 夜雨聆风
夜雨聆风2026年5月13日 | AI Agent狂飙、大模型融资破纪录、技术架构加速迭代
DeepSeek启动500亿首轮融资,创始人自掏200亿押注AGI
DeepSeek这次玩得够大。据多个信息源确认,这家国产AI公司正在推进一轮500亿人民币的融资——如果落地,将直接刷新中国AI公司的单轮融资纪录。
更值得关注的是创始人梁文锋的态度:知情人士透露,他本人将在本轮出资200亿。
真金白银往里砸,而不是讲PPT圈钱,这信号够明确——梁文锋不是在做生意,是在赌AGI这个方向。
500亿砸下去能做什么?算力储备、挖顶尖人才、出海抢市场。
DeepSeek已经启动识图功能内测,产品线持续扩张,目标已经不是“中国最好的AI公司”,而是全球第一梯队。
参考:https://www.aitop100.cn/ai-daily-2026-05-09
同一天三家厂商发新模型,国产AI进入"周更"节奏

5月9日,蚂蚁百灵、百度、阶跃星辰三家厂商同日发布新模型——产品迭代速度已经进入“周更”模式。
同一天,DeepSeek在资本和产品两端同时推进:融资消息流出同时,向用户开放图像识别功能内测。
左手要钱,右手扩能力,节奏卡得很紧。
基础设施层面也有动作:中国移动上线大模型集成平台,汇聚超过300款模型供企业调用。
说白了就是把AI能力打包成“外卖”,让不懂技术的公司也能快速用上。
另外,红果短剧下架了超过万部劣质AI生成短剧。
AI内容泛滥的副作用开始显现,内容治理不再是说说而已。
参考:https://www.kaggle.com/datasets/sethelm/ai-llm-intelligence-may-2026-edition
62%的企业已经部署AI Agent,后来者窗口期正在收窄
最新数据显示,截至2026年5月,已有62%的企业在业务中部署了AI Agent。
这个比例比去年翻了几倍,说明AI应用已经从“要不要试”进入“必须上线”阶段。
36氪对30个顶级AI Agent产品做了深度分析,梳理出三大核心趋势:技术架构升级、应用场景拓宽、商业模式成熟。
先行者已经吃到效率提升和成本优化的红利,后来者面临的追赶压力只会越来越大。
对普通员工意味着什么?你的同事可能已经在用AI Agent处理客户咨询、生成报告、自动审核合同了,而你还在手动复制粘贴。
参考:https://futureagi.com/blog/best-llms-may-2026
CB Insights发布69页AI Agent报告,预测六大趋势
美国风投数据机构CB Insights最近出了一份69页的《AI Agent圣经》,被称为目前最权威的Agent领域分析。
