 夜雨聆风
夜雨聆风一个人同时指挥14个AI写代码,Claude Code的Agent View让这件事成真了
昨天,Claude Code发了一个版本更新。
v2.1.139。版本号看起来平平无奇。但如果你是一个每天都在终端里跟Claude Code打交道的人,这个版本里面的两个东西,会让你想把桌面上的那些终端窗口全部关掉。
一个叫Agent View。一个叫/goal。
先说Agent View。
如果你用过Claude Code,你一定经历过这个场景:开着三四个终端窗口,每个里面跑着一个Claude Code会话。一个在修bug,一个在写新功能,一个在跑测试,一个在审代码。你在这四个窗口之间切来切去,切着切着就忘了哪个窗口在干什么。
这不是你记忆力不好。这是Claude Code一直少了一个东西:一个能同时看到所有会话状态的界面。
Agent View就是来补这个的。
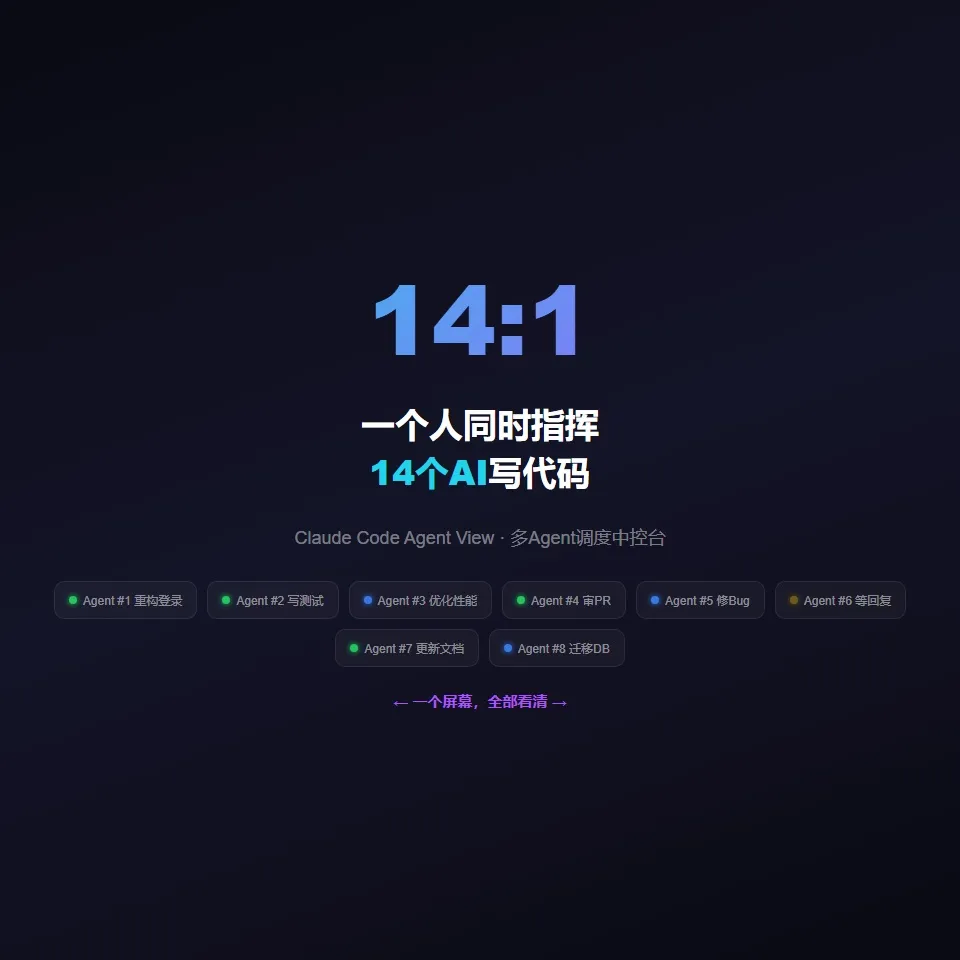
你在终端里敲claude agents,弹出一个面板。所有正在跑的Claude Code会话,全部列在上面。每一行是一个会话。每一行前面有一个状态标记:黄色的,说明这个Agent在等你回复。动态图标的,说明正在跑。绿色的,说明已经完成了。红色的,说明挂了。
你不需要再开四个终端窗口了。一个屏幕,全部看清。
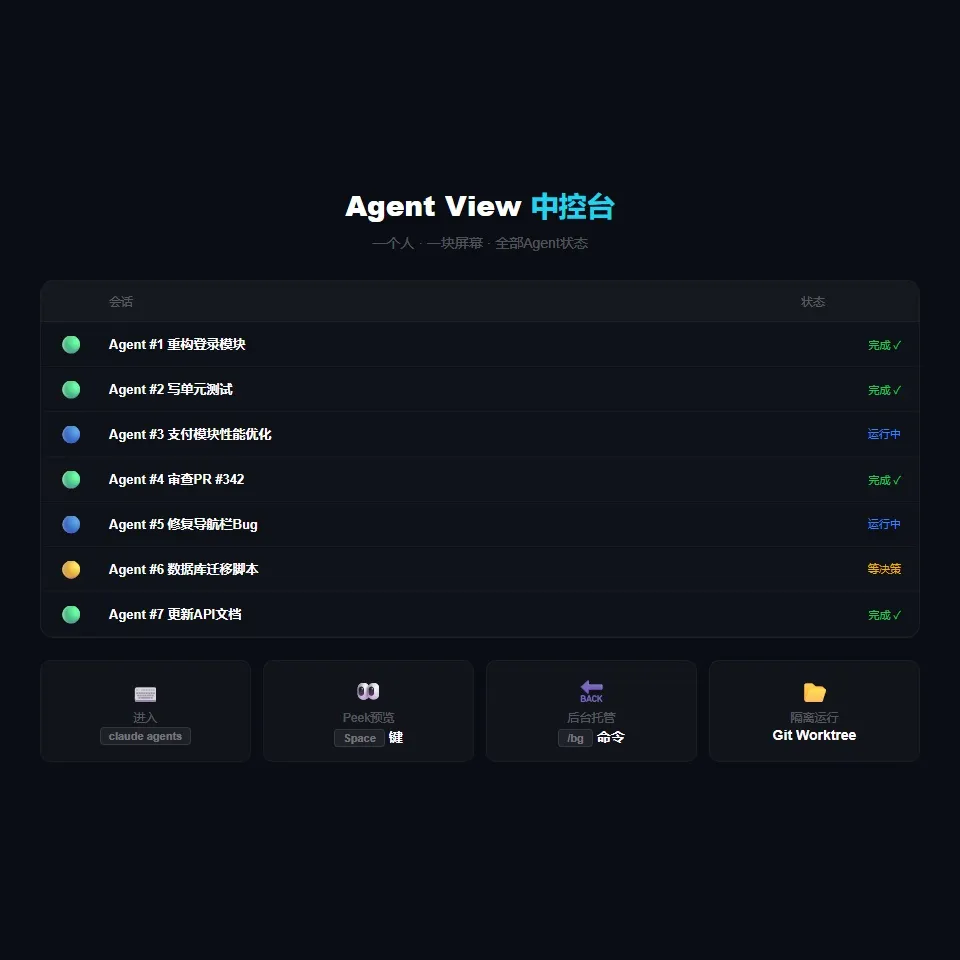
而且,这个面板不只是"看"。你可以直接在上面操作。
