 夜雨聆风
夜雨聆风当前AI计算与科学计算发展势头迅猛,海量数据高速交互已成为常态,传统网络架构的性能短板越来越明显,根本撑不起超大规模AI集群的高效运行。作为英伟达官方经销商,今天我们就为大家介绍一款能打破这一困境的核心网络设备——NVIDIA Spectrum SN5610交换机。它不只是简单的硬件升级,更是专门针对数据中心、科学计算和人工智能场景打造的革新之作,更是推动下一代AI基础设施落地的核心动力。

1
突破传统:Spectrum-X以太网,兼顾性能与生态的双重革新
NVIDIA Spectrum-X以太网的核心亮点,就是把InfiniBand的核心能力无缝融入以太网,有效带宽能达到95%左右,几乎和InfiniBand持平,同时还能完美适配现有以太网生态,支持原生多租户隔离。
结合我们多年的行业实操经验,我们建议选型时:大家要综合考虑自身集群规模、现有基础设施情况、成本预算以及多租户需求。目前大多数客户都会选择混合部署模式——用InfiniBand支撑核心训练集群,靠NVIDIA Spectrum-X承载多租户云和推理场景,这样既能保证性能,又能兼顾生态。

2
生态主导:从RoCEv2协议到全场景布局,NVIDIA的核心优势
RoCEv2是目前AI数据中心里常用的低延迟RDMA协议(由IBTA标准化),它能发展到今天,离不开Mellanox的开创性贡献——是他们率先推出了完整的硬件实现方案(也就是ConnectX系列)。2019年Mellanox被NVIDIA收购后,凭借ConnectX/BlueField网卡,NVIDIA快速占据了RoCEv2部署市场的绝大部分份额,成为了这个领域实际意义上的标准制定者。
在此基础上,NVIDIA通过Spectrum-X,把InfiniBand的传输层技术引入以太网,专门针对AI场景优化了RoCEv2协议,最终实现了显著的性能提升:AI训练有效带宽提高1.6倍,存储读带宽提升48%,存储写带宽提升41%。目前,Meta、Oracle、xAI、Israel-1超算等行业头部企业,都已经大规模部署了这套方案,这也说明NVIDIA已经完成了从协议支持到生态主导的完整布局,实力得到了全球顶尖企业的认可。
3
实践标杆:Meta大规模AI集群,见证SN5610的实战实力
