 夜雨聆风
夜雨聆风【导读】Google DeepMind 发布了面向数学研究的 agent 工作台 AI Co-Mathematician。它在 FrontierMath 最难档 Tier 4 拿到 48% 准确率,远超底模裸跑的 19%——差距全来自系统编排层。但 Epoch AI 同期提醒:数据集正在复核中,后续分数可能调整。
48%:当前已评测 AI 系统的新高分
5 月 7 日,Google DeepMind 在 arXiv 挂出了一篇 22 页的论文:*AI Co-Mathematician: Accelerating Mathematicians with Agentic AI*。
论文直接报了一个数字:FrontierMath Tier 4 准确率 48%,所有已评测 AI 系统中最高。


▲ DAIR.AI 在 X 上发布的论文摘要帖
Tier 4 有多难?这是 FrontierMath 里最高级别,定义为 research-level mathematics——对标的是数学家日常研究中遇到的真实问题。
更细的口径:排除 2 道公开样例后,AI Co-Mathematician 在 48 道题里正确解出 23 道。作为对照,Gemini 3.1 Pro 裸模型只拿到 19%。
这段差距从哪来?
提升全靠工作流
论文给出了一个非常明确的定位:
"...does not rely on any custom model behavior or training."
「这套系统没有专门训练新底模——核心全在工作流和编排层。」
AI Co-Mathematician 的设计思路,更像是把 coding agent 的架构搬进了数学研究。几个关键组件:
项目协调器(Project Coordinator)——接收用户的研究问题后,先做目标确认和边界厘定,再把任务拆成多个方向。
并行工作流(Parallel Workstreams)——多条研究路线同时推进,有的尝试证明,有的尝试反证,有的做计算实验。
内置审稿 Agent(Reviewer Agents)——每条工作流的产出都要经过审查,形成"生成 → 审 → 卡住 → 回改 → 再审"的多轮循环。
失败假设追踪——走不通的路线不会被扔掉,留在系统里作为后续参考。
▲ arXiv 上的论文页面,作者为 Google DeepMind / Google 研究者
换一种理解方式:数学研究里大量时间花在"猜错方向、做小实验、查文献、走进死胡同再退回来"上。AI Co-Mathematician 的目标,就是把这些关键的中间过程留下来,让它们变成可追溯、可复用的资产。
牛津数学家的真实体验:错误证明里藏着对的策略
论文里最有画面感的案例来自牛津大学的 Marc Lackenby。他用 AI Co-Mathematician 处理了 Kourovka Notebook 中的一个开放问题(Problem 21.10)。
过程并不顺利——
系统先开了两条工作流,一条尝试证明,一条尝试反证。最先返回的结果是一份被 reviewer agent 判定为错误的证明草稿。
但 Lackenby 读完后,发现了一个意外收获:
"really, really clever proof strategy."
「这里面有一个真的非常聪明的证明策略。」
再看 reviewer 指出的缺口,他立刻反应过来:
"Hang on a second, I know how to fill that gap."
「等一下,我知道怎么把这个缺口补上。」
后续的流程是:Lackenby 指出补缺方向,系统写出完整正确的证明,他再做修订、泛化结果、补充例子,最后上传回系统做终审。
这个案例真正打动人的地方在于——系统给出了一个被审稿 agent 判错的草稿,但这份草稿对专家仍有启发价值。证明可以错,策略可以对。
它展示了一种和"AI 直接给完美答案"完全不同的协作模式:系统产出的半成品、思路、甚至错误路线,对领域专家来说都可能是有用的研究中间物。
架构收益,肉眼可见
社区对这组数据的反应很集中。Jeremy Blankenship 的回复代表了"架构派"的解读:
"The gap between a raw model (19%) and an orchestrated system (48%) is what matters here. That is not model scale. It is architecture..."
「最值得看的是 19% 到 48% 的差距。这来自架构——并行工作流、审稿循环、保留失败假设——让真实研究中有用的东西可见。」

▲ Jeremy Blankenship 在 DAIR.AI 帖下的回复
他还补了一句值得留意的话:
"The Kourovka case study is more interesting than the benchmark score. Most agent demos optimize for a clean final answer. This one optimizes for the process that gets there, dead ends included."
