 夜雨聆风
夜雨聆风如果要评选出人工智能领域最著名的一句话
Attention Is All You Need
一定值得被提名
2017年,8位Google的工程师发表了一篇论文。
论文发表之后,一家创业公司敏锐地抓住了论文中架构的核心思想,用它训练了一个新模型,彻底改变了整个AI圈。
这家公司就是截止到目前市值超过 8000 多亿美元的 OpenAI。
这个模型就是 GPT 系列。
其中GPT 的 T,就是指 Transformer。

而这篇论文的标题就是这句
Attention Is All You Need。
你需要的,只是注意力。
这篇论文首次提出了 Transformer 架构,彻底改变了人工智能的技术路线,催生了OpenAI等行业巨头的迅速崛起。
后来 8 位作者也都离开了 Google,其中的 7 位选择了创业,
而他们创立的公司,估值也普遍达到了数亿到数十亿美金。
一篇论文的背后催生的商业帝国价值实在让人疯狂,
为什么今天的大模型,都活在《Attention Is All You Need》的影子里。
有时候,一场技术革命的开头,看起来像一句很狂的话。
《Attention Is All You Need》
这个标题翻译得再直一点,大概就是,你只要注意力就够了,其他都不需要。
说真的,这种标题多少有点要掀桌子的意思。
读懂了这篇论文,就掌握了通用生成式大模型的核心思想。
要理解 Transformer,我们先看它出现之前,到底存在什么问题。
回到 2017 年之前,
AI 处理自然语言,靠的主要是一种叫 RNN(循环神经网络)的技术。
RNN 的工作方式,就像一个一字一句,按顺序读书的学生。读到「我」,记住「我」,然后读「今」,然后读「天」,然后读「买」……每读一个字,它都把前面的信息往后带一点。
后来的 LSTM、GRU,都是在这条路线上做的改良。
听起来很合理,对吧。我们读句子不也是这样吗。
可读着读着,问题就来了。
RNN 有两个非常棘手的问题。
第一个就是记性不好,
一句很短的话,还撑得住。
句子一长,前面的信息就容易被冲淡。
「我昨天在书店买了一本科幻小说,晚上回家洗完澡,泡了杯茶,坐到沙发上,才开始读它。」
人当然知道最后那个「它」指的是前面的「科幻小说」。
但是机器如果靠RNN,走到最后时,那本书的影子有可能就要忘记了。
它可能会猜「它」指的是茶,或者沙发。
你想想看,这像不像传话筒。
人一多,距离一长,前面说过的话就开始失真。
越长的句子,RNN 越容易犯糊涂。
而且,还慢。
这是另一个更要命的问题。
RNN 这条路线天然很难并行。
前一个词没算完,后一个词就不好算。
这在今天的 GPU、TPU 世界里,特别吃亏。因为这些硬件最擅长的事,不是耐心排队,而是大家一起算。
但 RNN 的结构决定了它只能排队一个个来,完全浪费了快速发展的底层能力。
后来人们也不是没有想办法补救。
在 Transformer 之前,注意力机制其实已经出现了。那时候它更像给老房子加了个外挂窗户,翻译模型在生成一个词的时候,可以回头看一看原句里哪些地方更相关。
是有一定的效果。
但房子的主梁还在,还是那套一格一格往前传的结构。
2016年的某一天,谷歌工程师波罗斯库欣在公司吃饭,向同事乌兹科雷特抱怨,说搜索模型里 RNN 太慢了,达不到想要的效果。
乌兹科雷特随口说了一句话,一共五个单词,全是初中词汇:
「Why not use self-attention?」
为什么不用自注意力呢?
就是这句话,推开了一扇门。
二人一拍即合,决定推翻当时风头正盛的 RNN 和 LSTM。
乌兹科雷特后来给这个新项目取了个名字,叫 Transformer。因为他从小是变形金刚的铁粉。他们甚至在项目文档中画了一幅变形金刚的卡通图,然后写了一句底气十足的话:
「We are awesome.」

接下来的内容有点干,我们先喝口水...
