整推导写进博士论文——然后所有期刊都拒了。
为什么?倒回五年前。1969 年,Minsky 和 Papert 出版《感知机》,严格证明单层感知机连 XOR 逻辑都学不会。证明本身是对的——单层感知机是线性分类器,XOR 是非线性问题。但学界把结论无限放大:所有神经网络都是死路。Minsky同年拿图灵奖,威望压下来,神经网络经费一夜清零,第一个冬天降临。
解法已经在哈佛图书馆的书架上了。但整个领域被一个过杀的错误共识堵住耳朵——整整 12 年。
直到 1986 年。Rumelhart、Hinton 和 Williams 独立重新发现反向传播,发表在 Nature 上。那篇论文的态度很冷静:它不急着证明这就是大脑真正的学习方式,只证明一件事——反向传播能把误差信号传回隐藏层,让网络自己学出有用的内部表示。神经网络从此与心理学脱钩,变成纯粹的工程问题。

▲ 三个时代的三张书桌:1969 年 Minsky 黑板前的红叉、1974 年 Werbos 在图书馆昏灯下无人阅读的论文、1986 年 Hinton 屏幕上的loss.backward()亮起。
(二)
训练的本质:找一个超级函数
训练的本质是什么?一句话就能讲清楚——“找一个函数”。
但不是普通的函数。是一个超级函数:几千亿个可调参数,数学上叫“万能逼近器”。理论上,只要参数够多,这个超级函数可以逼近任何合理的输入输出映射——猫的照片进去,“猫”出来。一段中文进去,流畅的英文翻译出来。一个问题进去,有逻辑的回答出来。
传统编程是你自己写这个函数。输入是猫照片,你写三百条 if-else 规则来识别耳朵、尾巴、胡须——但没耳朵的猫还是猫,不叫的猫还是猫。规则永远写不完。传统编程是加法:往代码库里堆逻辑。
训练呢?你不写函数。你给例子。给模型看一百万张标好“这是猫”或“这不是猫”的图片,让它自己从数据里把函数“长”出来。训练是减法——模型每次猜错,就回头修正,重复几十亿次,直到函数的行为越来越接近你的期望。
每一组参数的取值,都让这个超级函数呈现出一种不同的“形状”。参数就是函数形状的旋钮——拧一下,函数的行为就变一点。几千亿个旋钮,能拧出近乎无穷多种形状。训练的终极目标,就是在这些形状构成的空间中,找到最接近你期望的那一个。