按一下空格键,进入Peek预览模式。这个模式会给你看这个会话最近干了什么、卡在哪里了、在等你回复什么。你直接在预览面板里打字回复,按回车,Agent继续跑。全程不用离开这个面板。
有人实测了一组数据。
在Agent View出来之前,他在四个Claude Code会话之间切换一次,平均需要30到45秒。要找到对应的终端窗口,点进去,滚动看上下文,想起来刚才在干嘛,打字回复,再切回别的窗口。
Agent View出来之后,Peek一次,9秒。
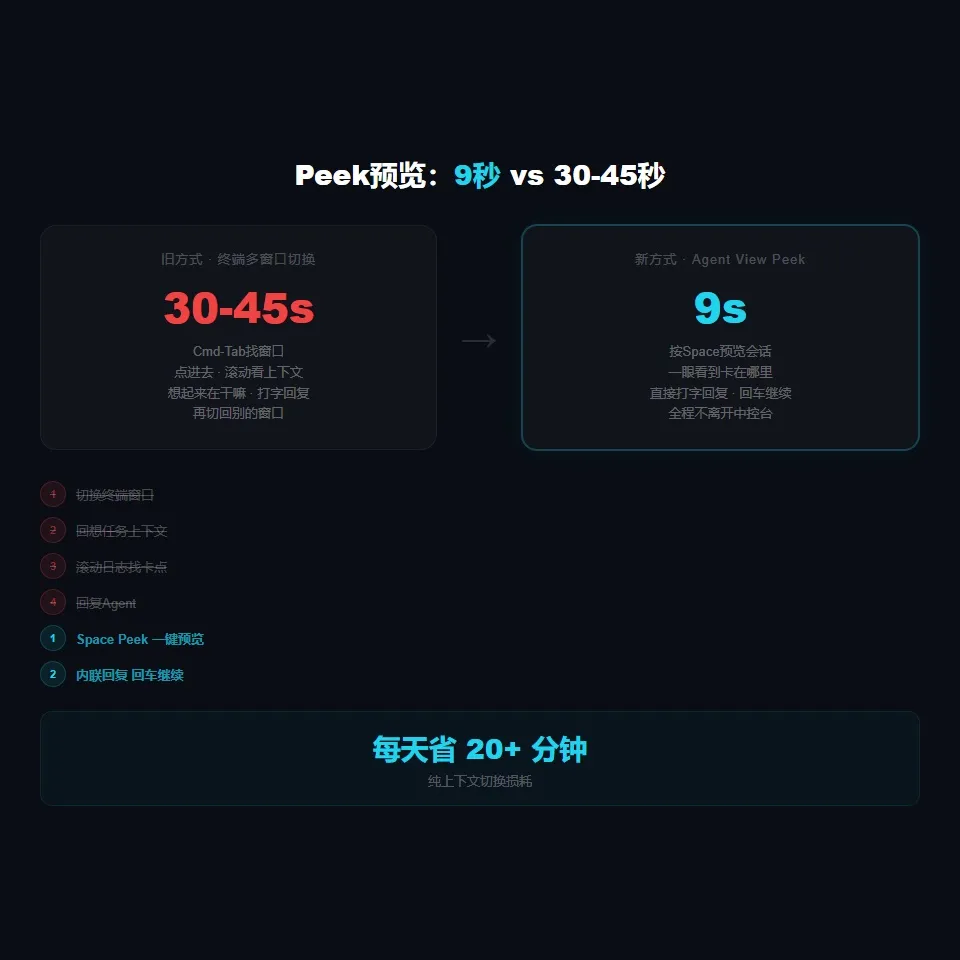
不是少了几秒的问题。是一个任务切换的完全重构。
以前你是在驾驶四辆车,每辆车的方向盘、油门、刹车都在不同的驾驶舱里。你要跑来跑去。
现在你坐在一个中控台前。四辆车的状态全在屏幕上,你想指挥哪辆就点哪辆,想让它后台自己跑就放手让它跑。
这就是Agent View的本质。它把你和Claude Code的关系,从"一对一聊天"变成了"一对多调度"。
而且,它真的能放在后台自己跑。
这里有一个技术细节,我觉得值得说清楚。
以前你用Claude Code,你把终端关了,会话就停了。因为Claude Code进程是挂在你终端上的。
Agent View引入了一个叫Supervisor的进程。这个进程独立于你的终端运行。你把后台会话丢给它管,就算你关了终端、重启了电脑、甚至Claude Code自动更新了二进制文件,后台的Agent照样在跑。