报告核心就两点:AI Agent正在加速渗透企业工作流程,行业专属应用正在快速落地。
翻译成人话就是——通用AI讲故事的时代过去了,现在大家都在做“专精特新”的AI。
报告还独家披露了头部Agent初创公司的营收梯度分布。
简单说,赚钱的和烧钱的已经拉开差距了,第一梯队和第二梯队的生存状态完全不同。
多家投资机构已经把这份报告列为评估AI Agent赛道的必读材料。
参考:https://lmmarketcap.com/zh/llm-updates
2026年技术三大趋势:AI从"聊天"变"做事",程序员能力模型重构
2026年5月,技术圈迎来阶段性复盘。三个核心趋势值得关注:
趋势一:AI从问答工具变成干活工具。 Agent自动化、超长上下文、低幻觉——这些技术特性让企业真正敢把AI用到生产环节,而不是停留在demo演示。
趋势二:程序员的竞争力重构。 纯写代码已经被判“死刑”,未来的核心竞争力是架构设计、AI调度能力、工程优化。说白了,以前比谁代码写得好,现在比谁能让AI把活干好。
趋势三:国产技术全面崛起。 大模型、开源项目、资本热度,国产在多个维度已经追平甚至超越海外。这个变化来得比预期快。
参考:https://www.36kr.com/p/3518938465770373
大模型竞争升级:从堆参数到拼落地
2026年的AI大模型行业,竞争逻辑变了。
之前比的是谁家模型参数大、谁家融资多。现在大家比的维度转向实际场景落地效果和性价比。
堆算力的故事不好讲了,客户要的是能解决具体问题、费用还划算的方案。
海内外巨头和创业公司都在密集发布新模型,推理能力、多模态交互、场景适配成为迭代重点。
行业正在从野蛮生长转向精细化竞争。
对企业的启示是:选模型不再只看榜单分数,要看和自己的业务场景匹配度。
参考:https://www.neican.ai/morningnews/2026-05-13-ai-2026-05-13-/
2026年5月大模型横评:四强争霸,DeepSeek V4杀入战局
FutureAGI在5月13日发布了月度大模型评测,对比当前四款主流模型:GPT-5.5、Claude Opus 4.7、Gemini 3.1 Pro和DeepSeek V4。
评测维度包括编码能力、Agent表现、多模态性能、成本控制和开源权重开放程度。
一个有意思的现象:模型迭代速度已经快到“新版本每周发布”,评测报告刚发出来可能就过时了。
GPT、Claude、Gemini三强争霸的同时,DeepSeek V4作为开源选手也杀入战局,给开发者和企业提供了更多选择。
闭源三强谁更强?开源模型能否凭借成本优势突围?