 ▲ 三种范式的对比。左:传统编程——人手写规则,输入进黑盒,输出结果。中:训练——人不写规则,给一堆“输入→正确答案”的例子,让模型自己反向传播修参数。右:超级函数——训练结束后产物:一个几千亿旋钮的函数,任何输入都能吐出合理的输出。
▲ 三种范式的对比。左:传统编程——人手写规则,输入进黑盒,输出结果。中:训练——人不写规则,给一堆“输入→正确答案”的例子,让模型自己反向传播修参数。右:超级函数——训练结束后产物:一个几千亿旋钮的函数,任何输入都能吐出合理的输出。
前向传播与损失曲面
刚出生的模型是一团乱麻——所有旋钮拧在随机位置。训练的第一步是先让它猜一次:数据从左到右穿过一层又一层神经元,每一层做同一件事——把上一层输出乘上自己的权重矩阵,过激活函数,传给下一层。99% 的计算量花在矩阵乘法上。
最后一层拍板:“这是猫,置信度 73%。”正确答案是 100%,差了 27%。
这个 27% 在数学上意味着什么?把几千亿个参数的所有可能取值画成坐标轴——几千亿维的空间。在这个空间中每一个点上,这个超级函数的误差值漂浮起来,形成一片无边无际的几何曲面。这就是损失曲面。高的地方函数形状烂——猜得离谱。低的地方函数形状好——猜得准。训练的目标只有一个:在这片几千亿维的山脉中找到最低的谷底——找到那个让误差最小的函数形状。
交叉熵损失函数就是这个曲面的测绘仪。它衡量的不是简单的“猜对还是猜错”——而是函数输出的概率分布和真实答案在几千亿维空间中的几何距离。为什么不能用准确率当损失函数?因为它不可导,是一块没有“下坡方向”的平地。交叉熵处处光滑,让曲面有了起伏,有了“往下走”的指南针。
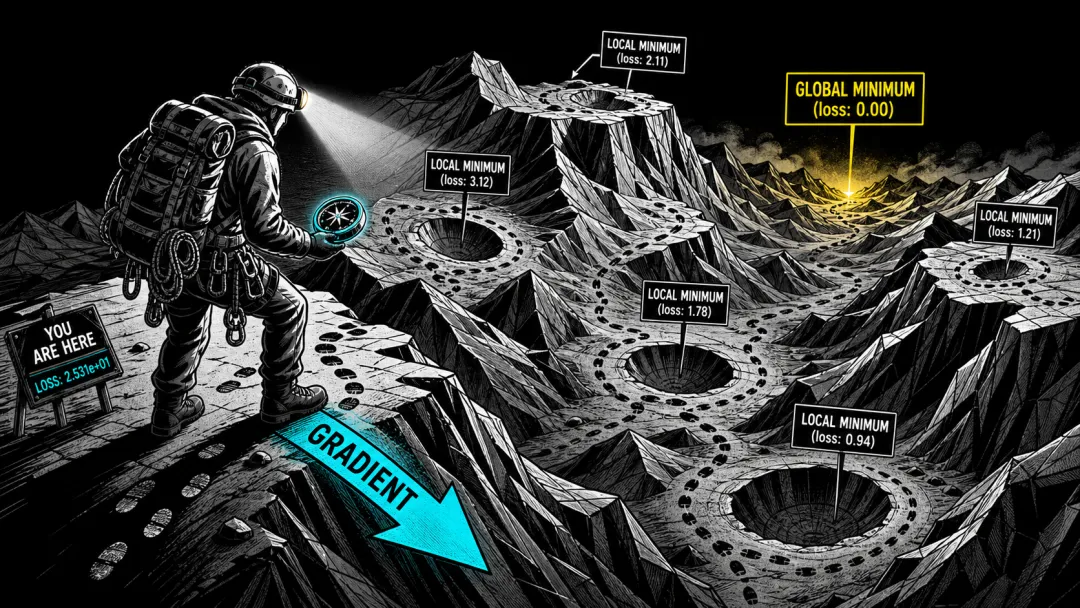 ▲ 几千亿维损失曲面的三维截面。一个登山者站在崎岖的山脊上——每一个点代表超级函数的一种形状。手中的指南针指向最陡的下坡方向。远处谷底隐约可见——那是全局最优的函数形状。
▲ 几千亿维损失曲面的三维截面。一个登山者站在崎岖的山脊上——每一个点代表超级函数的一种形状。手中的指南针指向最陡的下坡方向。远处谷底隐约可见——那是全局最优的函数形状。
反向传播:在这片曲面上导航
知道“当前函数形状有多差”只是一半。更关键的:这几千亿个参数旋钮,每个该往哪个方向拧、拧多大?
