 夜雨聆风
夜雨聆风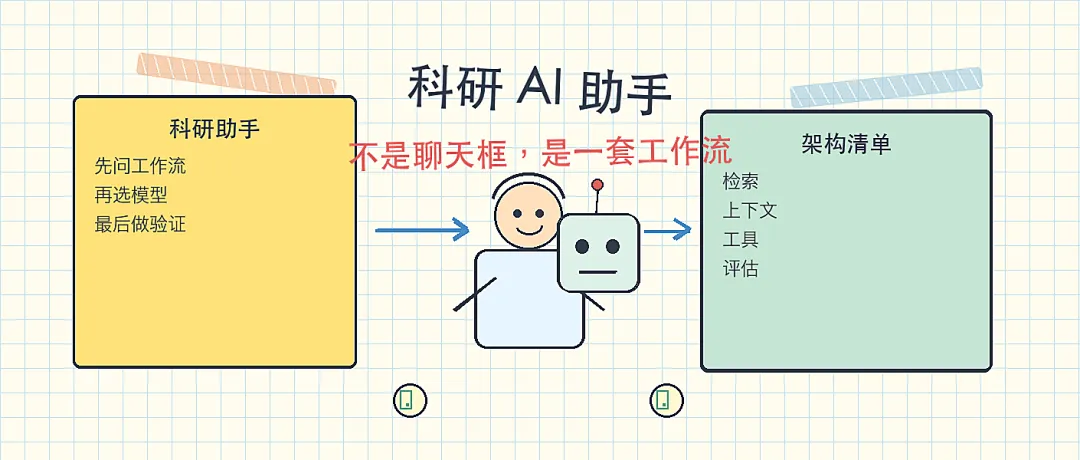
很多人现在都想做 AI 助手。
在科研里,这个愿望更强。最好它能查论文、读公式、跑代码、整理实验记录,还能帮你把一段混乱的想法写成清楚的初稿。
但真正难的地方,不是把问题丢给一个更强的大模型。难的是把它放进科研流程里,让它少编、少漏、可追溯、可复查。
换句话说,科研 AI 助手不是一个聪明聊天框。它更像一套实验台。
做科研助手,第一步不是问用哪个模型。
第一步要问:你到底想让它帮哪一段科研流程?
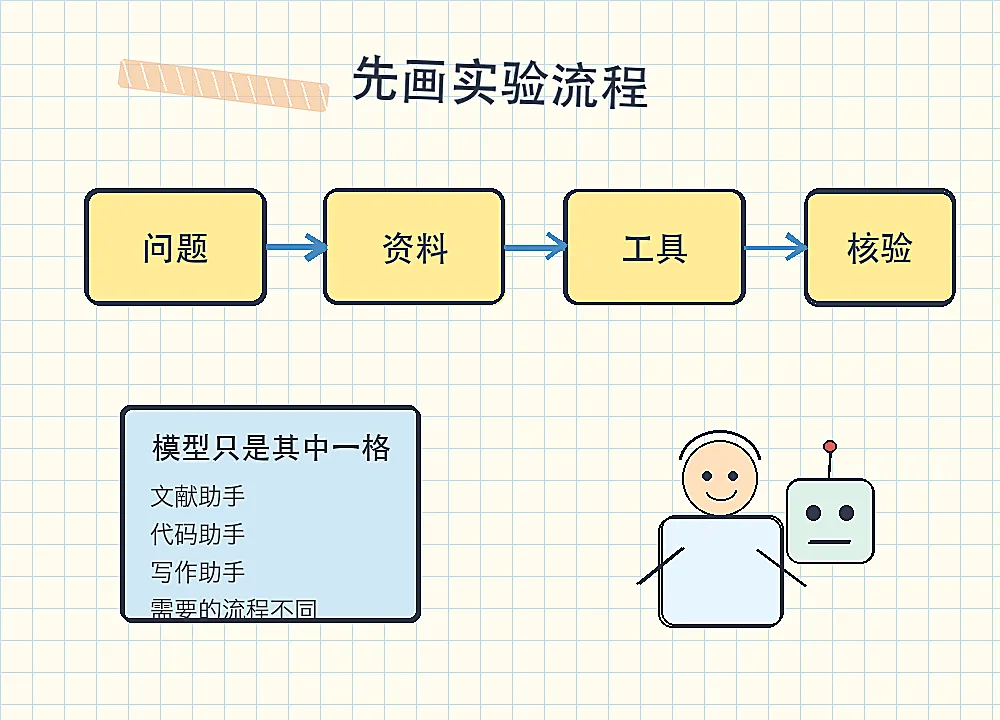
如果是文献助手,它要会找资料、比来源、保留引用。它不能只给一段顺口的总结。
如果是代码助手,它要能读文件、运行测试、看到报错,再修改代码。它不能只停在“建议你检查一下变量名”。
如果是写作助手,它要知道文章的论点、证据、读者和期刊风格。它不能把一堆材料压成漂亮废话。
模型只是其中一层。科研问题真正需要的是流程设计。
上下文是临时工作台
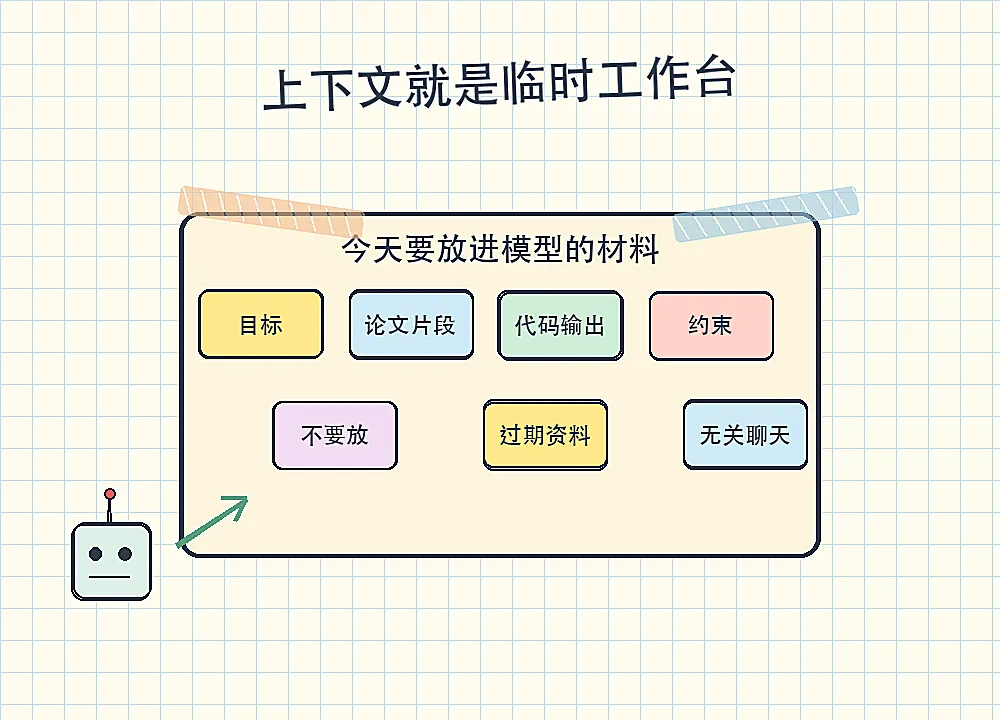
大语言模型,简单说,就是根据上下文继续写下去的模型。
