 夜雨聆风
夜雨聆风你是否也曾对AI助手感到失望?它能写出流畅的代码,能生成优美的文案,但在多轮对话后,却常常忘记你最初设定的前提,或是你刚刚提到的关键信息。这种“金鱼记忆”般的体验,是当前AI Agent(智能体)面临的核心痛点之一。
就在上个月,Y Combinator总裁Garry Tan开源了一个名为GBrain的项目,为这个问题提供了一个极具启发性的解决方案。它不仅是一个知识管理系统,更被设计为AI Agent的“长期记忆”,旨在让AI真正理解并记住你的一切。
今天,我们就来深入拆解这个在GitHub上迅速斩获数万Star的热门项目。
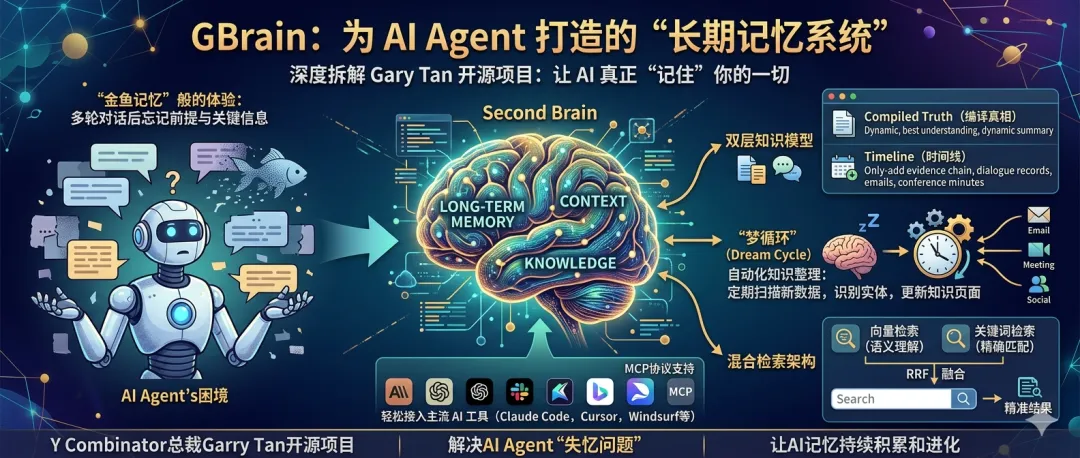
GBrain是什么:为AI打造的“第二大脑”
简单来说,GBrain是一个专为AI Agent设计的、可被持续读写的长期记忆系统。
它的灵感源于Andrej Karpathy提出的“LLM Wiki”范式,但Garry Tan在实践中发现,当个人知识库增长到数万份Markdown文件、十余年的日历和邮件数据时,传统的文件管理方式已不堪重负。于是,他引入了数据库和向量检索,构建了GBrain。
GBrain的核心目标非常明确:解决AI在个人数据层面的“失忆问题”。它能够将你的笔记、邮件、会议记录、日历、社交动态等多源数据整合成一个结构化的知识库,并让AI Agent在对话前后自动进行知识的读取与写入,从而实现记忆的持续积累和进化。
核心原理:不只是存储,更是智慧的进化
gBrain的强大之处,源于其精巧的设计哲学。它并非简单地将你的所有文件丢进一个数据库,而是通过一系列机制,让知识“活”起来。
1. “编译真相”与“时间线”双层知识模型
这是gBrain最核心的创新。系统中的每一个知识页面(Page)都由两部分构成:
编译真相(Compiled Truth):位于上层,是系统基于所有现有证据,对某个实体(如一个人、一个概念、一个项目)的“当前最佳理解”。它是一个动态的、可被重写的摘要。当新的证据出现时,这一层会被更新,确保Agent总能获取到最新的结论。
时间线(Timeline):位于下层,是一个“只追加、不修改”的证据链。所有原始的对话记录、邮件、会议纪要、文档片段等,都会按时间顺序被追加到这里。它保证了信息的可追溯性,让你和Agent都能回溯任何一个结论的来源。这种设计巧妙地分离了“结论”与“证据”,既保证了知识的时效性,又保留了其演化过程,让AI的记忆不再是杂乱无章的碎片,而是结构化的智慧。
2. 混合检索架构:精准与广度的完美结合
当你向gBrain提问时,它如何从海量知识中找到最相关的信息?gBrain采用了一套强大的混合检索方案:
向量检索:理解语义,即使你用的词和原文不同,也能找到相关内容。
关键词检索:确保精确匹配,不会遗漏关键术语。
