 夜雨聆风
夜雨聆风nano-vllm 用千行代码拆解 vLLM 核心,是读懂大模型推理最快的捷径。
L05 一直把 BlockManager 持有 num_kvcache_blocks 块物理块当作既定前提,但这个数字从哪里来,L05 没解释。回到 Config 类,num_kvcache_blocks: int = -1 默认值是 -1——BlockManager 构造时把这个数当作物理块总数,-1 显然不是合法值,所以必须在 runtime 中改写它,否则 BlockManager 初始化就会因断言失败而崩溃。看 ModelRunner.__init__,这一赋值发生在 allocate_kv_cache 这一行:它根据安全系数、driver/PyTorch 当前观测到的字节数与单块字节数,算出可分配的物理块数:
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes公式四个变量 total / used / peak / current 第 4 节才逐项展开,现在只需要知道:它们都是 GPU 在运行时给出的字节计数;gpu_memory_utilization 是配置中给出的安全系数(默认 0.9,即只动用 90% 显存,留 10% 余量,第 4.2 节展开)。从这四个字节数反推"还剩多少显存可分给 KV cache",再除以"每块占多少字节" block_bytes 得到块数。
这一行引出三个问题:total / used / peak / current 分别是谁、为什么这样组合;为什么这个表达式必须在 warmup_model 之后执行才能算对;block_bytes 又是怎么算的。三个问题指向同一件事:把"还剩多少显存可给 KV cache"这个量,从 PyTorch allocator 与 GPU driver 在 runtime 提供的字段里反推出来,而非在启动前静态估算。
读完你能:
• 解释为什么 num_kvcache_blocks不能在加载模型前算出,必须先做一次 forward• 解释预算公式中 -peak + current这一组合的物理含义,以及它消除的是哪一项重复计算• 在给定 GPU 总显存、模型参数量、 dtype、tp_size、max_model_len的情况下,定性推导num_kvcache_blocks的量级• 说明 block_bytes六个因子各自代表什么,以及把tp_size从 1 改成 4 会如何影响这个数
1. 系统位置:num_kvcache_blocks 从哪来
要回答"num_kvcache_blocks 在何时、由谁赋值"这一问题,先看 ModelRunner.__init__ 的初始化序列。
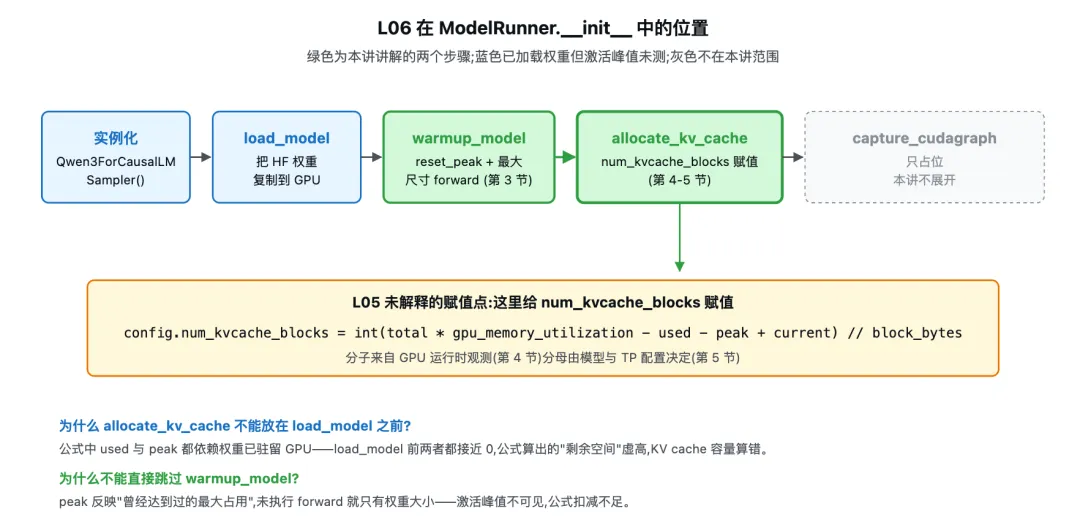
上图横向自左向右是 ModelRunner.__init__ 的执行顺序。蓝色块对应模型/采样器的实例化与权重加载,绿色块是 warmup_model 与 allocate_kv_cache 这两步——本讲讲解的核心,后者是 num_kvcache_blocks 真正被赋值的位置;灰色块是后续的 capture_cudagraph,只占位,本讲不展开。allocate_kv_cache 框内标出 L05 未解释的 num_kvcache_blocks 赋值位置,与公式 total * gpu_memory_utilization − used − peak + current 连线,提示本讲核心。
从位置看,allocate_kv_cache 既不在最前(权重还没加载),也不在最后(CUDA Graph 还没捕获)。这个位置由前置条件决定:它必须晚于 load_model,因为公式要扣减权重占用;还必须晚于 warmup_model,因为公式要扣减激活峰值——激活峰值只有在 forward 真实执行过一次后才能被 PyTorch 的 memory allocator 记录下来。第 2 节解释为什么这两个前置条件不可省;第 3 节解释 warmup_model 具体怎么把激活峰值变得可观测。
2. 为什么不能预先写死容量
如果让用户在配置文件里直接给 num_kvcache_blocks 填一个数,他要算清楚 GPU 上还剩多少字节可用,需要知道下面这些因素的具体值:
