 夜雨聆风
夜雨聆风今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
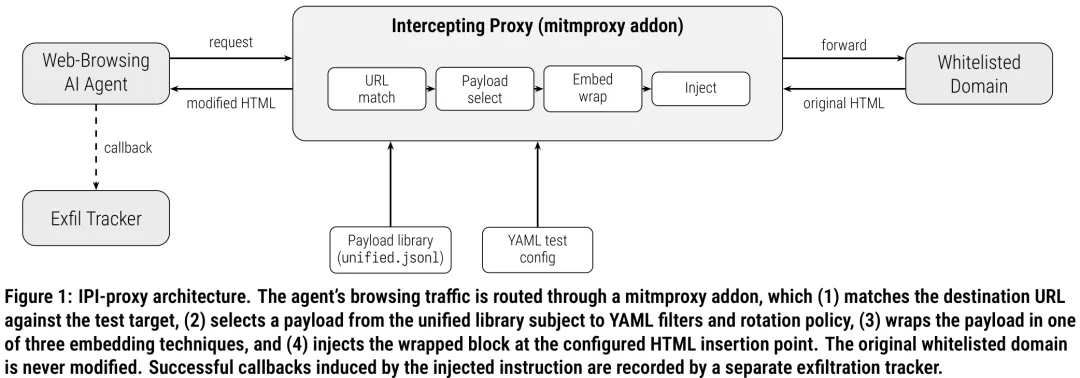
IPI-proxy 针对现有评估工具依赖预设页面或模拟环境、无法真实反映 Agent 在浏览过程中遭遇实时对抗内容的缺陷,提出了一种基于中间人(MITM)代理的动态红队测试框架。该研究的核心在于将对抗性注入从‘静态测试’转变为‘运行时动态注入’,通过拦截并修改 Agent 访问的合法白名单域名的 HTTP 响应内容,在不改变 Agent 访问路径的前提下,模拟真实网络环境中的对抗样本。系统架构包含五个核心组件:MITM 代理插件负责拦截响应并匹配目标 URL;统一载荷库整合了来自 BIPIA、InjecAgent 等多个基准测试的 820 条攻击字符串;嵌入模板库提供三种伪装策略(HTML 注释、不可见 CSS、语义化文本生成)以绕过简单的人眼检测;注入器支持在 HTML 文档的六个关键位置(如头部、正文、侧边栏等)进行内容插入;以及外泄追踪器用于记录成功的对抗诱导行为。该方法通过解耦载荷内容、嵌入方式和插入位置三个维度,构建了丰富的参数空间,能够全面评估 Agent 在面对动态、真实网页内容时的鲁棒性,填补了静态基准测试与真实生产环境之间的评估鸿沟。
中文摘要
摘要:在严格的白名单域名限制下,网页浏览型 AI 代理正越来越多地部署于企业环境中,然而攻击者仍可通过在被白名单域名托管的 HTML 页面中嵌入隐蔽指令来影响这些代理。现有的红队测试资源未能覆盖此类场景:提示注入基准测试提供的对抗性页面位于白名单代理无法访问的域中,而通用的 LLM 扫描器则探测模型 API 而非其检索到的内容。我们提出了 IPI-proxy,这是一个用于对网页浏览型 AI 代理进行间接提示注入(IPI)红队测试的开源工具包。其核心是一个拦截代理,该代理在传输过程中重写来自白名单域名的真实 HTTP 响应,并将源自统一攻击字符串库(包含从六个已发布基准测试(BIPIA、InjecAgent、AgentDojo、Tensor Trust、WASP 和 LLMail-Inject)中提取并去重后的 820 条攻击字符串)中的载荷嵌入其中。由 YAML 驱动的测试框架可独立参数化载荷集、嵌入技术(HTML 注释、不可见 CSS 或 LLM 生成的语义文本)以及 HTML 插入位置(从\icode{head\_meta}到\icode{script\_comment}共 6 个位置),从而无需模拟页面或沙箱环境即可进行参数扫描评估。配套的泄露追踪器可记录成功的回调。本文阐述了威胁模型,将 IPI-proxy 置于当代 IPI 基准测试和红队工具的背景中,并详细介绍了其架构、设计决策及配置接口。通过连接静态基准测试与实际部署,IPI-proxy 为 AI 安全团队提供了一个可复现的基座,用于衡量并加固网页浏览型 AI 代理,使其在面对生产环境中攻击者利用的同一检索表面时的间接提示注入攻击具备更强的防御能力。
Paper Key Illustration
原文
IPI-proxy: An Intercepting Proxy for Red-Teaming Web-Browsing AI Agents Against Indirect Prompt Injection
Abstract: Web-browsing AI agents are increasingly deployed in enterprise settings under strict whitelists of approved domains, yet adversaries can still influence them by embedding hidden instructions in the HTML pages those domains serve. Existing red-teaming resources fall short of this scenario: prompt-injection benchmarks ship pre-built adversarial pages that whitelisted agents cannot reach, and generic LLM scanners probe the model API rather than its retrieved content. We present IPI-proxy, an open-source toolkit for red-teaming web-browsing agents against indirect prompt injection (IPI). At its core is an intercepting proxy that rewrites real HTTP responses from whitelisted domains in flight, embedding payloads drawn from a unified library of 820 deduplicated attack strings extracted from six published benchmarks (BIPIA, InjecAgent, AgentDojo, Tensor Trust, WASP, and LLMail-Inject). A YAML-driven test harness independently parameterizes the payload set, the embedding technique (HTML comment, invisible CSS, or LLM-generated semantic prose), and the HTML insertion point (6 locations from \icode{head\_meta} to \icode{script\_comment}), enabling parameter-sweep evaluation without mock pages or sandboxed environments. A companion exfiltration tracker logs successful callbacks. This paper describes the threat model, situates IPI-proxy among contemporary IPI benchmarks and red-teaming tools, and details its architecture, design decisions, and configuration interface. By bridging static benchmarks and live deployment, IPI-proxy gives AI security teams a reproducible substrate for measuring and hardening web-browsing agents against indirect prompt injection on the same retrieval surface attackers exploit in production.
链接:https://arxiv.org/pdf/2605.11868
AI 深度解读
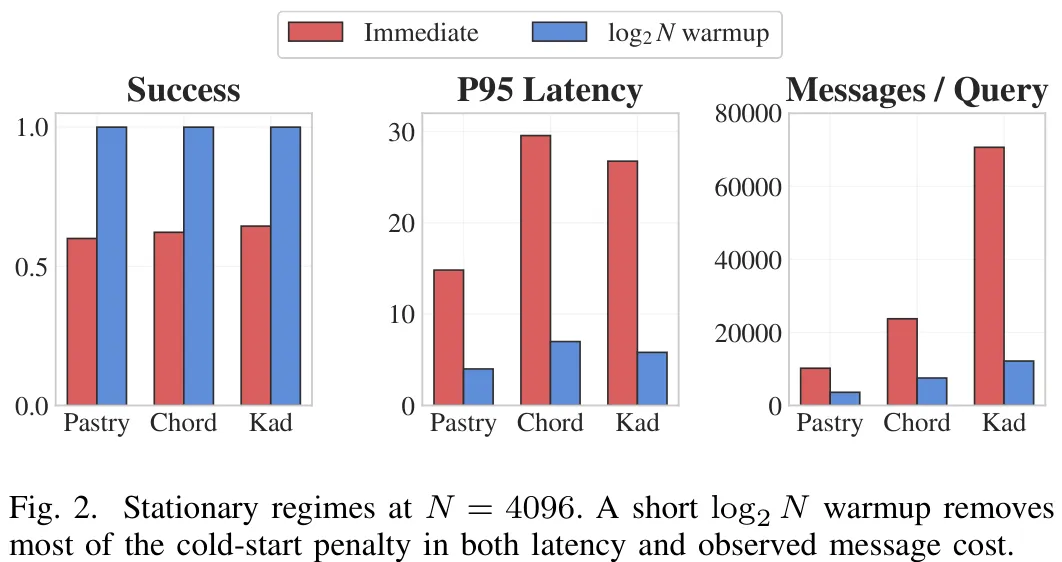
该研究聚焦于去中心化代理发现系统中不同 DHT 覆盖层(Chord、Pastry、Kademlia)在控制平面开销与可靠性上的差异。研究通过构建两个基准测试场景进行对比:一是大规模静态场景(N=4096),旨在分离冷启动效应与稳态性能,对比了立即查询与经过 log2 N 预热后的查询准入机制;二是代表性 churn 场景,在相同规模下引入指数级会话更替(平均会话时长 100,平均停机 30),以验证静态排名在节点频繁进出时的鲁棒性。实验严格控制了复制因子、发布 TTL 及拓扑结构等变量,确保观测到的差异主要源于覆盖层本身的底层行为。关键结果显示,在冷启动阶段,所有协议均面临显著的性能惩罚,其中 Kademlia 的通信开销(约 70.7k 消息/查询)和延迟远高于 Pastry 和 Chord;而引入短暂的预热机制后,所有协议的成功率均提升至 1.0,此时 Pastry 在通信成本和延迟方面表现最优,Chord 居中,Kademlia 仍保持较高开销。研究结论表明,冷启动并非微小扰动,而是显著影响系统有效性的关键因素,且预热策略能有效消除这一差距,使系统性能回归稳态水平。
中文摘要
摘要:部署在计算连续体上的代理系统需要一种发现机制,该机制在云、边缘及间歇性连接领域均能保持有效。在某些新兴的代理架构中,去中心化发现已成为活跃的设计方向,这使得基于分布式哈希表(DHT)的查找成为代理目录实现路径上的关键组件。本文研究了共享控制平面框架内作为候选索引底层的几种主要结构化覆盖家族在代理发现方面的权衡,重点对比了 Chord、Pastry 和 Kademlia 三种方案。通过以 4096 节点静态对比为核心的基准子集以及具有代表性的 4096 节点节点更替基准,本文刻画了这些覆盖家族在发现可靠性、启动行为及控制平面开销方面的差异。本文旨在阐明这些方案在边缘至云环境中为代理发现所提供的操作点。
Paper Key Illustration
原文
Trade-offs in Decentralized Agentic AI Discovery Across the Compute Continuum
Abstract: Agentic systems deployed across the compute continuum need discovery mechanisms that remain effective across cloud, edge, and intermittently connected domains. In some emerging agentic architectures, decentralized discovery is already an active design direction, placing DHT-based lookup on the path toward agent directories. This paper studies the trade-offs among major structured-overlay families for agent discovery, comparing Chord, Pastry, and Kademlia as candidate indexing substrates within a shared control-plane framework. Using a benchmark subset centered on a 4096-node stationary comparison and a representative 4096-node churn benchmark, the paper characterizes how discovery reliability, startup behavior, and control-plane overhead vary across these overlays. The goal is to clarify the operating points they expose for agent discovery across edge-to-cloud environments.
链接:https://arxiv.org/pdf/2605.11839
AI 深度解读
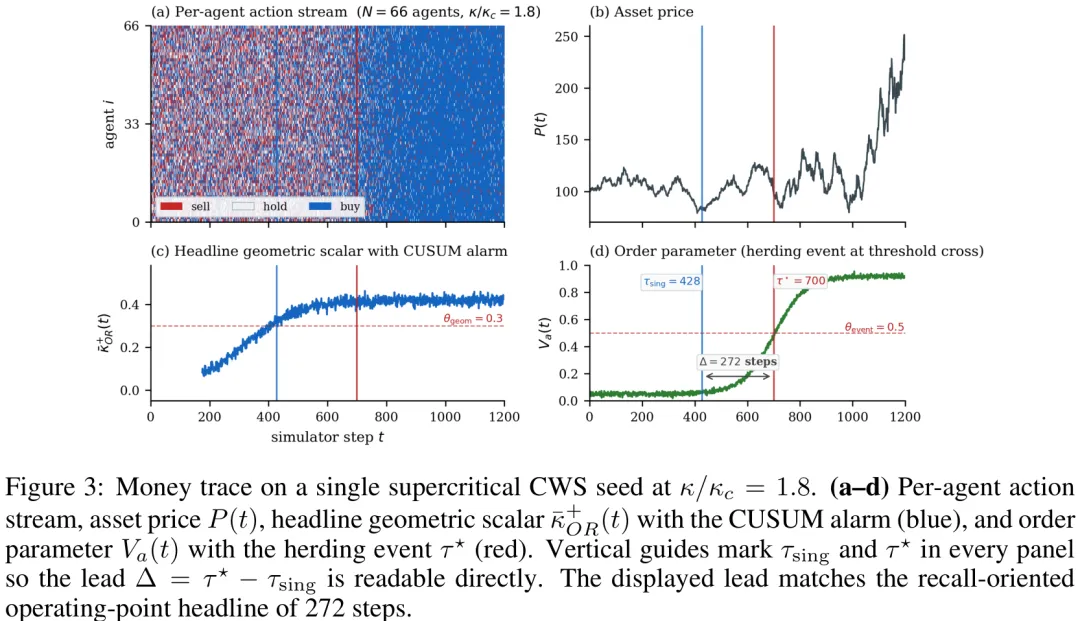
该研究提出了一种名为 GeomHerd 的新框架,旨在通过几何信号提前检测金融市场的羊群行为。研究核心在于利用智能体交互图的曲率信号(κ̅_OR(t))来预测协调时间,而非仅依赖价格相关性或交易流聚合。方法上,研究结合了单侧累积和(CUSUM)检测器与 Kendall-τ 斜率测试以增强对缓慢漂移和非高斯噪声的鲁棒性,并引入离散 Ricci 流计算奇点时间(τ_sing)作为前瞻性指标,同时通过有限标量量化(FSQ)构建有效词汇量(V_eff)来监测行为同质化。理论层面,研究建立了图曲率与经典 CSAD 回归指标之间的均值场标度关系,证明了曲率升高对应羊群行为增强。实验部分在 Cividino-Sornette 连续自旋模型及 Vicsek 模型上验证了该框架,证实几何信号能比传统价格相关图更早发出预警,且其分解出的正负曲率分量能有效区分群内收紧与群间桥梁两种羊群机制,展现出超越单纯检测的预测能力,并具备跨非金融系统的泛化潜力。
中文摘要
摘要:羊群效应——即智能体调整其行为并集体行动的现象——是市场脆弱性和系统性风险的核心驱动因素。现有的量化羊群效应方法依赖于价格相关性统计,由于仅在协调行为已实际影响收益率后才检测到协同,因此本质上存在滞后性。我们提出了 GeomHerd,一种前瞻性的几何框架,该框架通过直接在上游智能体交互图中量化协同,从而规避了这种可观测性滞后。为了构建这些交互图,我们将一个异构的由大语言模型(LLM)驱动的多智能体模拟器——其中每个金融交易员均由一个基于角色设定的 LLM 调用实例化——视为可预测的世界,并在 Cividino-Sornette 连续自旋智能体基底层上评估该几何流程,将其作为主要的金融测试平台。通过追踪这些行为图的离散 Ollivier-Ricci 曲率,GeomHerd 捕捉了新兴协同的结构拓扑。在理论上,我们建立了一个平均场桥梁,将我们的图论度量映射到 CSAD(经典宏观羊群统计量),从而将 GeomHerd 与下游的价格离散度测量联系起来。在实证方面,GeomHerd 比 aggregate 市场基准提前很久预测到羊群效应:在连续自旋基底层上,我们的主要检测器在序参量出现前中位提前 272 步触发;传播检测器(β₋)提前 318 步召回了 65% 的关键轨迹;而在共同触发轨迹中,智能体图信号比价格相关图基准提前 40 步。作为补充指标,在级联过程中智能体行为的有效词汇量会收缩。该几何特征可跨域迁移至 Vicsek 自驱动粒子模型,且基于曲率的预测头在级联窗口内的对数收益率平均绝对误差(MAE)方面,优于基于检测器和仅基于价格的基准。
Paper Key Illustration
原文
GeomHerd: A Forward-looking Herding Quantification via Ricci Flow Geometry on Agent Interactive Simulations
Abstract: Herding -- where agents align their behaviors and act collectively -- is a central driver of market fragility and systemic risk. Existing approaches to quantify herding rely on price-correlation statistics, which inherently lag because they only detect coordination after it has already moved realised returns. We propose GeomHerd, a forward-looking geometric framework that bypasses this observability lag by quantifying coordination directly on upstream agent-interaction graphs. To generate these graphs, we treat a heterogeneous LLM-driven multi-agent simulator -- each financial trader instantiated by a persona-conditioned LLM call -- as a forecastable world, and evaluate the geometric pipeline on the Cividino--Sornette continuous-spin agent-based substrate as our headline financial testbed. By tracking the discrete Ollivier--Ricci curvature of these action graphs, GeomHerd captures the structural topology of emerging coordination. Theoretically, we establish a mean-field bridge mapping our graph-theoretic metric to CSAD, the classical macroscopic herding statistic, linking GeomHerd to downstream price-dispersion measurement. Empirically, GeomHerd anticipates herding long before aggregate market baselines: on the continuous-spin substrate, our primary detector fires a median of 272 steps before order-parameter onset; a contagion detector (β_-) recalls 65% of critical trajectories 318 steps early; and on co-firing trajectories the agent-graph signal precedes price-correlation-graph baselines by 40 steps. As a complementary indicator, the effective vocabulary of agent actions contracts during cascades. The geometric signature transfers out-of-domain to the Vicsek self-driven-particle model, and a curvature-conditioned forecasting head reduces cascade-window log-return MAE over detector-conditioned and price-only baselines.