Meta作为AI领域的标杆企业,为了满足Llama 3等千亿参数模型的训练需求,搭建了基于RoCEv2的大规模后端网络,其AI集群规模达到了24K H100 GPU。这么庞大的集群要想高效运转,离不开科学的网络架构设计,更离不开高性能核心设备的支撑。
Meta的网络架构,已经从早期的星型拓扑升级为多级CLOS架构,通过RTSW、CTSW、ATSW等交换机,实现了机架内和跨机架的高速互联,稳稳支撑起排名、推荐、自然语言处理等生产级分布式训练任务。值得关注的是,Meta专门为分布式AI训练搭建了独立的后端网络,不用依赖数据中心的其他网络,可自主发展、运行和扩展,能最大限度保障训练任务的稳定和高效。
Meta的网络架构,已经从早期的星型拓扑升级为多级CLOS架构,通过RTSW、CTSW、ATSW等交换机,实现了机架内和跨机架的高速互联,稳稳支撑起排名、推荐、自然语言处理等生产级分布式训练任务。值得关注的是,Meta专门为分布式AI训练搭建了独立的后端网络,不用依赖数据中心的其他网络,可自主发展、运行和扩展,能最大限度保障训练任务的稳定和高效。
训练集群依赖于两个独立的网络:前端(FE)网络用于数据摄取、检查点和日志记录等任务,后端(BE)网络用于训练,如下图所示:
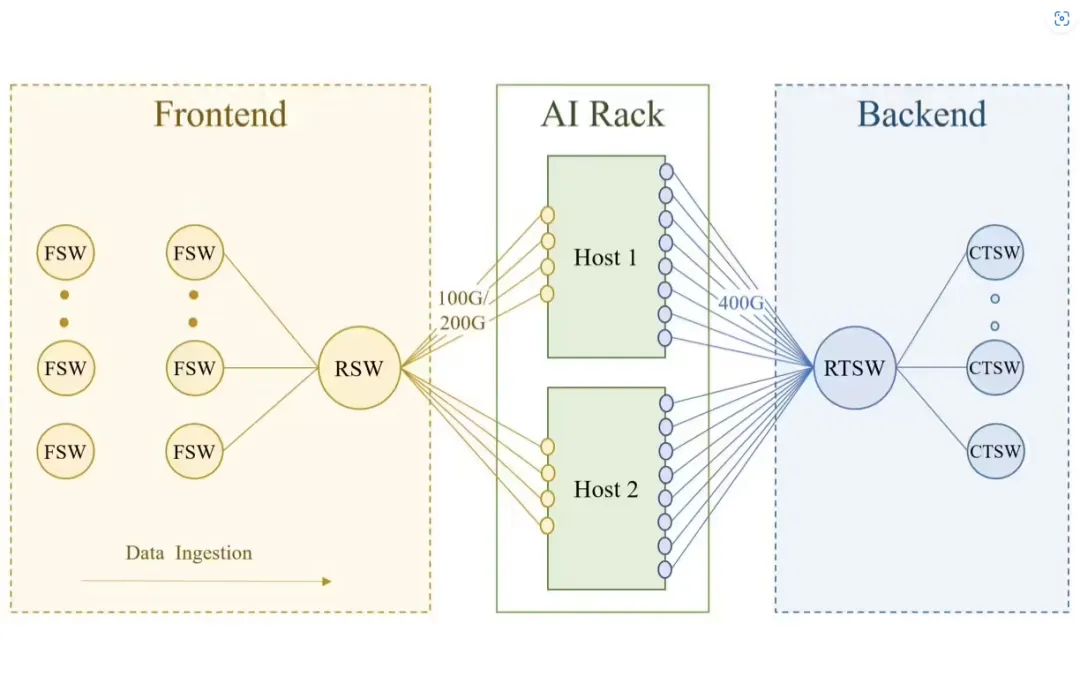
训练机架连接到数据中心网络的 FE 和 BE。FE 的网络层次包括机架交换机 (RSW)、结构交换机(FSW)等,其中包含存储仓库,为 GPU 提供训练工作负载所需的输入数据。
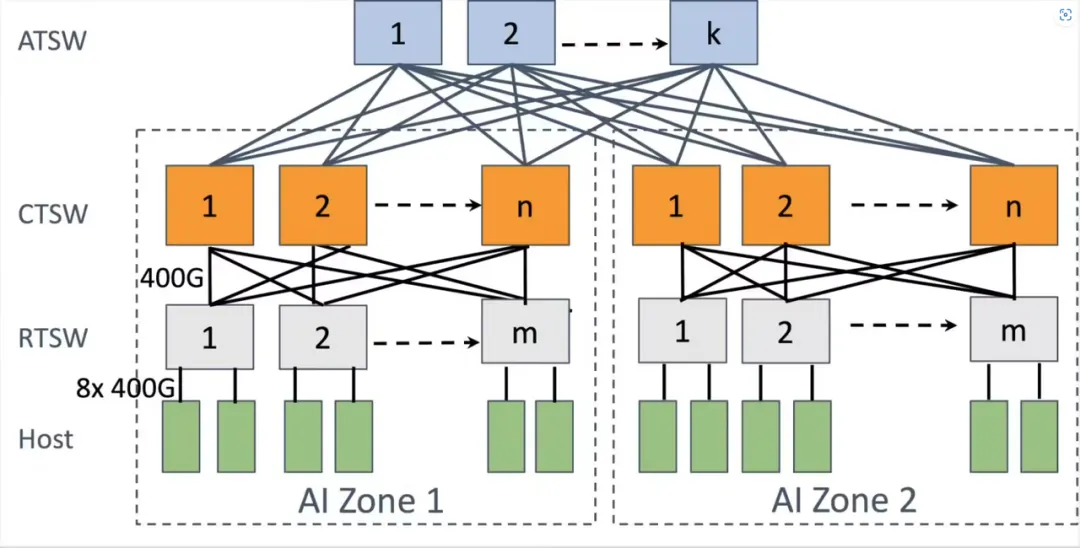
为了应对 LLM 模型训练对 GPU 规模的需求,Meta 设计了聚合训练交换机(ATSW)层,将多个 AI 区域互连起来。此外,Meta 还优化路由、拥塞控制等方面,以提升网络性能。
4
核心解析:Spectrum SN5610,专为AI工作负载而生
NVIDIA Spectrum SN5610交换机的核心竞争力,就在于它搭载的Spectrum-4 ASIC 51.2 Tbps芯片。正是这款芯片,让SN5610拥有了前所未有的性能:它配备64个800 GbE端口,能无缝对接云端和GPU计算资源,51.2 Tbps的总吞吐量可以确保数据无阻塞传输,单台交换机就能满足超大规模AI集群的互联需求,大大简化企业的网络架构,降低部署和维护成本。