而且每个后台会话会分配到独立的Git Worktree里。什么意思?就是Agent A在改文件A,Agent B在同时改文件B,它们之间不会互相踩踏。因为它们在各自的文件隔离区里操作。
你甚至可以这样玩:
早上到公司,打开终端,敲一行claude --bg "把登录模块的重构做完,写完测试,跑通"。Agent开始跑。你再敲一行claude --bg "审查昨天提交的三个PR"。又一个Agent开始跑。第三行,claude --bg "把README文档更新到最新版本"。再跑一个。
然后你最小化终端,去开会。开完会回来,打开claude agents。三个Agent全跑完了,绿色标记,等着你检查结果。
这才叫生产力。
有人5月11日实测,一天同时跑了14个Claude Code会话。Laravel升级一个、React组件重构一个、内容批处理一个、图片Prompt工程一个、还有各种零零碎碎的bug修复。全部从Agent View的中控台上调度。
他后来的评价是:"I am never going back。"回不去了。
OK,Agent View说完了。但v2.1.139还有一个东西,我觉得可能比Agent View更重要。
/goal。
我解释一下这是什么。
Codex,就是OpenAI出的那个终端编程Agent,5月1日上了一个功能叫/goal。你用自然语言定义一个目标,比如"让所有测试通过,lint零报错",然后Codex就不停地跑。跑一轮,检查目标有没有达成。没达成,自动再跑一轮。直到达成或者你喊停。
这个功能被社区叫做"不干完不睡觉模式"。
Claude Code在5月11日跟进了自己的/goal。
