 夜雨聆风
夜雨聆风Token经济学:AI时代的新货币战争
中国模型如何用1/17价格杀入全球市场?
硅谷最新的炫富方式不是豪车名表,而是——
“你今天烧了多少token?”
在硅谷,一种新的攀比文化正在悄然兴起。它有一个新词——Token-maxxing,意思是“把token用量拉到极限”。工程师之间互相问的不再是“你写了多少行代码”,而是“你每天消耗多少token?”“你能同时调度多少个agent运行?”“你的token throughput有多高?”
Meta内部甚至有一个名为“Claudeonomics”的排行榜,汇集了超过85,000名员工的AI使用数据。最近一个月,排行榜上的总使用量突破了60万亿token。按照Anthropic Opus的定价粗略换算,这些token价值高达约9亿美元。排名第一的员工,一个人就烧掉了数百万美元。
| 8.5万Meta员工参与 | 60万亿月消耗Token | 9亿美元等值金额 |
这场疯狂的“烧token”竞赛背后,是一个正在成形的新经济范式——Token经济学。它正在重新定义AI时代的成本结构、商业模式,甚至国家之间的产业竞争。
一、什么是Token经济?AI时代的“新货币”
要理解Token经济学,首先要明白:token是什么?
在大型语言模型中,token是模型处理文本的最小单位。一个token可以是一个汉字、一个英文单词的一部分,或者一个标点符号。当你向ChatGPT问一句话,或者让Claude写一段代码,你的输入会被拆分成若干个token,模型生成的回答也是一个个token拼接而成。
每一次交互,背后都是一笔token账单。
Token为什么是“货币”又是“电力”?
像货币——因为它是交换价值的媒介。你向模型“支付”token(消耗配额),换取模型的计算能力和输出结果。一些风投基金已经开始直接给被投企业提供token额度作为投资的一部分——拿了钱也是去买token,不如直接给token。
像电力——因为它是驱动一切AI应用的底层能源。没有token,agent无法运行,Claude Code无法响应,自动化流程寸步难行。而且token也有“峰谷电价”式的分级定价,就像黄仁勋在2026年GTC大会上提出的五档框架:从免费层到每百万token 150美元的超高速层,按交互速度和场景定价。
可以说,Token经济学就是研究如何生产、定价、分配、消耗和套利token的学问。 它正在成为AI时代最基础的商业逻辑。
二、Token怎么计费?一个对话藏着三种价格
你可能以为token计费就是“单价 × 数量”。实际上,一次最简单的对话交互,账单上至少有三种不同价格的token在同时运转。
以OpenAI的GPT-5为例(API定价):
• Input:每百万token 1.25美元
• Cached input:每百万token 0.125美元
• Output:每百万token 10美元
而更强的GPT-5.5,output token涨到了每百万token 30美元。
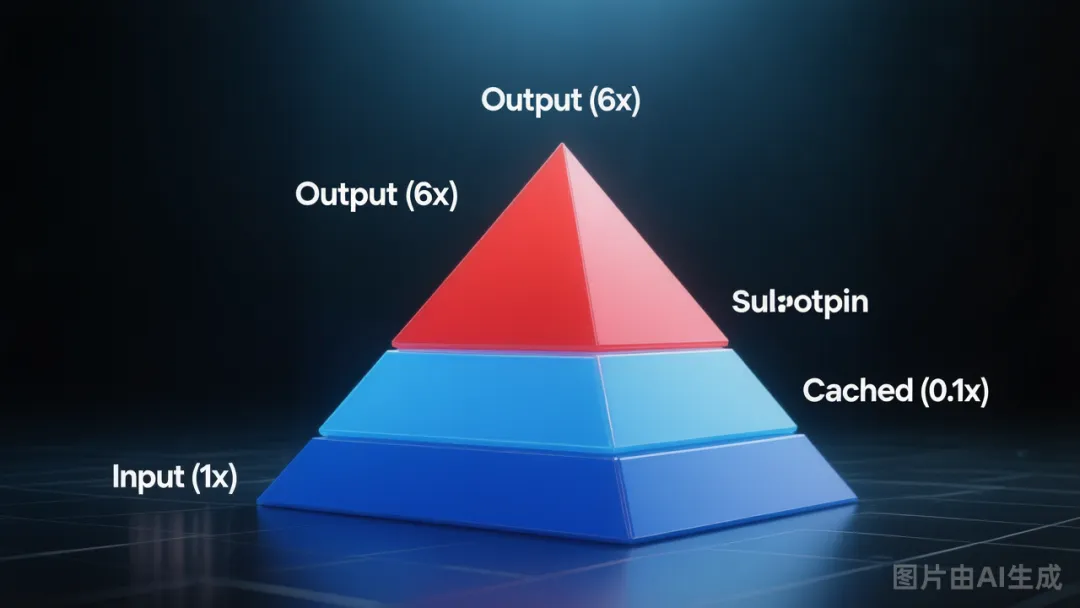
Token三种定价比例:Input : Cached : Output