• GPU 总显存:A100-80GB、L4-24GB、H100-94GB 各不相同,跨硬件不能共用一个数字。 • 模型权重占用:Qwen3-7B 在 bf16 下约 14 GB,在 fp8 下约 7 GB,在 4-bit 量化下更小。同一模型 dtype 一改,这一项就变。 • 激活峰值:激活指 transformer forward 过程中产生的中间张量(attention logits、FFN 中间结果等),激活峰值是这些张量在某一时刻同时占用显存的最大值。它由 max_num_batched_tokens(单步 forward 一次处理的最大 token 总数,默认 16384)、hidden_size(模型隐藏维度)、num_hidden_layers(模型层数)等共同决定;同一个模型在 prefill 4096 token 与 prefill 16384 token 时的激活峰值相差数倍。• TP 分片:TP(张量并行,Tensor Parallel)把模型权重沿某一维度切到多张 GPU 上协同推理。 tp_size=4时每张卡只持有 1/4 的权重和 1/4 的 KV head,但激活的某些维度并不按tp_size整除分摊;每 rank 实际剩余显存与单卡情形完全不同。• GPU 上的其他占用:CUDA driver 自身、其他用户进程、共享 GPU 的同节点服务都会占用一部分显存。
让用户在启动前估算这些,要么得查每个 GPU 的规格手册,要么得对 transformer forward 的中间张量大小有精确认识。即便估准,估错的方向都是危险的:估少了,KV cache 不够用、抢占频繁触发、吞吐下降;估多了,forward 过程中激活和 KV cache 争用内存、直接 OOM、进程崩溃。
唯一可靠的办法是放弃静态估算,改用动态测量:先把权重加载进显存,再执行一次最大尺寸的 forward,然后向 PyTorch 与 GPU driver 读取"刚才用过的最大字节数"。这两步分别由 load_model 和 warmup_model 完成;读取的工具是两个 API:torch.cuda.memory_stats() 返回 PyTorch allocator 视角下的统计(本进程申请到的字节数与历史最高值),torch.cuda.mem_get_info() 返回 GPU driver 视角下的统计(整张卡当前总占用与剩余)。两个视角的差异在第 4 节展开,它们的若干字段就是预算公式的输入。
反直觉点 ①:你可能以为加载完权重后立刻就能从 PyTorch 读出可用余量,但实际必须先 forward 一次——否则激活峰值不会出现在任何统计字段里。原因留到第 3 节展开:这与 peak 字段的语义有关。
3. warmup_model 让激活峰值可见
第 2 节的"动态测量"方案,关键一步是让"激活峰值"这个量变得可观测。PyTorch 的 CUDA allocator 提供了一个原生支持这件事的字段——memory_stats()["allocated_bytes.all.peak"],简称 peak。
3.1 peak 字段的语义
torch.cuda.memory_stats() 返回一个字典,本节用到两个键:
• allocated_bytes.all.peak:从上次reset_peak_memory_stats()调用以来,PyTorch allocator 持有过的最大已分配字节数。注意是"曾经达到过的最大值",不是"当前持有量"。• allocated_bytes.all.current:PyTorch allocator 当前持有的已分配字节数,随分配/释放实时升降。
forward 时 PyTorch 会临时分配大量激活张量(中间结果),forward 结束后这些张量被释放,current 下降,但 peak 字段会保留这次 forward 期间达到过的最高值,被覆写前始终有效——peak 不会随张量释放而被清除。这个语义是后续反直觉点的基础:peak 只能反映"曾经发生过的占用",不能反映"未来可能出现的占用"。
3.2 反直觉点:不 forward 一次,peak 看不到激活
你可能以为加载完权重就能从 peak 读出"以后 forward 大概要用多少内存"。但 peak 反映的是"已经发生过的最大值",不是"未来可能达到的最大值"。如果在 load_model 后、任何 forward 之前读取 peak,得到的就是权重大小本身——peak 中尚不包含激活的占用。
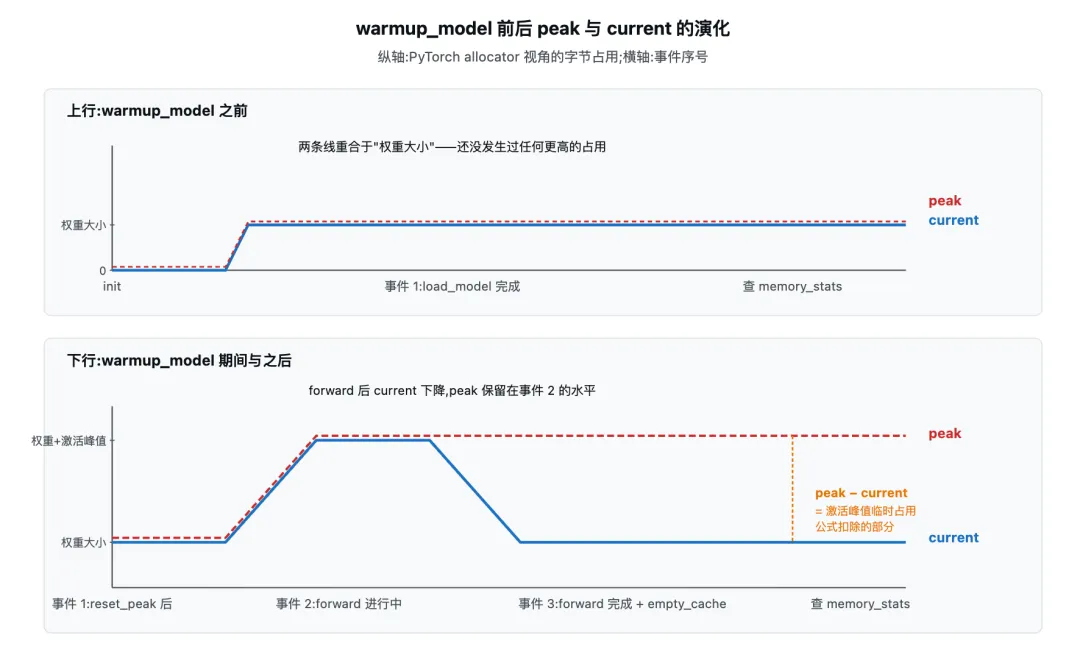
上图分上下两行,横轴是事件序号,纵轴是 PyTorch allocator 视角下的字节占用。上行 "warmup_model 之前":事件 1 是 load_model 完成,current 上升到权重大小、peak 也上升到权重大小——两条线重合,因为还没发生过任何更高的占用。下行 "warmup_model 之后":事件 1 是 reset_peak_memory_stats 把 peak 计数器与 current 对齐(下一节解释这一步的必要性);事件 2 是 forward 进行中,current 上升到"权重 + 激活峰值",peak 也同步上升到这个水平;事件 3 是 forward 完成、调用 empty_cache,current 下降到接近权重大小,但 peak 保留在事件 2 的水平。