RRF融合排序:将上述两种检索结果进行智能融合与重排序,取长补短。
多查询扩展:AI会自动将你的问题扩展成多个相关问法,以覆盖更多可能性。这套组合拳确保了gBrain的检索既懂“言外之意”,又不失“精准打击”,有效避免了纯向量检索可能带来的信息稀释问题。
3. “梦循环”(Dream Cycle):自动化的知识整理
gBrain不仅仅是一个被动的存储库,它还有一个主动整理的“梦循环”机制。在后台,Agent会定期(例如每晚)自动扫描你当天的对话、邮件、会议记录等新数据,识别出新的实体(人名、公司、概念),并将相关信息自动归档、更新到对应的知识页面中。这就像人类在睡眠时大脑会整理白天的记忆一样,gBrain也在你休息时,默默地为你和你的AI整理知识库,使其不断成长。
如何部署与上手:三条路径任你选
GBrain的设计哲学是“Thin Harness, Fat Skill”,即运行时尽可能轻量,将智能逻辑封装在“技能”(Skill)文件中。这也使得它的部署非常灵活,提供了三种主流路径。
1. 让Agent自动安装(最推荐)
如果你已经在使用OpenClaw或Hermes Agent,这是最简单的方式。你只需将一段特定的指令发送给Agent,它就会自动完成克隆仓库、安装依赖、配置集成等所有步骤。你只需要在过程中提供必要的API密钥,大约30分钟即可拥有一个功能完备的“大脑”。
2. 本地命令行体验(最轻量)
如果你只想先在本地体验一下,可以通过命令行快速启动。GBrain默认使用PGLite(一个嵌入式的PostgreSQL),无需任何数据库配置,零门槛上手。
操作步骤:
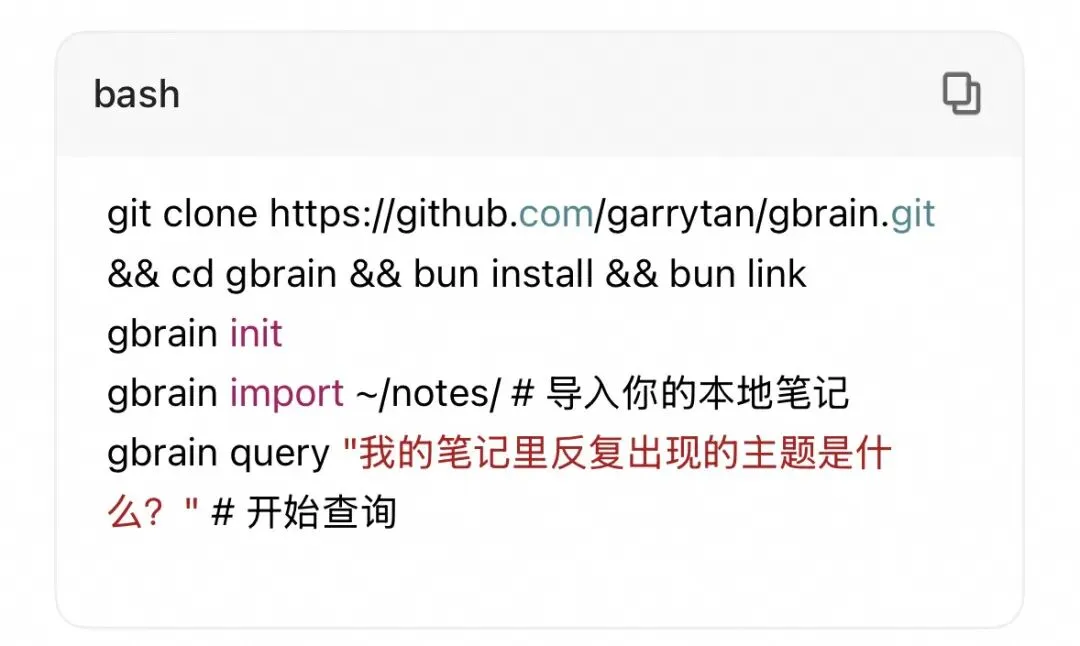
当你的知识库规模扩大后,还可以通过一条命令轻松迁移到Supabase等云端数据库。
3. 接入主流AI工具(最实用)
GBrain原生支持MCP(Model Context Protocol)协议,这意味着它可以作为一个MCP服务器,轻松接入Claude Code、Cursor、Windsurf等主流AI编程工具。接入后,你在写代码时,AI就能直接读取你“大脑”里的信息,比如之前关于某个架构的讨论、某位同事的偏好等,让上下文理解能力得到质的飞跃。
总结与展望:不止于代码的启发GBrain不仅仅是一个开源项目,它更是一种设计哲学的体现。它告诉我们,在AI时代,模型能力是基础,但真正构成壁垒的是属于你个人的、不可替代的私有上下文(Context)。通过GBrain,Garry Tan将他自己管理海量知识、人脉和项目的“操作系统”开源了出来。它提供了一个强大的参考,让我们看到如何构建一个能够持续学习、自我维护的AI记忆系统。对于开发者、创业者以及任何知识工作者而言,GBrain无疑是构建个人“第二大脑”、释放AI杠杆潜力的强大工具包。它或许不是完美的,但其背后的思路和实践,值得我们深入学习和借鉴。