这里的“上下文”,可以理解成你临时摊在桌上的材料。你把正确的论文片段、数据表、代码输出和限制条件放上去,它才有机会做对。
你把无关聊天、过期资料、没有来源的结论都塞进去,它就会被噪声带偏。
很多 AI 系统的问题,其实不是模型不聪明,而是工作台太乱。
好的科研助手会先整理上下文:
• 当前任务是什么 • 哪些资料是证据 • 哪些信息已经过期 • 哪些假设不能越界 • 输出需要什么格式
这一步很朴素,却决定了后面大部分质量。
检索常常比微调更重要
很多人一上来就想微调模型。
微调,就是拿一批样本继续训练模型,让它更像某种风格,或更熟悉某类任务。它有用,但不是科研助手的第一解。
科研里更常见的问题是:模型不知道你的最新论文、项目笔记、实验记录和本地代码。
这时更该先做检索。
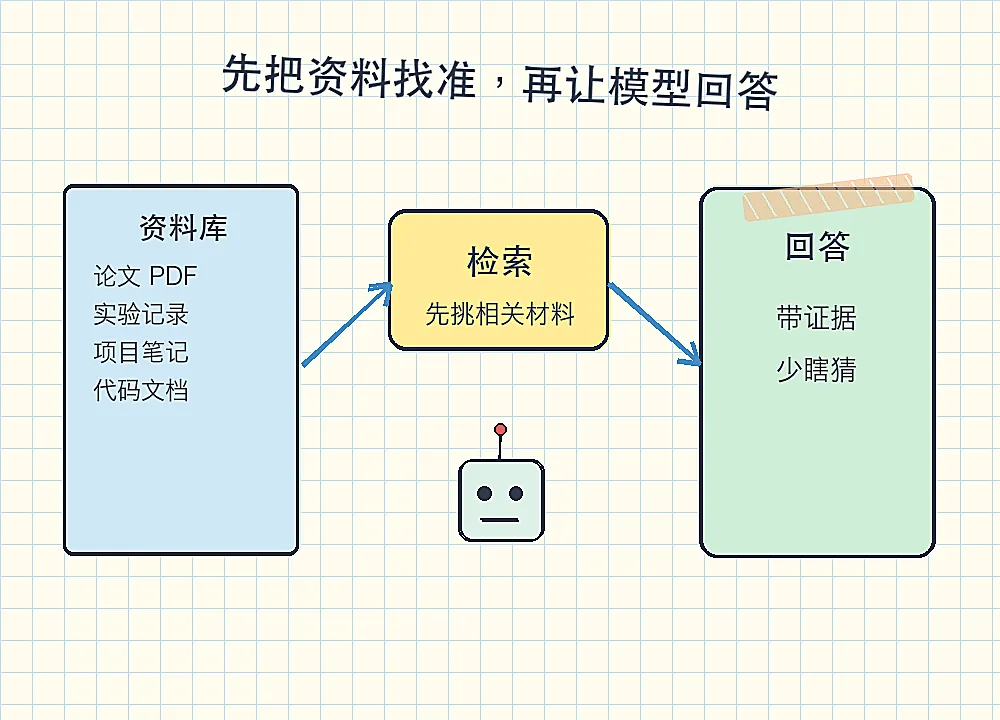
检索增强生成,常叫 RAG。可以把它理解成:先从资料库里找出相关材料,再把这些材料交给模型回答。
一个基本的检索系统通常包含几件事:
• 把论文和笔记切成小块 • 把文字变成便于搜索的数字表示 • 找出最相关的片段 • 再按质量和相关性重排 • 最后要求模型引用这些片段回答
如果检索层很弱,再强的模型也会答偏。它可能写得很流畅,但证据并不存在。