这张图直接对应预算公式里 -peak + current 的物理含义:peak − current 正好就是"激活峰值临时占用的那部分",这部分要预留给后续每次 forward。
知道 peak 在 forward 前不反映激活后,触发一次最大尺寸 forward、将真实激活峰值写入 peak 字段,正是 warmup_model 这段代码要做的事。
3.3 warmup_model 的实现
defwarmup_model(self):
torch.cuda.empty_cache()
torch.cuda.reset_peak_memory_stats()
max_num_batched_tokens, max_model_len = self.config.max_num_batched_tokens, self.config.max_model_len
seq_len = min(max_num_batched_tokens, max_model_len)
num_seqs = min(max_num_batched_tokens // seq_len, self.config.max_num_seqs)
seqs = [Sequence([0] * seq_len) for _ inrange(num_seqs)]
for seq in seqs:
seq.num_scheduled_tokens = seq_len
self.run(seqs, True)
torch.cuda.empty_cache()理解这段代码前,先说明 PyTorch 的两层内存模型:PyTorch CUDA allocator 向 driver 申请大块显存,称为 reserved;再从 reserved 里切出小块分给具体张量,称为 allocated。两层结构的目的是避免每次张量创建/销毁都触发 driver 调用——driver 申请开销大,allocator 把归还的小块留在 reserved 池里复用,只有调用 empty_cache() 时才把 reserved 中未分配出去的部分归还给 driver。current 与 peak 都是 allocated 维度的统计,与 reserved 无关。

上图按时间顺序展示三个状态:① 4 个张量全部分配时,reserved 池正好被填满,allocated current = 4、peak = 4;②del T2/del T3释放两个张量后,allocatedcurrent降到 2,但 reserved 池仍保持 4(空槽以虚线方框表示,留作后续torch.empty(...)复用),peak仍是 4 不下降;③ 调用empty_cache()后,reserved 池里两个空槽被归还 driver,reserved收缩到 2,current不变,peak仍是 4。三个状态对照说明:张量释放只动 allocated、不动 reserved;empty_cache 才让 reserved 收缩;peak 始终保留历史最大值——预算公式只用current和peak(都是 allocated 维度),与 reserved 大小无关,因此warmup_model中两次empty_cache是为了让 driver 视角的mem_get_info() 报告更准确,而非影响 peak。
关键的四步:
1. torch.cuda.empty_cache():把 PyTorch reserved 但未分配出去的缓存归还给 driver,让mem_get_info()返回的 GPU 总占用更准。2. torch.cuda.reset_peak_memory_stats():把peak计数器置为当前current值。这一行只清空 peak,不修改 current 与其他累计字段;之后 peak 只反映 warmup 这一次 forward 的最大值。3. 构造一个最坏情况的输入: seq_len = min(max_num_batched_tokens, max_model_len),意思是单条 seq 的长度不能超过模型支持的最大长度,也不能超过单步 forward 一次能处理的 token 上限;num_seqs = min(max_num_batched_tokens // seq_len, max_num_seqs),其中max_num_seqs是单步 forward 能并发的最多 seq 条数(默认 512),这一行的意思是在不超过最大并发条数的前提下,把 seq 数填到正好让num_seqs × seq_len ≈ max_num_batched_tokens,合计输入恰好占满max_num_batched_tokens。代码倒数第二行self.run(seqs, True)的第二个实参对应is_prefill=True,表示执行 prefill 分支(用 prefill 而非 decode,是因为 prefill 一次性处理整段输入,激活张量比 decode 大得多)。4. forward 完成后再 empty_cache(),把临时激活归还给 driver,但 peak 已被记录,不会随这次清理而下降。