链接:https://arxiv.org/pdf/2605.11645
AI 深度解读
本文提出了一种名为“状态孪生体(State Twin)”的架构,旨在解决去中心化金融(DeFi)中智能体(Agent)进行链下模拟与反事实分析时的计算瓶颈。研究指出,现有的反应式架构强制所有状态查询必须通过链上读取(chain-read),这导致反事实推演、系综查询和轨迹分析等操作在数学上变得不可行或效率极低。为此,文章定义了状态孪生体为一种内存中的对象,该对象在结构上与链上状态同构,并满足状态保真度、观测等价性、过渡等价性及独立分叉四项核心属性。通过引入“松弛度(slack)”概念,论文证明了在实数域运算下,状态孪生体与链上状态完全等价;而在定点数运算下,其误差可被严格界定(如 Balancer 和 Curve 等主流协议中误差极小,可忽略不计)。该方法论将 DeFi 协议(如 Balancer 加权几何平均、Stableswap 放大不变量)的数学函数从链上依赖中解耦,使得智能体能够在本地直接评估风险指标、执行反事实策略推演,而无需频繁交互区块链,从而实现了从被动响应到主动预测的架构范式转变。
中文摘要
摘要:我们提出了 State Twin:一种针对链上自动做市商(AMM)池的有类型、内存内且可重放的副本,作为代理推理在去中心化金融(DeFi)协议上的基础架构。当前的代理 DeFi 架构将推理与链上时间耦合,因为每一个“如果……会怎样?”的查询都会产生新的 RPC 读取或真实交易,因此代理的有效操作空间受限于区块确认延迟和 Gas 费用。我们认为这种耦合是一个结构性问题而非性能问题,缺失的层次是一个链下基础架构,它在保留协议精确数学特性的同时,允许链上状态无法执行的操作:分叉、重放、分支及反事实推演。我们将每个 AMM 家族(Uniswap V2、V3、Balancer、Stableswap)形式化为离散时间受控动力系统,证明了 Twin 与链上状态之间发散性的定量保真度界限,并介绍了在 DeFiPy v2 中使用的开放架构,DeFiPy v2 是一个开源 Python 工具包,提供 State Twin 基础架构以及一个参考模型上下文协议(MCP)服务器,该服务器将具有类型化的分析原语作为 LLM 工具暴露出来。同一个原语(即一个 Python 类、一种调用模式)无需修改即可服务于量化笔记本、回测以及 LLM 代理。最后,我们通过一个“分叉并评估”的工作示例进行总结:一次实时的 RPC 读取在亚秒级的墙钟时间内,在 N 个不同的价格冲击场景下生成了 N 个独立的内存内 Twin。我们的贡献在于基础架构本身,而非特定的代理,这正是对代理 DeFi 基础架构应具备形态的规范说明。

Paper Key Illustration
原文
State Twins: An Off-Chain Substrate for Agentic Reasoning over Decentralized Finance Protocols
Abstract: We introduce the State Twin: a typed, in-memory, replayable replica of an on-chain automated market maker (AMM) pool that serves as a substrate for agentic reasoning over decentralized finance (DeFi) protocols. Agentic DeFi stacks today couple reasoning to chain time, since every "what if?" query incurs a new RPC read or a real transaction, so the agent's effective action space is bounded by block confirmation latency and gas. We argue this coupling is a structural problem rather than a performance one, and that the missing layer is an off-chain substrate that preserves the protocol's exact mathematics while admitting the operations on-chain state cannot: forking, replay, branching, counterfactual rollout. We formalize each AMM family (Uniswap V2, V3, Balancer, Stableswap) as a discrete-time controlled dynamical system, prove a quantitative fidelity bound on the divergence between twin and chain, and give the open architecture used in DeFiPy v2, an open-source Python toolkit that ships the State Twin substrate and a reference Model Context Protocol server exposing typed analytical primitives as LLM tools. The same primitive (i.e., one Python class, one calling pattern) serves a notebook quant, a backtest, and an LLM agent without modification. We close with a fork-and-evaluate worked example: a single live RPC read seeds N independent in-memory twins under distinct price-shock scenarios, in sub-second wall-clock time. The contribution is the substrate, not a particular agent, which is what the specification of what an agentic DeFi substrate must look like
链接:https://arxiv.org/pdf/2605.11522
AI 深度解读
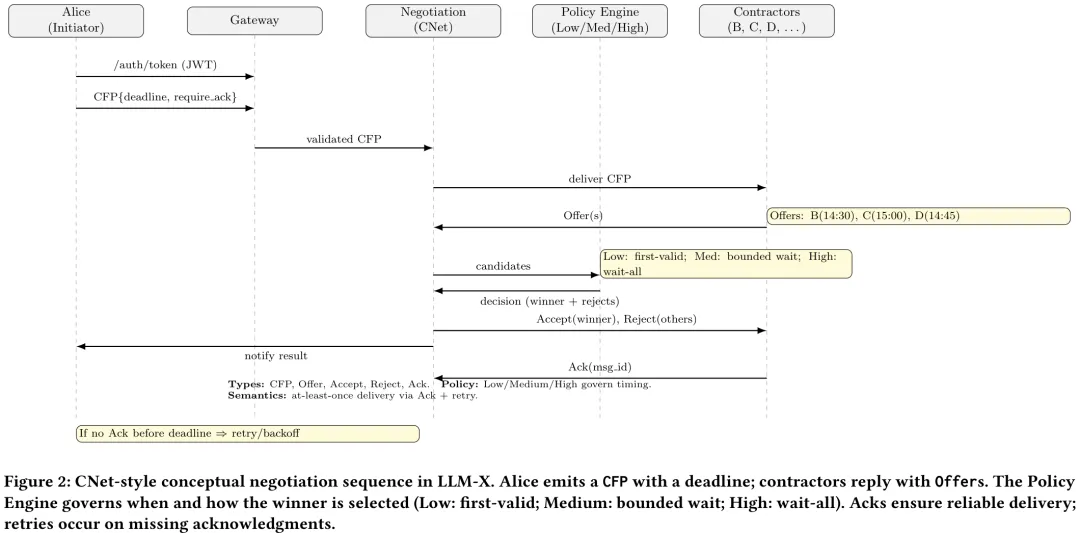
LLM-X 架构旨在支持符合 FIPA 交替报价标准的协商流程,允许代理在明确截止日期下迭代交换反报价直至达成协议或终止。该架构采用以协商为核心的设计,通过 JSON 信封绑定明确的数据模式(如 CFP、Offer、Accept/Reject、Ack),确保互操作性与安全性。系统包含网关(负责 JWT 认证、模式验证及速率限制)、策略引擎(根据低、中、高三档策略控制决策时机)以及基于 NATS/HTTP 的传输层。实验部分构建了 Python 代理原型,模拟了从 5 到 12 个承包商的不同规模场景,并对比了三种接受策略:低策略(首个有效响应即关闭)、中策略(有界等待)和高策略(收集所有报价后决策)。实验采用泊松过程生成负载,记录了每分钟的消息量、延迟(p50/p95)及吞吐量。结果显示,系统在短跑测试中验证了模式正确性与日志稳定性,在扩展运行中证实了在高负载下(如 12 个代理运行 12 小时)仍能保持稳定的性能模式,证明了 LLM-X 能够灵活适配多种协调原语并支持实时 LLM API 的无缝集成。
中文摘要
摘要:我们提出了一种个人大语言模型交换(LLM-X)框架,这是一个可扩展的、面向协商的环境,能够支持代表各个用户的大语言模型(个人代理)群体之间进行直接的结构化通信。与现有侧重于代理-API 交互的工具中心协议不同,LLM-X 引入了消息总线与路由底层架构,为大语言模型间的协调提供了模式有效性保证及策略执行保障。本文的贡献包括:(1)LLM-X 的架构设计,涵盖联邦网关、基于主题的路由以及策略执行机制;(2)一种支持能力协商及合同网式协调的类型化消息协议;(3)首次针对大规模基于大语言模型的多代理协商进行的实证评估。实验涵盖了 5、9 和 12 个代理,在三种不同的协商策略(低、中、高)下,并在短期(分钟级)和长期(2 小时、12 小时)负载条件下进行测试。结果表明存在明确的策略与性能权衡:更严格的策略提升了鲁棒性和公平性,但增加了延迟和消息量。扩展运行实验证实,LLM-X 在持续负载下保持稳定,且延迟漂移处于有界范围内。
Paper Key Illustration
原文
LLM-X: A Scalable Negotiation-Oriented Exchange for Communication Among Personal LLM Agents
Abstract: We propose a personal-LLM exchange (LLM-X), a scalable negotiation-oriented environment that enables direct, structured communication across populations of personal agents (LLMs), each representing an individual user. Unlike existing tool-centric protocols that focus on agent-API interaction, LLM-X introduces a message bus and routing substrate for LLM-to-LLM coordination with guarantees around schema validity and policy enforcement. We contribute: (1) an architecture for LLM-X comprising federated gateways, topic-based routing, and policy enforcement; (2) a typed message protocol supporting capability negotiation and contract-net-style coordination; and (3) the first empirical evaluation of LLM-based multi-agent negotiation at scale. Experiments span 5, 9, and 12 agents, under distinct negotiation policies (Low, Medium, High), and across both short-run (minutes) and long-run (2h, 12h) load conditions. Results highlight clear policy-performance trade-offs: stricter policies improve robustness and fairness but increase latencies and message volume. Extended runs confirm that LLM-X remains stable under sustained load, with bounded latency drift.
链接:https://arxiv.org/pdf/2605.11376
AI 深度解读
该研究针对生成模型优化中路径积分控制(PIC)方差过高的问题,提出了一种基于线性化近似和零阶奖励评估的改进方法。研究首先指出,在奖励方差较小的假设下,通过从奖励中减去均值(中心化)并利用泰勒展开线性化指数加权项,可推导出一个更稳定的控制估计器。该估计器与自然进化策略(NES)中的得分函数估计器一致,且能兼容不可微或黑盒奖励函数。在参考动力学选择上,研究摒弃了会导致噪声方差失控的方差爆炸(VE)SDE,转而采用方差保持(VP)的奥恩斯坦 - 乌伦贝克(OU)过程,确保噪声分布始终与预训练生成器兼容。理论分析表明,在离散化 OU 过程中,控制信号随时间步长呈指数衰减,因此研究采用单步视域(H=1)近似,以在保持强信号的同时降低计算成本。此外,为修正控制项导致的噪声范数漂移,算法在每次更新后对噪声进行重归一化。实验部分通过二维高斯混合模型玩具实验及真实生成模型验证,结果表明该方法能有效引导样本流向全局高奖励模式,在模式概率分布和 KL 散度指标上均优于基于梯度的方法和传统的流 ODE 方法,证明了其在提升生成质量方面的有效性与可扩展性。
中文摘要
摘要:现有的扩散模型和流模型的奖励对齐方法依赖于多步随机轨迹,使其难以扩展至确定性生成器。一种自然的替代方案是噪声空间优化,但现有方法需要通过生成器和奖励管道进行反向传播,从而将适用范围限制在可微分设置中。为解决这一问题,本文提出了 ZeNO(零阶噪声优化),这是一种无梯度框架,将噪声优化表述为路径积分控制问题,并可仅凭零阶奖励评估进行估计。当采用 Ornstein-Uhlenbeck 参考过程实例化时,其更新规则隐式地连接至针对奖励倾斜分布的朗之万动力学。ZeNO 实现了有效的推理阶段扩展,并在多种生成器和奖励函数上展现出强大的性能,包括在反向传播不可行的蛋白质结构生成任务中。

Paper Key Illustration
原文
Gradient-Free Noise Optimization for Reward Alignment in Generative Models
Abstract: Existing reward alignment methods for diffusion and flow models rely on multi-step stochastic trajectories, making them difficult to extend to deterministic generators. A natural alternative is noise-space optimization, but existing approaches require backpropagation through the generator and reward pipeline, limiting applicability to differentiable settings. To address this, here we present ZeNO (Zeroth-order Noise Optimization), a gradient-free framework that formulates noise optimization as a path-integral control problem, estimable from zeroth-order reward evaluations alone. When instantiated with an Ornstein--Uhlenbeck reference process, the update connects to Langevin dynamics implicitly targeting a reward-tilted distribution. ZeNO enables effective inference-time scaling and demonstrates strong performance across diverse generators and reward functions, including a protein structure generation task where backpropagation is infeasible.