一个反直觉的悖论:越贵的模型,反而越省钱?
你可能会想:那我肯定选最便宜的模型啊。但事实恰恰相反。
强模型一次就能做对,弱模型可能要反复重试,中间出错还需要人工介入。 在agent场景下,模型会被来回调用多次,每一步都可能调用不同工具,工具产生新日志再返回给模型。如果用弱模型,这个循环会变得又长又贵。
“越贵的模型,可能对于完成任务的综合成本是越低的。” —— 研究芯片与token效率方向的专家肖志斌
💡 强模型悖论
单价高,但总成本低。用弱模型反复试错的代价,往往比直接用强模型更高。
三、近一半Token被浪费了:成本焦虑蔓延
既然token这么贵,那大家是不是都精打细算?并不是。
业内有人批评,当前全球企业AI应用中,可能有近一半的token没有产生实际价值。原因很简单:Agent不像人类那样知道“够了就停”。
在执行任务的过程中,agent会反复做这些低效操作:
• 反复读取整个对话历史(哪怕大部分内容与当前任务无关)
• 重新扫描已经处理过的文件
• 把早就过期的上下文一遍又一遍地“喂”给模型
📊 成本焦虑案例
案例:Uber的CTO 最近透露,公司2026年的AI预算在开年几个月内就全部用完了——工程师们对Claude Code的使用量暴增。他的原话是:“我得重新回去做预算了,因为我以为够用一年的钱,已经没了。”
硅谷投资人Chamath Palihapitiya 也公开抱怨,他投资的一家软件公司,自从团队开始使用AI编程工具后,运营成本在几个月内翻了三倍多。
如何让agent少烧冤枉钱,正在成为一个新的技术和商业赛道。 Token Efficiency成了下一个关键词。
四、智能路由与Token套利:省钱的终极方案
既然不同的模型有不同的性能和价格,那最聪明的做法就是:简单任务交给便宜模型,复杂任务交给强模型。 这就是混合模型使用,而实现它的核心技术叫做模型自动路由。
你可以搭建一个“智能路由器”:
用户请求进来后,先用一个小模型判断任务的复杂度
简单任务(如分类、提取关键词)→ 分配给便宜模型(如国产开源模型)
复杂任务(如代码生成、逻辑推理)→ 分配给Claude或GPT
对用户来说是完全黑盒的,他只知道结果。但作为服务提供方,你的token成本大幅下降。
这就是Token Arbitrage(Token套利)——利用不同模型之间的性能和价格差异,赚取差价。
套利的类比
报税审计师:你自己报税可能要交1万美金,花5000美金雇一个专业审计师,他能帮你优化到只交2000美金,省下来的钱两人分。
运营商带宽:你家的下行带宽1千兆,上行只有40兆,但普通用户感受不到区别。token套利也是类似——用户体感上,便宜模型和贵模型的输出差别不大,那中间就有套利空间。
OpenRouter:套利的基础设施
OpenRouter 就是这样一个平台。它聚合了市面上几乎所有模型,开发者用一个接口就能调用各家模型,平台从中抽取约5%的费用。创始人Alex Atallah是OpenSea的联合创始人兼CTO,目前OpenRouter估值接近13亿美元。
让OpenRouter真正起飞的,是OpenClaw等agent框架的爆发。全球开发者疯狂调用各种模型来驱动agent工作流,需要一个能够快速切换模型的中间层——OpenRouter恰好在那里等着。
