 夜雨聆风
夜雨聆风
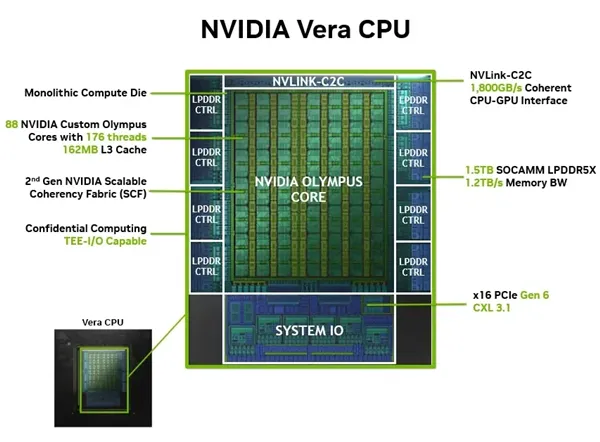
一、拆解 Vera:为 AI 而生的 “非典型” CPU
88 个自定义 Olympus 核心,176 线程,164MB L3 缓存:没有沿用 ARM 公版架构,也没有盲目堆核心数,而是针对 AI 工作负载做了深度定制。传统 x86 CPU 的大量晶体管都浪费在了通用计算和兼容性上,而 Vera 的每一个核心都只为加速 GPU 前的预处理、数据调度和推理任务而生。
1.5TB SOCAMM LPDDR5X,1.2TB/s 内存带宽:这是 Vera 最恐怖的地方。目前 AMD 最强的 EPYC 9005 系列 CPU,内存带宽也才不到 500GB/s,而 Vera 直接做到了 2.4 倍。AI 计算中 90% 的延迟都来自内存瓶颈,Vera 用片上封装内存的方式,直接把这个瓶颈砸得粉碎。
1800GB/s NVLink-C2C 一致性接口:这才是英伟达真正的杀招。传统 CPU 和 GPU 之间通过 PCIe 连接,不仅带宽低,还需要频繁的数据拷贝,浪费大量算力。而 NVLink-C2C 实现了 CPU 和 GPU 的内存完全一致,两者可以直接访问对方的内存空间,数据传输延迟降低了一个数量级。
x16 PCIe Gen6 + CXL 3.1:保留了对现有生态的兼容,同时支持最新的 CXL 3.1 协议,可以连接更多的加速器和存储设备。再加上第二代可扩展一致性架构 (SCF) 和机密计算支持,Vera 从一开始就是为数据中心级别的大规模部署设计的。
二、为什么英伟达必须做 CPU?

三、行业地震:谁会成为最大的输家?
四、写在最后:AI 计算的 “英伟达时代” 正式到来
欢迎关注!→点一个【赞】和【小红心】