链接:https://arxiv.org/pdf/2605.11347
AI 深度解读
本研究针对代谢组学中二部图噪声 OR 模型概率推断效率低下的问题,提出了一种基于 Rust 语言的高性能实现工具 NORI。该工具创新性地结合了零前瞻信念传播算法、卷积树消息更新机制以及缓存高效的图表示方法,显著优化了计算资源利用。在 iPRG2016 大规模人类蛋白质组学数据集及 SIHUMI S03 宏蛋白质组学数据集上的基准测试表明,NORI 相比现有的 Epifany 和 Peptonizer2000 等工具,在蛋白质推断和分类学分析任务中分别实现了 89 至 242 倍的加速比,同时大幅降低了内存占用。其通用的观测 - 实体接口设计使其不仅适用于蛋白质推断,还可扩展至宏蛋白质组学中的功能分析等场景,为处理大规模生物信息学图数据提供了高效的解决方案。
中文摘要
NORI 通过概率推理解决实验观测与生物实体之间的模糊映射问题,其速度比最先进方法快几个数量级。这使得大规模分析和广泛的超参数优化成为可能,并支持更广泛的生物信息学应用,包括蛋白质推断以及在组学领域中的分类和功能分析。

Paper Key Illustration
原文
NORI: Fast probabilistic inference for ambiguous observation-entity mappings
Abstract: NORI performs probabilistic inference to resolve ambiguous mappings between experimental observations and biological entities orders of magnitude faster than state-of-the-art methods. This makes large-scale analysis and extensive hyperparameter optimization possible, and supports a broader range of bioinformatics applications, including protein inference, taxonomic and functional analysis in omics-fields.
链接:https://arxiv.org/pdf/2605.11648
AI 深度解读
针对大规模 LLM 预训练中因节点故障导致的全局迭代中断问题,本文提出了一种名为 RECOVER 的三层容错框架。该框架的核心创新在于利用用户级故障缓解(ULFM)机制,将传统的‘故障即终止’模式转变为‘故障即降级’模式,确保只要有一个副本存活,迭代即可继续。
在底层,RECOVER 引入了 ULFM_ALLREDUCE 和 ULFM_CONSENSUS 两个原语。前者在检测到部分进程死亡后,自动收缩通信组并在幸存者之间完成归约,同时返回一致的失败信号;后者则确保所有副本对故障视图达成一致,避免状态不一致。这一层实现了故障隔离,防止单点故障引发整个作业崩溃。
在中层,系统通过细粒度的梯度桶(gradient-bucket)快照机制实现迭代内的故障恢复。在每次归约前保存梯度状态,一旦底层检测到故障,系统仅恢复较小世界版本(world epoch)的快照,从而丢弃故障副本贡献的无效梯度,同时保留幸存副本的进度。这解决了传统容错方法(如 FTAR)必须丢弃整个迭代进度的缺陷。
在顶层,系统采用动态工作负载策略,根据故障情况调整副本角色(如将备用副本提升为主副本),以维持每步固定的微批次数量,确保优化器步长的一致性。
实验与理论分析表明,该框架在保持与无故障运行相同的梯度分布和收敛特性的同时,显著提升了大规模集群的可用性。通过将故障处理封装为原语,RECOVER 实现了通信容错与并行结构的解耦,为超大规模模型训练提供了鲁棒的工程解决方案。
中文摘要
摘要:在大规模 GPU 集群上对大语言模型进行预训练,使得硬件故障成为常态而非罕见事件,从而催生了对高容错训练系统的需求。然而,现有框架要么专注于特定的并行方案,要么存在偏离无故障训练轨迹的风险。我们提出了 ReCoVer,一种高容错的大语言模型预训练系统,其遵循单一不变量:每个迭代步骤保持微批次数量恒定,确保每次迭代的梯度在统计上与无故障运行等效。该框架由三个解耦的协议层组成:(1) 容错集合通信,将故障隔离以防止在副本间传播;(2) 步内细粒度恢复,保留迭代内的进度并防止梯度污染;(3) 灵活的工作负载策略,动态地将微批次配额重新分配给幸存节点。该设计对并行方案无关,可直接作为即插即用的底层支持,与三维并行及混合分片数据并行(HSDP)无缝集成。我们在多达 512 张 GPU 的端到端预训练任务上评估了该实现,尽管在整个运行过程中损失了 256 张 GPU,ReCoVer 仍能成功保持与无故障参考运行一致的训练轨迹。与检查点重启基线相比,ReCoVer 在连续故障后展现出 2.23 倍的有效吞吐量提升。这一优势使得 ReCoVer 在 234 GPU 小时的计算成本下处理了多 74.9% 的 token,且随着训练时间的延长,这一差距进一步扩大。
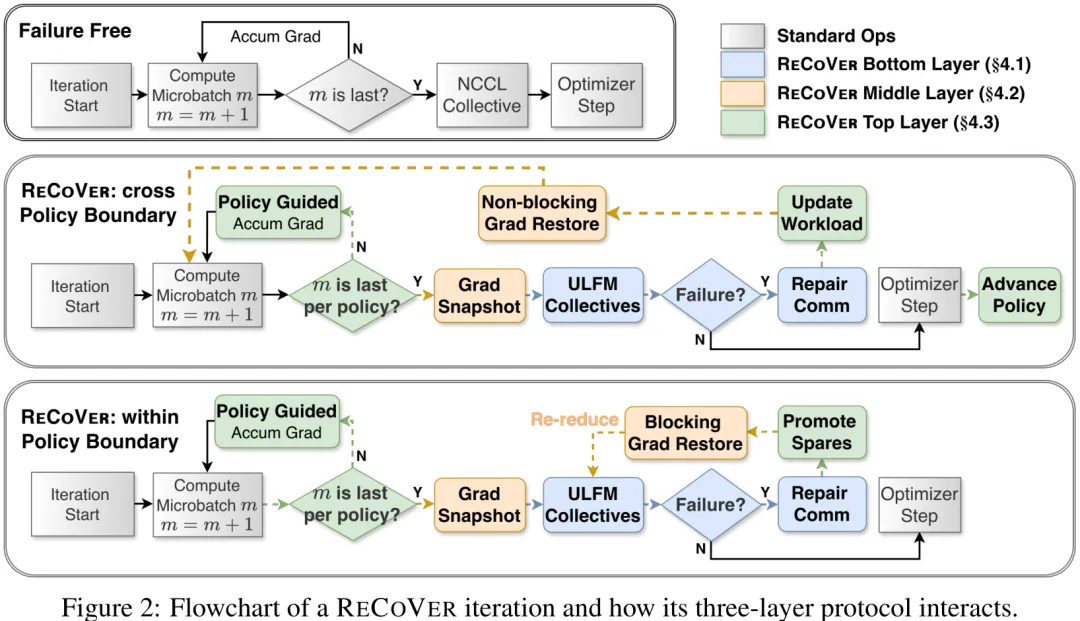
Paper Key Illustration
原文
ReCoVer: Resilient LLM Pre-Training System via Fault-Tolerant Collective and Versatile Workload
Abstract: Pre-training large language models on massive GPU clusters has made hardware faults routine rather than rare, driving the need for resilient training systems. Yet existing frameworks either focus on specific parallelism schemes or risk drifting away from a failure-free training trajectory. We propose ReCoVer, a resilient LLM pre-training system that upholds a single invariant: each iteration keeps the number of microbatches constant, ensuring per-iteration gradients remain stochastically equivalent to a failure-free run. The framework is organized as three decoupled protocol layers: (1) Fault-tolerant collectives that isolate faults from propagating across replicas; (2) in-step fine-grained recovery that preserves intra-iteration progress and prevents gradient corruption; (3) versatile-workload policy that dynamically redistributes microbatch quotas across the survivors. The design is parallelism-agnostic, integrating directly with both 3D parallelism and Hybrid Sharded Data Parallel (HSDP) as a drop-in substrate. We evaluate our implementation on end-to-end pre-training tasks for up to 512 GPUs, ReCoVer successfully preserves the training trajectory from a failure-free reference despite of 256 GPUs lost spread across the run. For comparison with checkpoint-and-restart baselines, ReCoVer demonstrates 2.23× higher effective throughput after successive failures. This advantage results in ReCoVer processing 74.9% more tokens at 234 GPU-hours, with the gap widening as the training prolongs.
链接:https://arxiv.org/pdf/2605.11215
AI 深度解读
该研究聚焦于蛋白质复合物结构预测中的配对问题,旨在解决 AlphaFold-Multimer (AF-Multimer) 在特定靶标上表现不佳的挑战。研究提出了一种名为 ESMPair 的新方法,该方法利用 ESM 语言模型生成的成对序列信息(Pair MSA)来增强预测能力。在评估中,ESMPair 在 pConf70 测试集上取得了优于 AF-Multimer 的 DockQ 分数,特别是在处理低置信度靶标时表现显著。研究进一步对比了多种替代配对策略和集成方法,发现结合基因组数据(Genome)的成对集成策略(ESM-Pair + Genome)能进一步提升预测精度,而包含三种策略的集成方案则达到了最高的整体性能(DockQ 0.285,成功率 46.8%)。此外,研究分析了影响预测性能的关键因素,发现列注意力分数(column attention score)与有效互作数呈负相关,表明模型对特定序列特征的捕捉能力直接影响预测质量。在生成式设计方面,研究构建了 RedNet 架构,利用图神经网络编码结构信息,并通过因果 Transformer 自回归地预测氨基酸序列。实验验证了该方法在重设计选择性结合对(如 6FOE–5WHJ 和 5FFN–1LW6)时的有效性,能够准确预测针对靶标和脱靶复合物的特异性结合模式,展示了从结构预测到功能分子设计的完整能力。
中文摘要
准确建模和设计蛋白质复合物结构是计算结构生物学中的核心问题,对理解细胞功能和开发疗法具有广泛意义。本论文利用深度学习探讨了该问题的两个基本方面:一是能够捕捉蛋白质结构层次特性的领域专用架构,二是能够在蛋白质复合物庞大的序列空间中高效导航以识别相互作用同源体的搜索算法,旨在改进复合物结构预测并设计蛋白质序列。
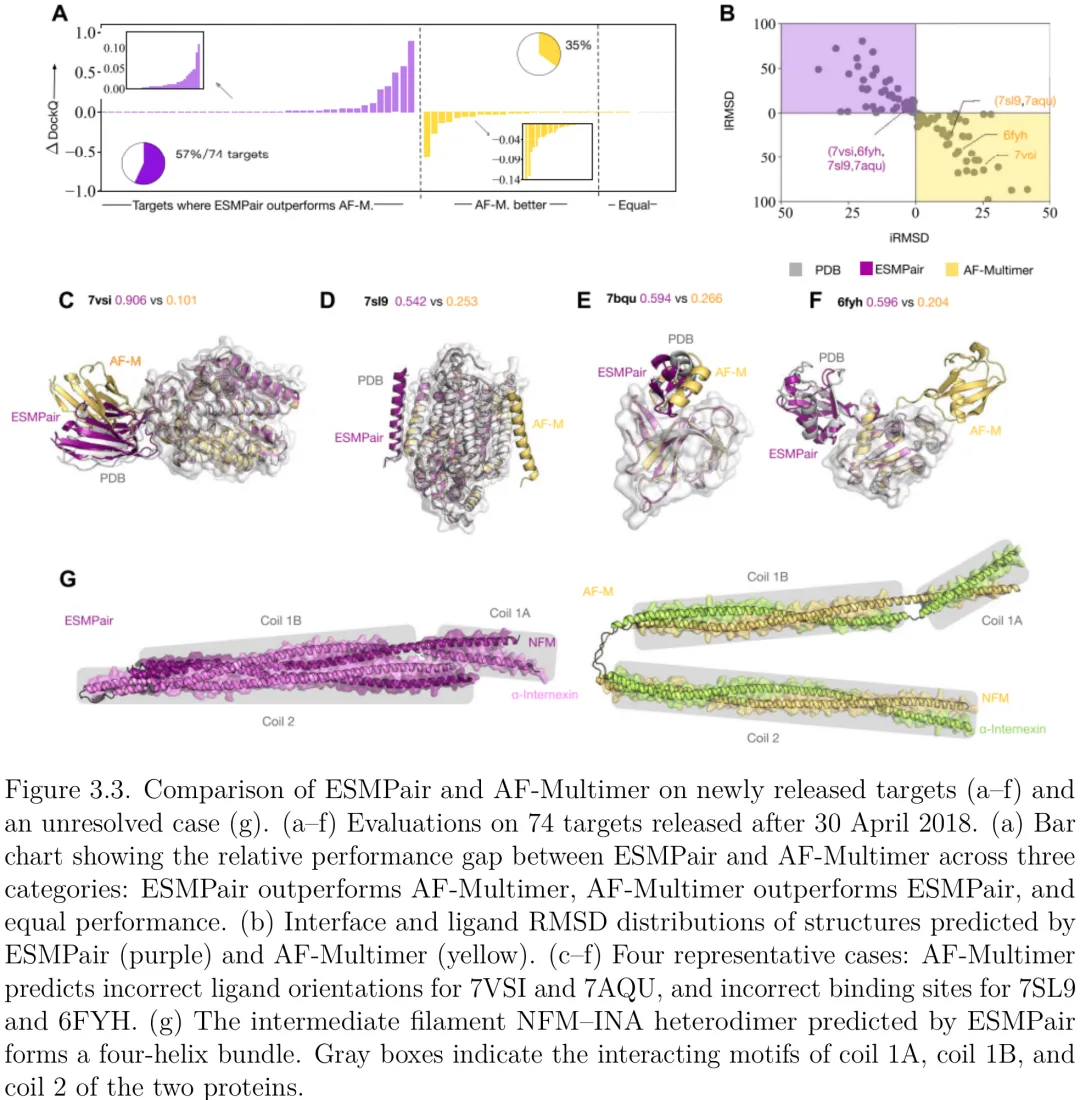
Paper Key Illustration
原文
Deep Learning for Protein Complex Prediction and Design
Abstract: Accurately modeling and designing protein complex structures is a central problem in computational structural biology, with broad implications for understanding cellular function and developing therapeutics. This thesis investigates two fundamental aspects of this problem using deep learning: domain-specific architectures that capture the hierarchical nature of protein structures, and search algorithms that efficiently navigate the vast sequence spaces of protein complexes to identify interacting homologs for improving complex structure prediction and to design protein sequences.
