 夜雨聆风
夜雨聆风学习一个陌生领域,第一步应该是要构建起这个领域的知识地图。
很多朋友,包括我自己在内,第一次想要深入学习AI这个领域的时候,其实会被一大堆概念所困扰。
比如ChatGPT、gpt-5.5、Claude、claude opus4.6、Gemini、gemini-3.1pro、DeepSeek、Llama、Cursor、Claude Code、Agent、RAG、向量数据库、LangChain、n8n、提示词工程、上下文工程。
因此,建立一个理解框架来让这些概念对号入座,其实是非常有必要的。下面是我和 AI 学习讨论之后所总结出来的一张理解框架图。将这些概念分成三层框架。
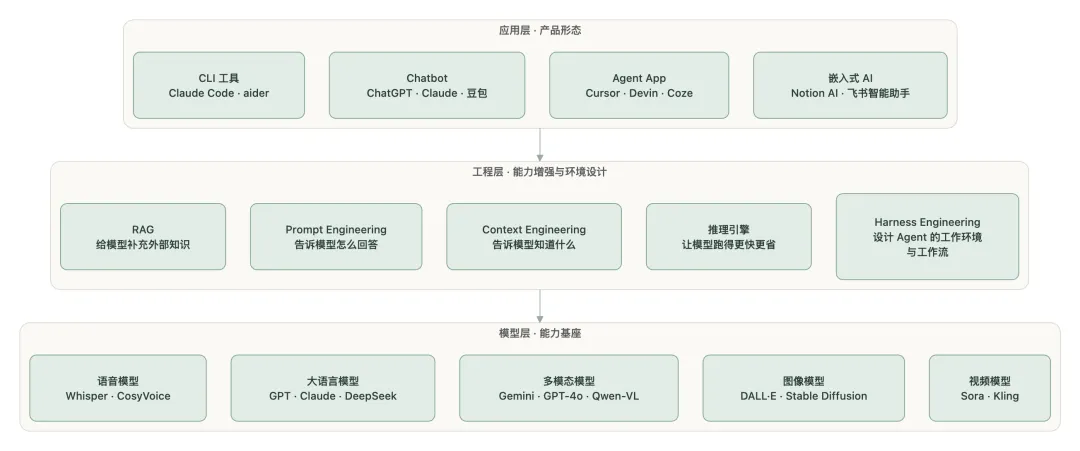
模型层:能力基座
这是 AI 的「大脑」,一切能力的源头。
1.1 大语言模型(LLM)
| 概念 | 解释 |
|---|---|
| Transformer | 2017 年 Google 提出的神经网络架构,几乎所有现代大模型的基础。核心是「注意力机制」 |
| Attention(注意力机制) | 让模型能「关注」输入中最重要的部分。例如「我把杯子放在桌上,它很重」→ 模型知道「它」= 杯子 |
| Token(词元) | 模型不直接看文字,而是把文本拆成 token。1 个汉字 ≈ 1-2 token,1 个英文单词 ≈ 1-3 token |
| 参数(Parameters) | 模型的「脑容量」。7B = 70亿参数,参数越多通常越聪明,但也越贵越慢 |
| 预训练(Pre-training) | 用海量文本(几乎整个互联网)训练模型学习语言规律、常识、推理。成本极高:数百万到上亿美元 |
| 微调(Fine-tuning) | 在通用模型基础上,用特定领域数据再训练,适配具体任务(如医疗、法律) |
| RLHF(人类反馈强化学习) | 让人类给模型回答打分,训练模型产生更好、更安全的回答。ChatGPT 的关键突破之一 |
| 幻觉(Hallucination) | 模型一本正经地胡说八道——生成看似合理但事实错误的内容。LLM 最大的已知缺陷 |
1.2 其他模型类型
| 模型类型 | 代表 | 做什么 |
|---|---|---|
| 多模态模型 | Gemini · GPT-4o · Qwen-VL | 同时理解文字 + 图片 + 音频 + 视频 |
| 语音模型 | Whisper · CosyVoice | 语音识别(听)和语音合成(说) |
| 图像模型 | DALL·E · Stable Diffusion | 根据文字描述生成图片 |
| 视频模型 | Sora · Kling | 根据文字/图片生成视频 |
1.3 其他核心概念
| 概念 | 作用 | 直觉 |
|---|---|---|
| Temperature(温度) | 控制输出随机性 | 0 = 最确定保守,1+ = 更创意随机 |
| 上下文窗口(Context Window) | 模型一次能「看到」的最大文本量 | GPT-4 约 128K tokens ≈ 一本20万字的书 |
| Embedding(嵌入) | 把文本转成数学向量 | 用于搜索、相似度比较等 |
| 向量数据库 | 存储和检索 Embedding 向量的数据库 | RAG 的基础设施 |
工程层:能力增强与环境设计
原始模型很强但很「野生」,工程层让它变得可控、可靠、可用。
2.1 Prompt Engineering(提示词工程)
一句话:告诉模型怎么回答
你是一个资深 Python 工程师。回答要简洁,给出代码示例。- 通过精心设计输入文本,引导模型输出你想要的结果
- 技巧:角色设定、Few-shot 示例、思维链(Chain of Thought)等
2.2 Context Engineering(上下文工程)
一句话:告诉模型知道什么
- 不只是写提示词,而是系统性地设计模型能看到的所有信息
- 包括:系统提示词、对话历史、检索到的文档、工具返回的结果等
- 与 Prompt 的区别:
- Prompt = 一句话指令
- Context = 模型看到的完整信息环境(系统提示 + 用户输入 + 检索结果 + 工具输出 + ...)
