【论文写作工具】用AI跑科研代码总是报错?有人用这个GitHub开源Skill调通了单细胞和分子对接在日常科研中,越来越多研究生开始使用Cursor、Claude Code或 Gemini来辅助编写代码、处理数据。在处理通用编程任务时,AI的表现确实很惊艳。但一旦进入到垂直的科研领域。比如调用Scanpy做单细胞分析,或者用RDKit处理化学分子式,大模型就开始高频报错。一、通用大模型的科研痛点
科研常用的Python包(如 OpenMM、MDAnalysis 等)相对小众且更新频繁。通用大模型因为缺乏最新的,结构化的专业文档支持,生成的代码经常“对错参半”,导致debug的时间成本甚至超过了自己手写。做课题要跨越PubChem、UniProt、ClinicalTrials等多个平台。手动查阅资料、频繁切换、编写爬虫或调用各自的API,耗费了大量重复性的精力。
3. 未发表数据隐私
实验室的核心实验数据、临床样本信息,直接上传到云端大模型存在学术泄露风险,这也让许多同学在研究中对AI工具望而却步。
二、scientific-agent-skills科研技能包
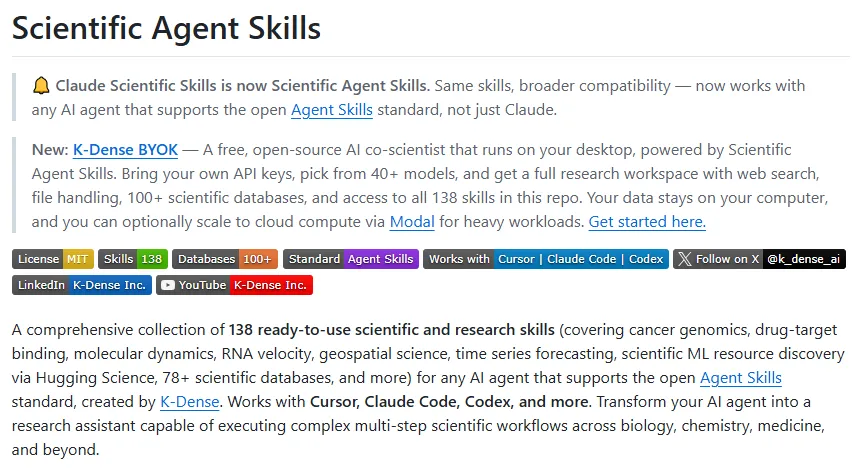
GitHub上最近出现了一个值得关注的开源项目:由K-Dense-AI团队开发的scientific-agent-skills。它不是一个全新的大模型,而是一套专为科研AI助理(Agent)打造的“标准化垂直技能包”。这个项目就像是为 Cursor、Claude Code、Gemini 等AI编程工具提供了一本“科研专属操作手册”。目前项目已包含135个即插即用的科研技能。针对生信同学头疼的工具链,项目集成了Scanpy、Biopython以及Squidpy(空间转录组学分析库)。无论是做单细胞RNA测序数据的质量控制、降维聚类,还是处理复杂的基因序列、空间转录组数据可视化,AI都能根据新的API规范准确输出代码,不再盲目瞎编过时的参数。对于化学和药学方向,项目内置了RDKit(化学信息学核心库)、OpenMM(分子动力学模拟)以及MDAnalysis。你可以让AI帮你编写分子指纹提取、相似度计算的代码,甚至自动生成分子动力学轨迹分析的脚本。因为配备了详尽的库文档支持,AI写出的模拟配置文件可以直接运行,省去了反复修改报错的痛苦。找数据、拼表格是科研搬砖的日常。该项目直接打通了 78 个公共科学数据库,包括生医领域的COSMIC、UniProt,物理经济领域的FRED,以及专利数据库USPTO等,间接覆盖超100个数据源。你不需要再去一个个网站手动搜索、下载,只需用自然语言命令AI,它就能自动完成多平台的跨库检索、数据抽取与清洗。除了垂直学科工具,项目还强化了PyTorch、SciPy以及Scikit-learn在科学计算场景下的表现。无论是构建一个预测分子性质的图神经网络(GNN),还是对实验曲线进行复杂的非线性拟合,AI助理都能直接调用符合科研规范的算法模板。工具链接:https://github.com/K-Dense-AI/scientific-agent-skills

 夜雨聆风
夜雨聆风