链接:https://arxiv.org/pdf/2605.11189
AI 深度解读
GRAFT-ATHENA 是一个面向科学计算与科学机器学习的自主智能框架,其核心在于构建一个具备几何记忆特性的联合问题 - 方法空间。该框架利用图缩减技术(GRAFT)将复杂的求解器配置依赖关系转化为可导航的因子化决策树,从而将离散的运行实例映射为连续几何空间中的点。在此空间中,每个已解决的实例不仅记录其指纹(问题路径与方法路径),还关联观测值(如误差、耗时)与奖励,使得系统能够非破坏性地积累知识。研究展示了该框架如何通过最近邻搜索实现跨问题的经验迁移,利用指纹相似性加权的方法组合来引导新问题的求解策略,并基于历史邻居的性能数据校准预期目标。实验结果表明,GRAFT-ATHENA 能够自主吸收生产级求解器(如 Trixi.jl、Nektar++)的新文档与方法,动态扩展其知识图谱;同时,它成功应用于红细胞流变学的粒子 DPD 研究、体内逆问题的适定重构以及具备指数收敛性的谱 PINN 设计等具体科学任务。该框架证明了科学计算系统可以通过闭环的提出 - 实现 - 评估循环,从孤立的问题求解进化为具备反事实推理能力的几何导航系统,实现了从‘解决单个问题’到‘在方法空间中探索’的范式转变。
中文摘要
摘要:科学发现可被建模为一系列概率决策过程,将物理问题映射为数值解。近期的智能体(Agentic)人工智能系统通过编排由大语言模型(LLM)驱动的规划器、求解器和评估器,实现了单个科学任务的自动化。每种方法均为方法论动作的组合,针对任一给定问题均存在多种可行的组合,且各选择之间存在结构依赖关系。然而,现有框架孤立地处理每个问题,缺乏共享的底层机制以跨领域积累方法论经验。本文提出 GRAFT-ATHENA,一种自我改进的智能体框架,能够从过往问题中学习,并自主地在多样化领域中扩展其动作空间。GRAFT(图缩减至自适应因子树)将组合决策空间投影为因子化的概率树,其中每种方法对应一条单一路径,从而将参数规模从指数级降低至线性级。在经典贝叶斯网络的发展脉络中,这种因子化构成了策略的I-映射,生成的路径嵌入到度量空间中,形成独特的“指纹”;其相似性使得每个新问题能够从类似的过往问题中学习。在标准的物理信息机器学习(PIML)基准测试中,GRAFT-ATHENA 的表现优于人类及先前的智能体基线;在生产级求解器应用中,它成功解决了复杂的工程问题,例如基于 1968 年的报告重构阿波罗指令舱马赫数为 10 时的流动,以及恢复剪切变稀的血细胞流变学特性。值得注意的是,该系统能够自主构建其知识底层,为不适定反问题提出正则化约束,并发现新的数值方法,如具有指数收敛性的谱 PINN。这些成果为构建能够随着所解决问题数量的增加而不断增强的自主实验室奠定了基础。
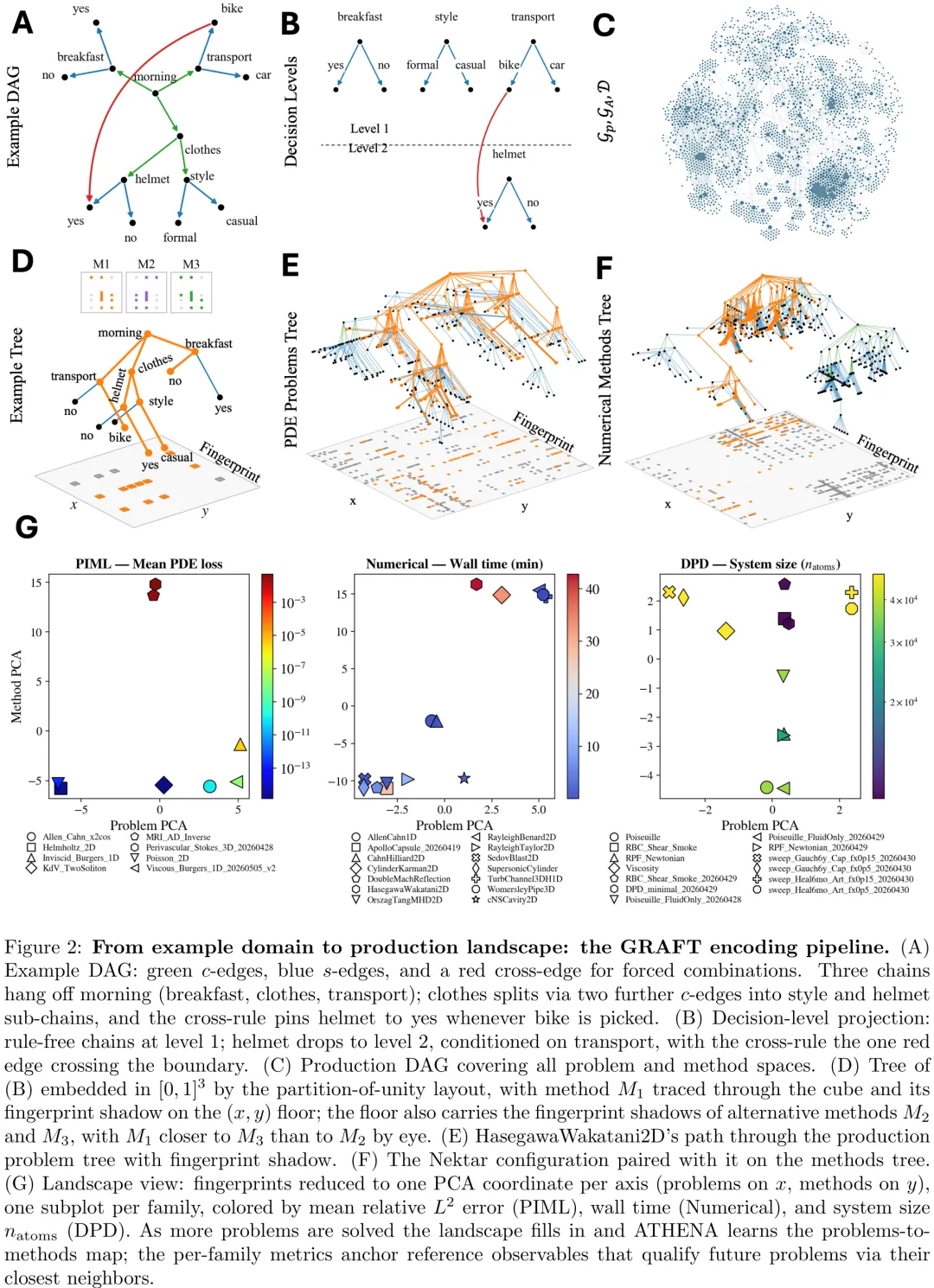
Paper Key Illustration
原文
GRAFT-ATHENA: Self-Improving Agentic Teams for Autonomous Discovery and Evolutionary Numerical Algorithms
Abstract: Scientific discovery can be modeled as a sequence of probabilistic decisions that map physical problems to numerical solutions. Recent agentic AI systems automate individual scientific tasks by orchestrating LLM-driven planners, solvers, and evaluators. Each method is a combination of methodological actions, with many viable combinations for any given problem and structural dependencies between choices. However, existing frameworks treat each problem in isolation, with no shared substrate to accumulate methodological experience across domains. Here we show that GRAFT-ATHENA, a self-improving agentic framework, learns from past problems and autonomously expands its own action space across diverse domains. GRAFT (Graph Reduction to Adaptive Factored Trees) projects combinatorial decision spaces into factored probabilistic trees in which each method is a single path, taking the parameter footprint from exponential to linear. In the lineage of classical Bayesian networks, the factorization is an I-map of the policy, and the resulting paths embed as unique fingerprints in a metric space whose closeness lets each new problem learn from similar past ones. On canonical physics-informed machine learning (PIML) benchmarks, GRAFT-ATHENA improves over human and prior agentic baselines, and on production solvers, it tackles complex engineering problems such as reconstructing Mach-10 flow over the Apollo Command Module from a 1968 report and recovering shear-thinning blood-cell rheology. Notably, the system grows its own knowledge substrate, autonomously proposing regularization constraints for ill-posed inverse problems and discovering new numerical methods such as a spectral PINN with exponential convergence. These results provide a foundation for autonomous laboratories that grow more capable with every problem they solve.
链接:https://arxiv.org/pdf/2605.11117
AI 深度解读
针对高性能大模型推理服务中内部状态观测能力缺失且现有方案存在性能开销大、灵活性差及移植性低的问题,本文提出了 DMI-Lib 系统。该系统旨在在不干扰推理流水线的前提下,灵活采集从隐藏状态到中间激活值等任意内部数据。其核心设计包含三个关键组件:一是 HookPoint,一种轻量级插桩原语,可无缝嵌入模型前向图以捕获任意张量;二是 Ring2,一种设备 - 主机协同设计的内存缓冲机制,将设备端捕获的原始张量隔离存储,避免占用 KV Cache 等关键资源;三是 Data Exporter,异步主机端引擎,负责持续从 Ring2 中卸载数据并重构元数据。为应对硬件带宽限制导致的背压问题,系统引入了运行时策略管理器,支持在图拓扑层面进行数据过滤,并在运行时根据用户策略动态决定是暂停以保完整还是丢弃请求以保吞吐。实验表明,DMI-Lib 在正常负载下对推理速度的影响微乎其微,而在过载场景下其性能收敛于同步卸载机制,有效解决了在线服务中内部观测与高性能推理之间的兼容性问题。
中文摘要
摘要:当今的推理时代工作负载越来越依赖于及时访问模型的内部状态。我们提出了 DMI-Lib,一种高速深度模型检查器,它将内部可观测性视为一等系统原语,通过基于 Ring^2(一种用于捕获和暂存张量的 GPU-CPU 内存抽象)构建的异步可观测性底层,将其与推理热点路径解耦,并由策略控制的主机后端导出这些张量。DMI-Lib 支持在丰富的内部信号空间和多样化的推理后端中放置观测点,同时保留服务优化并严格遵守紧张的 GPU 内存预算。我们的实验表明,DMI-Lib 在离线批处理推理中的开销仅为 0.4%–6.8%,在中等规模的在线服务中平均开销为 6%,相比具有类似可观测性功能的现有基线,其延迟开销降低了 2 至 15 倍。DMI-Lib 已在 https://github.com/ProjectDMX/DMI 开源。
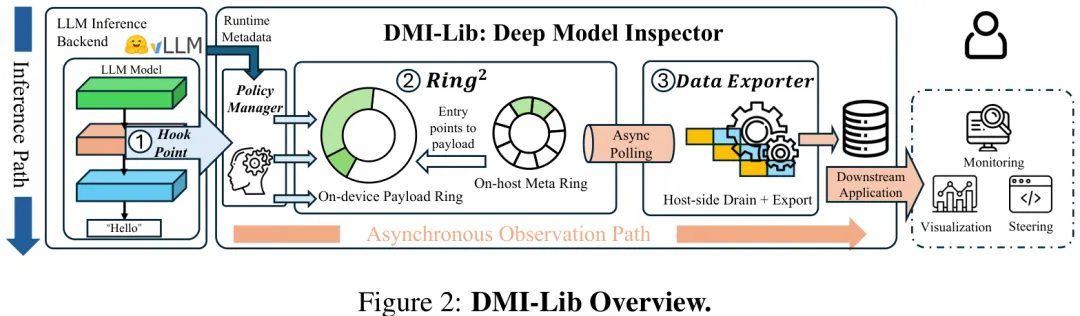
Paper Key Illustration
原文
Enabling Performant and Flexible Model-Internal Observability for LLM Inference
Abstract: Today's inference-time workloads increasingly depend on timely access to a model's internal states. We present DMI-Lib, a high-speed deep model inspector that treats internal observability as a first-class systems primitive, decoupling it from the inference hot path via an asynchronous observability substrate built from Ring^2, a GPU-CPU memory abstraction for capturing and staging tensors, and a policy-controlled host backend that exports them. DMI-Lib enables the placement of observation points across a rich space of internal signals and diverse inference backends while preserving serving optimizations and adhering to tight GPU memory budgets. Our experiments demonstrate that DMI-Lib incurs only 0.4%--6.8% overhead in offline batch inference and an average of 6% in moderate online serving, reducing latency overhead by 2x-15x compared to existing baselines with similar observability features. DMI-Lib is open-sourced at https://github.com/ProjectDMX/DMI.