「Kourovka 案例比分数更有意思。多数 agent demo 都在优化最终答案,这个系统优化的是抵达答案的过程——包括所有走过的死胡同。」
过去两年 coding agent 的发展已经证明了一件事:在复杂专业场景里,单靠底模升级能带来的提升有限,真正拉开差距的往往是系统层面的设计——任务拆解、并行执行、版本管理、review 循环。
数学研究可能正在走上同一条路。
别急着定论:Epoch AI 正在复核数据集
在看这个分数的同时,另一个信号同样重要。
Epoch AI 在 2026 年 5 月 11 日更新了 FrontierMath 页面,明确说:
他们正在对 Tiers 1-4 做 AI-assisted review,目前约三分之一的题目被标出存在 fatal errors,且他们认为其中大多数 flag 可能有效。
完成人工复核后,会在 corrected dataset 上重新发布 updated scores。
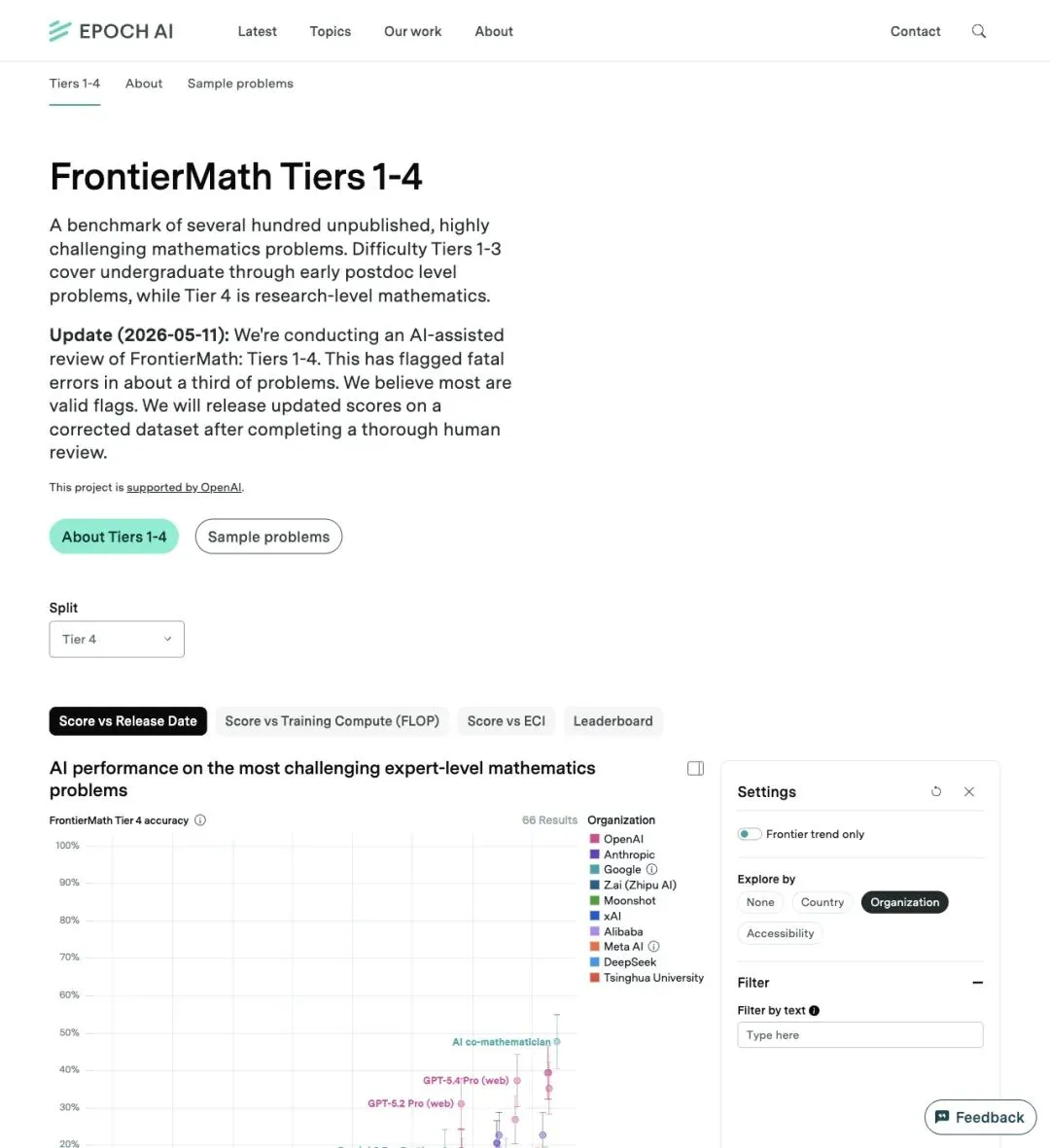
▲ Epoch AI 的 FrontierMath Tier 4 页面,顶部可见数据集复核提醒
这意味着 48% 这个数字的分母本身还在调整中。后续在 corrected dataset 上的分数,可能更高,也可能更低。
论文也坦率地承认了另一个限制:AI Co-Mathematician 没有沿用 Epoch 常规评测的 token 限制,系统没有模型调用或 token 总量上限,因此推断其推理成本高于此前被评测的系统。
把条件摆全来看:48% 对应的是一个更重、流程更长、调用预算更宽松的 agent 系统,在一个仍在复核中的 benchmark 上拿到的当期最高分。强,但上下文同样重要。
这种 stateful workbench 能走出数学吗?
社区里另一个值得留意的声音来自 Marcus:
"The interesting question isn't whether it beats human mathematicians on competition problems. It's whether the stateful environment pattern generalizes to research domains where 'correct' is harder to define than a proof."
「能不能在竞赛题上赢数学家,已经不是焦点了——更值得追问的是,这种状态化研究环境能不能迁移到那些"正确答案"比数学证明更模糊的领域。」
这可能是 AI Co-Mathematician 最大的行业含义。
如果一个 stateful、可持续推进、带内置 review 和失败路线追踪的 agent workbench,在数学这种对 correctness 要求最严苛的领域也能工作——那它的底层模式(任务拆解 + 并行执行 + 审查循环 + 中间态保留),完全有可能外溢到法律、金融、科学探索等同样需要"长流程、高专业度、多轮迭代"的场景。
AI 在高专业度领域的价值,正在从一次性问答,转向把问题定义、检索、实验、草稿、审查、回退、再推进串成的一条可追溯研究链。
数学,只是因为对 correctness 要求最高、最能暴露系统真实水平,才最先成为试验场。
— END —