进入论文中最精髓的部分,就是这张 transformer 架构图 Encoder-Decoder,
我们只用小学数学知识理解它。
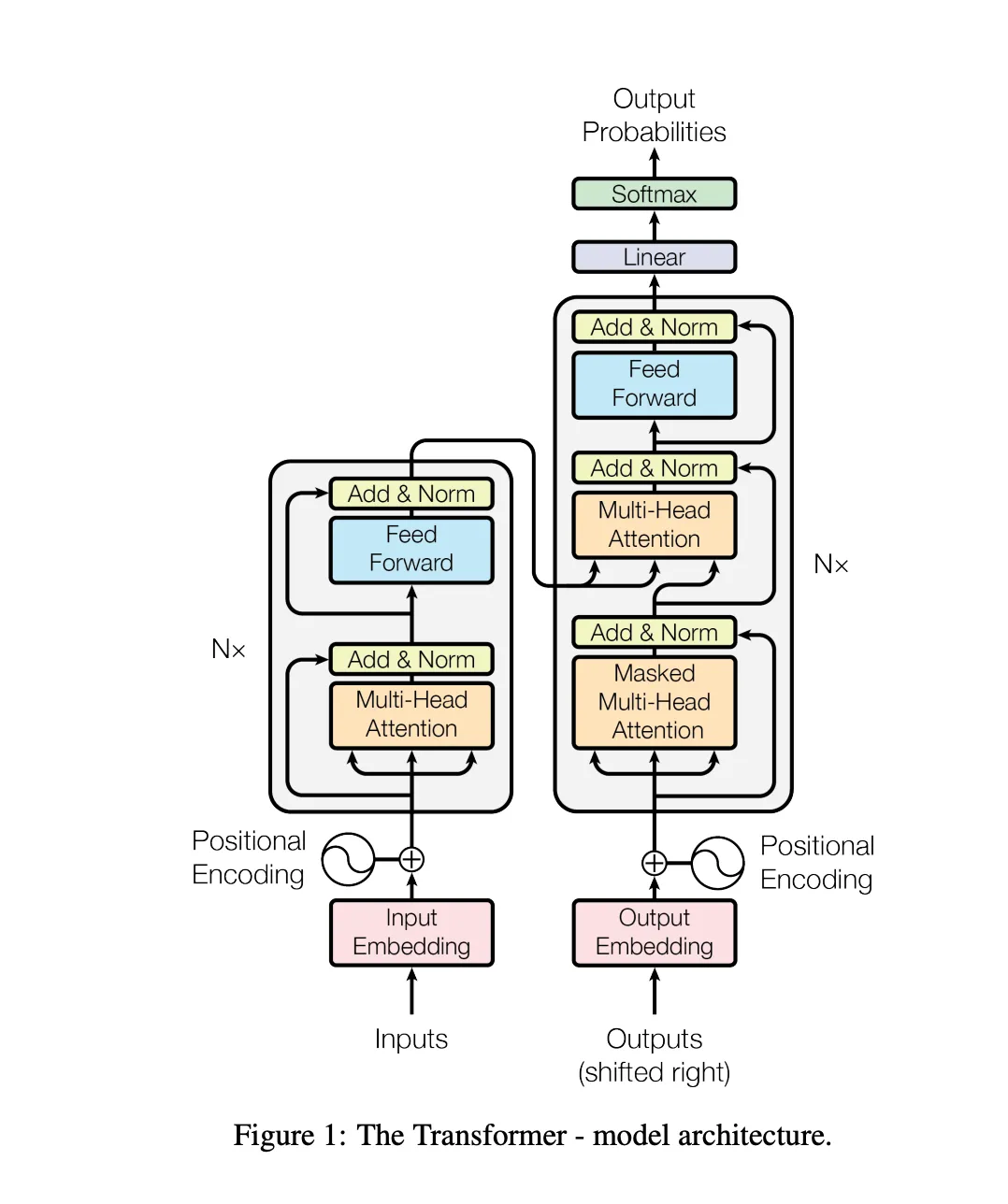
先看左边的最底部 inputs
transformer 架构最初是为了处理翻译任务,在训练模型时喂给模型的语料数据就是输入
进入模型后首先进行input embedding,输入嵌入
我们平时使用的自然语言,模型是无法直接计算的,都会先经过分词被转换成另一个大家每天都能听到的词 token
token 最近也有了自己的官方中文名字 「词元」
这里插一句自然语言转换成 token,不同的模型使用的分词规则是不同的,
举个最直观的例子
中文常用字级分词,‘我爱 AI’会分成 4 个 token
也有模型用词级,‘人工智能神奇’会分词 3 个 token,人工智能算成了一个词。
为了让计算机理解,所以每个词,都要先被转换成一组数字,也就是一个向量,在原始的 Transformer 论文里,这个向量是 512 维的。
比如‘我’变成了 [0.12, -0.33, 0.98 ...]
3 维空间我们很好理解,但是 512 维脑子就乱了,
但是计算机可以很好的利用 512 维的空间,这样每个词的所有特征都能被标记出来,计算机就理解了每一个词的含义。
想象有 512 位侦探,每人只负责观察这个词的一个特定角度,有人专门看「这个词和食物有没有关系」,有人专门看「这个词是不是带情绪的」,有人专门看「这个词更偏向具体的东西还是抽象的概念」
512 个人各自给出一个数值,合在一起就是这个词的向量。
含义相近的词,在这个 512 维空间里会挨得很近,
苹果和香蕉的距离比和石头的距离要近,程序员和代码位置也会比较近。
有了数字表示的向量,这个 512 维的空间就可以运算了。
比如我们用「湖人」的向量减去「洛杉矶」,再加上「芝加哥」的向量,结果就落在「公牛」的附近。
「长城」减 「中国」,再加上「埃及」,结果很可能就是「金字塔」。
如果你好奇,也可以用向量算一下谁更像男版的杨超越...