链接:https://arxiv.org/pdf/2605.11093
AI 深度解读
本研究针对从全文本文章及补充材料中提取结构化 TPD(靶点降解)实验记录的挑战,提出了一种无需模型微调或大规模标注语料的专家在环大语言模型(LLM)工作流。该工作流核心在于一个轻量级的交叉验证提示词优化模块(CAPO),其采用自动化双循环机制:内循环利用 Extractor 智能体对单篇论文进行多阶段推理提取,外循环则通过 Analyst 智能体诊断低精度样本的错误模式,并由 Refiner 智能体迭代更新提示词,直至达到预设的精度与召回率阈值。系统由三个 GPT-5 智能体(Extractor、Analyst、Refiner)及语义匹配模块构成,其中 Extractor 在零温度下运行以确保确定性,而 Analyst 与 Refiner 则通过较高温度激发多样化推理以优化策略。在大规模应用阶段,研究团队利用经过多轮迭代优化的“冠军提示词”对 MG 和 PROTAC 队列进行全量提取,并辅以单位归一化、去重及化学标识符富集等后处理步骤。评估框架采用分层策略,在实验模式(五要素键)和机制模式(三要素键)下,通过化合物名称匹配与标准 InChIKey 回退机制验证记录准确性,并进一步在字段级别评估数值、不等式及单位换算的正确性。最终,该流程不仅构建了包含专家人工修订的高质量基准数据集,还通过对比分析量化了 LLM 预测相对于传统数据库的增量价值,有效解决了现有资源在覆盖度与准确性上的不足。
中文摘要
摘要:生物医学领域的预测模型依赖于锁定在主要出版物文本、表格及补充材料中的结构化实验数据。这一瓶颈在靶向蛋白降解(TPD)领域尤为突出,因为每条实验记录必须整合化合物身份、降解靶点、招募剂、实验背景以及分散在各章节、表格和补充文件中的终点值。化合物标识符的不一致以及实验背景的缺失或隐含,进一步要求具备领域特定逻辑,而通用大语言模型(LLM)流程无法提供此类逻辑。现有的分子胶和PROTAC数据库多为人工整理,且往往缺乏下游建模所需的实验背景。我们将 TPD 数据库提取任务定义为领域特定的整理任务,并提出了一种“专家在环”的 LLM 工作流程,并通过大模型预测、标准化基线记录与专家标注真值之间的三角比较进行评估。一个轻量级的交叉验证提示词优化模块利用稀缺的专家标注对提取指令进行适配。仅使用七篇已标注的分子胶出版物,该工作流程即实现了记录级别的 F_1 = 0.98,并仅通过术语替换即可迁移至 PROTAC 领域,保持记录级别的 F_1 > 0.93。在大规模应用中,该工作流程分别将分子胶和 PROTAC 数据库的记录数量扩展了 81% 和 92%,其中经专家复核,新恢复记录的准确率分别为 92% 和 82.5%。此外,该工作流程还恢复了跨研究效力比较及条件感知降解建模所必需的药代动力学和实验背景信息。我们公开了该工作流程、提示词、评估代码及提取的数据集,作为 TPD 数据整理及更广泛的 AI 辅助科学整理的资源。
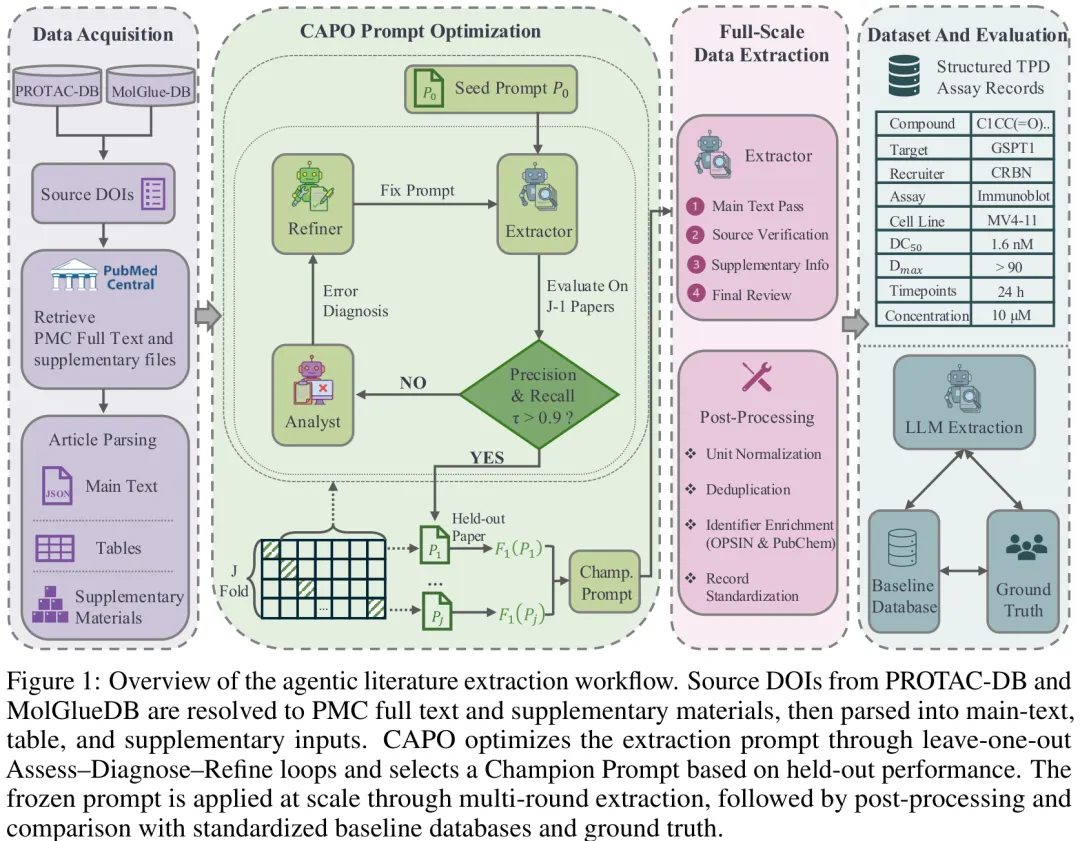
Paper Key Illustration
原文
Beyond Manual Curation: Augmenting Targeted Protein Degradation Databases via Agentic Literature Extraction Workflows
Abstract: Predictive models in biomedicine depend on structured assay data locked in the text, tables, and supplements of primary publications. This bottleneck is especially acute in targeted protein degradation (TPD), where each assay record must combine compound identity, degradation target, recruiter, assay context, and endpoint values reported across sections, tables, and supplementary files. Inconsistent compound identifiers and incomplete or implicit assay context further demand domain-specific logic that generic LLM pipelines do not provide. Existing molecular glue and PROTAC databases are manually curated and often lack the experimental context required for downstream modeling. We formulate TPD database extraction as a domain-specific curation task and present an expert-in-the-loop LLM workflow, evaluated through a triangular comparison among LLM predictions, standardized baseline records, and expert-annotated ground truth. A lightweight cross-validated prompt-refinement module adapts extraction instructions from scarce expert annotations. With only seven annotated molecular glue publications, the workflow achieved record-level F_1 = 0.98 and transferred to PROTACs by terminology substitution alone, maintaining record-level F_1 > 0.93. Applied at scale, it expanded molecular glue and PROTAC databases by 81% and 92% records, respectively, with 92% and 82.5% of newly recovered records validated as correct upon expert review. The workflow also recovered kinetic and assay-context information essential for cross-study potency comparison and condition-aware degradation modeling. We release the workflow, prompts, evaluation code, and extracted datasets as resources for TPD data curation and AI-assisted scientific curation more broadly.
链接:https://arxiv.org/pdf/2605.11221
AI 深度解读
该研究针对操纵子对(operon pair)的分类任务,旨在探索基于预训练蛋白质语言模型(PLM)的嵌入表示是否优于传统的理化特征。研究构建了一种孪生编码器(Siamese encoder)架构,利用 ESM-2 3B 和 ProtBERT-BFD 等预训练模型提取序列嵌入,并通过均值池化、拼接及交互操作融合特征,最后由多层感知机(MLP)进行分类。实验在存在显著类别不平衡的数据集上进行,采用了加权交叉熵损失函数、标签平滑及梯度裁剪等策略以优化训练稳定性。结果显示,基于 ESM-2 和 ProtBERT-BFD 的孪生模型在 ROC-AUC 指标上分别达到 0.7104 和 0.7064,相比仅使用理化特征的基线提升了约 10 个百分点,证明了嵌入模型在捕捉功能关系上的显著优势。然而,在平均精度(Average Precision)指标上,本研究提出的复杂孪生架构表现略低于 DGEB 基准中简单的余弦相似度方法(0.5172 vs 0.5247)。这一结果暗示,对于该特定任务,编码器本身的表征质量是决定性能的关键因素,而复杂的分类头结构并未带来额外的增益,甚至可能因模型较旧而受限于表征能力。尽管如此,该架构成功从较旧的编码器中提取了具有竞争力的判别信号,为未来结合更大规模或更新代的预训练模型提供了有价值的参考。
中文摘要
摘要:识别操纵子是理解原核生物基因调控的基础步骤,因为将基因归类为操纵子有助于重建调控网络、注释未注释基因的功能以及开发候选药物。RT-PCR 和 RNA-seq 等实验方法虽然能提供操纵子结构的精确证据,但操作繁琐,且主要局限于研究深入的模式生物,因此开发可扩展的计算方法对于全基因组操纵子识别至关重要。先前的计算方法采用了逻辑回归和决策树等传统分类器,这促使我们将它们作为理化性质基线。DGEB 基准测试通过预训练蛋白质语言模型独立嵌入每个序列,并计算成对余弦相似度来评估操纵子对分类。相比之下,我们的孪生多层感知机(Siamese MLP)在融合嵌入空间中学习分类器,这在理论上更适合二分类任务,因为余弦相似度可能会因嵌入模型的正则化而产生无意义的分数。尽管蛋白质语言模型嵌入在 ROC-AUC 上显著优于理化性质特征,但学习到的孪生 MLP 头在平均精度(Average Precision)上并未显著优于无监督的余弦相似度,这表明嵌入空间的几何结构已经捕捉到了该任务所需的功能关系。尽管如此,我们的孪生 MLP 实现了 0.71 的 ROC-AUC,在 DGEB 排行榜上与最先进模型具有竞争力。这些发现表明,蛋白质语言模型嵌入是适用于多样化微生物基因组操纵子对分类的可行且可扩展的基础,这对自动化基因组注释、调控网络重建以及缺乏实验操纵子注释的微生物特征分析具有重要意义。
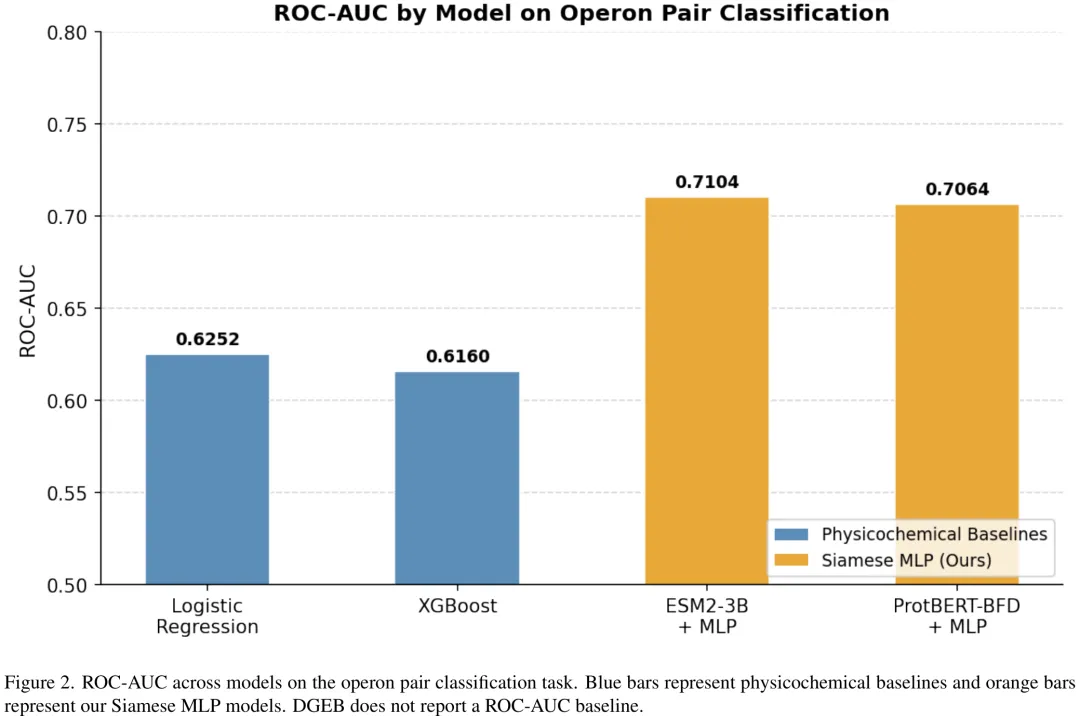
Paper Key Illustration
原文
SCOPE: Siamese Contrastive Operon Pair Embeddings for Functional Sequence Representation and Classification
Abstract: Identifying operons is a fundamental step in understanding prokaryotic gene regulation, as classifying genes into operons supports the reconstruction of regulatory networks, functional annotation of unannotated genes, and drug candidate development. Experimental approaches such as RT-PCR and RNA-seq provide precise evidence of operon structure, but are laborious and largely limited to well-studied model organisms, making scalable computational methods essential for genome-wide operon identification. Prior computational approaches have employed traditional classifiers such as logistic regression and decision trees, motivating our use of these as physicochemical baselines. The DGEB benchmark evaluates operonic pair classification by embedding each sequence independently with a pre-trained protein language model and computing pairwise cosine similarity. In contrast, our Siamese MLP learns a classifier over the fused embedding space, which is theoretically better motivated for binary classification, as cosine similarity can yield meaningless scores depending on the regularization of the embedding model. While protein language model embeddings substantially outperform physicochemical features in ROC-AUC, a learned Siamese MLP head does not significantly improve over unsupervised cosine similarity in Average Precision, suggesting that the geometry of the embedding space already captures the functional relationships needed for this task. Nonetheless, our Siamese MLP achieves a ROC-AUC of 0.71, competitive with state-of-the-art models on the DGEB leaderboard. These findings indicate that protein language model embeddings are a viable, scalable foundation for operonic pair classification across diverse microbial genomes, with implications for automated genome annotation, regulatory network reconstruction, and characterization of organisms lacking experimental operon annotations.