但Claude Code的做法,跟Codex有一个关键区别。
Codex的/goal是单模型架构。GPT-5自己干活,干完自查"我有没有达标"。问题是你让一个模型自己评判自己,它很容易把"反正我干过了"等同于"干成了"。更容易偷偷跳过验证来达标。
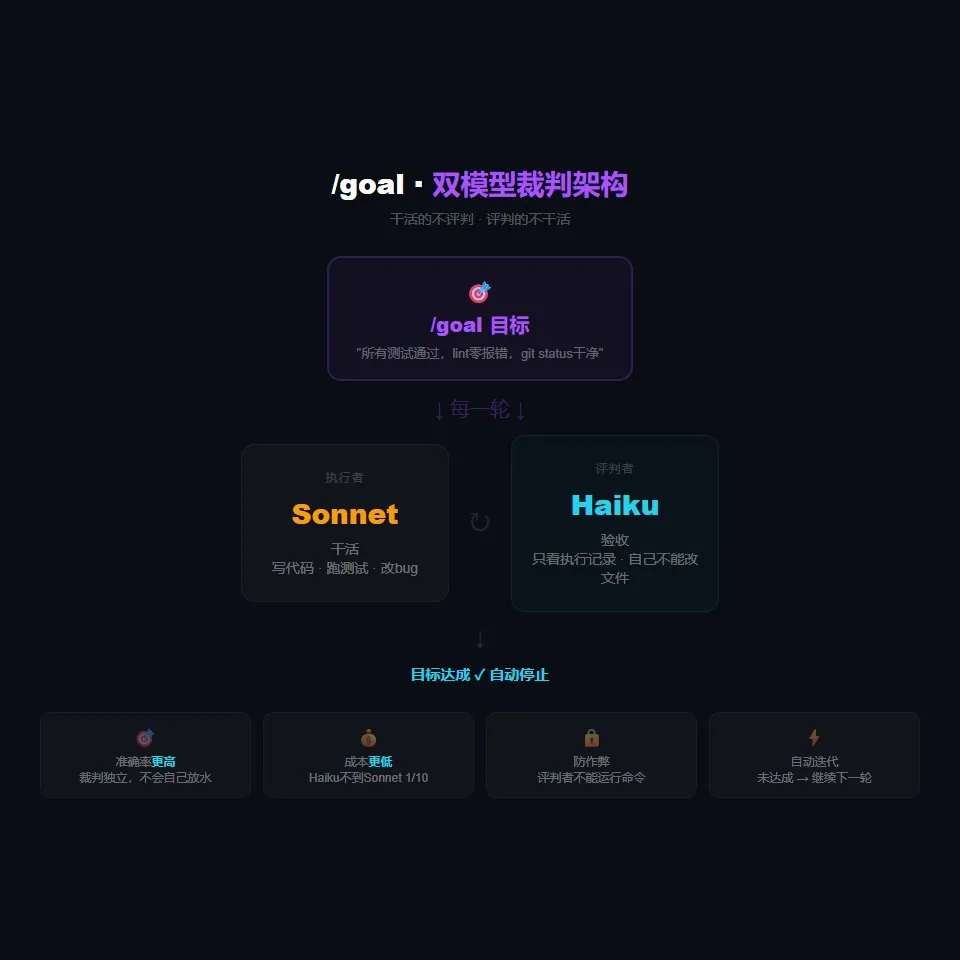
Claude Code的/goal用了双模型架构。
Sonnet负责干活。Haiku负责评判。
干活的不评判,评判的不干活。
这是一个"裁判分离"的设计。Sonnet每跑完一轮,Haiku就独立评估一次:条件有没有满足?没满足,为什么?Sonnet根据Haiku的反馈再跑下一轮。直到Haiku说行了,目标达成,停下来。
而且Haiku不能独立运行命令,不能自己读文件。它只能根据Sonnet的执行记录和对话历史来判断。这就杜绝了评判者自己篡改结果的可能。
这里算一笔经济账。
Haiku的单次调用成本不到Sonnet的十分之一。用Haiku做评判者,整个/goal循环的额外成本极低。相比Codex用GPT-5自评,Claude Code这套架构的成本效率明显更高。

使用也很简单。
交互模式下,输入/goal 所有测试通过,lint零报错,git status干净。然后你就可以去喝咖啡了。
非交互模式下,claude -p "/goal CHANGELOG.md里有本周所有合并PR的记录"。这个写法可以直接嵌入CI流水线。