和传统以太网交换机相比,SN5610最大的不同就是完全围绕AI工作负载设计,它搭载了NVIDIA Spectrum-X网络平台,通过零接触加速的RDMA over Converged Ethernet技术,为横向扩展的分布式应用提供超高吞吐量和低延迟连接。这一创新,成功把InfiniBand级的性能带到了以太网环境中,让企业能够轻松扩展到数十万颗GPU的规模,还不会损失任何性能,完全适配AI训练、科学计算等高性能需求场景。
5
生态协同:软硬件联动,释放极致AI性能
一款高性能交换机要想发挥最大作用,离不开完整的生态配合。当Spectrum SN5610与NVIDIA BlueField-3 SuperNIC或ConnectX-8 SuperNIC配合使用时,能为GPU服务器之间提供高达800 Gb/s的RoCE网络连接,让AI性能提升1.6倍,真正实现“1+1>2”的协同效果。

其中,NVIDIA® BlueField®-3网络平台专门用于加速数据中心基础设施工作负载,既能支持以太网连接,也能支持InfiniBand连接,速度最高可达400 Gb/s(千兆比特每秒)。这个平台整合了强大的计算能力和软件定义的硬件加速器,覆盖网络、存储、网络安全等多个领域,而且所有功能都能通过NVIDIA DOCA™软件框架完全编程。借助这个平台,BlueField数据处理单元(DPU)和BlueField SuperNIC™网卡彻底改变了传统计算环境,将其升级为安全、高性能、高效且可持续的数据中心,能够轻松应对各种规模、各类类型的工作负载。
6
核心优势总结:面向未来的AI网络选择
Spectrum SN5610的核心优势,在于交换机、SuperNIC和软件栈三者的协同联动,能够实现自适应路由、拥塞控制、乱序重排等高级功能,为AI训练搭建起高效、稳定、易管理的网络环境,彻底解决传统网络的性能瓶颈问题。

NVIDIA BlueField-3 SuperNIC
更值得一提的是,SN5610完全支持开源SONiC网络操作系统,同时还支持高度定制化。这种开放性,能让企业在享受最佳性能的同时,保持网络架构的灵活性和未来适配性,不用为技术迭代带来的兼容性问题发愁。
在AI驱动的新计算时代,Spectrum SN5610凭借突破性的性能、AI专属优化特性以及完整的生态集成,为下一代数据中心提供了真正面向未来的网络基础设施。作为英伟达官方经销商,我们也会全力为企业提供专业的设备选型、部署和运维服务,帮助大家搭建高效、稳定的AI计算平台。
对于正在搭建或升级AI计算平台的企业来说,选择Spectrum SN5610,不只是网络性能的一次飞跃,更是实现AI投资效益最大化的战略选择——携手正阳恒卓,一起解锁下一代AI算力基础设施的无限可能!

点击跳转京东小程序
注:与 NVIDIA 产品相关的图片或视频(完整或部分)的版权均归 NVIDIA Corporation 所有。