梯度告诉你在损失曲面上“最陡的下坡方向”。梯度下降就是沿着这个方向每次迈一个纳米级步子。反向传播就是计算梯度的算法:从最后一层开始一层层往回推,精确到单个参数——“为了让函数行为更接近期望,这个旋钮该往正方向拧还是负方向拧?拧多大?”你写的loss.backward()那一行代码,框架在后台展开了几千亿级的链式法则。
但问题来了。Sigmoid 激活函数导数最大只有 0.25,100 层后梯度衰减到忽略不计——深层旋钮完全不知道该往哪拧,这是梯度消失。残差连接为它开了“高速公路”——输入直接跳过中间层加到输出上,梯度多了一条没被衰减过的通道直达浅层。
 ▲ 工程师倒退着从梯子顶端往下爬,每退一步拧一下当前层的巨型齿轮旋钮——在几千亿维的空间中一步一步逼近那个最优的函数形状。仪表盘上的损失值从 27% 缓缓降向 0.0001%。
▲ 工程师倒退着从梯子顶端往下爬,每退一步拧一下当前层的巨型齿轮旋钮——在几千亿维的空间中一步一步逼近那个最优的函数形状。仪表盘上的损失值从 27% 缓缓降向 0.0001%。
至于优化器:SGD 沿梯度走固定步长,在峡谷里震荡;Adam 给每个参数分配独立学习率,陡峭处迈小步、平坦处迈大步;AdamW 把权重衰减从 Adam 的自适应逻辑里解耦出来。原理就这三句话。
从一步到一个完整的训练
上面讲的是一次“猜-差-改”。但训练不是做一次——是重复几百万、几千万次。这个重复过程有它自己的底层概念。
一百万张图片,你不可能一口气全塞给 GPU——显存放不下。所以数据被切成小批量,每次喂几百到几千张。模型在这一小批上猜一遍、算平均损失、反向传播修一次参数。这一个完整的“猜-差-改”循环,叫一步。
把训练数据里所有样本都用过一遍,叫一个轮次(epoch)。一个 epoch 包含很多步。小模型和监督训练常谈 epoch;大模型预训练更常谈总 token 数和训练步数——因为语料太大,很多时候不是把同一批数据反复刷几十遍,而是在有限数据和有限算力之间精打细算。
但光是反复修参数不够——你怎么知道模型是“学会了”还是“背下来了”?所以数据从一开始就被切成三块:训练集(用来修参数,占大头)、验证集(训练过程中定期检查用的——如果验证集上的表现也在变好,说明模型真的在学规律)、测试集(最终考试,只在训练结束后用一次)。如果训练损失一路下降、验证损失却不降反升——这就是过拟合,模型在背答案,不是在学规律。
