 夜雨聆风
夜雨聆风你让 Agent 写了一份架构方案,打开一看 300 行 Markdown。扫了两眼,关了。
不是你懒。是这个格式在超过 100 行之后,信息获取效率断崖式下跌。标题层级嵌套三四层,代码块和正文混在一起,表格一旦超过五列就开始折行。你很难在 30 秒内抓住重点,更别说带着这份文档去跟团队同步了。
Code review 的 PR description 也是一样。Agent 帮你生成的变更说明,你真的逐行读了吗?大概率也是扫一眼 merge 了事。
这不是某个人的问题。Anthropic Claude Code 团队的成员 Thariq Shihipar 前两天公开承认了同样的事 — 他发现自己不再真正阅读超过 100 行的 Markdown 文件,团队里也没人愿意读。
他的解决方案出人意料地简单,但影响深远 — 不再用 Markdown,改用 HTML。
Markdown 的优势正在失效,因为前提变了
先说清楚,Markdown 不是不好。它轻量、可编辑、纯文本可 diff、几乎所有平台都能渲染。这些优势在过去十年让它成为技术文档的事实标准。
但这些优势建立在一个前提上 — 人是主要编辑者。
Markdown 为「人写人读」设计。写的人用简单的语法标记格式,读的人用渲染器看到排版。这个循环在人类主导内容生产时运转良好。
问题在于,Agent 时代这个前提正在松动。
现在的工作流变成了 Agent 写方案、Agent 修改、人只做审核。当人不再手动编辑这些文件,Markdown 的核心优势 — 轻量可编辑 — 就弱化了。你不会去改那个 300 行方案里的语法错误,你会直接让 Agent 重写。
与此同时,Agent 输出的信息量在暴增。一份架构方案动辄包含模块关系、数据流、时序图、API 定义、权衡分析。Markdown 能表达这些吗?勉强能 — 用 ASCII 画架构图,用 Unicode 字符猜颜色,用嵌套列表模拟树状结构。
但这不是在用 Markdown 的优势,而是在用它的劣势。模型在 Markdown 里做的其实是降级表达 — 把本可以直观展示的信息压缩成了纯文本。
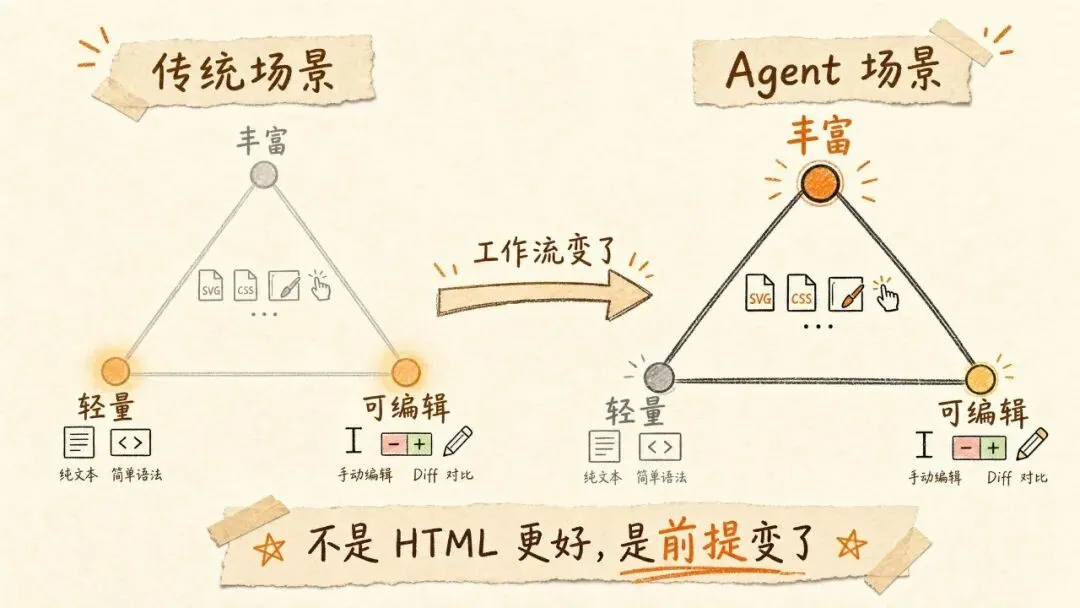