提示词其实是系统设计
提示词不是咒语。
在科研助手里,提示词更像实验说明书。它要告诉模型:你扮演什么角色,先做哪一步,能用哪些工具,遇到不确定时怎么说,最后用什么格式交付。
一个可靠的提示系统,往往不是一条大提示词。
它可能分成几段:
• 先判断任务类型 • 再检索资料 • 再提取证据 • 再写摘要 • 最后检查引用和结论是否一致
这样做的好处是,每一步都能被检查。
如果模型直接给出一篇完整回答,你很难知道它错在哪里。如果流程拆开,你能看到是检索错了、证据选错了,还是最后表达过头了。
工具和护栏要一起设计
科研助手迟早会用工具。
它可能要搜索网页,读 PDF,运行 Python,检查 LaTeX,比较两份结果,甚至帮你改项目里的文件。
这类能分步骤调用工具的程序,常被叫作智能体。名字听起来很高级,本质上就是“模型加工具加流程控制”。
工具越多,护栏越重要。
比如:
• 什么文件能读 • 什么命令能运行 • 失败后最多重试几次 • 多久没有进展就停止 • 哪些动作必须人工确认 • 结果怎样才算通过检查
没有护栏的智能体,很容易空转。它可能反复搜索、反复改代码、反复生成看似合理的解释。科研里最怕这种情况,因为它会消耗时间,还会把错误包装得更像真的。