我们在回头看刚才的例子,湖人指向洛杉矶的向量和公牛指向芝加哥的向量,两个方向几乎一致,
他们都代表 NBA 球队所在的城市,它们表示的语义非常接近,
两个向量的夹角越小,它们的内积,也就是点积就越大,代表这两个向量的意思越接近,
夹角越小,甚至方向相反,相关性就越小。
Embedding 做完之后,每个词都有了自己的 512 维向量。但这里有一个问题是之前提到的 RNN 是按照顺序一次进行的,
Transformer 不是这样,它是同时看所有词的。这就带来了麻烦,它不知道词的顺序。「猫追狗」和「狗追猫」,词完全一样,意思完全却相反。
所以再向上看就是 Positional Encoding 位置编码,要给每个词额外打上一个位置向量,也是一个 512 维的向量。
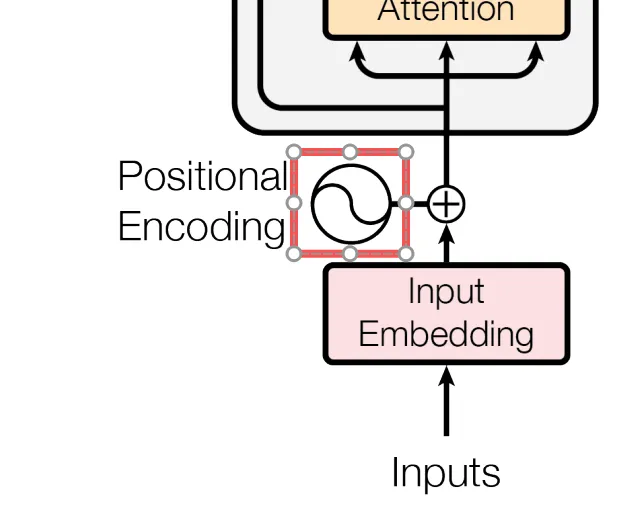
图中我们能看到是一个旋转太极的图形,其实代表的就是论文中的正弦和余弦函数的组合,
偶数维度用 sin,奇数维度用 cos。这里经过位置编码之后可以理解为模型虽然是并行处理,但是也完全理解了每个词真实的顺序位置。
到这里,每个词的向量里,既有「我是什么词」,也有「我在句子里排第几」。
然后我们就来到了 Encoder 最核心的部分,Multi-Headed Attention,多头自注意力机制。
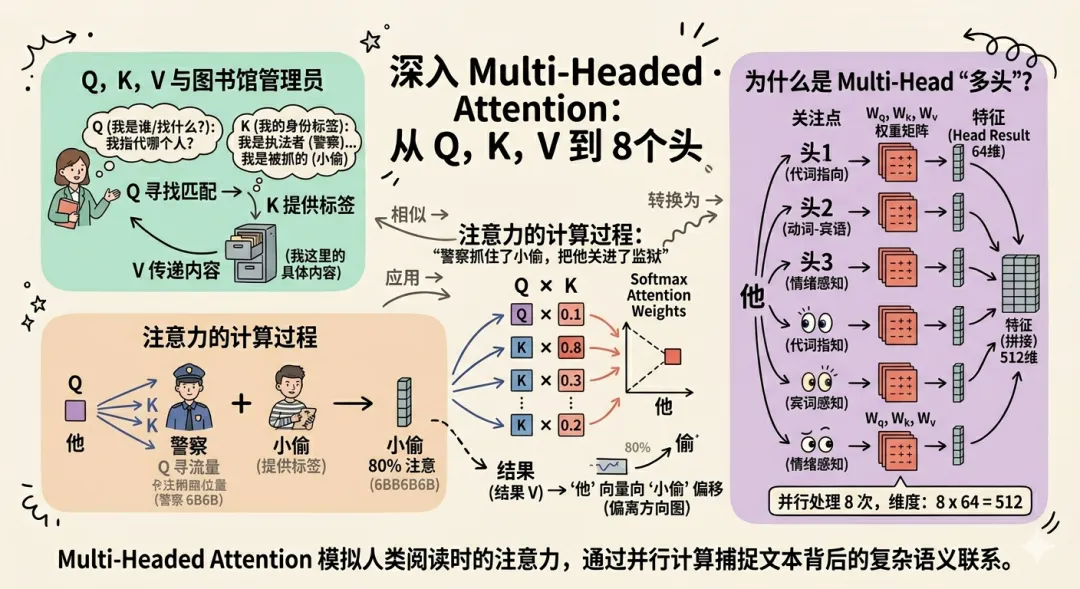
这里的三个剪头代表的就是注意力机制的三个运转核心,Q、K、V,Query、Key、Value。
你可以把句子里的每个词都想象成一个图书馆的档案员。每个档案员要回答两个问题,「我这里存的是什么」是他的 K,「我正在找什么」是他的 Q,「我这里存的具体内容」是他的 V。
举个具体的例子,「警察抓住了小偷,把他关进了监狱」,这句话里「他」这个字,他的 Q 是「我指代的是哪个人?」,
然后拿这个 Q 去碰句子里每一个词的 K。
碰到「警察」的 K,「我是执法者,主动做了抓人这件事」,
碰到「小偷」的 K,「我是被抓的那个人」,和「他」的 Q 比对一下,「被关进监狱」这件事,更可能发生在被抓的那个人身上,所以「他」把大部分注意力投给了「小偷」。
匹配确认之后,「他」去查看「小偷」的 V,也就是「小偷」在这个上下文里具体表达的信息。「他」的 512 维向量,朝着「小偷」的方向发生了偏移,模型因此理解了,这句话里「他」指代的是「小偷」而不是「警察」。
这是一次注意力的计算。
这个例子看似很绕,但是如果是我们自己阅读这句话,看到他时,立刻就知道了指的是小偷。因为我们自动联系了上下文。
transformer 也是这样,它会让 他 去看所有的词,然后判断和谁最相关,如何判断就是上面刚提到的 512维向量特征。