五、中国模型凭什么杀入全球市场?价格仅为1/17
在OpenRouter上,一个现象越来越明显:中国模型正在霸榜。
拿MiniMax M2.5和Claude Opus做直接对比:
💡 核心对比
核心对比:性能几乎无差异——在SWE-Bench Verified软件工程基准测试中,两者得分分别为80.2%和80.8%,实际使用中几乎感受不到差距。价格却差了17倍:MiniMax M2.5的输入价格是每百万token $0.3,Claude Opus是$5。
对于一个每天跑几千万token的OpenClaw用户来说,这不是省一杯咖啡钱的问题,而是账单从几百美元直接降到几十美元的区别。
为什么中国模型能这么便宜?
⚙️ 技术:MoE架构 深度MoE(混合专家模型),专家规模越来越小,每次激活的专家数量不大,从技术上节省了计算量 | 🏷️ 生态:补贴策略 国内大模型市场竞争激烈,各家都在用低价甚至免费策略吸引开发者 | ☁️ 云厂商优势 阿里、腾讯、百度本身就是云厂商,可以用内部定价把模型成本打到更低 |
中国token出海:下一个结构性产业机会?
OpenClaw爆火之后,agent任务对开源模型调用需求飙升,智谱AI、MiniMax等中国模型厂商在股价上迎来了疯狂涨幅。
与此同时,2026年3月,国内三大云厂商(腾讯云、阿里云、百度智能云)在10天内集体涨价约30%——这说明需求已经大到可以提价了。
**中国出口产业的演变**:上一个时代——衬衫;这个时代——电动车;下一个时代——**Token**。
上一个时代:衬衫这个时代:电动车下一个时代:Token
这听起来很疯狂,但逻辑是通的。中国在算力基础设施、模型工程化、成本控制方面积累了独特的优势。当全球AI应用开发者都在寻找“又强又便宜”的模型时,中国模型厂商带着1/17的价格杀入全球市场,这不是一次性的价格战,而是一个结构性的产业机会。
六、Token经济学的未来:谁掌握“电表”,谁掌握规则
如果token是AI时代的“电”,那总得有人来装“电表”。这家公司叫Metronome。
Metronome的客户名单令人咋舌:OpenAI、NVIDIA、Anthropic、Databricks……全部在用它的计费系统。两位创始人都出自Dropbox,亲身经历过“改定价”的痛苦——表面上调几块钱月费,背后要动一大堆写死在代码里的计费逻辑。
到了AI时代,收费单位从“一个人头一个月多少钱”变成了token数、API调用次数、GPU时长这些颗粒度极细的指标,而且每个客户的合同条款、折扣结构和用量阶梯都不一样。Metronome做的事情就是清晰地记住:谁在什么时间调用了什么东西,花了多少token。
Token经济学的未来,不仅仅是模型厂商之间的竞争,更是“货币发行权”和“计量标准”的争夺。
写在最后
一句话总结:Token正在成为AI时代的货币,中国模型靠性价比杀入全球市场,而“Token套利”将是下一个创业风口。
Token经济学正在从硅谷的极客话题,变成每一个AI创业者、开发者甚至投资者都必须理解的底层逻辑。
本文内容基于《硅谷101》视频字幕整理与分析,数据与案例均已核实。