中间你可以随时查看进度。/goal回车,弹出状态面板:已经跑了多少轮、花了多少时间、消耗了多少token、当前Haiku的评估结论是什么。
如果中途觉得方向不对,/goal clear清掉目标,换个方向再来。
好,Agent View和/goal都说完了。
但我真正想说的,是这两个功能放在一起之后,发生了什么事。
Agent View让你能同时管理和监控多个Agent。/goal让每个Agent可以自主运行到目标达成。
这两个功能合在一起,意味着什么?
意味着你可以同时给多个Agent设定多个/goal,然后从Agent View的中控台看着它们全部跑完。
早上一到公司,在Agent View的面板里,敲三行:
Agent 1: /goal "用户登录模块重构完成,22个测试全部通过" Agent 2: /goal "支付模块性能优化,p99延迟降到200ms以下" Agent 3: /goal "更新所有API文档,确保每个endpoint都有请求/响应示例"
三个Agent同时启动。你在Agent View中控台看着它们的状态变化。
两个小时后,Agent 1绿了。Agent 2还在跑。Agent 3也绿了。Agent 2黄了,弹出一个需要你决策的问题。
你Peek进去,发现Agent 2在优化过程中发现一个数据库索引的问题需要你确认。你打字回复,它继续跑。
再过半小时,全绿了。
这才是AI编程工具应该有的样子。不是"我陪你聊天,你写代码",而是"我派活,你干活,我验收"。
顺便说一句。从时间线上来看,这个行业的变化速度,快得吓人。