第 2 步是关键。反例 ①:若省略 reset_peak_memory_stats,这次 forward 之前 load_model 也短暂产生过临时占用(权重初始化、HF 加载器复制张量),那段历史峰值可能高于本次 forward 的真实激活峰值,导致后续公式扣减过多空间——num_kvcache_blocks 偏小、KV cache 利用率下降。反例 ②:若省略输入的最坏情况构造,例如只执行一条短 seq 的 forward,peak 反映的就是这条短 seq 的激活峰值,后续真实请求一旦超过这个尺寸就会 OOM。反例 ③:若 is_prefill=False 执行 decode 分支,激活只覆盖单 token,peak 会大幅低于真实 prefill 时的水平,后果与反例 ② 相同。三条合起来保证 peak − current 这一差值恰好等于"未来任何一次 forward 可能达到的最大激活临时占用"。
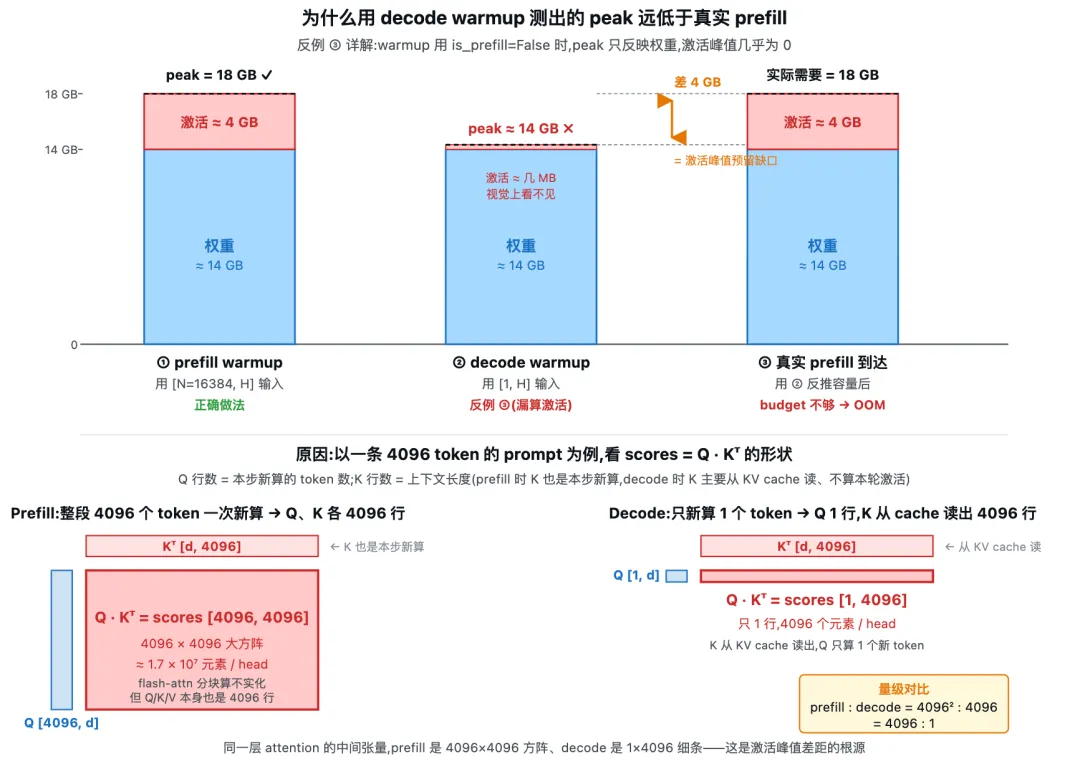
上图三根柱状条对比同一模型在三种情形下 PyTorch allocator 的 peak。① prefill warmup(is_prefill=True、输入形状 [N=16384, H])记下 peak ≈ 18 GB(权重 14 GB + 激活峰值 4 GB),按这个 peak 反推容量,留给 KV cache 的空间恰当;② decode warmup(is_prefill=False、输入形状 [1, H])激活只覆盖单 token,只占几 MB,视觉上几乎看不见,peak ≈ 14 GB,只反映了权重大小;③ 真实负载下 prefill 请求到达,仍需要 18 GB,但 ② 已按 14 GB 反推容量、KV cache 把剩余空间分得满满,4 GB 激活临时分配无处可放,直接 OOM。中间橙色双向箭头标出的 4 GB 缺口,正是反例 ③ 的代价。下半部分用 attention 的核心计算 scores = Q · Kᵀ 解释这个差距的根源。Q 和 K 在两条路径下角色不同:
• Q 是本步新算的 token 的 query——每个本步要算的 token 贡献一行; • K 是上下文中所有 token 的 key——上下文长度 = K 行数。prefill 时 K 还没存入 cache,本步与 Q 一起新算;decode 时 K 主要从 KV cache 读出,不算本轮激活。
以一条长度为 4096 的 prompt 为例(对应 nano-vllm warmup batch 内一条 seq 的视角),两条路径下 Q 与 K 的形状截然不同:
• Prefill:整段 4096 token 一次性新算,K 还没存入 cache,Q 与 K 都是 4096 行( Q [4096, d]、K [4096, d]),Q · Kᵀ = [4096, 4096]大方阵,约4096² ≈ 1.7×10⁷个元素 / head。• Decode:只新算 1 个新 token,Q 只 1 行( Q [1, d]);K 从 KV cache 读出该 prompt 已有的 4096 行(K [4096, d]),Q · Kᵀ = [1, 4096]一条细带,只 4096 个元素 / head。
两者的中间张量量级差到 4096² / 4096 = 4096 倍——这就是 ② 的 peak 远低于 ③ 实际需要的根本原因。回到上半的 nano-vllm 实际 warmup 场景:4 条 prompt × 4096 token 同时 prefill,等于把上述单条 attention 矩阵复制 4 份并行算,激活峰值再放大约 4 倍,得到约 4 GB 的差距。
warmup_model 执行完后随即调用 allocate_kv_cache,此时 peak 已被设置为真实激活峰值,公式的所有输入都就绪。
4. 预算公式逐项解读
allocate_kv_cache 的前半段是公式的全部输入,核心一行把这些数字组合起来:
defallocate_kv_cache(self):
config = self.config
hf_config = config.hf_config
free, total = torch.cuda.mem_get_info()
used = total - free
peak = torch.cuda.memory_stats()["allocated_bytes.all.peak"]
current = torch.cuda.memory_stats()["allocated_bytes.all.current"]
...