这里面可以抽象出一个「格式选型三角」来理清思路。轻量、丰富、可编辑,三个属性构成三角形,传统场景下我们选 Markdown 因为轻量和可编辑最重要。但 Agent 场景下,权重变了 — 丰富度和可读性的优先级大幅上升,可编辑性下降。
不是 HTML 更好,是工作流变了。
HTML 在 Agent 场景下赢在三个层次
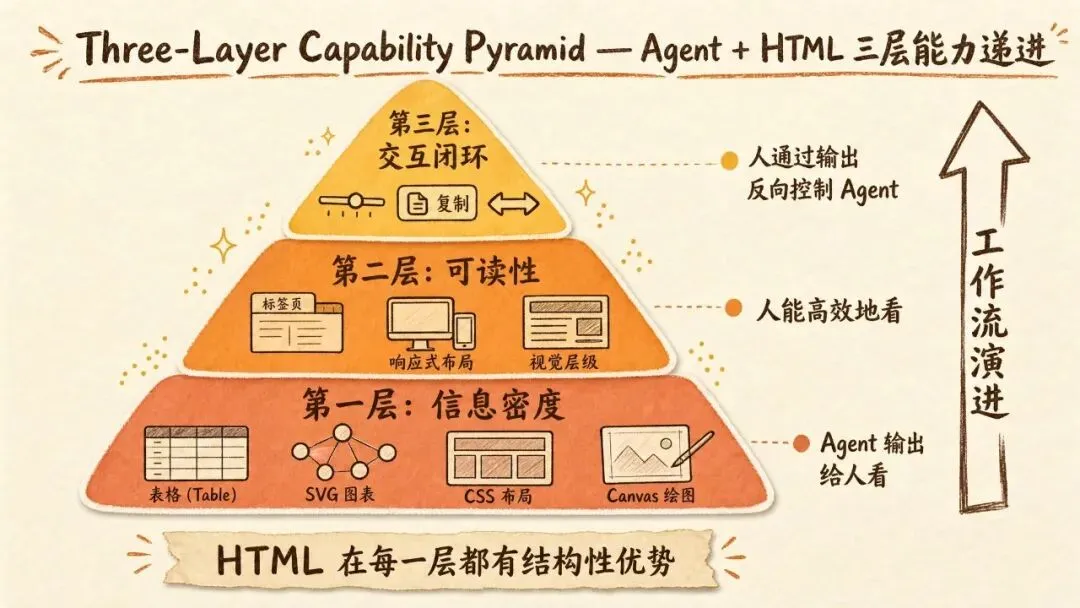
HTML 不是一个简单的「比 Markdown 多几个功能」。在 Agent 输出这个特定场景下,它的优势是分层递进的。
第一层,信息密度。
HTML 原生支持表格、SVG 矢量图、CSS 样式、Canvas 绘图、绝对定位布局、图片嵌入。这些东西在 Markdown 里要么不支持,要么只能降级表达。
一个真实的例子 — 你让 Agent 分析两个系统的架构差异。Markdown 版本只能用 ASCII 画两棵树,然后用文字描述区别。HTML 版本可以直接画两张 SVG 架构图,差异部分高亮,鼠标悬停显示详细说明。信息获取效率不在一个量级。
这还没完。HTML 可以在同一份文档里同时展示多种信息形态 — 左边是流程图,右边是对应的代码片段,下方是参数表格。Markdown 只能线性排列,读到后面忘了前面。
第二层,可读性。
同样 300 行内容,HTML 版本能让人真正读完。
原因很简单 — HTML 可以做 tab 折叠,把次要信息收起来;可以做视觉层次,让读者第一眼就看到重点;可以做响应式布局,在手机上也能舒适阅读。
Markdown 呢?300 行就是 300 行,你只能从上往下看。想跳到某个章节,全靠 Ctrl+F。
Thariq 提到一个细节让我很有共鸣 — 他说用 HTML 写的 spec、报告和 PR 说明,「有人真正去读的概率高得多」。这听起来是小事,但在团队协作中,一份没人读的文档等于不存在。
第三层,交互闭环。
这是我觉得最有价值的部分。
Agent 生成一个 HTML 文件,里面带 slider 调参、拖拽排序、开关切换。你调完参数,点「copy as prompt」,把调整后的配置粘贴回 Agent 的输入框,Agent 据此修改方案。
这不再是一个静态文档,而是一个你与 Agent 之间的交互界面。