训练过程中你盯得最紧的,就是损失曲线。它应该一路下滑,逐渐趋于平坦——这叫收敛。如果曲线突然跳起一个尖峰,多半是某个 batch 的数据太脏或梯度爆炸了。如果降到某个值就再也下不去——你可能撞到了模型容量的天花板。
这些概念——epoch、训练/验证/测试划分、收敛、过拟合——就是训练最基础的语言。
术语 | 一句话 |
参数 | 超级函数的可调旋钮,几千亿个 |
前向传播 | 数据过一遍网络,算出预测 |
损失 | 预测和真实答案的差距 |
梯度 | 损失曲面上最陡的下坡方向 |
反向传播 | 从最后一层倒着算梯度 |
一步 | 一次完整猜-差-改循环 |
学习率 | 每次拧旋钮的幅度 |
Epoch | 训练数据完整过一遍 |
收敛 | 损失不再下降,函数形状稳了 |
过拟合 | 训练集考满分、验证集不及格 |
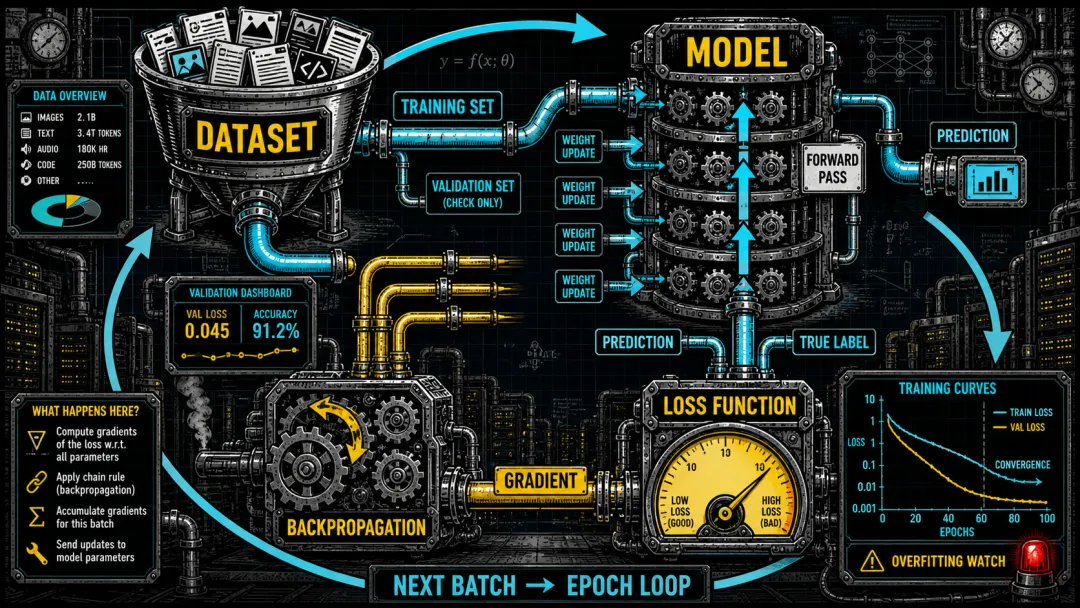
▲ 训练循环流水线。数据集切分后,训练集走闭环:前向传播→损失计算→反向传播→更新参数→下一批——反复循环。验证集只走前向检查,不参与参数更新。外围大箭头标注 epoch 循环
(三)
训练中的关键技术:集群、并行与精度
理解了单步怎么修参数、也理解了一整个训练怎么跑,现在看工程怎么把它放大到万亿参数。
一张 GPU 根本不够用
一个 1750 亿参数的 GPT-3,FP16 权重本身就要约 350GB。训练时还要放梯度、优化器状态、主权重和中间激活值——光这些账加起来就是 TB 级。一张 H100 只有 80GB 显存。你至少需要几十张 H100 像一个整体一样协同工作。
三种并行,三种物理代价
数据并行最直观:每张卡持有完整模型,各吃不同数据,梯度用 all-reduce 同步。PyTorch 里这就是 DDP(Distributed Data Parallel),最通用的训练并行方式。缺点是一张卡放不下完整模型就歇菜。
张量并行把单层内的权重矩阵切到多张卡上,各算一块再拼起来。但每一层的前向和反向都需要通信——频率极高。单机 8 卡间 NVLink 双向 900 GB/s 能跑,跨机器 InfiniBand 单端口仅 50 GB/s(400 Gb/s),即使多端口聚合也远低于 NVLink——通信延迟立刻淹没并行加速。所以张量并行几乎只在单机 8 卡内做。不是工程偏好,是物理带宽画下的围墙。