config.num_kvcache_blocks = int(total * config.gpu_memory_utilization - used - peak + current) // block_bytes4.1 四个数字各自代表什么
• total:GPU 总显存,由 driver 给出。一张卡的硬件物理上限,与本进程无关。• free:当前仍未被任何进程占用的字节数,由 driver 给出。• used = total - free:GPU 视角下当前已被占用的总字节数。等式的物理含义:driver 报告的free是"仍未被任何进程申请的字节",total − free就是被申请出去的总量,既包含本进程的权重和 PyTorch reserved 缓存,也包含其他用户进程、CUDA context 自身、以及 GPU 上任何其他占用项。• peak:PyTorch 视角下,从reset_peak_memory_stats以来本进程 PyTorch allocator 持有过的最大已分配字节数。第 3 节解释过,经过 warmup 后,这值等于"权重 + 激活峰值"。• current:PyTorch 视角下,本进程 PyTorch allocator 当前持有的已分配字节数。warmup 完成时empty_cache()已把临时激活归还,current中剩下的主要就是权重张量,因此current ≈ 权重大小。
两个视角的关系:used 是 driver 视角的全量,包含 PyTorch allocator 的占用;current 是 PyTorch allocator 自身视角的当前占用,是 used 的子集。两者相减:used 是 driver 视角的全部占用,current 是 PyTorch allocated 的子集;前者减后者剩下的部分,按定义就是 PyTorch allocated 之外的所有占用——即"非 PyTorch 占用"(driver 自身、其他进程、CUDA context、PyTorch reserved 但未分配的那部分)。
明确了四个字段各自代表什么后,接下来解释源码为什么把它们组合成 total*util − used − peak + current 这一形式。
4.2 公式的物理含义
total * gpu_memory_utilization - used - peak + current
逐项解释:
• total * gpu_memory_utilization:可用上限。gpu_memory_utilization默认 0.9,即只动用 90% 的显存,留 10% 安全边界,防止 driver/CUDA context 在 runtime 增长触发 OOM。• - used:扣除当前已被占用的全部字节(包含本进程权重 + 其他进程 + driver)。• - peak + current:扣除激活峰值预留。承 4.1:warmup 后current ≈ 权重大小、peak ≈ 权重 + 激活峰值,两者之差就是激活峰值。这部分内存当前虽然空闲,但下一次真实推理 forward 又会用到,必须为它预留空间。
合起来 - used - peak + current = - (used - current) - peak,这是一个更直观的等价改写:
• - (used - current):扣除非 PyTorch 占用(其他进程、driver、context、PyTorch reserved 部分)。• - peak:扣除本进程 PyTorch 在 forward 期间的最高占用(包含权重 + 激活峰值)。
两种写法逐项物理含义相同,后者更贴近读者直觉。源码选择前者写法,原因是 peak 与 current 都直接来自 memory_stats() 字段,字段组合后形式整齐,无需再算一次 used − current。
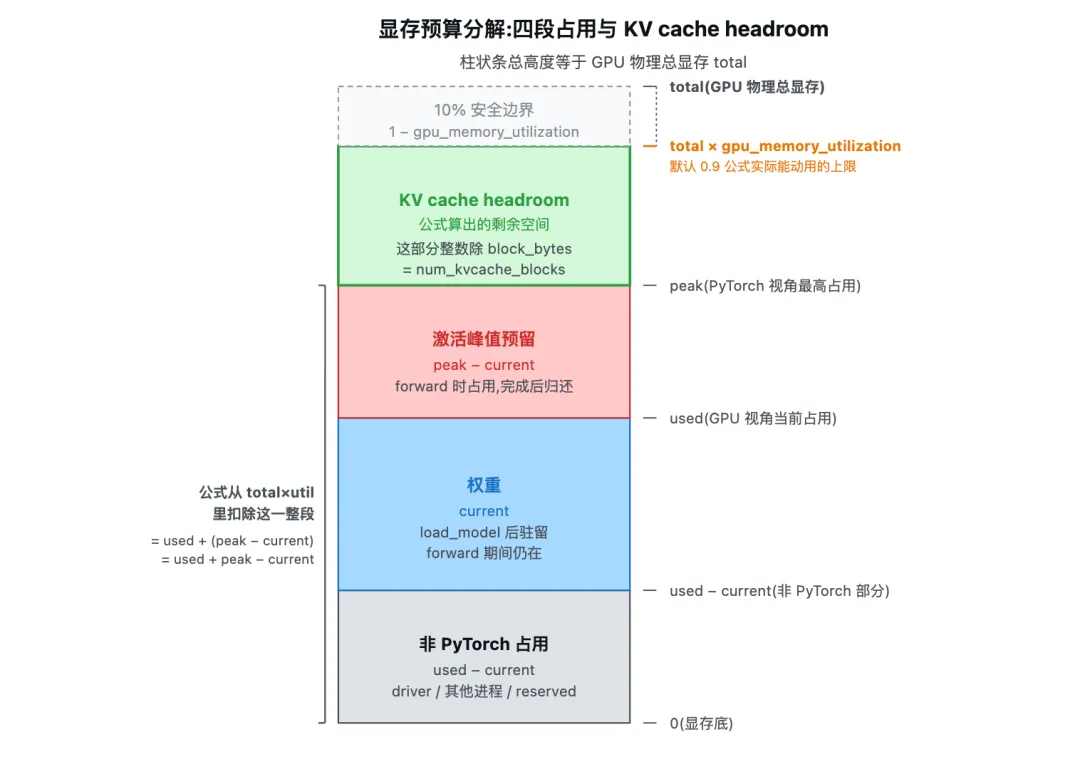
