 夜雨聆风
夜雨聆风系列:大模型算法白话拆解 · 阶段五:概率统计
你点了一份外卖。
软件上写着:预计29分钟送达。
29分钟过了,没动静。再等5分钟,还没来。又过了10分钟,骑手才按响门铃。
你盯着那个29分钟,越想越不对。这个数字到底从哪儿来的?
我们自己算一遍
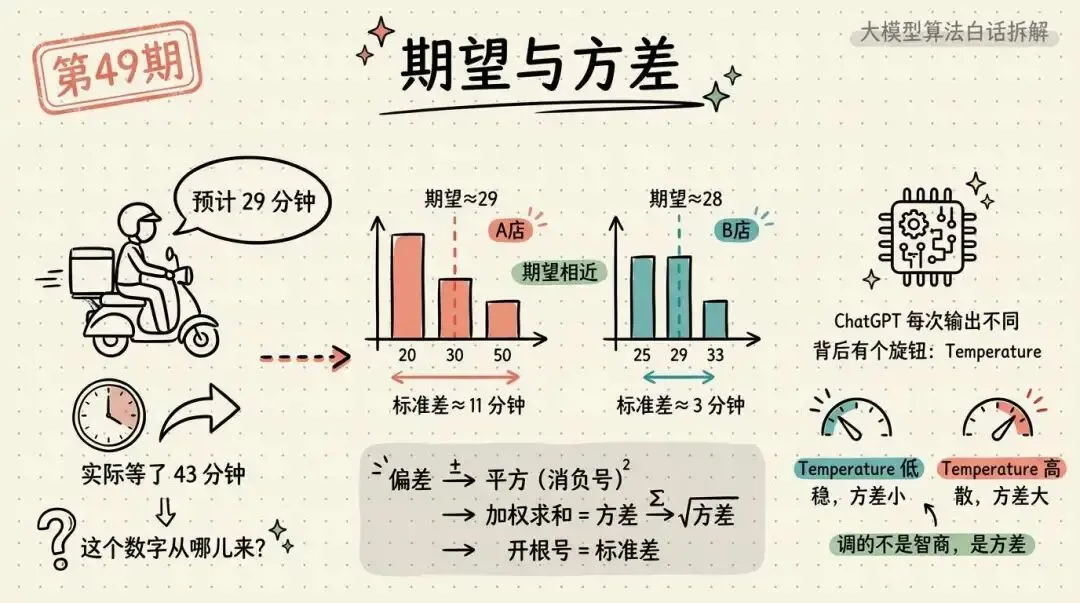
假设你家楼下那家店,过去送了1000单,结果有三种:
500单,20分钟送到 300单,30分钟送到 200单,50分钟送到
平均送达时间怎么算?
把分子展开,1000拆进去:
就是20分钟在历史里出现的频率,也就是概率。
这个就叫期望。不是新东西,就是加权平均。
软件显示的29分钟,就是这么来的。
它是过去一千单算出来的平均数。
问题在这里
再看一眼那张表,有20%的概率,送达时间是50分钟。
期望值没说这件事。它只告诉你重心落在哪。每次实际结果离重心有多远,它不管。
现在看隔壁那家店,历史记录是这样:
400 单,25分钟送到 400 单,29分钟送到 200 单,33分钟送到
期望值:
跟第一家几乎一样。
两家店期望值差不多,但一家最晚33分钟,另一家能拖到50分钟。
期望值到这里就不够用了。你还需要另一个数,描述结果散得多远。
偏差不能直接加
还是第一家店,期望值 29 分钟。每种结果偏了多少?
20 分钟:偏了-9分钟 30 分钟:偏了+1分钟 50 分钟:偏了+21分钟
按概率加权:
正好是零。
偏早和偏晚精确抵消。期望就是那个重心,偏差一正一负,加起来必然是零。
这条路算不出任何信息。那个50分钟还在那里,数字却说完全没问题。
所以先平方,把负号消掉:81,1,441
再按概率加权,跟算期望一模一样:
129,单位是分钟²,这就是方差。
开个根号换回正常的分钟,叫标准差:
这家店每次送达,平均偏离29分钟约11分钟。
第二家店算下来,只有约3分钟。
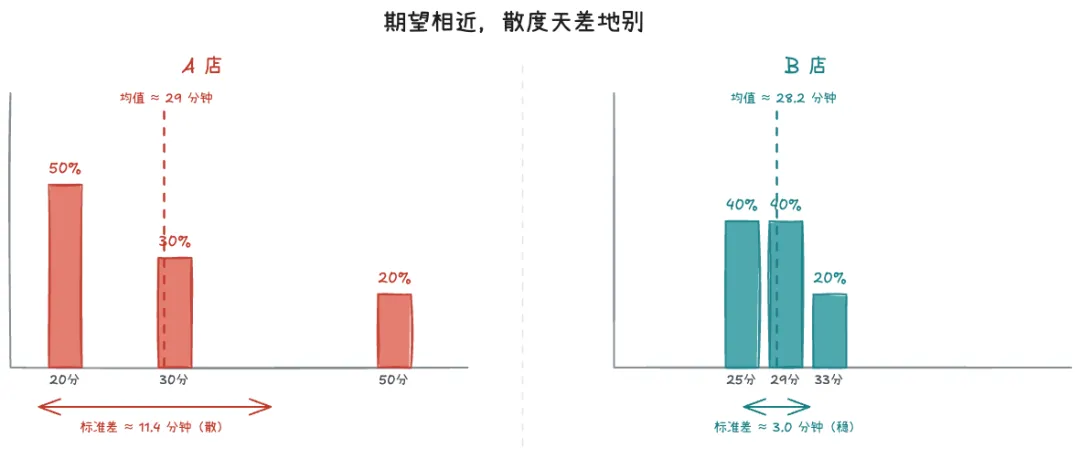
两家期望值一样,标准差差了将近四倍。外卖软件只把期望摆出来,方差藏着没说。不是骗,是只说了一半。
大模型在哪里用
同一个问题问 ChatGPT,今天和昨天可能是两个截然不同的答案。背后有个参数,叫 Temperature。
大模型生成文字,一个词一个词往外蹦。每蹦一个词之前,先算出一张概率表:哪些词可能排在后面,各自的概率是多少。和那张外卖送达时间的表是一回事。
这张概率表,来自你已经见过的 softmax:
Temperature 就是往里加了一个参数:
把每个打分除以 ,就这一个改动。
,什么都没变,就是原始 softmax。
,打分缩小,高概率词被压低,冷门词被拉高,各词概率往中间靠。看起来平了,但恰恰因为每个词都有机会,每次采样结果不一样,输出的方差变大。
,反过来,打分被放大,高分词优势更突出,低分词几乎没机会。分布更尖锐,输出的方差变小。
,概率全堆在得分最高的词上,每次输出都一样。方差为零,趋向 argmax。
写代码、做翻译, 压低,每次都选概率最大的那个结果。
写诗、头脑风暴, 调高,赌那个偏出去的好句子。
Temperature 调的是方差,不是智商。
和外卖软件藏起来的那个数,是同一件事。