流水线并行按层切分,数据像流水线流过。下游 GPU 等上游产出时是空闲的——“流水线气泡”。1F1B 调度交替执行前向和反向,把气泡压到最小。只传层间激活值,通信量远小于张量并行,适合跨机器部署。
三种切法的物理布局:张量并行在 NVLink 域内(通信密度极高),流水线并行跨机器(通信量低),数据并行在流水线各阶段上铺开。GPT-4 级别训练三者缺一不可。
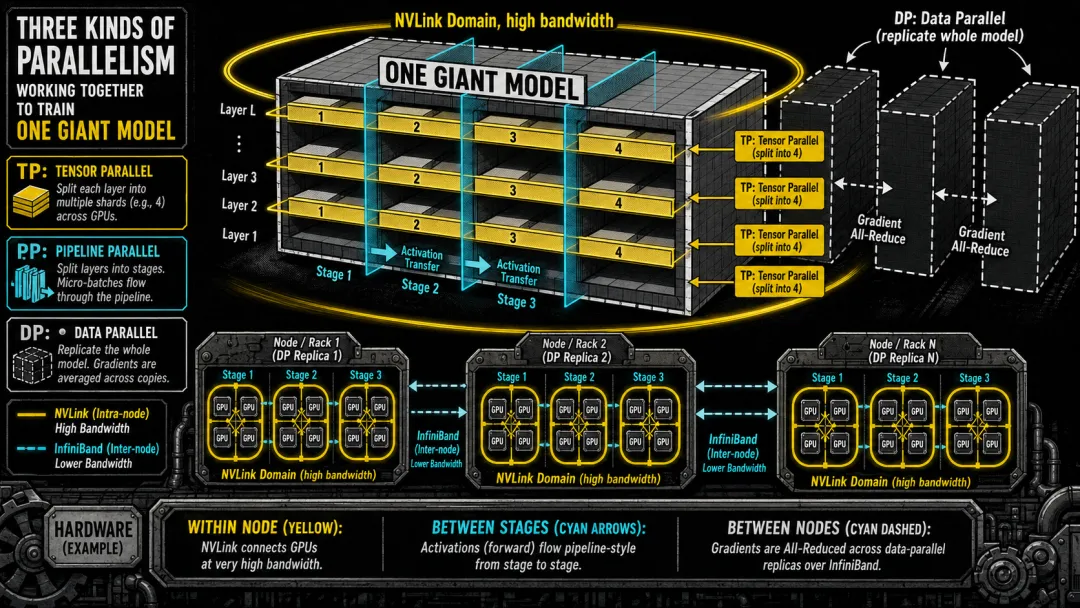 ▲ 3D 并行架构:张量并行(TP)横向切、流水线并行(PP)纵向切、数据并行(DP)复制铺层。NVLink 域承受高频通信,InfiniBand 域只走低频传输。
▲ 3D 并行架构:张量并行(TP)横向切、流水线并行(PP)纵向切、数据并行(DP)复制铺层。NVLink 域承受高频通信,InfiniBand 域只走低频传输。
ZeRO:不存重复的东西
在标准数据并行中,每张卡持有完整模型,Adam 的 m 和 v 在 128 张卡上存了 128 份完全相同的副本。微软 DeepSpeed 的 ZeRO 分三阶段消灭这种冗余:阶段 1 优化器状态分片(省 4× 显存),阶段 2 梯度分片,阶段 3 参数本身分片。ZeRO-3 + 张量并行 + 流水线并行是当前大模型训练的事实标准。
Ring All-Reduce
梯度同步是分布式训练中最频繁的全局操作。朴素方法——所有人发给参数服务器再广播——1000 张 GPU 同时灌一台机器,网卡直接烧穿。Ring All-Reduce 让 GPU 排成逻辑环,每张卡只和左右邻居通信。梯度切段沿环转满一圈,所有人凑齐全局平均。单卡通信量不再随着 GPU 数量线性爆炸,而是趋近于参数量的常数倍——这是分布式训练能扩展到几千张 GPU 的通信基础。
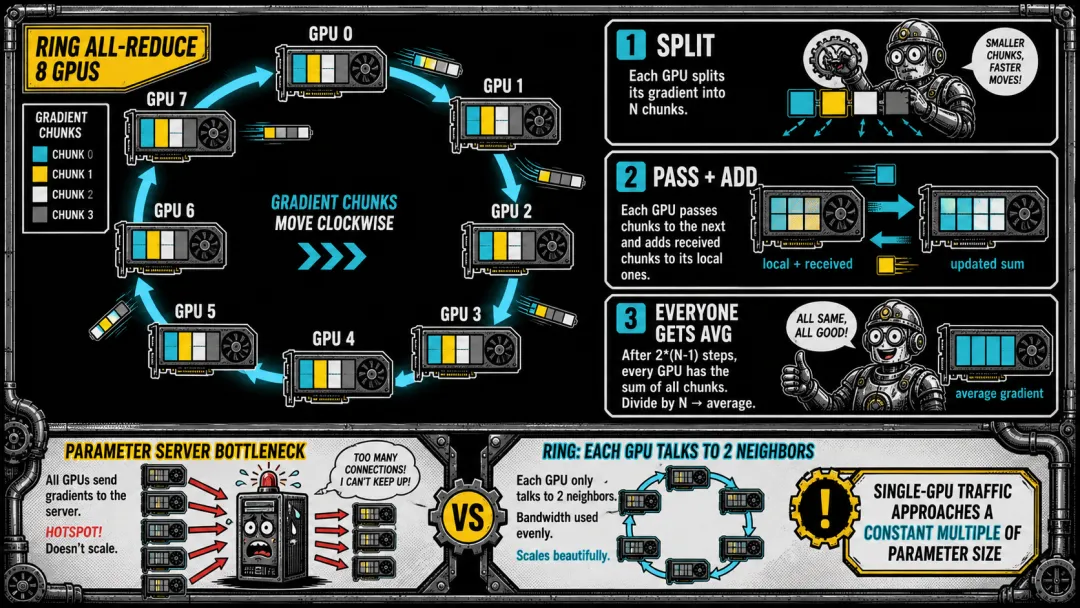 ▲ N 张 GPU 围成逻辑环,梯度段沿环流转。单卡通信量趋近于参数量的常数倍,不再随 GPU 数量线性爆炸。
▲ N 张 GPU 围成逻辑环,梯度段沿环流转。单卡通信量趋近于参数量的常数倍,不再随 GPU 数量线性爆炸。
以上解决的是多卡协同的问题——把找函数的工作拆到集群上。但回到单卡内部,还有另一个维度的优化没碰。
混合精度的基本功:榨干单卡每一滴算力