上图是一根纵向的显存柱状条,自下而上分四段。最底层 非 PyTorch 占用(used − current)代表 driver、其他进程、PyTorch reserved 等;中间层 权重(current)代表 load_model 后驻留在 PyTorch 里的张量,warmup 后临时激活已被 empty_cache 归还,这一段近似等于权重大小;再上是 激活峰值预留(peak − current),代表 forward 期间瞬时被占用、forward 后归还、但下次 forward 还要用的空间;最顶端是 KV cache headroom,即留给 BlockManager 的字节数。柱状条右侧用横线标注两个关键上界:总显存 total 是绝对上限,total * gpu_memory_utilization 是公式实际能动用的上限,两线之间的灰色带是 10% 安全边界。
关键不变式:非 PyTorch 占用 + 权重 + 激活峰值预留 + KV cache headroom = total * gpu_memory_utilization,即四段之和等于公式实际能动用的上限。预算公式的本质就是已知前三项,反推第四项。
4.3 反直觉点:为什么同时减 peak 又加 current
你可能以为 −peak 已经把"激活峰值"扣完了,公式不该再 +current。但源码就是这样写的,原因如下。
peak 是 PyTorch 视角下 forward 期间的总最高占用——这个值天然包含权重大小(forward 期间权重一直驻留)。而 used 也已经包含权重(权重作为 PyTorch 当前的 current 那部分,被 driver 计入 used)。如果不加回 current,公式就会把"权重"这部分内存在 −used 和 −peak 中重复扣除一次。+current 正好抵消这一次重复:peak 里包含的 current 那部分,已经在 used 里扣过一次,加回来之后只剩 peak − current = 激活峰值临时占用 在被扣。
等价改写:- used - peak + current = - (used - current) - peak,左右两式恒等,后者读起来不需要做这道"减两次再加一次"的算术。带 +current 修正项的预算公式,几乎都是为了消除两个视角下重复计入的某一项。
5. block_bytes 六因子
预算公式给出的是"留给 KV cache 的字节数",还得除以"每块占多少字节"才能得到块数。先想清楚一块要存什么,六因子的乘积关系就是自然结果:一块覆盖 block_size 个 token;每个 token 在 attention 的每一层都要单独存 K 和 V 两份(attention 把每个 token 投影成 K、V 两个向量,各按 head 拆分,缓存它们供后续 token 查询);每份 K 或 V 的形状是 [每 rank 的 KV head 数, head_dim](每 head 算出一个 head_dim 维的向量);每个元素占 dtype.itemsize 字节。把这四个"每"层级相乘,就得到一块的字节数:
num_kv_heads = hf_config.num_key_value_heads // self.world_size
head_dim = getattr(hf_config, "head_dim", hf_config.hidden_size // hf_config.num_attention_heads)
block_bytes = 2 * hf_config.num_hidden_layers * self.block_size * num_kv_heads * head_dim * hf_config.dtype.itemsize5.1 六个因子的含义
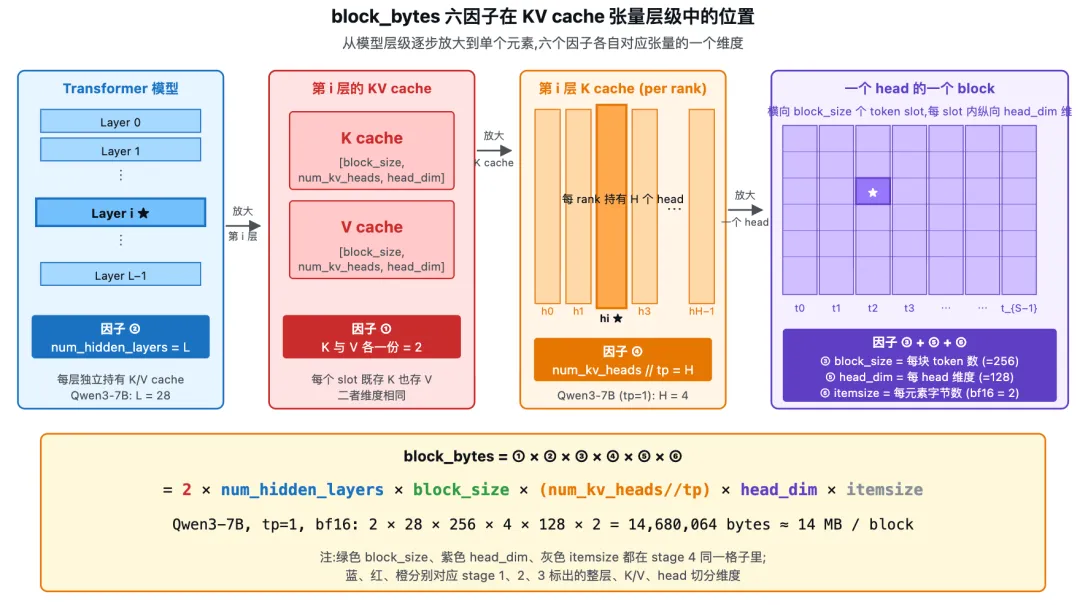
上图把 KV cache 张量按"从模型到元素"的四个层级逐步放大,六个因子各自落在层级的一个维度上:stage 1(蓝)整个 Transformer 由 L 层叠加,每层独立持有 K/V cache → 因子 ② num_hidden_layers;stage 2(红)第 i 层内部分 K 与 V 两份张量 → 因子 ① 2;stage 3(橙)K cache 按 head 切分为 H 个 head 块,每 rank 持有的头数由 TP 整除决定 → 因子 ④ num_kv_heads // tp;stage 4(紫)一个 head 的一个 block 内:横向 block_size 个 token slot,每个 slot 是 head_dim 维向量,每个元素占 itemsize 字节(图中高亮的小格 ★ 就是一个元素)→ 因子 ③⑤⑥。箭头表示"逐级放大",底部黄色框是六因子相乘公式与 Qwen3-7B 代入示例(详见 5.2)。