Thariq 把这种模式叫「throwaway editor」— 一次性编辑器。不是要做一个产品或通用工具,而是针对当前任务生成一个专用界面。比如你要重新排列 30 个 ticket 的优先级,让 Agent 生成一个可拖拽的看板,排完点「导出 Markdown」把结果贴回去。
这种闭环设计让「人在 loop 中」这件事变得真正可行 — 不是被动地阅读 Agent 的输出,而是主动地调整它的方向。
三个层次的递进恰好对应 Agent 工作流的演进。第一层是「Agent 输出给人看」,第二层是「人能高效地看」,第三层是「人通过输出反向控制 Agent」。HTML 在每个层次都有结构性优势。
数据层面也有支撑。Thariq 提到 Opus 4.7 的上下文窗口已经到 1M token,HTML 比 Markdown 多消耗的 token 在这个尺度下几乎可以忽略。格式选型的天平因此进一步倾斜。
三种 Agent + HTML 工作模式
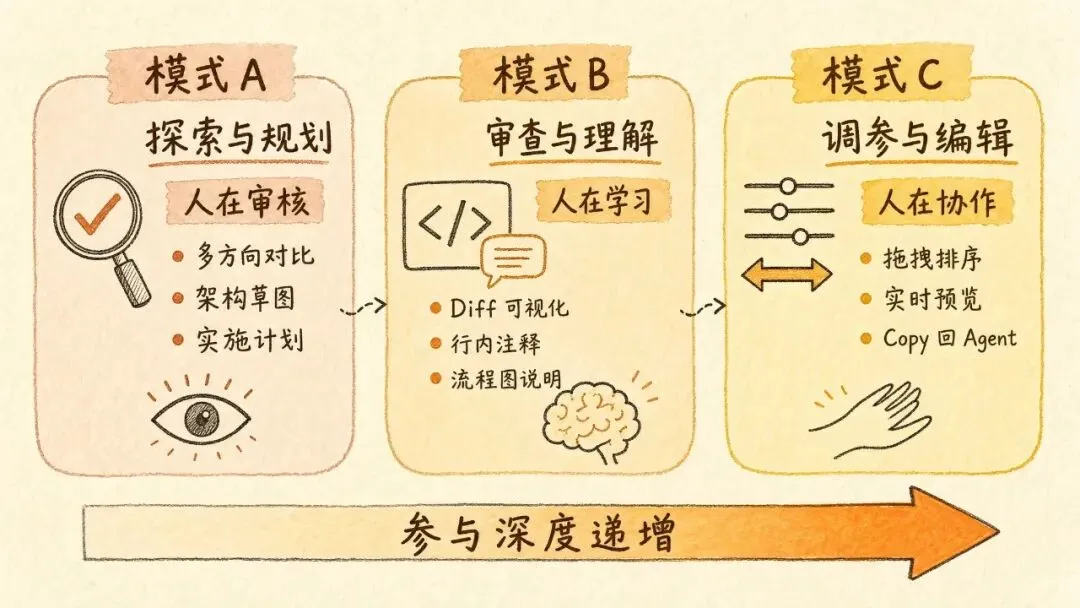
从 Anthropic 内部实践和社区讨论中,可以提炼出三种有代表性的工作模式。不是原文五个用例的简单翻译,而是按「人在 loop 中的参与深度」重新归类。
模式 A — 探索与规划,人在审核
当你面对一个模糊的问题时,不要让 Agent 生成一份 Markdown plan。让它生成一组 HTML 文件。
具体做法是先让 Agent 探索多个方向,每个方向一个 HTML 页面,里面包含方案概述、架构草图、关键 trade-off。这些页面可以并排打开对比,比在一份 Markdown 里来回滚动高效得多。
选定方向后,再让 Agent 生成一份完整的 implementation plan — 同样是 HTML,包含 mockup、数据流图、需要 review 的关键代码片段。这种规划的密度和可读性,Markdown 根本做不到。
Prompt 模板 — 「我不确定这个功能该怎么做,帮我生成 3 个不同方向的探索方案,每个方案用单独的 HTML 文件,包含架构图、关键 trade-off 和适用场景。排列在一个 HTML 文件里方便我对比。」
这个模式的核心是人做判断,Agent 做表达。HTML 让 Agent 的表达更丰富,让你的判断更准确。
模式 B — 审查与理解,人在学习
代码审查是 Markdown 的重灾区。PR description 里的变更说明,你真的逐行读了吗?