单卡内部还有优化空间。H100 的 FP16 Tensor Core 算力是 FP32 的 6 倍。用低精度训练,显存砍半,计算翻倍——前提是不溢出。FP16 只有 5 位指数,最大值 65504,稍大激活值就溢出到 inf,污染整个 batch 的梯度。BF16 把指数位扩到 8 位——和 FP32 一样宽,动态范围相同。训练时“不溢出”远比“算得精确”重要——溢出是灾难性的,精度损失可以在迭代中消化。
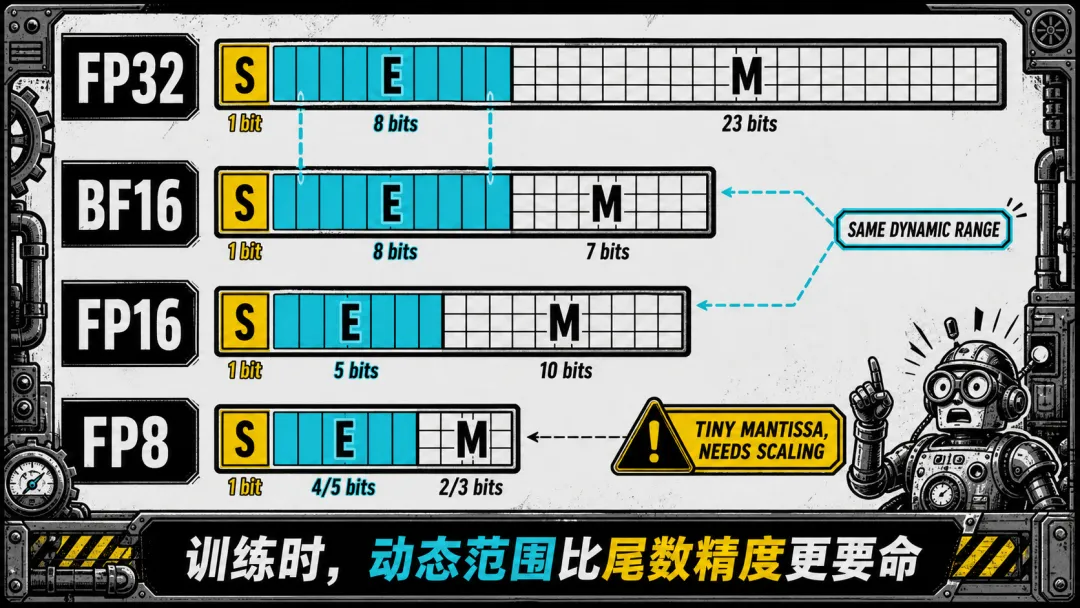 ▲ FP32、BF16、FP16、FP8 精度条对比。BF16 和 FP32 指数位相同(8位)——动态范围一致。FP8 尾数仅 3-4 位,精度极低。
▲ FP32、BF16、FP16、FP8 精度条对比。BF16 和 FP32 指数位相同(8位)——动态范围一致。FP8 尾数仅 3-4 位,精度极低。
 ▲ 训练集群剖面。几百张 GPU 全速运转,风扇吹出燃烧的美元钞票。监控屏幕上蓝色损失曲线缓缓下行,红色电费曲线陡峭上升——交叉点上打着一个问号。
▲ 训练集群剖面。几百张 GPU 全速运转,风扇吹出燃烧的美元钞票。监控屏幕上蓝色损失曲线缓缓下行,红色电费曲线陡峭上升——交叉点上打着一个问号。
(四)
硅幕已落下:不是所有人都有资格训练
你理解了分布式训练和混合精度。但一个更残酷的事实是:不是所有人都有资格用这些工具。
2022 年 10 月,美国系统性收紧先进 AI 芯片出口管制,NVIDIA 的 A100 和 H100 被禁止卖给中国。NVIDIA 推出中国特供版 A800 和 H800——互联带宽被砍,勉强能用。2023 年 10 月,管制再次收紧,连 A800 和 H800 也被禁了。
现在回看前面讲的分布式训练,就知道这意味着什么。H800 的 NVLink 带宽比 H100 低——而张量并行恰恰靠 NVLink 的高带宽才能跑。跨机器的 InfiniBand 也被卡——流水线并行和数据并行靠它同步梯度。Ring All-Reduce 再巧妙,也架不住通信管道本身变窄了。整条技术路线上每一个节点都被掐住。
但你不能停下——模型不训练,产品就死了。这就是 DeepSeek 故事的真正起点。
(五)
DeepSeek:被制裁逼出来的最优解