• 2:K 与 V 两份张量。attention 每个 slot(KV cache 中一个 token 对应的存储位置)既存 K 也存 V,二者维度相同,字节数因此 ×2。• num_hidden_layers:模型层数。每一层 attention 都有独立的 K/V cache(不同层语义不同,不能共享),Qwen3-7B 为 28 层、Qwen3-14B 为 40 层。• block_size:一块容纳的 slot 数,即一块能存多少个 token 的 K/V。config.kvcache_block_size默认 256。这值越大每块越大、块数越少,但内部碎片也可能越多。• num_kv_heads // world_size:每 rank 持有的 KV head 数。先说 KV head 与 attention head 的区别:在 MHA(多头注意力)里两者数量相等;在 GQA(分组查询注意力)里,多个 attention head 共享一份 KV head(降低 KV cache 占用),num_key_value_heads小于num_attention_heads——例如 Qwen3-7B 是 28 个 attention head、4 个 KV head。整除world_size表示张量并行把 KV head 维度切到各 rank,每 rank 只算 K/V 的一部分头。KV head 之间在 attention 计算中互相独立,因此沿 head 维度切分到各 rank 没有跨 rank 通信开销——这是 TP 选择切这一维的原因。具体切分实现不在本讲范围。• head_dim:每个 head 的维度,通常 64/96/128。HF config 若没显式提供head_dim,fallback 用hidden_size // num_attention_heads。• dtype.itemsize:每个浮点数的字节数。fp16/bf16 是 2,fp32 是 4,fp8 是 1。dtype 直接影响block_bytes,改 dtype 是最直接放大num_kvcache_blocks的手段。
5.2 一个具体例子
六个因子分别讲清楚后,代入一组真实数字看看 block_bytes 与 num_kvcache_blocks 大致在什么量级。以 Qwen3-7B、bf16、tp_size=1、block_size=256、num_key_value_heads=4、num_hidden_layers=28、head_dim=128 估算。先做一步换算:tp_size=1 时 num_kv_heads = num_key_value_heads // world_size = 4 // 1 = 4。代入六因子:
block_bytes = 2 × 28 × 256 × 4 × 128 × 2
= 14,680,064 bytes
≈ 14 MB / block若 GPU 总显存 80 GB、util=0.9,假设各项占用大致是:权重对应 current ≈ 14 GB,激活峰值对应 peak − current ≈ 4 GB,非 PyTorch 占用 used − current ≈ 1 GB,合计需要扣除约 19 GB,留给 KV cache 大约 80 × 0.9 − 19 ≈ 53 GB:
num_kvcache_blocks ≈ 53 GB / 14 MB ≈ 3780 块每条 max_model_len=4096 的请求最多用 4096 / 256 = 16 块,理论上能并发 3780 / 16 ≈ 236 条请求(实际还受 max_num_seqs 上限制约)。
5.3 TP 对 num_kvcache_blocks 的影响
上例假设单卡(tp_size=1)。当 tp_size 从 1 变成 4,模型权重沿 head 维度切到 4 张卡协同推理,这一切分同时影响 num_kvcache_blocks = 分子 / block_bytes 公式的两端。
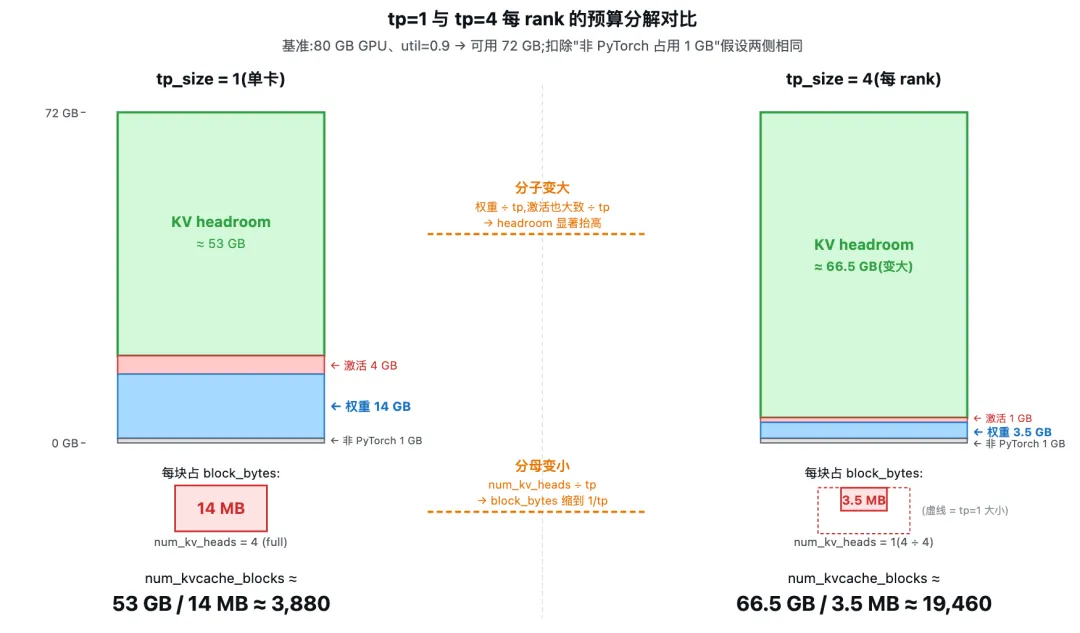