让 Agent 生成一个 HTML 文件来描述 PR — diff 直接渲染成带颜色标注的对比视图,关键变更旁边加行内注释,逻辑复杂的部分配流程图说明。Thariq 的做法是让 Agent 按 severity 分级,用不同颜色标注发现的问题。
更广义地说,任何需要「理解一段代码/系统」的场景都适用。比如你不理解团队的限流器怎么工作,让 Agent 读代码、生成一份 HTML explainer — 顶部是 token bucket 流程图,中间是关键代码片段加注释,底部是「容易踩的坑」。一份文档读一遍就能理解。
Prompt 模板 — 「帮我 review 这个 PR,生成一份 HTML 文件描述变更内容。我对流控逻辑不太熟,重点展开那部分。渲染 diff 并加行内注释,按严重程度颜色标注。」
这个模式的核心是把「理解」从一个主动的脑力劳动变成一个被动的阅读体验。好的 HTML explainer 让你不费力气就能建立理解。
模式 C — 调参与编辑,人在协作
这是最前沿的模式,也是交互闭环的实际应用。
你有一个 feature flag 配置需要编辑,让 Agent 生成一个表单编辑器 — flag 按功能分组,依赖关系可视化,开启一个前置条件未满足的 flag 会弹出警告。编辑完点「copy diff」,把改动粘贴回 Agent。
或者你在调一个 system prompt,让 Agent 生成一个左右分栏的编辑器 — 左边是可编辑的 prompt,变量位置高亮,右边是三个示例输入实时渲染。底部是 token 计数器和 copy 按钮。
这些编辑器都是一次性的,用完就扔。但它们解决了一个真实问题 — 有些东西用纯文本很难描述(颜色、缓动曲线、拖拽顺序、开关组合),但用界面表达一目了然。
Prompt 模板 — 「帮我生成一个 HTML 编辑器来调优这个 system prompt。左边可编辑 prompt,变量高亮,右边三个示例输入实时渲染。加 token 计数和 copy 按钮。」
这个模式的核心是人不只是在读 Agent 的输出,而是在通过输出反向控制 Agent。HTML 在这里扮演的不是文档角色,而是界面角色。
别急着全转 HTML,先看清代价
前面的分析可能会让人觉得 HTML 全面碾压 Markdown,但实际上没那么简单。每一个技术选型都有代价,HTML 的代价还不小。
Token 消耗更大。 一份同等内容的 HTML 文件通常比 Markdown 大 2-5 倍。虽然 1M token 的上下文窗口让这个问题变得不那么紧迫,但成本不是零。如果你同时处理多份长文档,累积的开销仍然值得注意。
版本 diff 噪音大。 Markdown 是纯文本,git diff 非常干净。HTML 的结构变化 — 一个 div 层级调整、一个 CSS 属性修改 — 在 diff 里会产生大量噪音。如果你需要精确追踪文档的变更历史,HTML 会增加 review 的负担。
调试门槛高。 让 Agent 生成 HTML 没问题,但当生成结果不如预期时,手动调试 HTML 需要前端知识。不是所有后端工程师都愿意打开开发者工具去查一个 layout 问题。
工具链依赖。 Markdown 处处可读 — 终端、编辑器、聊天窗口、git 平台。HTML 需要浏览器渲染。在有些场景下(比如 terminal-only 的环境),HTML 反而不方便。
那什么时候还是该用 Markdown?
Git commit message、PR comment、聊天中的内嵌格式、快速笔记、需要精确 diff 追踪的文档 — 这些场景 Markdown 仍然是更好的选择。
我的判断是,正确的做法不是二选一,而是 HTML 作为 Agent 正式输出的默认格式,Markdown 作为轻量交互的格式。就像编程语言里的 Python 和 Shell — 不存在谁替代谁,而是场景不同。你不会用 Shell 写一个 Web 服务,也不会用 Python 写一个一行管道命令。

格式选择的前提变了,你的工作流也该变了
回到开头的问题 — 300 行 Markdown 没人读。
HTML 不是唯一答案,但它提醒我们注意一件更重要的事 — 我们习以为常的很多工具选型,是建立在「人是主要生产者」这个前提上的。 当 Agent 成为内容的主要生产者,这些选型需要重新评估。
不只是输出格式。编辑器、review 工具、协作方式、知识管理 — 这些都在被 Agent 改变。Markdown vs HTML 只是最先暴露出来的一个。
Thariq 说的一句话我觉得很有代表性 — 用 HTML 之后,他感觉自己「比以往任何时候都更 in the loop」。不是因为他读了更多内容,而是因为 HTML 让他能更高效地理解 Agent 在做什么,并通过交互界面给出反馈。
从「人写人读」到「Agent 写人读」再到「Agent 写人调 Agent 改」,每次工作流的升级都伴随着工具形态的更新。HTML 只是这个更新的第一步。
下次让 Agent 出方案时,试试把 prompt 里的「生成 Markdown 文件」改成「生成 HTML 文件」。不需要改工具链,不需要学前端,只需要改一句 prompt。看看输出是不是真的更容易读、更容易理解、更容易做判断。
答案大概率是肯定的。
以上,如果觉得有帮助,欢迎点赞、在看、转发三连。
我们,下次再见。
/ 作者:迈索斯
参考资料
- • Using Claude Code: The unreasonable effectiveness of HTML — Thariq Shihipar, Anthropic 官方博客 (2026-05-20)
https://claude.com/blog/using-claude-code-the-unreasonable-effectiveness-of-html