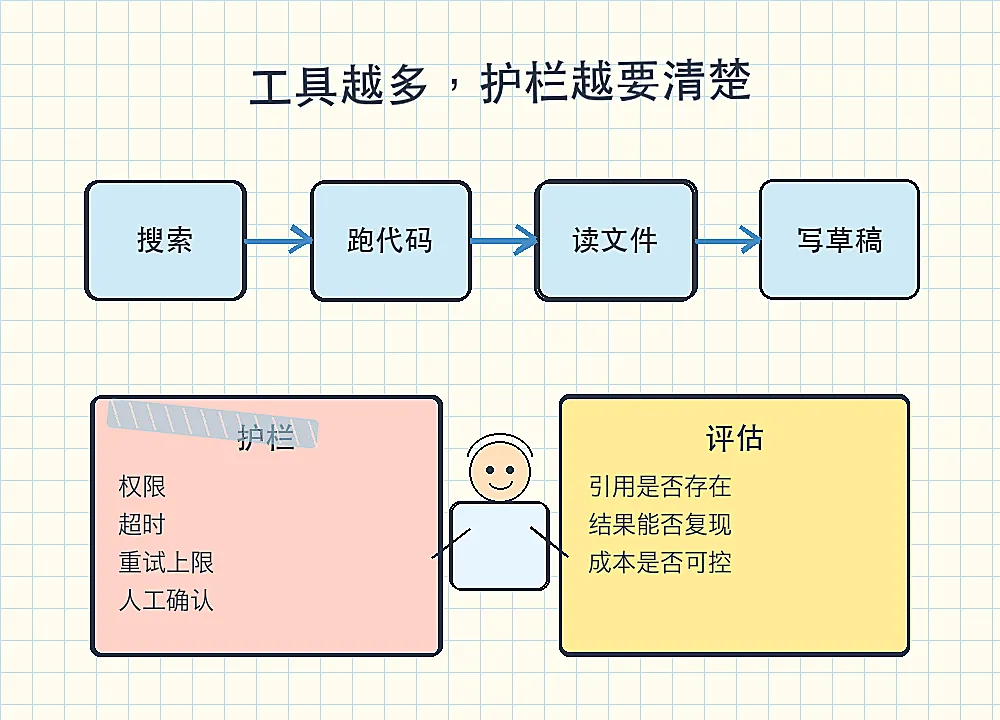
评估是质量控制
科研助手不能只靠“看起来不错”来判断。
你需要评估。
评估就是给它准备一批有答案的问题,反复测试它。像实验仪器校准一样,先知道标准答案,再看它偏到哪里。
可以测试这些问题:
• 引用的论文是否真实存在 • 摘要是否漏掉关键限制 • 公式解释是否改变了原意 • 代码修改后测试是否通过 • 同一个问题多问几次是否稳定 • 每次回答要花多少时间和成本
成本也属于架构问题。
不是每一步都要调用最强模型。简单分类可以用小模型,重复资料可以缓存,长文可以先压缩,检索可以先筛一遍再精排。这样系统才可能长期使用。
一个实用判断表
如果你要做一个科研 AI 助手,可以先问五个问题:
第一,它服务哪条科研流程?
第二,它的证据从哪里来?
第三,哪些内容必须进入上下文?
第四,它可以调用哪些工具,边界在哪里?
第五,怎样证明它这次没有胡说?
这五个问题答不清,模型再强也只能做演示。
答清了,一个普通模型也能变成可靠系统的一部分。
一句话收住
科研 AI 助手的核心不是“换一个更聪明的模型”,而是把检索、上下文、工具、记忆、护栏和评估放进同一条可复查的工作流。
