 夜雨聆风
夜雨聆风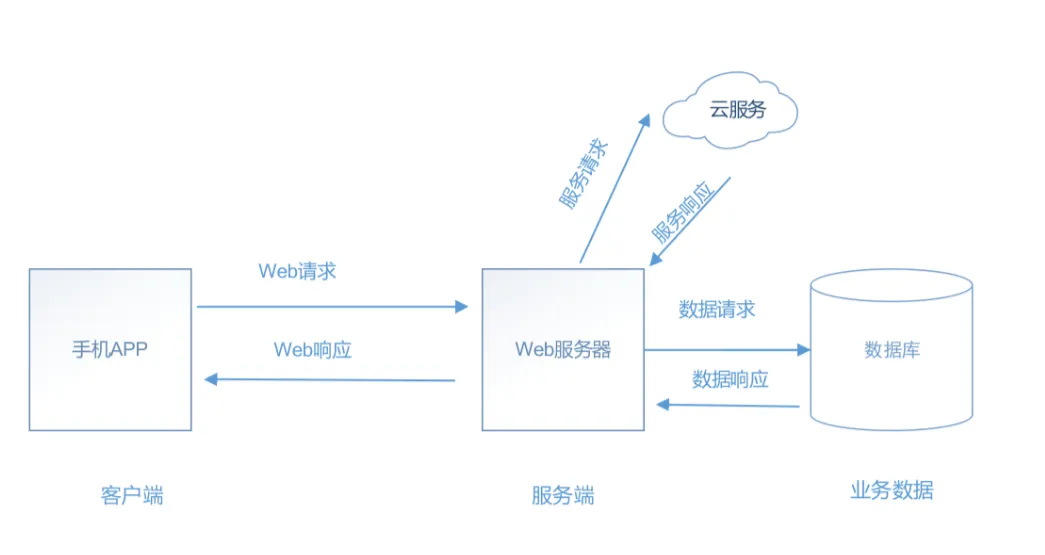
各位在数字商业赛道上“飙车”的道友们,大家好!我是那个一边盯着服务器CPU负载,一边盘算着如何将技术转化为商业护城河的移动端架构师。👷♂️💻
不知道大家有没有遇到过这种让人“血压拉满”的尴尬场景:产品原型演示时,你拍着胸脯保证“逻辑绝对没问题”,结果内测第一天,只是模拟了几十个用户同时在线,不仅数据加载转圈转到天荒地老,就连测试小姐姐的手机都发烫得能煎鸡蛋了。这哪里是搞软件开发,简直是在给用户发“暖手宝”!🥚🔥
其实,造成这种“翻车”现场的罪魁祸首,往往是因为我们低估了真实商业环境的复杂度。很多团队在开发初期,习惯于用“单机思维”去写代码,把数据和算力全压在用户手机端。但对于真正商用化的移动APP产品而言,这无异于让一个小学生去扛煤气罐。今天,咱们戴上市场经济的放大镜,深扒复杂应用必须面对的两大灵魂拷问:数据到底存在哪?算力究竟该由谁提供? 💡
一、 数据存储的抉择:“小卖部”与“大型仓储物流中心”的较量 📦
咱们先来聊聊数据存放位置的问题。在做简单的数据访问测试,或者开发一些工具类小Demo时,把数据存在手机本地确实香——速度快、不用联网、还不花钱。但一旦进入真实的商业战场,这种“小农经济”模式就会瞬间破功。
(一)本地数据库的“物理天花板” 🧱
手机本地的轻量级数据库(比如常见的Key-Value存储或关系型数据库),本质上是为了满足单设备、单用户的数据持久化需求而设计的。
它的优点是小巧灵活,但缺点也同样致命:容量受限(通常几百兆到几个G就到顶了)、并发能力极差(多个进程同时写容易锁死)、最要命的是数据孤岛(很难跨设备、跨用户实时共享)。
优化空间:如果你正在开发的电商或社交APP,还在试图用本地数据库去承载商品目录、订单流水或聊天记录,那恐怕很快就会遇到“磁盘满载”或“数据丢失”的尴尬。这就像试图用一个家用小冰箱去给一家星级酒店供货,不仅容量不够,食材还会串味。🍦🥩
(二)远程数据库的“降维打击” 🌌
对于复杂应用来说,其处理的数据不仅庞大,而且需要多用户共享访问。这时候,你必须果断引入功能强大的远程数据库(如云端的关系型数据库或大容量的NoSQL数据库)。
经济账:把数据放到云端,不仅能轻松应对TB甚至PB级别的海量数据,还能借助云服务的读写分离、自动备份等高可用机制,确保业务万无一失。更重要的是,云端数据库可以通过内网高速通道与后端应用服务器无缝对接,为后续的数据分析、精准营销提供可能。把专业的事交给专业的“基础设施”,才是商业的最优解。 💰
(三) 鸿蒙生态的“云端一体化”捷径 🚀
作为鸿蒙开发者,我们是幸运的。HarmonyOS 不仅在端侧提供了强大的分布式数据管理能力,更在生态层面打通了端云协同的快捷通道。
通过集成云端数据库服务,你可以实现数据的全局透明同步:用户在手机端修改了一条数据,云端和其他设备会自动更新。这种“无感知”的数据流转体验,正是构建高端商业应用的核心竞争力所在。
二、 算力突围战:“小电驴”与“重型卡车”的降维打击 🚛
聊完了数据存放,我们再来看看另一个致命瓶颈:移动APP处理数据的性能问题。
手机是什么?是一部集成了通信、传感器和有限计算能力的便携式消费电子产品。它的性能,在面对真实商业场景中“猛兽般”的业务处理强度时,其实是相当脆弱的。
(一)用户量增长带来的“算力雪崩” ❄️