上图左右两侧分别画出 tp=1 与 tp=4 每 rank 的显存柱状分解,可以直接对照看出两个变化方向:
• 分母 block_bytes缩小:num_kv_heads // world_size从 4 变成 1,block_bytes缩小到原来的 1/4(图中右侧的红色方块只有左侧的 1/4 大小,虚线轮廓是 tp=1 时的对照)。• 分子(KV headroom)抬高:每 rank 只持有 1/4 权重( 14 GB → 3.5 GB),激活峰值在多数 TP 实现下也大致按tp_size缩小(4 GB → 1 GB,因为 TP 把 attention 的 head 维度和 FFN 中间维度都切到各 rank,中间张量大致按tp_size缩小)。扣除项总和从约 19 GB 降到约 5.5 GB,绿色KV headroom段从 53 GB 抬高到 66.5 GB。
num_kvcache_blocks = 分子 / block_bytes 在两端同时受益:分子变大、分母变小,两者通过除法相互放大。代入估算,tp=1 时 ≈ 3,880 块,tp=4 时 ≈ 19,460 块——每 rank 容量约是 tp=1 时的 5 倍,显著大于 tp_size = 4 本身。
具体倍数取决于权重与激活在扣除项里各占多大;tp_size=2 时两端的变化方向同样适用,具体数字推导见思考题。
6. 思考题
先合上教程自己答一遍,再看参考答案。
问题 1(dtype 影响):某模型在 bf16 下 num_kvcache_blocks = 1000。其他配置不变,把 dtype 改为 fp8(itemsize 从 2 变为 1)。新的 num_kvcache_blocks 大约是多少?写出推导步骤,标明你做了哪些近似。
问题 2(TP 影响):同一模型,tp_size 从 1 改成 2。说明 block_bytes 和"留给 KV cache 的字节数"分别如何变化(各自变大、变小,还是不确定),并解释每一项变化的原因。最后推断 num_kvcache_blocks 的变化方向。
问题 3(顺序依赖):如果把 warmup_model 这一行从 ModelRunner.__init__ 里删除,直接进入 allocate_kv_cache,推断 num_kvcache_blocks 最有可能算出什么值(偏大、偏小,还是大致正确),并说明运行时会出现什么后果。
7. 总结
• 动态测量替代静态估算: num_kvcache_blocks不能在启动前拍数字,必须先加载权重、做一次最大尺寸 forward,再读取 PyTorch allocator 与 GPU driver 的运行时字段反推。让用户在硬件、dtype、TP、max_model_len任一项变化时都不用重新算。• 预算公式 = 上限 − 占用 − 预留: total × gpu_memory_utilization是上限,扣掉 GPU 当前已被占用的used、再扣掉 forward 期间的激活峰值peak − current,剩下的字节数就是留给 KV cache 的。+current修正项的作用是消除used与peak都包含权重而被重复扣除一次的部分。• warmup 不可省: peak字段只反映"已经发生过的最大值",所以必须先 forward 一次让激活峰值"被看见"。reset_peak_memory_stats把历史峰值清零、is_prefill=True用最大尺寸输入,两件事合起来让peak − current恰好等于"未来任何一次 forward 可能达到的最大激活临时占用"。• block_bytes是 KV cache 张量的体积:六因子2 × num_hidden_layers × block_size × (num_kv_heads // tp) × head_dim × itemsize各对应张量的一个维度。dtype 改半、TP 切到多卡,都会同时缩小block_bytes并放大num_kvcache_blocks。• 关键不变式: 非 PyTorch 占用 + 权重 + 激活峰值预留 + KV cache headroom = total × gpu_memory_utilization。预算公式做的事就是已知前三段、反推第四段,再整除block_bytes得到块数。