为什么叫Attention注意力机制,因为模仿的就是人阅读时的注意力,把注意力放在重要的信息上。
那 Multi-Head「多头」是什么意思呢。
论文里这个计算不是只进行一次,而是同时并行做 8 次,每次叫一个「头」,每个头用一组独立的参数,从不同角度理解同一句话。
真实的模型中 8 个头其实就是 8 组可学习的权重矩阵(Wq、Wk、Wv),模型训练前全是随机数,训练之后权重就固定了。
有的头可能专门追代词指向,有的头可能专门看动词和宾语的关系,有的头可能专门感知句子的情绪走向。这 8 种关注方式不是人为规定的,是模型自己从训练的数据里自己学出来的。
每个词是 512 维,8 个头各自只处理 64 维,8×64 正好是 512,最后把 8 个头的结果拼起来,维度还是回到 512。
到这里最难的部分我们已经走过了,下面的名词更不需要害怕。
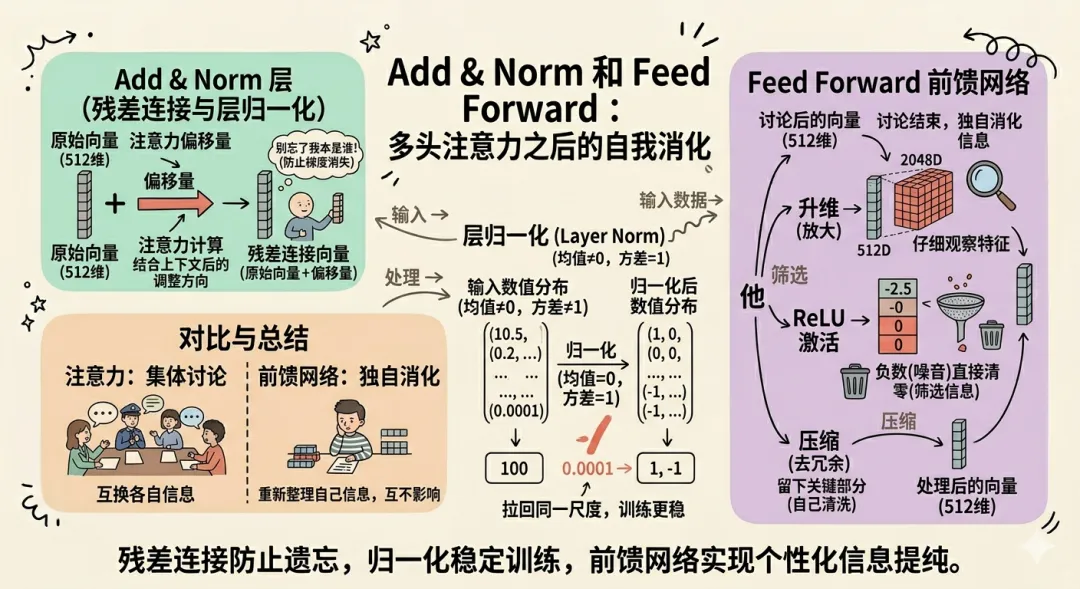
多头注意力做完之后,进入 Add & Norm,也就是 残差连接 与 层归一化。
注意力计算给每个词产生了一个「偏移量」,表示这个词在结合上下文之后需要往哪个方向调整。
残差连接把这个偏移量直接和原来自己的 512 维向量相加,得到一个新向量。就这么简单,就是为了防止经过大量计算之后把原始信息丢失。也就是防止传说中的梯度消失,让模型至少能知道每个词原来是谁,防止爹妈都不认识自己。
层归一化就是把这批向量的数值分布重新拉回均值为 0、方差为 1 的状态,让数字不会太大也不会太小,保证后续训练更稳。
用一组简化的数字对比更直观,
100 和 0.0001 归一化之后就变成了 1 和 -1,不管原来差距多大,都能拉回到同一尺度。
再往上走就是 Feed Forward,前馈网络。
如果将注意力机制看作是一次集体讨论,每个词都和其他词交换了各自的信息。
那前馈网络就是讨论结束之后,每个词需要独自消化一下刚才收集到的东西,重新整理自己身上的信息,互不影响。
具体过程是,每个词的 512 维向量先升维到 2048 维,在更大的空间里充分展开,就像用一个放大镜在仔细观察每个特征。
然后通过 ReLU 激活函数,把所有负数直接清零,这一步是在强迫模型做一次筛选,负数就是噪音,可以直接丢弃。
最后从 2048 维再压缩回 512 维,去掉冗余,留下最关键的部分。相当于自己做了一次放大清洗。
然后又进入 Add & Norm,你会疑惑为什么刚刚走过又来一遍。层归一化就是每一层都 “踩一脚刹车”,把数值拉回安全区,这样就很好理解了。
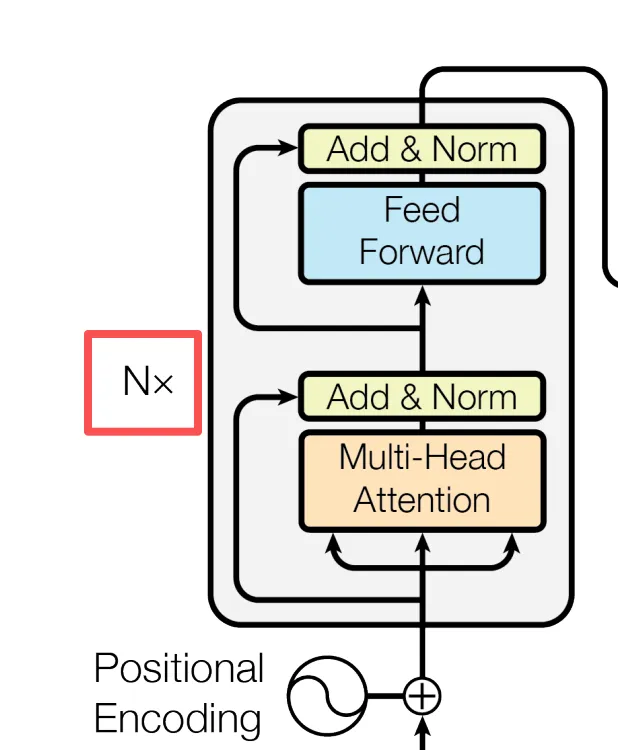
图中我们仔细看是一个 Nx ,论文中描述实际上这个层被重复了 6 次。也就是 6 次反复的阅读理解。