DeepSeek V3——6710 亿参数的 MoE 模型——在 2048 张 H800 上训练。注意,是 H800,不是 H100。论文披露的预训练计算量是 278.8 万 H800 GPU 小时;如果按每 GPU 小时 2 美元估算,训练计算成本约 558 万美元。这个数字很惊人,但它不是完整研发成本——不包含前期实验、数据工程、人员、机房和硬件折旧。Meta 训练 LLaMA 3.1 405B 用了 16000 多张 H100,公开讨论里常被拿来对比的,是 DeepSeek 低得多的算力消耗。Andrej Karpathy 评价:“算力消耗仅为 LLaMA 3 405B 的 1/11,表现却更强。”
怎么做到的?
向前一步:FP8。 FP8 只有 3-4 位尾数,直接套用 BF16 策略梯度会下溢到零。DeepSeek 的解法不是数学技巧,而是精确到硬件管线的工程编排。GPU 内部每个 SM 有一小片约 228KB 的 SRAM,带宽是 HBM 显存的十几倍——GPU 天然就把大矩阵切成能塞进 SRAM 的小块(tile)。DeepSeek 的 FP8 策略与这个硬件约束共生:激活值按小 tile 缩放,权重按 block 缩放,数据在 SRAM 里校准后送入 FP8 Tensor Core 全速计算;部分结果再切回高精度累加,保证精度不丢。细粒度缩放——不是给整个张量一把尺子,而是让每个小块都有自己的刻度。
这不是“降精度”的妥协。这是一次数据在 SRAM、寄存器、Tensor Core、HBM 之间的精确流动编排。DeepSeek 的工程师在编排每一比特数据在芯片内部的物理旅程。结果不是简单省点显存,而是把 H800 被限制后的计算、显存和通信能力尽量榨干。
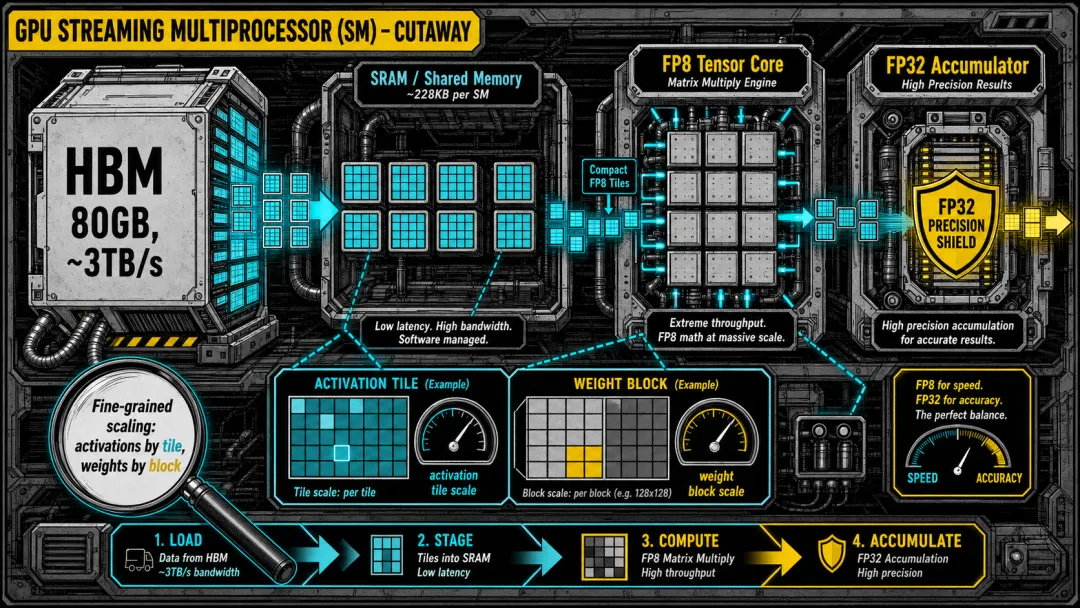 ▲ GPU SM 内部视角。矩阵切块塞进 SRAM,每个 tile 独立缩放送入 Tensor Core 以 FP8 计算,累加器恢复 FP32。缩放因子切换点和物理存储边界精确对齐。
▲ GPU SM 内部视角。矩阵切块塞进 SRAM,每个 tile 独立缩放送入 Tensor Core 以 FP8 计算,累加器恢复 FP32。缩放因子切换点和物理存储边界精确对齐。
全文收束:训练的故事
他们在被阉割的通信带宽上跑分布式训练,在锁死的硬件天花板下发明 FP8 细粒度缩放。训练计算成本只有美国同行的一小部分,不是因为数学比美国好——是因为每一层技术栈都被逼到墙角,只能从软件的缝隙里挤出性能。