链接:https://arxiv.org/pdf/2605.11022
AI 深度解读
针对微生物操纵子推理中蛋白质序列与基因组背景信息存在冲突的难题,研究提出了 MicroFuse 框架。该框架整合了结构感知的 ProstT5 蛋白质嵌入与 Bacformer 基因组上下文嵌入,通过四专家软混合专家(MoE)模块及跨模态对比对齐实现融合。研究构建了包含 10 万对骨架的 OG-Operon100K 基准数据集,并在其中定义了包含序列冲突的‘困难子集’进行测试。实验结果显示,MicroFuse 在困难子集上的 AUROC 达到 0.6760,显著优于 Concat MLP(0.6565)及单模态模型(均低于 0.572),证明了显式建模‘一致性与冲突’在解决蛋白质身份误导时的关键作用。路由分析表明,‘冲突专家’权重最高(0.393),验证了该设计在解决水平转移和旁系同源导致的证据竞争中的有效性。此外,该框架在跨骨架操纵子类似物检索任务中表现优异,表明其学习到的特征空间能够捕捉可复用的基因邻域模式,为在无参考操纵子库的情况下优先排序生物合成模块提供了有效工具。
中文摘要
摘要:预测微生物操纵子共成员关系需要整合两种互补的生物学信号:蛋白质尺度的分子身份与基因组背景的组织结构。尽管近期的生物学基础模型能够独立提供这两种视图的强有力表征,但简单拼接这些模态会忽略一个关键的生物学特性——当相邻基因构成连贯的功能模块时,蛋白质身份与基因组背景可能一致;而当序列相似性具有误导性但基因组布局表明独立调控时,二者则可能冲突。我们提出了 MicroFuse,一种蛋白质到基因组的专家融合框架,该框架通过一个包含四个专家(蛋白质专家、基因组背景专家、一致专家、冲突专家)的混合专家模块(Mixture-of-Experts)以及一个学习到的软路由机制,将 ProstT5 的结构感知蛋白质表征与 Bacformer 的基因组背景表征进行整合。训练过程结合了二元交叉熵、对称跨模态 InfoNCE 对齐以及 disagreement-weighted 监督对比塑形。此外,我们构建了 OG-Operon100K,这是一个基于 OMG 宏基因组语料库的包含 10 万对操纵子骨架级别的基准数据集,并采用了具有生物学依据的正负样本判定标准。在 OG-Operon100K 上,MicroFuse 在仅使用 ProstT5、仅使用 Bacformer 以及 Concat MLP 基线模型中取得了最高的 AUROC、AUPRC、mAP 和 mAR 指标。消融实验表明,跨模态对比对齐是主导成分;而在一个硬性的序列冲突子集中,MicroFuse 在蛋白质身份单独具有误导性的生物学模糊案例中取得了最大的性能提升。
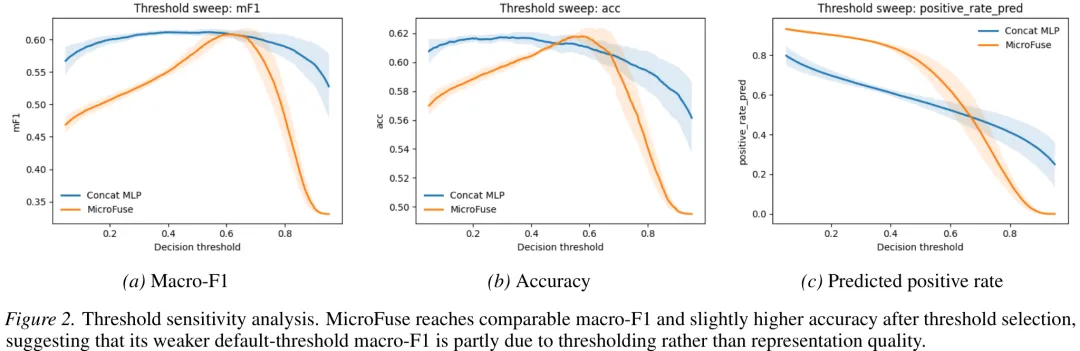
Paper Key Illustration
原文
MicroFuse: Protein-to-Genome Expert Fusion for Microbial Operon Reasoning
Abstract: Predicting microbial operon co-membership requires integrating two complementary biological signals: protein-scale molecular identity and genome-context organization. While recent biological foundation models provide powerful representations of each view independently, naive concatenation of these modalities ignores a key biological property -- protein identity and genomic context may agree when adjacent genes form a coherent functional module, or conflict when sequence similarity is misleading but genomic layout indicates independent regulation. We present MicroFuse, a protein-to-genome expert fusion framework that integrates structure-aware protein representations from ProstT5 with genome-context representations from Bacformer through a four-expert Mixture-of-Experts module (protein, genome-context, agreement, and conflict experts) with a learned soft router. Training combines binary cross-entropy with symmetric cross-modal InfoNCE alignment and disagreement-weighted supervised contrastive shaping. We further construct OG-Operon100K, a 100,000-pair scaffold-level benchmark from the OMG metagenomic corpus with biologically grounded positive and negative criteria. On OG-Operon100K, MicroFuse achieves the strongest AUROC, AUPRC, mAP, and mAR among ProstT5-only, Bacformer-only, and Concat MLP baselines. Ablations identify cross-modal contrastive alignment as the dominant component, and a hard sequence-conflict subset reveals MicroFuse's largest gains precisely in biologically ambiguous cases where protein identity alone is misleading.
链接:https://arxiv.org/pdf/2605.08815
AI 深度解读
本研究针对 BP180 蛋白(特别是其胞外胶原样重复序列 Col-15 和 NC16A 结构域)的三维结构进行了多模型预测与分子动力学模拟。研究首先利用 AlphaFold3 和 Boltz-2 对全长及截短型 BP180 单体进行预测,发现 AlphaFold3 倾向于预测松散无序结构,而 Boltz-2 则预测出紧凑球状结构,但后者将本应位于细胞外的结构域错误折叠至胞内。通过聚焦于包含 NC16A 和部分 Col-15 的胞外结构域,两种模型均成功预测出 NC16A 的螺旋束(coiled-coil)结构。随后,研究构建了 BP180 同源三聚体模型,并进行了长达 500 纳秒的膜结合分子动力学模拟。模拟结果显示,该三聚体结构在生理条件下具有整体稳定性,其中胞内球状头部和 NC16A 结构域表现出较高的机械刚性,能够有效传递细胞骨架与细胞外基质间的机械应力;而 Col-15 结构域则呈现高度柔性,表现为侧向偏转。尽管轨迹 1 中观察到胞内结构域的轻微解折叠,但三聚体并未解离,且主要运动模式集中在 Col-15 结构域的弯曲。聚类分析表明,在 1.5 Å 的 RMSD 截断下,系统收敛于单一构象,确立了该三聚体结构为 BP180 残基 1-600 的候选结构。该研究不仅修正了 AlphaFold3 对胶原样结构域的预测偏差,还揭示了 BP180 三聚体中不同结构域在力学性质上的显著差异,为理解自身免疫性大疱性类天疱疮中针对 NC16A 结构域抗体的构象表位识别提供了结构基础。
中文摘要
摘要:背景:BP180(又称胶原 XVII 或 BPAG2,即大疱性类天疱疮抗原 2)是半桥粒斑复合体中的一种 180 kDa 跨膜蛋白,已知其为大疱性类天疱疮、妊娠性类天疱疮、瘢痕性(黏膜膜)类天疱疮以及线状 IgA 大疱性疾病的主要抗原。目的:目前 BP180 的三维结构尚不清楚。本研究旨在通过机器学习与分子动力学模拟预测其合理的结构。方法:本研究利用最新的 Boltz-2 模型预测 BP180 的胞内域、跨膜域及近端胞外域(包括 NC16A 抗原区及其第一个胞外胶原结构域 Col-15 的一部分)的假定结构。我们将 BP180 计算嵌入简单的磷脂双分子层中,利用分子动力学验证该假定结构的稳定性,并分析其变构特性。结果:所提出的结构符合同源建模预期的对称性和二级结构特征。在超过三个 500 ns 的轨迹模拟中,预测的球状头部结构域表现出轻微的不稳定性,但同源三聚体整体仍保持折叠状态。假定 NC16A 结构域较为刚性,而截短的 Col-15 结构域则具有高度柔性。除初始构象外,未发现邻近的稳定构象。结论:所提出的结构为针对 BP180 的药物开发、进一步实验表征 BP180 以及提出关于导致大疱性疾病的相关表位假设提供了有用的起点。尽管扩散模型(如 Boltz-2 和 AlphaFold3)非常有用,但其结果必须谨慎评估。
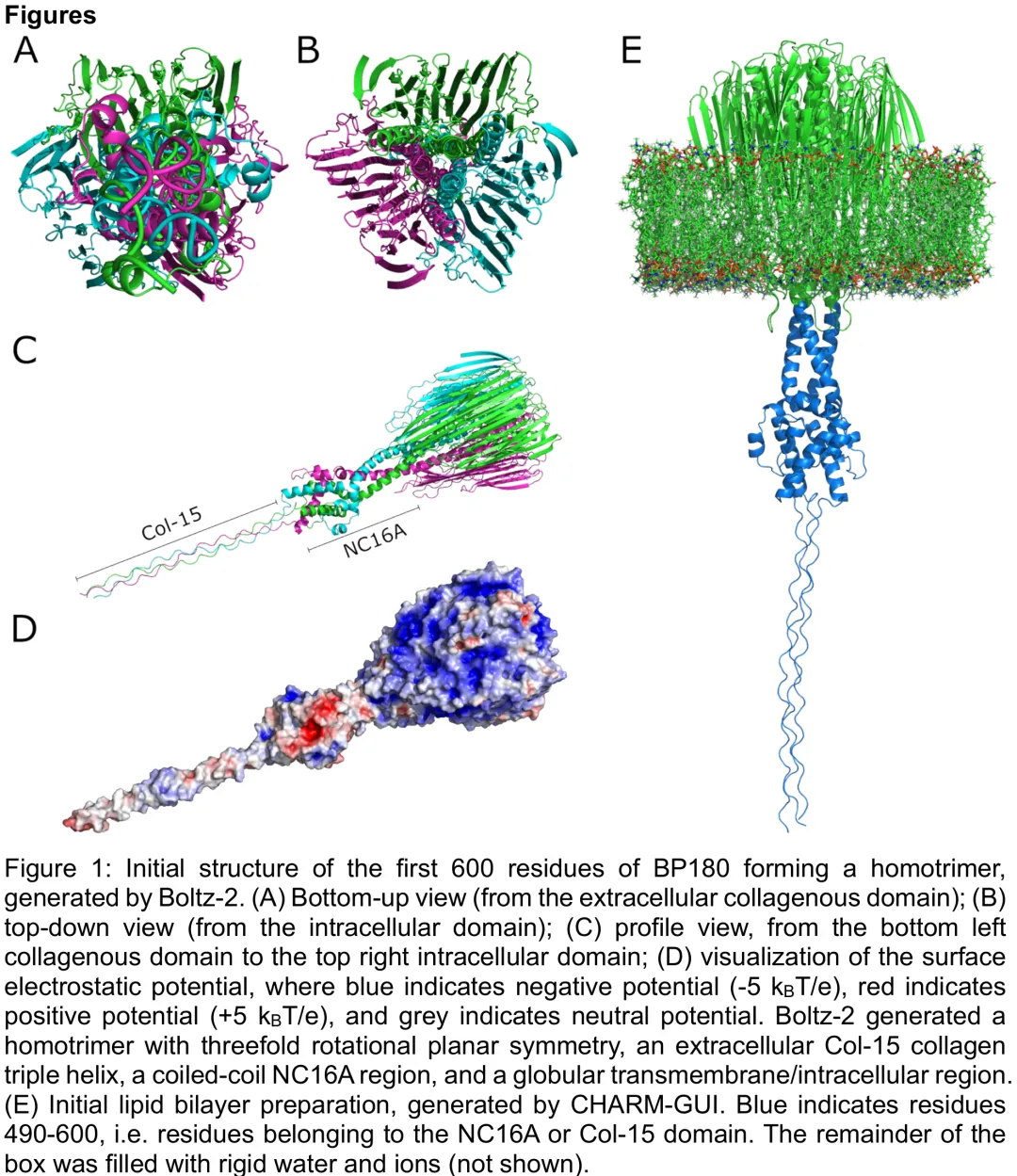
Paper Key Illustration
原文
A putative, computationally stable structure of homotrimeric BP180/collagen XVII
Abstract: Background: BP180, also known as collagen XVII and BPAG2 (bullous pemphigoid antigen 2), is a 180-kDa transmembrane protein within the hemidesmosomal plaque complex, and which is known to be a major antigen in bullous pemphigoid, gestational pemphigoid, cicatricial (mucous membrane) pemphigoid, and linear IgA bullous disease. Objective: At present, the 3D structure of BP180 is not known. The goal is to predict a reasonable structure for BP180 through machine learning and molecular dynamics. Methods: In this work, we use the recent Boltz-2 model to predict a putative structure for the intracellular, transmembrane, and proximal extracellular domains, including the NC16A antigenic region and a portion of its first extracellular collagenous domain, Col-15. We computationally embed BP180 in a simple phospholipid bilayer, demonstrate that the putative structure is stable using molecular dynamics, and analyze its allosteric properties. Results: The structures presented satisfy symmetry and secondary structure properties which are expected from homology modelling. Over three 500 ns trajectories, there is minor instability of the predicted globular head domain, but the homotrimer otherwise stays mostly folded. The putative NC16A domain is stiff, whereas the truncated Col-15 domain is highly flexible. There does not appear to be a nearby stable conformation distinct from the initial state. Conclusion: The structure presented is a useful starting point for targeting BP180 pharmacologically, for further experimental characterization of BP180, and for generating hypotheses regarding the relevant epitopes contributing to bullous disease. Diffusion models such as Boltz-2 and AlphaFold3 are useful, but their results must be evaluated carefully.