而且第一层的输出会作为第二层的输入,一直传下去。
每一层都在原来的基础上再深挖一遍,就像同一份案卷被 6 个经验不同的分析师依次复查,每一遍都能多发现一些上一遍没注意到的细节。
这样之后计算机就彻底理解了完整句子的含义。
为什么是 6次,这个数字是当时根据实验效果和计算资源权衡出来的,今天主流模型的层数已经到几十层甚至上百层了。
像 LLaMA-7B 模型就是 32 层,GPT-3 已经是 96 层。
6 层跑完,Encoder 对输入句子的理解,被浓缩进了每个词的 512 维向量里。
到这里,Multi-Headed Attention + Add & Norm + Feed Forward + Add & Norm,合在一起是一个左侧完整的 Encoder 层,编码器部分。
战术性喝水时间
接着进入右半部分,Decoder 解码器。
这部分就是我们现在看到的所有模型一个字一个字输出的效果,模型本质上就是在预测下一个最可能出现的token的概率,然后依次输出。
我们用一个具体的翻译任务,把「明天会更好」翻译成英文。
「明天会更好」先输入到模型,经过刚刚走完的 Encoder 流程,每个词的 512 维向量各自生成了对应的 K 和 V,进入 Decoder 备用,也就是 kv 缓存。
这句话经过 Encoder 之后,为什么就变成 Decoder 的 K 和 V
每个词经过 6 次处理之后,它的向量不再只是这个词本身的含义,同时包含了所有上下文的信息。
K 是「我是什么」的压缩表达,方便 Decoder 的 Q 来快速匹配,找到「原句里哪些词和我现在想生成的内容最相关」。
V 是「具体的内容」,一旦 Q 和 K 匹配上了,Decoder 就去读对应的 V,把那部分信息翻译过来。
在 Cross-Attention 也就是交叉注意力机制中,一个用来「被查询」,一个用来「被读取」。
这就是「Encoder 的输出作为 K 和 V 传给 Decoder」的具体作用。
现在翻译任务开始,Decoder 从一个特殊的起始信号开始,我们用「start」表示。
这个 start 不是真实的词,它的意思只有一个,告诉模型「你可以开始生成了」。
先看右侧最底部的 Embedding 和 Positional Encoding,
start 经过这两步之后同样是变成一个 512 维的向量,作为第一个 Q,这个过程和输入阶段完全相同。
这个 Q 去向 Encoder 传过来的 K 做匹配,问的是「我现在要开始翻译了,原句里谁最适合作为第一个词」。
Encoder 的 K 们各自回答
「明」是时间状语,「天」修饰时间,「会」是情态动词,「好」是结果,
模型判断,翻译一个关于明天的句子,第一个词最自然的是时间词,