从 Werbos 1974 年在哈佛昏灯下写出链式法则,到 DeepSeek 在 H800 的 SRAM 里精确编排 FP8 tile 的数据流动——训练的故事横跨了半个世纪。内核从未变过:前向传播猜一次,反向传播修一次。几十亿次下来,几千亿维的参数空间中,这个超级函数被一点一点拧向最优的形状。
变化的是物理边界被一步步推开。精度不够?混合精度顶上。显存不够?三维并行和 ZeRO 顶上。算力不够?几千张 GPU 用 Ring All-Reduce 捏在一起顶上。连卡都买不到?那就在被阉割的硬件上重新设计每一层软件的编排策略,继续找那个函数的最优形状。
训练的本质是找一个超级函数。但为了找到它,一群工程师在半个世纪里推开了所有能推开的物理极限——在被制裁逼到墙角的时候,也从来没有停下。
 ▲ 当互联网数据不再像自来水一样无限流出,训练策略会撞上数据墙。墙后面可能是合成数据、环境强化学习,也可能是一个还没被命名的新范式。
▲ 当互联网数据不再像自来水一样无限流出,训练策略会撞上数据墙。墙后面可能是合成数据、环境强化学习,也可能是一个还没被命名的新范式。
今日思考:如果互联网数据总量有限,当数据不再是无限资源,训练策略的下一次范式转换会是什么?——是合成数据的规模化提纯?是强化学习让模型从环境中实时学习?还是某种完全跳出“大数据预训练”框架的新范式?
参考资料
•Perceptrons (1969)— Minsky & Papert,证明了单层感知机的 XOR 局限,触发第一个 AI 冬天
•Beyond Regression (1974) — Paul Werbos 博士论文,反向传播算法的首次完整推导
•Learning representations by back-propagating errors (1986) — Rumelhart, Hinton & Williams,重新发现并普及反向传播
•DeepSeek-V3 Technical Report (2024)— FP8 混合精度训练的工程实践
•ZeRO: Memory Optimizations Toward Training Trillion Parameter Models (2020) — Microsoft DeepSpeed,优化器/梯度/参数三阶段分片
•Megatron-LM (2020) — NVIDIA,张量并行的工业级实现