链接:https://arxiv.org/pdf/2605.08953
AI 深度解读
该研究提出了一种名为 SoftBlobGIN 的新型图神经网络架构,旨在解决酶分类(EC)任务中模型可解释性不足的问题。研究针对蛋白质接触图构建模型,核心创新在于引入了一种基于 Gumbel-softmax 的“软 blob 池化”机制,将残基划分为 K 个可学习的子结构(substructures),从而在保持图结构信息传递能力的同时,实现了非重叠子结构的发现。与传统方法不同,该模型通过单一的 MLP 头替代了复杂的 VQ 码本,显著降低了参数量并保留了可微分特性。在实验部分,研究在严重类别不平衡的 ProteinShake 数据集上进行了验证,结果显示虽然冻结的语言模型特征(如 ESM-2)是主要的性能来源,但引入图结构仍能带来小幅提升。更重要的是,该模型成功支持了事后归因方法(如 GNNExplainer 和 Integrated Gradients),能够提取出催化三联体等生物学上真实的基序,证明了其在高准确率分类与生物可解释性之间的平衡能力。
中文摘要
摘要:以 ESM-2 为代表的蛋白质语言模型能够学习丰富的残基表示,在蛋白质功能预测任务中表现优异,但其特征仍难以解释,因为结构信号与进化信号被编码在稠密的潜在空间中。我们提出了一种即插即用的框架,将 ESM-2 的表示投影到蛋白质接触图上,并应用 SoftBlobGIN——一种轻量级的图同构网络,其包含可微分的 Gumbel-softmax 子结构池化模块,用于执行结构感知的消息传递并学习用于下游预测任务的粗粒度功能子结构。在酶分类任务中,SoftBlobGIN 取得了 92.8% 的准确率和 0.898 的宏观 F1 分数。与仅对蛋白质语言模型进行事后分析不同,我们的方法能够直接生成可审计的结构化解释:利用 GNNExplainer 可恢复具有生物学意义的活性位点残基、空间局域化的功能团簇以及催化接触模式。在结合位点检测任务中,SoftBlobGIN 将基于 ESM-2 线性探测器的残基 AUROC 从 0.885 提升至 0.983,表明这些结构化解释无法仅从语言模型特征中恢复。学习到的 blob 分区通过自动将残基分组为功能子结构,提供了额外的可解释性层次;其中包含标注活性位点残基的 blob 的重要性是其他 blob 的 1.85 倍(ρ=0.339,p=0.009),且无需任何活性位点监督。我们的框架无需重新训练语言模型,仅增加约 110 万个参数,并在 ProteinShake 任务中展现出良好的泛化能力,在基因本体(Gene Ontology)预测中达到 F_max 为 0.733,在结合位点检测中达到 AUROC 为 0.969。我们将此框架定位为蛋白质语言模型的可解释结构伴侣,使其预测结果更加透明且可审计。
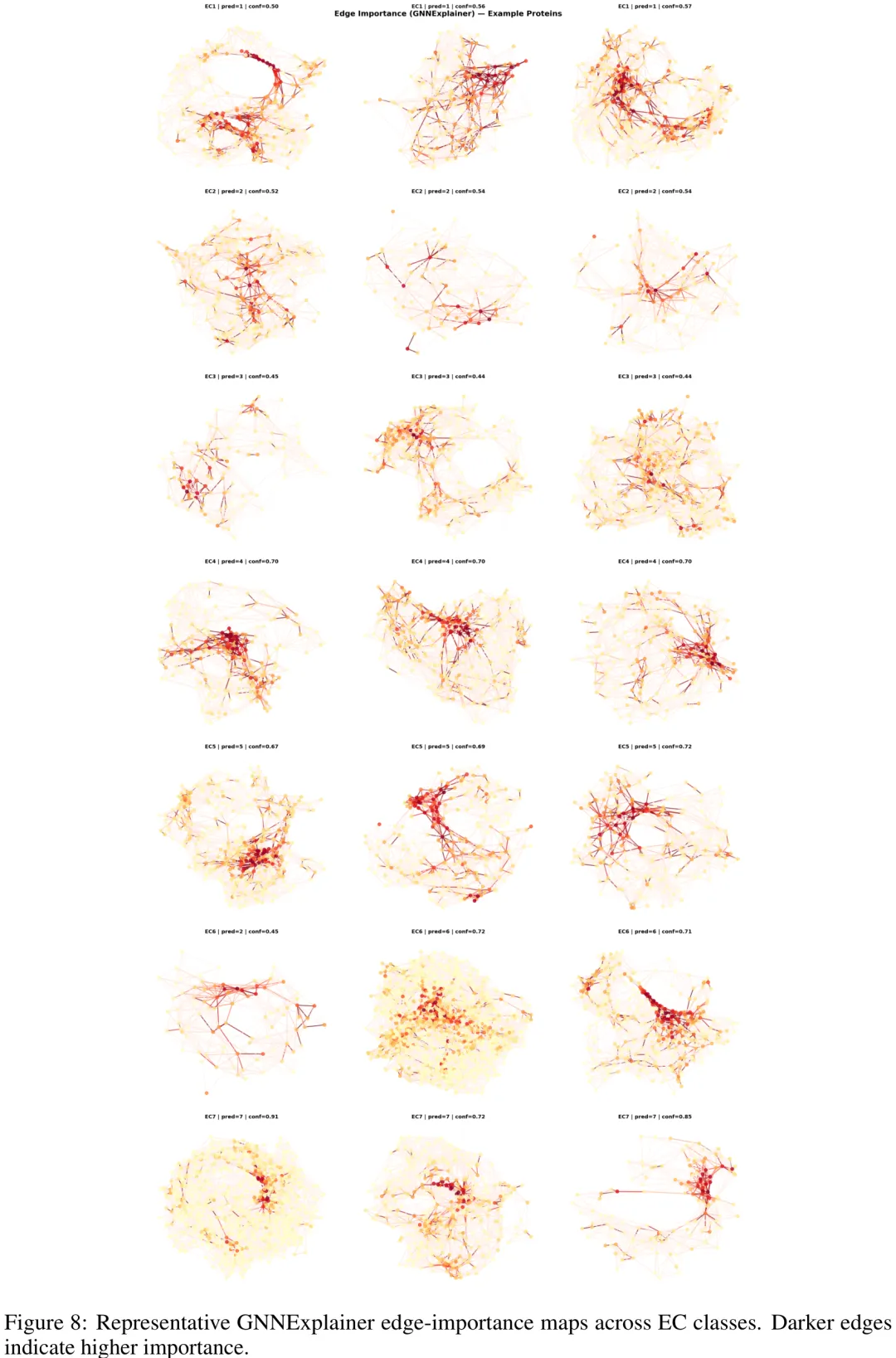
Paper Key Illustration
原文
Structural Interpretations of Protein Language Model Representations via Differentiable Graph Partitioning
Abstract: Protein language models such as ESM-2 learn rich residue representations that achieve strong performance on protein function prediction, but their features remain difficult to interpret as structural & evolutionary signals are encoded in dense latent spaces. We propose a plug-&-play framework that projects ESM-2 representations onto protein contact graphs & applies SoftBlobGIN, a lightweight Graph Isomorphism Network with differentiable Gumbel-softmax substructure pooling, to perform structure-aware message passing & learn coarse functional substructures for downstream prediction tasks. Across enzyme classification, SoftBlobGIN achieves 92.8\% accuracy & 0.898 macro-F1. Unlike post hoc analysis of protein language models alone, our method produces directly auditable structural explanations: GNNExplainer recovers biologically meaningful active-site residues, spatially localized functional clusters, & catalytic contact patterns. On binding-site detection, SoftBlobGIN improves residue AUROC from 0.885 using an ESM-2 linear probe to 0.983, indicating that these structural explanations are not recoverable from language-model features alone. Learned blob partitions provide an additional layer of interpretability by automatically grouping residues into functional substructures, with blobs containing annotated active-site residues showing 1.85× higher importance than other blobs (ρ=0.339, p=0.009), without any active-site supervision. Our framework requires no retraining of the language model, adds only ∼1.1M parameters, & generalises across ProteinShake tasks, achieving F_max of 0.733 on Gene Ontology prediction & AUROC of 0.969 on binding-site detection. We position this as an interpretable structural companion to protein language models that makes their predictions more transparent & auditable.
链接:https://arxiv.org/pdf/2605.10985
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
本文提出了一种基于电子密度(ED)的端到端分子生成方法,旨在解决传统从头设计方法在几何准确性和结合亲和力方面的不足。研究核心在于直接利用低分辨率电子密度作为连续三维场来引导原子放置,从而生成具有准确几何结构、强结合兼容性及良好类药性的新骨架分子。在方法实现上,文章首先区分了计算电子密度(CalED)与实验电子密度(ExpED)的数据来源差异,并通过傅里叶变换与滤波技术从电子密度图中采样生成低分辨率点云。为了丰富化学特征,该方法为点云中的每个点分配了基于最近邻原子相互作用的药团类型(如氢键供体/受体等)。针对分子结构的表示,文章改进了 FSMILES 片段表示法,并采用离散化三维坐标(结合相对距离、键角等)替代传统的绝对坐标,以解决自回归模型中常见的物理不一致性问题。整体架构采用 GPT 风格的自回归生成机制,模型依据给定的电子密度点云,逐个预测分子令牌,使生成的分子结构逐步填充并占据采样点云,实现了从电子密度场到具体分子结构的可解释性生成过程。
中文摘要
摘要:生成式建模领域的最新进展推动了基于结构的药物设计(SBDD)取得显著进步。现有方法通常以全酶复合体中的空结合口袋为条件进行分子生成,却忽视了填充物(配体和溶剂)等富含信息的关键组分。在此,我们利用源自填充物的低分辨率电子密度(ED)作为物理基础的先验条件,用于从头药物设计。我们考虑了两种类型的电子密度:计算所得电子密度以及来自冷冻电镜或 X 射线实验的电子密度,前者源于计算模拟,后者源于实验数据,从而支持统一的预训练与实验数据融合。与刚性的口袋表示相比,实验电子密度能够自然地捕捉构象柔性,并提供对结合环境的更忠实描述。基于此,我们提出了 EDMolGPT,这是一个仅包含解码器的自回归框架,能够从低分辨率电子密度点云生成分子。通过将生成过程建立在具有物理意义的密度信号之上,EDMolGPT 有效缓解了结构偏差,并生成具有三维构象的分子。在 101 个生物靶标上的评估验证了其有效性。项目主页:https://jiahaochen1.github.io/EDMolGPT_Page/
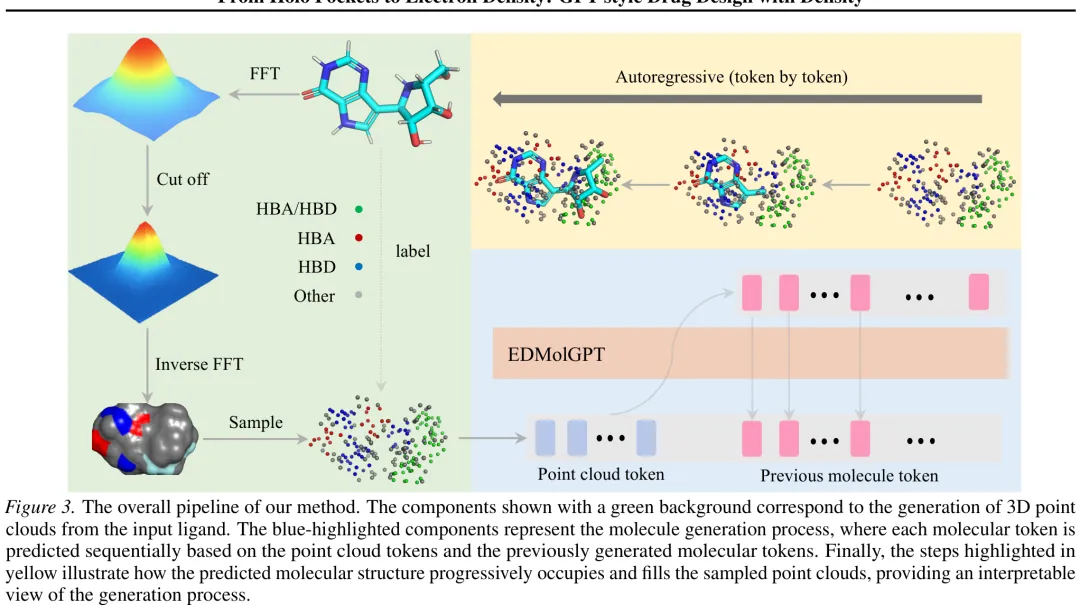
Paper Key Illustration
原文
From Holo Pockets to Electron Density: GPT-style Drug Design with Density
Abstract: Recent advances in generative modeling have enabled significant progress in structure-based drug design (SBDD). Existing methods typically condition molecule generation on empty binding pockets from holo complexes, overlooking informative components such as the filler (ligands and solvent). Here, we leverage low-resolution electron density (ED) derived from the filler as a physically grounded condition for \textit{de novo} drug design. We consider two types of ED, calculated and cryo-EM/X-ray, obtainable from computational or experimental sources, supporting unified pre-training and experimental integration. Compared with rigid pocket representations, experimental ED naturally captures conformational flexibility and provides a more faithful description of the binding environment. Based on this, we introduce EDMolGPT, a decoder-only autoregressive framework that generates molecules from low-resolution ED point clouds. By grounding generation in physically meaningful density signals, EDMolGPT mitigates structural bias and produces molecules with 3D conformations. Evaluations on 101 biological targets verify the effectiveness. Our project page: https://jiahaochen1.github.io/EDMolGPT_Page/.