于是 Q 和「明天」对应的 K 匹配度最高,读取对应的 V,输出第一个词 Tomorrow。
这里其实是纯向量计算的过程,只是看着像人的思考过程。
Tomorrow 生成之后,它不是消失了,而是再次回到 Decoder 的底部,经过 Embedding 和 Positional Encoding,变成新的 Q,加入到下一轮的计算里。
现在 Q 是「start + Tomorrow」,模型的问题变成了「我已经说了 Tomorrow,接下来该说什么」。
再次查询 Encoder 的 K 和 V,「会」这个字在原句里表达的是一种对未来的预期,对应的英文结构是「will」,于是第二个词 Will 生成出来。
然后「start + Tomorrow + Will」作为新的 Q,问「Tomorrow Will 后面是什么」,匹配到「更好」,输出 Be Better。
最后一轮,「start + Tomorrow + Will + Be + Better」作为 Q 再次送回底部,模型查询一遍,发现原句的信息已经全部生成完了,于是输出一个特殊的结束符号「EOS」,End Of Sequence,生成结束。
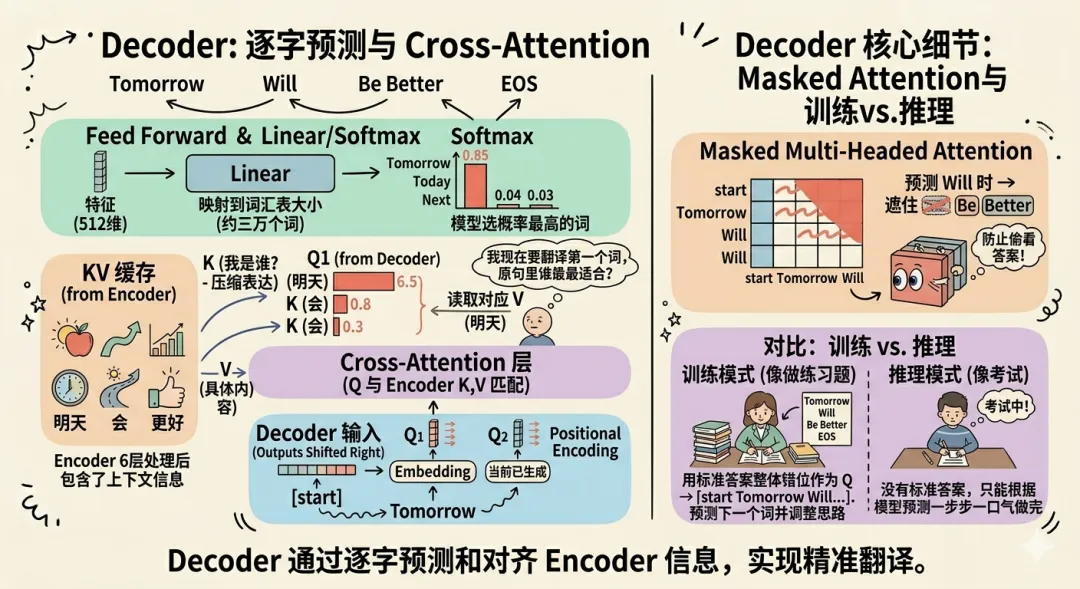
这个完整的过程就包括了右侧独有的 Multi-Headed Cross-Attention 多头交叉注意力。
知道了整体过程,我们再看其中的细节,架构图里在 Decoder 底部标了一行字,Outputs Shifted Right,输出向右移动一位。
这是什么意思呢。
训练的时候,标准答案「Tomorrow Will Be Better EOS」也会和翻译原文一起输入到模型中,
Decoder 每一步的 Q,是把标准答案整体往右错一位,在最前面加上 start,变成「start Tomorrow Will Be Better」。
也就是说,模型每次拿到的 Q,都是「已经生成的部分」,它的任务是预测「下一个词是什么」。
拿 start 预测 Tomorrow,拿「start Tomorrow」预测 Will。Q 序列比答案序列整体错开了一位,这就是 Shifted Right 的意思。
接着我们再看 Decoder 里另一个独有的机制,Masked Multi-Headed Attention,带掩码的多头注意力。
我们已经知道了训练时有答案一起输入,如果在预测第一个词 Tomorrow 时,它能偷看到后面的 Will、Be、Better,那训练就没有意义了,它直接照抄就行。
所以就需要掩码,在预测第 N 个词的时候,把第 N 个位置之后的所有词全部盖住,让模型只能看到它应该看到的部分。预测第一个词时,只能看到 start;预测第二个词时,只能看到 start 和 Tomorrow。