一旦你的APP推向市场,使用人数从几十个变成几千个、几万个,并发请求就会呈指数级增长。
如果你把复杂的业务逻辑(比如电商的订单拆单、库存扣减、金融的风控计算)全放在手机端处理,会发生什么?
用户的手机CPU会满负荷运转,内存吃紧,电池电量肉眼可见地往下掉。更要命的是,手机网络环境是极其不稳定的(从5G到弱网甚至断网),一旦在复杂计算过程中网络波动,数据就可能处于半截状态,导致严重的业务脏数据。
建设性建议:手机端的计算能力就像一辆“小电驴”,骑骑车买菜没问题,但你不能指望它去拉几十吨的集装箱。把重型计算任务放在端侧,不仅用户体验极差,还会因为不同手机型号的性能差异(碎片化),导致计算结果不一致。在商业级应用中,“端侧只做轻量级交互和展示,重逻辑一律上云”是一条铁律。 🚲🚫
(二)BFF架构与边缘计算的“神助攻” ⚡
为了解决端侧算力不足和弱网体验问题,成熟的商业化团队通常会引入 BFF(Backend For Frontend) 架构。
简单来说,就是在云端为移动端专门量身定制一套API接口层。端侧只需要发起一个简单的请求,云端BFF层负责去聚合各个微服务的数据、完成复杂的业务编排,最后把“拼装”好的结果一次性返回给APP。
此外,对于一些对时延要求极高的计算(如实时音视频滤镜、AR测量),可以考虑引入边缘计算节点,将计算资源下沉到离用户物理距离更近的地方,从而大幅降低网络延迟。这就像是给每个小区的用户都配了一个微型快递站,不用每次都跑到市中心的总仓库去取货。📦🏘️
三、 科研视角的冷思考:避开那些“想当然”的架构暗礁 🩺💊
作为一名习惯批判性思维的工程师,我必须指出:在从“单机Demo”向“商用级APP”转型的过程中,很多团队因为缺乏全栈视野,往往会掉进以下几个“大坑”。🚨
(一)“假云端”架构:只存不理的甩锅行为 🐌
症状:虽然把数据库迁到了云端,但应用的逻辑处理依然全部在手机端完成。手机端每次操作都需要下载大量原始数据到本地,计算完后再上传覆盖。
后果:网络请求耗时极长,用户操作卡顿感明显;同时云端数据库因为频繁的超大包传输,带宽费用直线上升。
建设性建议:重构为“真云端”架构。利用云端数据库自带的存储过程(Stored Procedures)或触发器(Triggers),将数据处理逻辑下沉到数据库服务器内部执行;或者通过云函数(Serverless)在数据写入前进行预处理。减少无效的数据传输,才是降本增效的关键。📉
(二)算力错配:把手机当成万能计算器 🔥
症状:为了在离线状态下也能使用某些复杂功能,开发团队花费大量精力在手机端移植了庞大的计算库(如图像处理、科学计算)。
后果:APP安装包体积暴增,低端机型直接闪退(OOM),用户手机发烫严重,纷纷卸载。
建设性建议:重新审视业务优先级。对于非核心的重度计算,果断砍掉离线支持,改为“弱网提示+云端计算”模式。如果必须离线计算,应严格限制输入数据的规模,并采用分步计算、结果缓存的策略,避免阻塞主线程。🧊
(三)忽视最终一致性的“分布式陷阱” 🌐
症状:在引入了云端数据库和多端同步机制后,没有处理好并发冲突。比如两个用户同时修改了同一条数据,导致云端数据被反复覆盖,产生脏数据。
建设性建议:在设计云端数据模型时,必须引入版本号(Version)或向量时钟(Vector Clock)机制。当发生冲突时,要么通过预设规则自动合并,要么将冲突抛给用户进行人工干预。不要试图掩盖问题,数据一致性是所有商业系统的生命线。🩸