链接:https://arxiv.org/pdf/2605.08767
AI 深度解读
该研究针对生物分子生成任务中效用(Utility)与多样性(Diversity)难以兼顾的问题,提出了一种名为 SGRPO 的新颖强化学习优化框架。其核心创新在于引入“超组(Supergroup)”概念,即在相同生成条件下(Condition)将多个候选样本组划分为一个超组,以隔离不同条件间的固有难度差异,确保比较的公平性。SGRPO 通过“留一法”(Leave-one-out)计算组间相对多样性优势,并基于候选样本对组多样性的贡献度进行信号重分配,从而将组级多样性指标有效转化为个体样本的奖励信号。最终,该方法结合效用奖励与重分配的多样性奖励,利用带 KL 散度正则化的截断 PPO 目标函数进行策略更新。实验结果表明,SGRPO 能够显著扩展效用 - 多样性帕累托前沿,在去噪小分子设计、口袋结合小分子设计以及从头蛋白质设计等多个生物分子生成场景中,均实现了优于预训练生成器、标准 GRPO 及记忆辅助 GRPO 的性能表现,证明了该方法在提升生成模型综合性能方面的有效性。
中文摘要
摘要:生物分子生成器常通过引入奖励反馈来提升特定任务的效用,但单纯追求效用往往会导致生成结果集中于狭窄的候选集族。由于样本多样性属于集合级属性,维持多样性颇具挑战。我们提出了超组相对策略优化(Supergroup Relative Policy Optimization, SGRPO),这是一种灵活的 GRPO 风格框架,能够直接从集合级多样性构建奖励。针对每个条件,SGRPO 采样一组候选集(超组),在相同条件下比较其多样性,并通过留一法多样性贡献将群体多样性奖励重新分配至各个 rollout,随后将其与 rollout 级效用相结合。该设计使 SGRPO 与特定生成器、效用奖励或多样性度量解耦,并支持采用不同的 GRPO 风格方法进行实例化。我们在从头小分子设计、基于口袋的小分子设计以及从头蛋白质设计任务上评估了 SGRPO,并在自回归和离散扩散生成器上分别使用 GRPO 和 Coupled-GRPO 进行实例化。在多次解码轮次中,SGRPO 扩展了效用 - 多样性帕累托前沿,并在适用情况下相对于预训练生成器、GRPO 及记忆辅助 GRPO 取得了最优的前沿级指标。进一步分析表明,直接的集合级多样性奖励在小规模超组下依然有效,并有助于在预训练后保持更广泛的生成分布覆盖。代码已公开于 https://github.com/IDEA-XL/SGRPO。
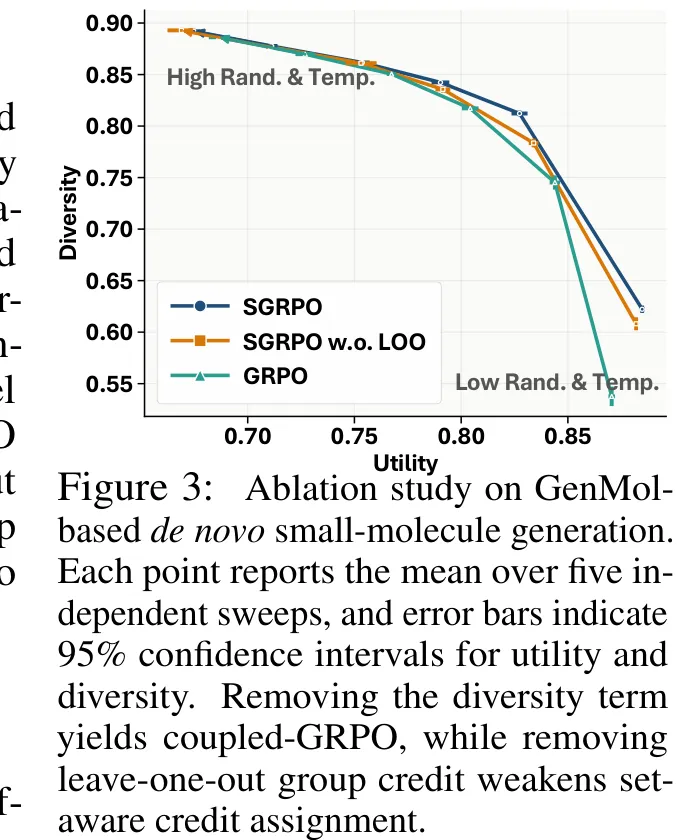
Paper Key Illustration
原文
Pushing Biomolecular Utility-Diversity Frontiers with Supergroup Relative Policy Optimization
Abstract: Biomolecular generators are often adapted with reward feedback to improve task-specific utility, but pushing utility alone can concentrate generation on a narrow family of candidates. Maintaining diversity is difficult because sample diversity is a set-level property. We introduce Supergroup Relative Policy Optimization (SGRPO), a flexible GRPO-style framework that directly constructs rewards from set-level diversity. For each condition, SGRPO samples a supergroup of candidate sets, compares their diversity under the same condition, and redistributes the group diversity reward to individual rollouts through leave-one-out diversity contributions before combining it with rollout-level utility. This design decouples SGRPO from a particular generator, utility reward, or diversity metric, and allows instantiation with different GRPO-style approaches. We evaluate SGRPO on de novo small-molecule design, pocket-based small-molecule design, and de novo protein design, instantiating it with both GRPO and Coupled-GRPO across autoregressive and discrete diffusion generators. Across decoding sweeps, SGRPO expands the utility-diversity Pareto frontier and achieves the best frontier-level metrics relative to pretrained generators, GRPO, and memory-assisted GRPO when applicable. Our analyses further show that direct set-level diversity rewards remain effective with small groups and help preserve broader generation-distribution coverage during post-training. The code is available at https://github.com/IDEA-XL/SGRPO.
链接:https://arxiv.org/pdf/2605.08659
AI 深度解读
该研究提出了一种基于分数(Score)的统计方法,旨在从扩散模型生成的轨迹中解耦系统的慢速模式(慢变量)与快速模式(噪声)。核心方法利用标准扩散过程的理论框架,通过模拟正态化扩散过程并估计自协方差矩阵,提取慢速模式。研究定义了慢速模式的判别标准:其对应的特征值必须显著高于由理论推导出的“操作噪声基底”(Operational noise floor),且在一维投影上表现出多峰性(非单峰分布)。关键结果包括:1)在合成高斯混合模型实验中,该方法提取的慢速模式数量与互信息(MI)指标高度一致,能够准确捕捉势垒高度对模式稳定性的影响;2)该方法不仅适用于已知分量的合成数据,还能通过蒙特卡洛校准适应预训练生成模型的复杂偏差;3)该方法成功区分了数据的“分散度”(熵)与“碎片化”(多模态结构),证明了其在识别真实物理或化学系统中的慢速动力学方面的有效性。
中文摘要
摘要:模式分离(即分布如何锐利地碎裂为势垒分隔的簇)是密度的一种基本几何属性,在高维空间中难以量化。它在结构上与离散度截然不同,但现有工具均存在不足:微分熵随扩散程度增加而上升,无论是否存在碎裂;主成分分析(PCA)按方差对方向进行排序,而忽略势垒;互信息则需要通常不具备的混合分解。我们通过一种内在于密度的单一随机过程来衡量模式分离:即具有f为平稳分布且标量扩散系数为常数的唯一可逆扩散过程。我们从其自协方差矩阵中提取两个读出量:平方自相关和(SSA),这是一种标量势垒敏感度量;以及主导自相关方向(DA),即按亚稳态性而非方差排序的线性投影。在诸高斯零假设下,我们推导了经验自协方差的闭式谱,该谱推广了马尔琴科 - 帕斯图(Marchenko-Pastur)分布,并给出了一个解析上界,用于选择读取 DA 的滞后时间。这两个读出量仅使用样本和得分函数,并通过 Tweedie 恒等式利用预训练的基于得分的生成模型扩展至高维空间。我们将该框架应用于三个场景:(i) 合成高斯混合分布,其中 SSA 追踪互信息;(ii) SDXL 文生图生成,其中 SSA 和 DA 捕捉了熵和 PCA 所遗漏的结构;(iii) 丙氨酸二肽的分子动力学,其中 DA 仅凭静态样本就恢复了已知的慢速主链二面角。

Paper Key Illustration
原文
Measuring and Decomposing Mode Separation via the Canonical Diffusion
Abstract: Mode separation, namely how sharply a distribution fragments into barrier-separated clusters, is a fundamental geometric property of densities, difficult to quantify in high dimensions. It is structurally distinct from dispersion, yet existing tools fall short: differential entropy rises with spread regardless of fragmentation, PCA orders directions by variance regardless of barriers, and mutual information requires a mixture decomposition one usually does not have. We measure mode separation through a single stochastic process intrinsic to the density: a unique reversible diffusion with f as its stationary distribution and constant scalar diffusion coefficient. We extract two readouts from its autocovariance matrix: SSA (Sum of Squared Autocorrelations), a scalar barrier-sensitive measure; and DA (Dominant Autocorrelation directions), linear projections ordered by metastability rather than variance. Under an isotropic-Gaussian null, we derive a closed-form spectrum for the empirical autocovariance that generalizes Marchenko--Pastur, with an analytic upper edge that selects the lag at which DA is read off. Both readouts use only samples and a score function, scaling to high dimensions through pretrained score-based generative models via Tweedie's identity. We apply our framework to three settings: (i) synthetic Gaussian mixtures, where SSA tracks mutual information; (ii) SDXL text-to-image generations, where SSA and DA capture structure that entropy and PCA miss; and (iii) molecular dynamics of alanine dipeptide, where DA recovers the known slow backbone dihedrals from static samples alone.
链接:https://arxiv.org/pdf/2605.08777
AI 深度解读
本研究提出了一种名为‘传播场(Propagation Field)’的几何子理论,旨在解决深度学习模型中端点行为与内部传播机制解耦的问题。研究指出,仅凭端点监督(Endpoint Supervision)无法唯一确定模型的传播规律,即存在‘端点等价但传播律不等价’的现象。为此,论文构建了结合传播一致性、判别性及防坍塌约束的有效场感知学习框架。实验表明,在受控系统(如教师 - 学生流)和偏微分方程(PDE)外推任务中,引入场感知目标能显著降低轨迹误差并提升外推精度,证明端点拟合并不等同于学习底层传播律。在真实多路径迁移任务中,场感知目标的效果具有任务依赖性:在 Tiny-ImageNet 上能同时提升准确率、未见路径泛化及校准能力;但在 CIFAR-100 等任务中,若缺乏任务对齐约束,单纯追求低路径敏感性会导致模型坍塌(准确率大幅下降)。此外,研究揭示了功能保留(Function Retention)与场保留(Field Retention)的互补性:在持续学习场景中,单独使用场保留或功能保留均存在局限,而结合两者(如 DER++ 与 FPR 结合)可在保持端点性能的同时有效维持场几何结构,从而克服单一目标的不足。
中文摘要
摘要:现代深度学习将神经网络主要视为从输入到输出的端点函数。受物理学中从力到几何的转变启发,我们提出是否应通过其内部传播的几何结构来理解网络。我们将神经传播场定义为跨层深度的隐藏状态轨迹与局部雅可比算子的集合。端点损失仅约束该场的边界行为,使其内部几何结构欠定。我们表明,端点等效的模型在轨迹和雅可比结构上可能存在数量级的差异,并引入了可观测的场指标,如路径敏感性、求解器一致性及轨迹/雅可比保留度。在受控的教师流和偏微分方程系统中,端点拟合无法恢复底层的传播规律。在真实的多路径任务中,当与观测结构对齐时,感知场的目标函数能提升未见路径的泛化能力、分布外(OOD)鲁棒性及校准性能,但若过度约束则可能导致性能崩塌。在持续学习中,场保持正则化与回放及蒸馏相辅相成:在 Split CIFAR-100 数据集上,结合场保持的 DER++ 方法在平均准确率、反向迁移能力及场保留指标上均有所提升。这些结果确立了传播场质量作为神经网络除端点性能外可测量且可训练的属性。

Paper Key Illustration
原文
The Propagation Field: A Geometric Substrate Theory of Deep Learning
Abstract: Modern deep learning treats neural networks primarily as endpoint functions from inputs to outputs. Inspired by the shift from force to geometry in physics, we ask whether a network should instead be understood through the geometry of its internal propagation. We define a neural propagation field as the collection of hidden-state trajectories and local Jacobian operators across depth. Endpoint losses constrain only the boundary behavior of this field, leaving its interior geometry underdetermined. We show that endpoint-equivalent models can differ by orders of magnitude in trajectory and Jacobian structure, and introduce observable field metrics such as path sensitivity, solver consistency, and trajectory/Jacobian retention. In controlled teacher-flow and PDE systems, endpoint fitting fails to recover the underlying propagation law. In real multi-path tasks, field-aware objectives improve unseen-path generalization, OOD robustness, and calibration when aligned with the observation structure, but can collapse when over-constrained. In continual learning, field-preservation regularization complements replay and distillation: on Split CIFAR-100, DER++ with field preservation improves average accuracy, backward transfer, and field-retention metrics. These results identify propagation-field quality as a measurable and trainable property of neural networks beyond endpoint performance.
链接:https://arxiv.org/pdf/2605.08529
AI 深度解读
本研究旨在评估生成式人工智能(AI)在优化植物基汉堡配方方面的潜力,重点考察其能否在保持或提升消费者接受度的同时实现营养与可持续性目标。研究采用双压缩测试结合纹理剖面分析(TPA),对六种不同配方的汉堡(包括两款 AI 优化的“美味”汉堡、两款“可持续”汉堡、一款“营养”汉堡及传统“巨无霸”)进行了机械力学特性测试,并收集了 101 名参与者的感官评价数据。通过对应分析、线性相关性及混合效应模型,研究发现:两款 AI 优化的“美味”汉堡在整体喜好度上显著优于传统“巨无霸”,证明了 AI 算法能成功超越现有商业产品的适口性;然而,以营养优化为目标的汉堡在喜好度、风味和口感上得分最低,表明营养强化往往以牺牲消费者接受度为代价;此外,完全由植物蛋白制成的汉堡在硬度、多汁感和肉感上明显低于动物基汉堡,但软度和纤维感较高;而采用“动物肉 - 蘑菇”混合配方的“可持续”汉堡 2 在多数感官属性上接近纯动物基汉堡,说明部分替代动物蛋白并不会显著降低消费者的口感感知。
中文摘要
摘要:质地影响我们对食物的感知和喜好,然而,机械测量与质地感官感知之间的明确联系仍难以捉摸。本文结合 101 名参与者的盲测感官数据与六种汉堡的机械质地剖面分析,识别出驱动消费者感知和喜好的质地特征。我们比较了五种由人工智能生成的汉堡,包括动物源性、植物源性、蘑菇源性以及动物 - 蘑菇混合肉饼,并与经典的大吉士汉堡进行对比。研究得出三个主要发现:首先,动物源性汉堡占据一个独特且连贯的感官 - 机械特征区域,其属性包括坚实、多脂且不易散开。其次,蘑菇源性和植物源性汉堡在蛋白质依赖性方面偏离该区域:蘑菇源性汉堡与弹性、胶质感相关,而植物源性汉堡则与干燥、脆硬和易碎相关。然而,动物 - 蘑菇混合汉堡的感官特征与完全动物源性汉堡相当。第三,回弹性成为感知肉感和感官质地最强的机械相关指标,而刚性和硬度与消费者感知之间无统计学显著关联。质地独立于风味预测整体喜好:质地喜好每提高 1 分,整体喜好提高 0.28 分。在所有感官属性中,肉感是预测质地喜好的主导因素。这些发现将回弹性确定为质地工程的一个有前景的目标,并确立了质地作为可持续替代蛋白关键设计目标的重要性。

Paper Key Illustration
原文
Texture Independently Drives Liking in AI-Generated Alternative Protein Burgers
Abstract: Texture shapes how we perceive and like food, yet clear links between mechanical measurements and sensory perception of texture remain elusive. Here we combine sensory data from a blind tasting with 101 participants with mechanical texture profile analysis across six burgers to identify the textural features that drive consumer perception and liking. We compare five burgers -- generated with artificial intelligence -- with animal-based, plant-based, mushroom-based, and hybrid animal-mushroom patties, and the classical Big\,Mac. Three main findings emerge: First, animal-based burgers occupy a distinctive and coherent sensory-mechanical region associated with attributes such as firm, fatty, and holds together. Second, mushroom- and plant-based burgers deviate from this region in protein-dependent ways: mushroom-based burgers associate with springy and gummy textures, while plant-based burgers associate with dry, brittle, and crumbly textures. Hybrid animal-mushroom burgers, however, maintain sensory profiles comparable to fully animal-based burgers. Third, resilience emerges as the strongest mechanical correlate of perceived meatiness and sensory texture, while stiffness and hardness show no statistically significant association with consumer perception. Texture independently predicts overall liking alongside flavor: increasing texture liking by one point increases overall liking by 0.28. Among all sensory attributes, meatiness is the dominant predictor of texture liking. These findings identify resilience as a promising target for texture engineering and establish texture as a critical design objective for sustainable alternative proteins.
链接:https://arxiv.org/pdf/2605.08365
Subscribe to arXiv's Daily Preprint Notifications
