 夜雨聆风
夜雨聆风一位独立开发者发布了
SmallCode,一个专门为本地小模型设计的开源编码工具。 用 4B 参数的 Gemma 4 跑出 87/100 的基准成绩,超过 14B 模型跑 OpenCode 的约 75 分。
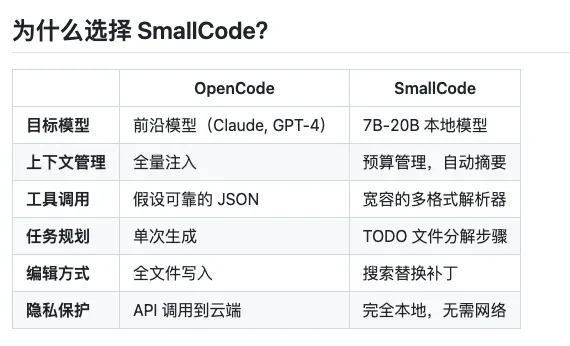
如果你在自己电脑上跑过 Llama、Qwen、Gemma 这些开源模型,大概有过类似体验:日常聊天还行,让它帮忙写代码就掉链子。工具调不对、上下文一长就忘事、走几步就崩。
最近一个叫 SmallCode 的开源项目,把这件事重新做了一遍。
作者账号是 Doorman11991。他自己试了一圈现有的编码工具,发现一个共同问题:它们都默认你在用 GPT-5、Claude 4 这种顶级模型。一旦换成本地跑的小模型,几乎没法用。
于是他自己写了一个。

跑分结果:87 分 vs 75 分
按作者公开的基准测试结果:
模型小了三倍多,分数反而更高。
瓶颈往往在工具层,模型大小本身反而排在次要位置。
它做了什么
01丨复合工具,少调几次
小模型连续调用工具特别容易出错。SmallCode 把多个常见操作合并成一个调用,让模型一次说清意图,不用来回点。
02丨改进循环,写完就查
模型生成代码之后,系统立刻去编译或检查一遍。错误信息自动喂回模型让它自己改。改完再查,直到通过。
03丨失败就拆
一个任务连续失败两次,自动拆成更小的子任务再试一遍。给模型台阶下,也降低单步的工作量。
04丨本地搞不定,叫云端救兵
可以配置:本地模型卡住的时候,把这一步任务升级给云端的 Claude、GPT 或 DeepSeek。需要自己填 API Key,session 级别有花费上限,平时不会偷偷烧钱。
05丨Token 预算管理
每次工具返回的内容做了 4K 字符截断,旧消息走语义压缩,不直接丢掉。让 8K 上下文的小模型也能干完一个完整长任务。
另外有个细节:解析模型的工具调用时,JSON、YAML、XML、纯文本都认,参数名或类型写错的会尝试自动修。对输出格式不严谨的小模型特别友好。
工具目标人群
过去的主流叙事是:模型越大越好,API 越贵越值。SmallCode 给出了另一种答案。
一类是想在自己电脑上跑 AI 写代码的人。门槛在快速变低,一张消费级显卡加 Ollama 或 LM Studio,再加 SmallCode 这样的工具,就能跑起来。
另一类是对代码不出本地有要求的场景。代码可以全程不上传任何云服务,对法律、医疗、企业内部工具开发都算是有意义的选择。
项目是开源的,npm 一行命令就能装。作者也在社区里持续更新。