四、 筑牢底线:国标指引下的合规架构 🇨🇳🛡️
当我们把海量用户数据存放到远程数据库,把复杂计算放到云端服务器时,我们必须清醒地认识到:我们已经成为了一名“数据管家”。遵守国家法律法规和行业标准,是我们不可推卸的责任。
(一)数据安全的“高压线” ⚡🔒
依据《GB/T 35273-2020 信息安全技术 个人信息安全规范》,我们在云端存储用户敏感信息(如手机号、身份证、生物识别信息)时,必须进行强加密存储(如AES-256),且在网络传输过程中必须使用HTTPS/TLS协议防窃听。
实战技巧:绝不在云端数据库明文存储密码!应采用加盐哈希(Salt + Hash)的方式存储口令。同时,对云端数据库的操作权限进行最小化控制,开启全量审计日志,防止内鬼泄密。🕵️♂️
(二)网络安全等级保护的“护城河” 🏰
参考《GB/T 22239-2019 信息安全技术 网络安全等级保护基本要求》,承载核心业务的云端数据库和应用服务器,必须达到相应的等保级别(通常为等保二级或三级)。
实战技巧:定期进行漏洞扫描和渗透测试;对云端数据库开启自动备份和异地容灾;在云端架构中部署Web应用防火墙(WAF)和DDoS防护。合规不仅是法律底线,更是赢得用户信任的商业基石。🧱
五、 结语:格局打开,拥抱“云边端”协同的新时代 🌌👑
从一根网线、一台服务器,到如今的5G、边缘计算和分布式云原生架构,移动互联网的技术底座一直在不断进化。
作为身处其中的开发者,我们的视野绝不能仅仅停留在如何优化一段端侧代码的性能上。跳出客户端的泥沼,去审视你的数据存储策略、评估你的算力分配模型、构建你的云端架构。因为只有在宏观层面做出了正确的技术选型,微观层面的代码才能发挥出真正的商业价值。 💎
别让“小电驴”去拉重载,给手机减负,让云端发力。把复杂留给后台,把简洁留给用户。让我们一起,用更现代化的工程理念,去迎接下一个全民智能化应用的红利期!🚀🔥
📚 参考文献:
[1] 国家市场监督管理总局, 国家标准化管理委员会. 信息安全技术 个人信息安全规范: GB/T 35273-2020[S]. 北京: 中国标准出版社, 2020.
[2] 国家市场监督管理总局, 国家标准化管理委员会. 信息安全技术 网络安全等级保护基本要求: GB/T 22239-2019[S]. 北京: 中国标准出版社, 2019.
[3] 华为技术有限公司. HarmonyOS开发者文档: 端云一体化开发指南[EB/OL]. (2024-09-01)[2024-10-01]. https://developer.harmonyos.com/.
[4] NEWMAN S. Building Microservices: Designing Fine-Grained Systems[M]. 2nd ed. Sebastopol: O'Reilly Media, 2021.
💬 互动时刻:
各位道友!在你们的商业化项目中,是否也曾经因为早期“图省事”把太多逻辑放在了端侧,结果后期被性能和并发问题折磨得痛不欲生?🕸️
或者说,你们团队在“端云数据同步”和“算力分配”上有哪些独到的架构设计心得?🌟
快来评论区畅所欲言,分享你的“踩坑”或“破局”故事!让我们一起交流,把我们的技术架构打磨得更加坚不可摧!👇👇👇