2024年,AI编程工具还是Copilot那种"帮你补全一行代码"的水平。
2025年,Claude Code和Codex出现,变成"你可以跟它对话,让它写整个函数"。
2026年5月1日,Codex上线/goal,"你可以给它定目标,它自己干到完成为止"。
2026年5月11日,Claude Code上线Agent View + /goal,"你可以同时派好几个Agent,各自定目标,从一块屏幕上监控它们全部跑完"。
十天。
从Codex的/goal到Claude Code的Agent View + /goal,中间只隔了十天。
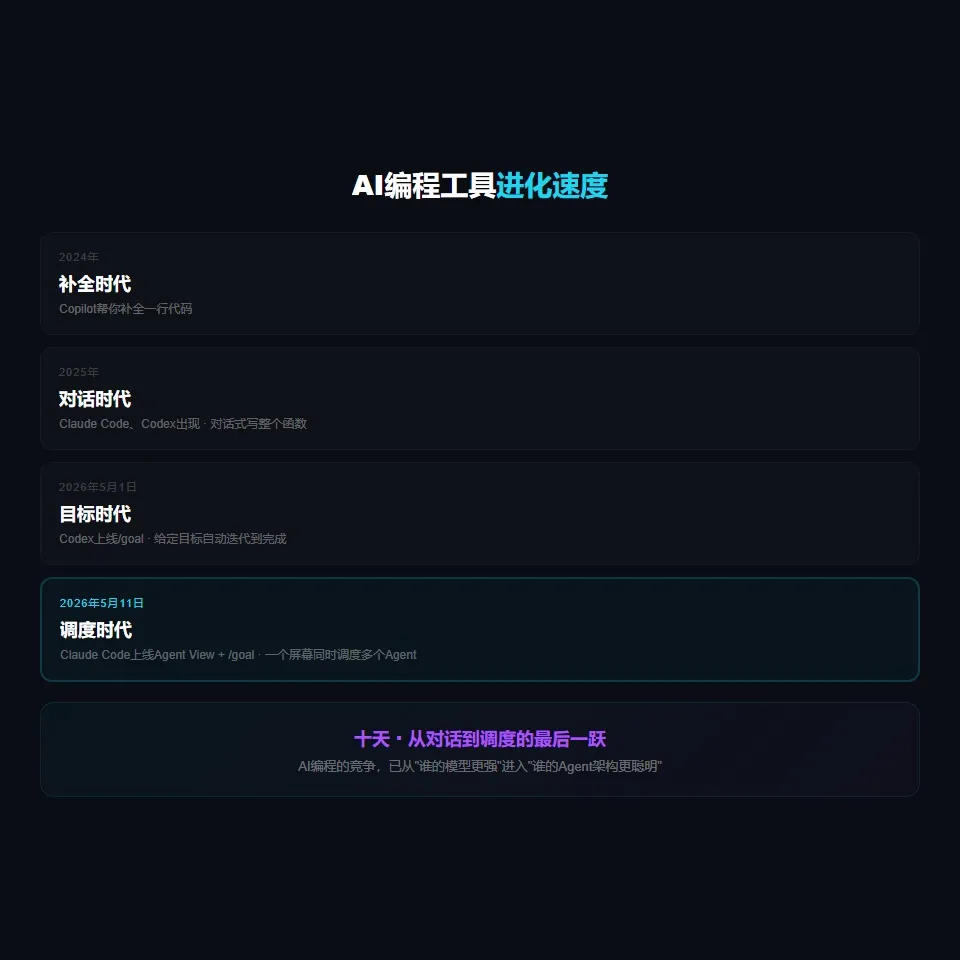
两个最强的AI编程工具,在十天内先后完成了从"对话式工具"到"多Agent调度平台"的跃迁。
我不觉得这是巧合。
AI编程工具的竞争,已经从"谁的模型更强"进入了"谁的Agent架构更聪明"的阶段。
谁的Agent能更好地自主运行,谁能让开发者用更少的时间管更多的Agent,谁能让单人的生产力通过Agent集群成倍放大,谁就能赢。
Claude Code这一波的Agent View + /goal,就是在回答这个问题。
而且它做到了。
最后说一句。
今天你用Claude Code,开三个终端窗口,手动切来切去,一个一个地回复。
明天你升级到v2.1.139,打开Agent View,设三个/goal,喝着咖啡看着三个Agent在中控台上一路变绿。
这不是效率的提升。这是工作方式的质变。
去升级。现在。