这场战争还在继续。
参考:https://www.aitop100.cn/daily-ai-news
"微回合"架构:让AI对话从打字聊天变成实时协作
Thinking Machines最近推出“微回合”实时交互架构,被视为Agent时代交互方式变革的标志性产品。
传统AI对话是什么模式?用户输入一段文字,AI回复,用户再输入——像微信聊天,一条一条来,中间有明显等待间隙。
微回合架构的核心思路是把这种离散交互变成连续协作。
多模态感知模块实时接收文字、语音、图像信息,与推理引擎深度耦合,AI能在对话过程中主动修正、补充、延续内容。
想象一下:你和AI开视频会议,它实时理解你的表情、语气、在白板上画的内容,然后在你停顿的间隙主动补充你没想到的方案——这才是真正的“协作智能体”。
微回合架构提供了一条技术实现路径。
参考:https://x.com/elonmusk/status/2054300779713007966#m https://x.com/xAI https://x.com/elonmusk https://x.com/ArtificialAnlys/status/2054234919887573292#m
首个AI大模型月度快照数据集上线,追踪100+模型生态
Kaggle平台最近上线了“AI LLM Intelligence”数据集的5月版本——这是该系列的首个版本。
数据集整合了三类来源:通过HuggingFace API获取下载量最高的80个开源模型;人工整理20个主流闭源模型的定价信息;GitHub Search API收录的100个头部AI工具。
这个数据集有什么用?对研究者来说,可以对比开源和闭源模型的生态分布、成本结构和社区活跃度;对开发者来说,可以作为选型的参考基准;对投资人来说,可以看到哪些模型真正被大家用起来。
一句话总结:给AI大模型生态做了一次系统性“体检”。
参考:https://x.com/harryjsisson/status/2054129873593999597#m
语音Agent的真实水平:最强模型也只能完成一半任务
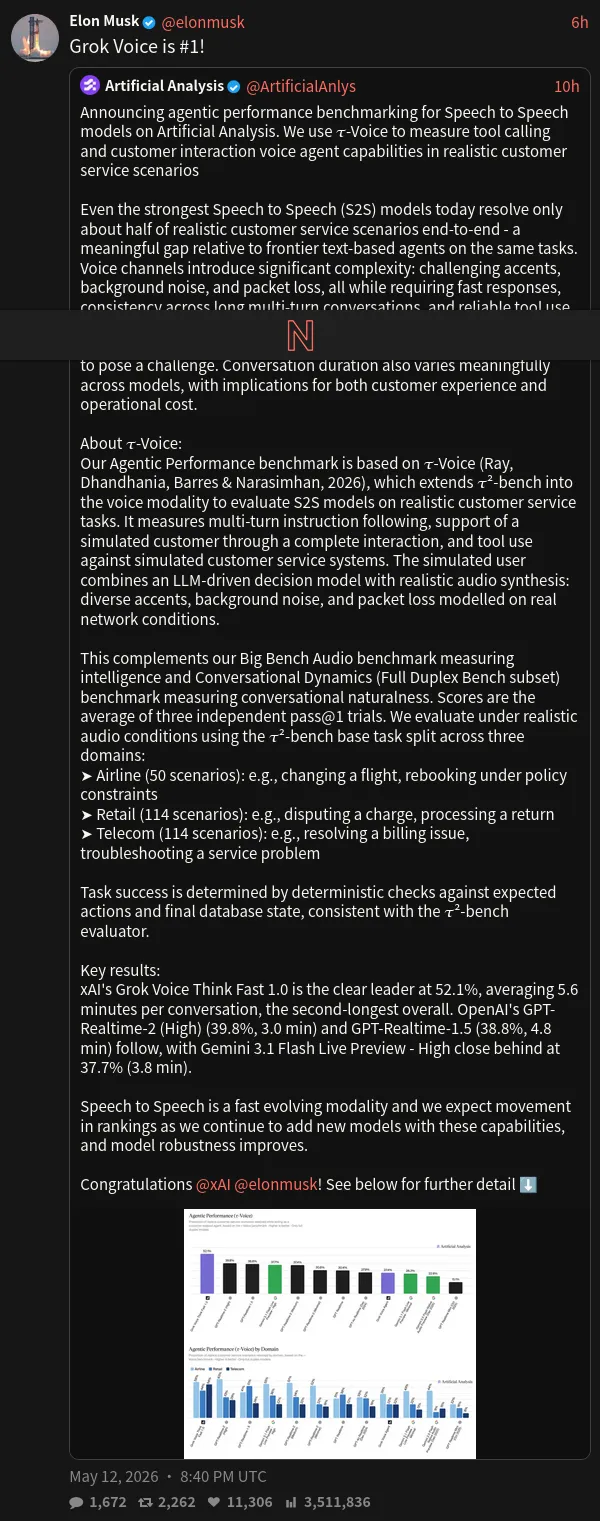
人工智能分析机构Artificial Analysis最近推出了语音模型Agent能力基准测试,用“τ-Voice”指标评估语音代理在真实客服场景下的表现。
结果有点打击信心:即便最强的语音到语音模型,在真实客服场景下也只能完成约一半的端到端任务。
相比之下,前沿文本代理在相同任务上的表现要稳定得多。