实际推理时,这个问题就不存在了,因为根本就没有标准答案。
所以掩码机制在训练时是主动遮住,在推理时是被动不存在,两种情况下模型看到的信息是完全一致的。
可以这么理解,训练时像我学生时代做练习题,每做完一道题,就想对一下答案。然后调整思路,然后继续做下一题。
推理时就是正式考试,只能在没有答案的前提下一口气做完。
带掩码的自注意力做完之后,经过 Add & Norm,然后就是上面提到的Cross-Attention,Decoder 拿着自己当前的 Q,去查询 Encoder 留下的 K 和 V,两边在这里交换信息。再过一次 Add & Norm,Feed Forward 升维到 2048 维再降回 512 维,最后一次 Add & Norm。
这个结构同样重复进行 6 次,最终进入 Linear 线性层。
到这一步,模型手里拿着一个 512 维的向量,但我们需要的是一个真实的词。
Linear 层做的事情就是把这 512 维向量映射到整个词汇表的大小。每种语言大概有三万个词,
Linear 层就把 512 维的向量转换成三万个数值,每个数值对应一个词的得分,得分越高,说明模型认为这个词越可能是下一个输出。
但这三万个得分是原始数值,可能有正有负,大小不一,没法直接比较。
所以接下来经过 Softmax,把这三万个得分全部转化成概率,每个概率在 0 到 1 之间,所有概率之和必须等于 1。
比如在生成第二个词的时候,
「Will」的概率是 0.85,「Is」的概率是 0.08,「Was」的概率是 0.04,剩下两万多个词瓜分剩余的 0.03。
模型选概率最高的那个,输出 Will。
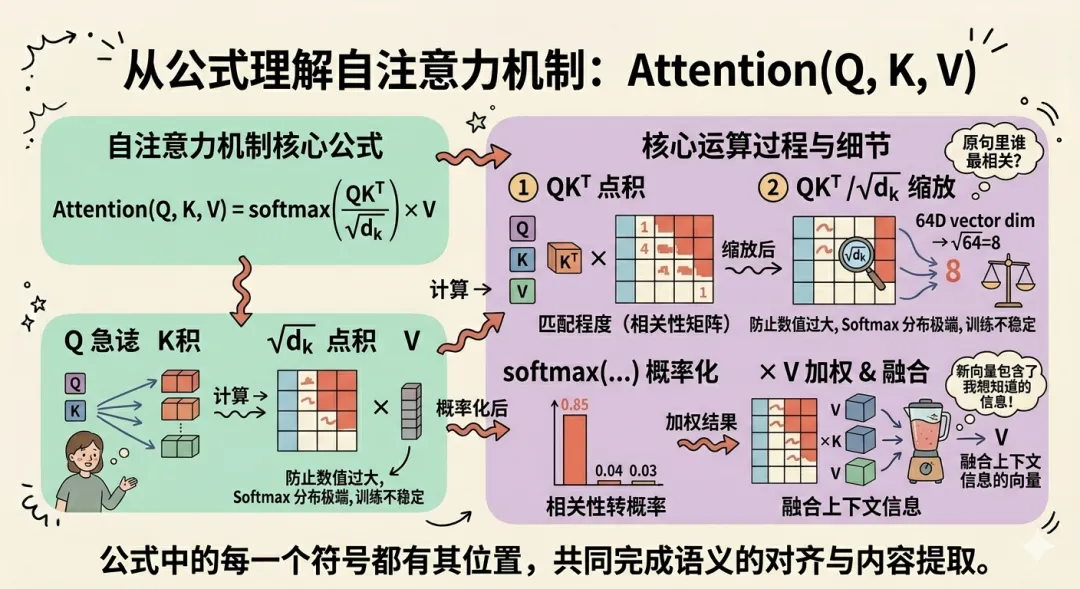
到这里,论文中下一页出现的著名的自注意力机制公式我们也能理解了。

QK^T 就是 Q 和 K 做点积,量每一个 Q 和所有 K 之间的匹配程度,得到一个相关性矩阵。
除以 √dk 是一个缩放操作,dk 是向量的维度,论文中是 64维,我们已经多次提到,
除以 √64 也就是除以 8,目的是防止点积结果数值太大,导致 Softmax 之后概率分布过于极端,训练不稳定。
然后 Softmax 把相关性矩阵转成概率,最后乘以 V,把注意力权重加权到每个词的具体内容上,得到融合了上下文信息的新向量。
公式里没有任何多余的东西,每一个符号都有它的位置。
论文的后面几页介绍了实现中的其他细节,同时作者们也提到了他们已经意识到
这个架构不仅可以用于翻译,在其他创作方面也有着非常广泛的应用前景。
论文写完之后,需要一个标题。这篇论文最核心的价值就是推翻注意力机制以前只是辅助的角色定位,不需要 RNN,不需要卷积,只要注意力就能把问题解决。