2.3 RAG(检索增强生成)
一句话:给模型接上外部知识库,减少幻觉
用户提问 → 从知识库检索相关内容 → 把相关内容塞进上下文 → 模型基于这些内容回答- 解决的问题:模型训练数据有截止日期、不了解你的私有数据
- 核心技术栈:Embedding + 向量数据库 + LLM
2.4 推理引擎
一句话:让模型跑得更快更省
- 代表技术:vLLM、TensorRT-LLM、SGLang
- 涉及:模型量化(压缩)、KV Cache 优化、批处理调度等
- 不改变模型能力,只优化速度和成本
2.5 Harness Engineering(驾驭工程)
一句话:设计 Agent 的工作环境与工作流
- 定义 Agent 能用什么工具、遵循什么规则、怎么协作
- 包括:工具注册、权限控制、记忆管理、多 Agent 协作编排
- 这个概念较新,强调的是环境设计而非单纯的提示词设计
想要具体了解的可以先看看这篇文章:《工程技术:在智能体优先的世界中利用 Codex》[1]
应用层:产品形态
把模型和工程能力包装成用户可以直接使用的产品。
3.1 Chatbot(对话机器人)
- 代表:ChatGPT、Claude、豆包
- 特点:一问一答的对话形式,最直接的 AI 产品形态
3.2 Agent App(智能体应用)
- 代表:Cursor(编程)、Coze(搭建)、Codex(编程)
- 特点:不只是聊天,而是能自主规划、调用工具、执行任务
- 核心概念:
- Agent = LLM + 工具 + 记忆 + 规划能力
- 能搜索网页、读写文件、调用 API、多步推理
3.3 CLI 工具
- 代表:Claude Code、Gemini CLI、OpenCode
- 特点:在终端/命令行中运行的 AI 工具,面向开发者
- 优势:与开发工作流无缝集成、可脚本化、高效
举个例子
你在豆包里问:
「帮我写一封请假邮件,明天请病假」
你说了一句话 ↓┌──────────────────────────────────┐│ 🖥️ 应用层(豆包 App) ││ ││ 收到你的消息,显示在聊天框里 ││ 决定调用哪个模型来回答 ││ 拿到回答后排版好展示给你 │└──────────┬───────────────────────┘ ↓┌──────────────────────────────────┐│ ⚙️ 工程层 ││ ││ ① 组装完整消息发给模型: ││ 系统提示:你是一个中文助手 ││ 你的消息:帮我写请假邮件... ││ 你之前的对话记录(如果有) ││ ││ ② 设定参数: ││ 温度 = 0.7(稍微灵活一点) ││ 上下文窗口 = 8K tokens │└──────────┬───────────────────────┘ ↓┌──────────────────────────────────┐│ 🧠 模型层(大语言模型) ││ ││ 收到完整 Prompt ││ ↓ ││ 逐字生成: ││ "尊敬" → "的" → "领导" → ... ││ ↓ ││ 输出一封完整的请假邮件 │└──────────┬───────────────────────┘ ↓ 回到应用层,展示给你简单来说:
| 层 | 干了啥 | 这个例子里 |
|---|---|---|
| 应用层 | 收消息、展示结果 | 豆包 App 的聊天界面 |
| 工程层 | 组装 Prompt、设参数 | 把系统提示 + 你的问题 + 对话历史打包发给模型 |
| 模型层 | 思考、生成回答 | 一个字一个字「预测」写出请假邮件 |
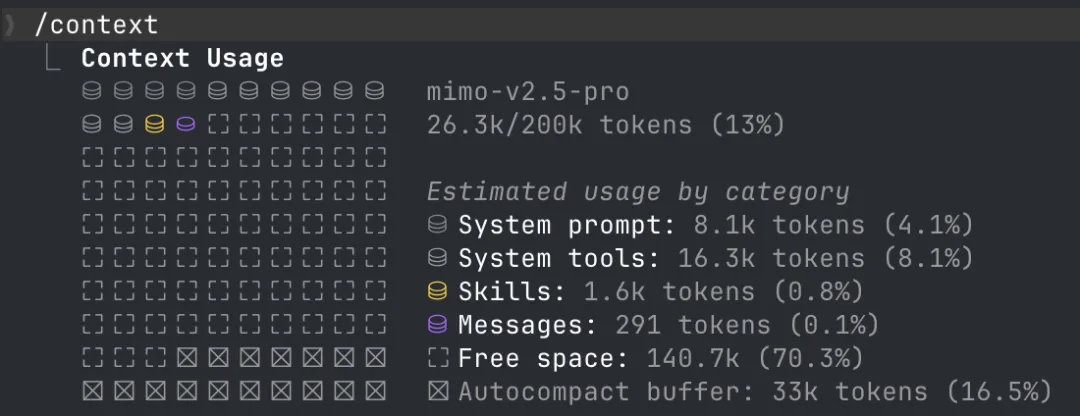
补充说明:本文提到的 Prompt Engineering 和 Context Engineering 并非只存在于你自己手写提示词的场景。在 Claude Code 等工具中,系统会自动注入 System Prompt、工具描述、上下文信息——这些都属于工程层的工作。在 Claude Code 中输入 /context 就能看到你的上下文空间里有多少是系统预设的内容。
这是AI入门系列的第一课,Enjoy exploring!
参考链接
- 《工程技术:在智能体优先的世界中利用 Codex》: https://openai.com/zh-Hans-CN/index/harness-engineering/