语音通道带来的挑战是独特的:方言口音、背景噪音、网络丢包,同时还要求快速响应、保持长对话一致性、可靠调用工具。
实验室里的漂亮测试数据,一到真实环境就原形毕露。
不同音频条件下性能差异明显。安静环境下部分模型表现优异,但嘈杂的真实场景仍是所有玩家的持续挑战。
参考:https://x.com/AndrewYNg/status/2054236506756370865#m
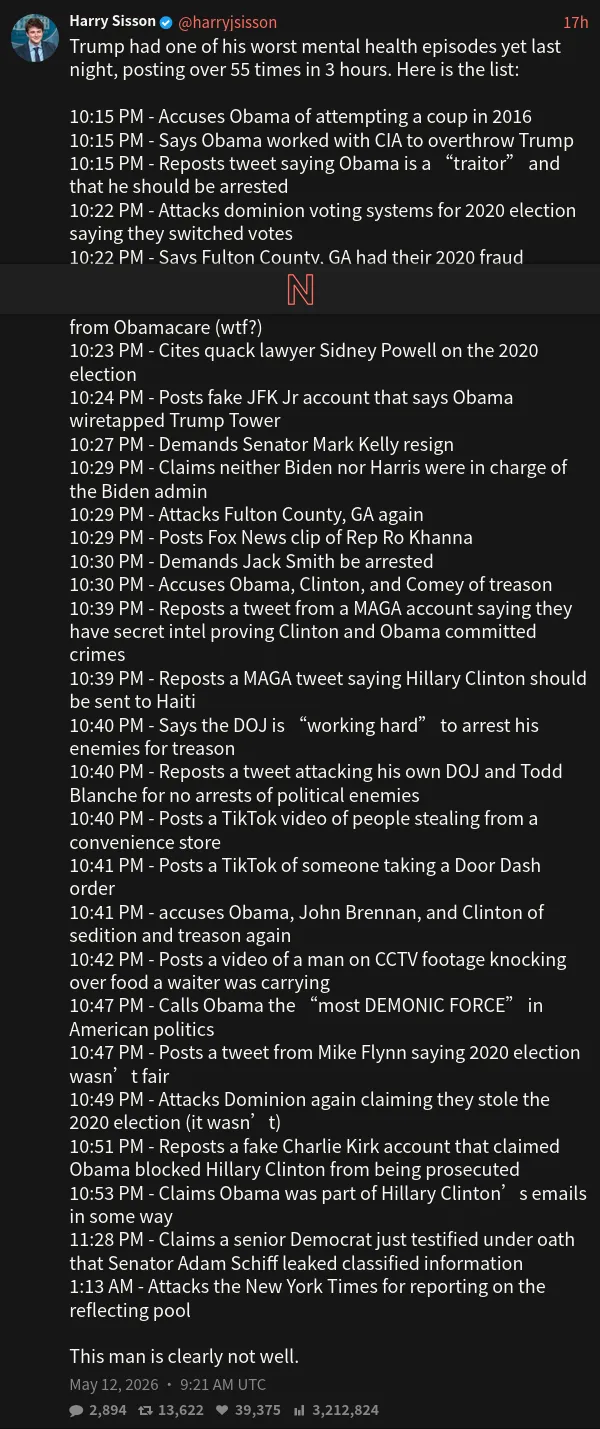
资深工程师反驳AI失业潮叙事:这说法不负责任
一位资深软件工程师最近撰文反驳“AI将导致大规模失业”的流行叙事。
他认为这种说法不负责任,且具有误导性。
核心论点:软件工程是受AI工具影响最大的领域,但软件工程师的招聘需求依然保持强劲。
AI带来的净就业创造大于就业破坏,与此前各次技术浪潮的情况一致。
目前美国失业率仍维持在健康的4.3%。
他同时分析了“AI失业潮”叙事流行的原因:前沿AI实验室有动机把技术描绘得足够强大以证明收费合理;企业有动机把裁员归因于AI以彰显技术能力;疫情期间资本充裕时期存在过度招聘,实际裁员与AI关联有限。
三个理由都指向同一个事实:AI失业叙事是多方合谋生产出来的焦虑,而不是客观现实的全貌。
参考:https://x.com/kyleichan/status/2054256038375784821#m https://x.com/jietang/status/2054222017566855508#m
Gemma 4推理加速横评:MTP与DFlash谁能更快
一项针对Gemma 4模型的推理加速技术横评在单卡H100 80GB上进行,对比MTP(多Token预测)与DFlash在推理任务中的加速效果。
结果很有趣。在Gemma 4 31B稠密模型上,MTP实现3.11倍加速,DFlash实现3.03倍加速,两者差距很小。
但在Gemma 4 26B-A4B MoE模型上,DFlash反而以1.73倍加速超越MTP的1.49倍。
不同工作负载类型也有差异。编程、数学、科学类任务因为token预测模式更具规律性,加速效果更明显。
简单总结:加速技术不是万能钥匙,模型架构不同,最优选择也不同。
选型时不能只看加速倍数,要看自己的业务场景。
参考:https://www.reddit.com/r/MachineLearning/comments/1tb8k3n/steam_recommender_using_similarity_undergraduate/ https://nextsteamgame.com/ https://github.com/BakedSoups/NextSteamGame