所以其中一位作者琼斯想到了经典乐队披头士的一首歌,叫 All You Need Is Love,你需要的只是爱。
把 Love 换成 Attention,就有了 Attention Is All You Need。
这个标题里藏着一个判断,一个在当时听起来有点狂妄的判断,注意力机制,才是你真正需要的东西。
所以回到最开始的那个问题。
为什么 Attention is all you need,有资格被评选为人工智能领域最著名的一句话
现在你应该也有了答案。
在所有人都觉得一切就应该是这样的固化思维下,8 位作者勇敢的创造性的换了一个角度重新观察自然语言模型应该有的样子。

还有一个小彩蛋我们在回到论文的作者页面,可以看到上图中每一个名字上有一个星号,
是因为最开始论文发表之前 8 位之一的 Google 传奇程序员沙泽尔突然发现自己的名字排在第一位,
transformer 架构中最核心的多头注意力机制和位置编码等都是沙泽尔的核心设计,
但是他坚决反对自己的名字排在最前面,后来大家一致决定,
在每个人的名字后加一个星号,注明作者贡献相同,排名不分先后。
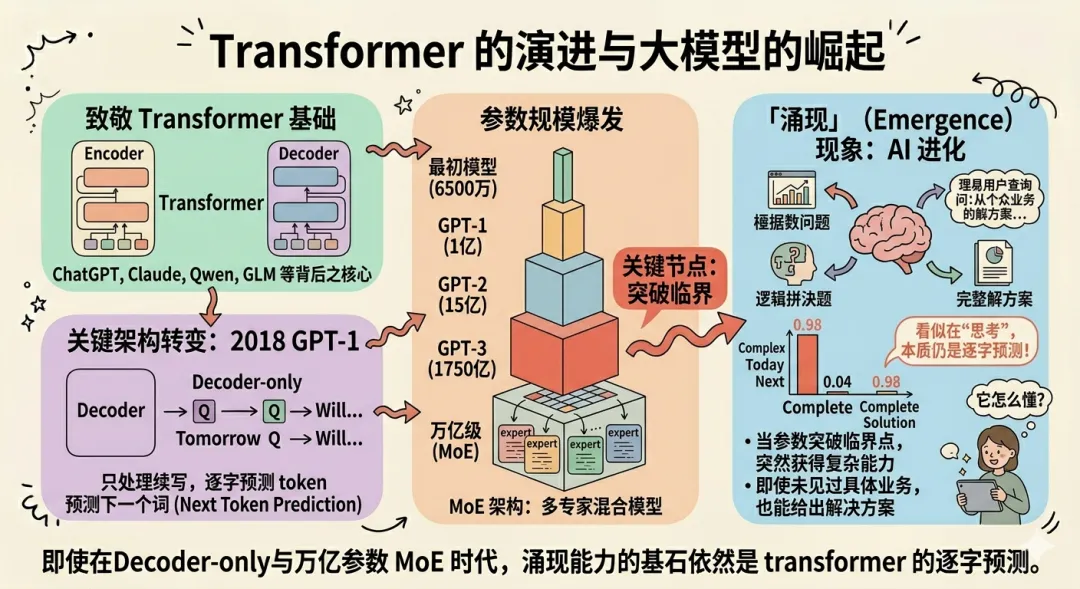
如今 ChatGPT、Claude、Gemini、DeepSeek、混元、千问Qwen、GLM、Kimi、MiniMax、豆包等一个个耀眼的名字背后都离不开 transformer。
但是值得一提的时我们现在使用的模型架构并不是和 transformer 的 Encoder-Decoder 完全相同,而是
2018 年 GPT-1开创的 Decoder-only,只处理从左到右的续写,预测下一个最可能出现的 token。这也是现在通用大模型的起点。
参数规模上也从论文中最初的 6500 万,到 GPT-1的 1 亿,再到 GPT-2的 15 亿,GPT-3的 1750 亿,最后到现在的万亿级参数,也就是 MoE 架构的出现。
这里有一个关键节点,GPT-3的 1750 亿参数规模,开始出现 「涌现」 现象,出现最神奇的 AI 进化,当参数突破临界点,模型会突然获得复杂能力,这就是「涌现」。正因为此我们才会觉得模型虽然没有见过我的业务,但是它会像人一样在'思考',然后给出完整的解决方案。其实本质依旧是逐字预测下一个词。
最后,这篇肝了一周的文章希望能对你有一点点帮助,当再次看到模型神奇的回答自己的问题时,它背后藏着的秘密相信你已经有了自己的认识。
以上,既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~
谢谢你看我的文章,我们,下次再见。
>/作者:AI真人感
