 夜雨聆风
夜雨聆风论文标题:Agentic Trading: When LLM Agents Meet Financial Markets
论文地址:https://arxiv.org/abs/2605.19337
一、AI 交易 Agent 遍地开花,但有人认真审计过吗
这两年,用大语言模型做交易决策的论文越来越多。FinAgent、TradingAgents、FinMem、AI-Trader……奇哥也写了不少这类项目的深度分析。每次看到这些论文的实验结果,收益率曲线都是45度角往右上角走,夏普比率一个比一个高。
但一个问题始终绕不开:这些结果,别人能复现吗?
2026年5月,深圳大学的 Yihan Xia 和 Taotao Wang 团队在 arXiv 上发了一篇系统审计论文,标题很直接:Agentic Trading: When LLM Agents Meet Financial Markets。他们不是来做实验的,是来做审计的。他们翻遍了77篇 AI 交易论文,然后对19篇有实际交易实验的研究做了深度复现性审计。结论四个字:触目惊心。
二、这篇审计做了什么:从77篇筛出19篇实证研究
先说清楚这篇审计论文干了什么。它不是一个比较谁收益更高的综述,而是一个检查每篇论文是否提供了足够信息让独立研究者复现其结果的审计报告。
筛选流程
·时间范围:2022年1月到2026年3月,跨越4年多的所有 AI Agent 交易论文
·数据源:ACM Digital Library、IEEE Xplore、arXiv、SSRN、Google Scholar,加上反向引用追踪
·初筛去重后得到92篇候选论文
·全文筛选后保留77篇进入证据映射
·从77篇中按两个硬标准筛选出19篇实证研究:必须输出可交易动作(Action Output),且这些动作在回测或实盘中接受过闭环评估(Closed-Loop Evaluation)
剩下58篇要么只有观点没有实际交易实验,要么只做预测不生成交易动作,全部归入背景参照组。
审计维度
研究团队逐篇检查了以下六个关键协议字段:时间一致性分割协议(比如训练集和测试集的时间边界是否明确)、交易成本模型(手续费、滑点是否建模)、股票池和幸存者偏差处理(股票进出是否合理)、执行时机和语义(订单是市价单还是限价单、什么时间执行)、可复现性等级(代码能跑吗)。这套审计维度完全来自实际研究中的反复痛点,不是凭空捏造的。
三、审计结果:15篇完全不可复现,0篇达到完整复现包
可复现性等级:一个字,惨
研究团队把可复现性分成四个等级。
R0:完全没有可运行的公开代码,或者代码链接已经404。
R1:代码存在但不可运行,缺依赖、缺数据、缺评估脚本。
R2:代码可以跑起来,但缺pinned环境或者完整文档,运行起来有缺口。
R3:完整的复现包,包括锁定的环境、数据快照、完整文档、端到端的评估流水线。
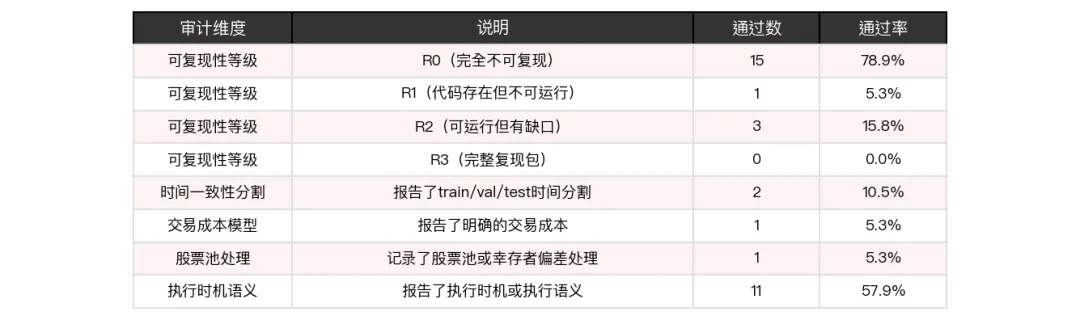
结果非常惨烈:19篇实证研究中,15篇是R0,也就是78.9%完全没有可复现性。只有3篇达到了R2,分别是TradingAgents和另外两篇。注意,没有任何一篇达到R3。整个领域的可复现性天花板就是R2。
图119篇实证论文审计结果
协议报告:关键信息大面积缺失
六个关键协议字段的覆盖率同样惨淡。19篇论文里,只有2篇(10.5%)报告了时间一致性分割协议,也就是说绝大多数论文没有明确告诉你训练集和测试集的时间边界。只有1篇(5.3%)明确写了交易成本模型,这意味着剩下18篇论文的回测结果到底扣没扣手续费、怎么扣的,你无从验证。同样只有1篇记录了股票池的构建方式和幸存者偏差处理。相对好一点的是执行时机和语义,有11篇(57.9%)做了报告,但仍然有超过40%的论文没有说清楚自己的交易是怎么执行的。
这些数字放在一起意味着什么?意味着这个领域目前的状态是,每篇论文都在自己的实验设定下跑了漂亮的结果,但由于关键协议信息缺失,你没有办法把两篇论文的结果放在一起比较,因为根本不知道它们在什么条件下跑的。
四、不止是审计:A-C-A框架重新审视 Agent 交易
这篇论文的贡献不仅仅是揭短,它还提出了一个重新理解LLM交易Agent的三层分析框架,叫做 Architecture-Capability-Adaptation,简称A-C-A。
Architecture(架构):Agent怎么处理信息
第一个维度是架构,研究团队把它拆成了四个组件。感知(Perception):Agent接收什么类型的数据,文字的、时序的、图像的还是多模态的。记忆(Memory):短期工作记忆保留当前对话上下文,情景记忆存档过去的交易经验,语义记忆编码市场规律。推理(Reasoning):反应式推理处理毫秒级别的即时判断,反思式推理做秒级的事后回顾,战略式推理做分钟到小时级别的全局规划。动作执行(Action/Execution):从决策信号到实际订单的映射,包括执行时机和成本建模。
Capability(能力):Agent到底能干什么
第二个维度是能力,包括三类金融任务。Alpha因子发现:基于代码生成、基于检索或者基于进化算法的因子挖掘。组合管理:资产配置、仓位确定、再平衡。风险管理:交易前风控、实时风控、交易后审计。
Adaptation(适应):Agent怎么学习和进化
第三个维度是适应机制,从简单到复杂分四层。上下文学习就是每次都在提示词里给例子。监督微调用标注数据更新参数。强化学习用回测奖励信号优化策略。自我演化则是让Agent自己记忆、反思和迭代。
这个框架的价值在于,它把怎么处理信息、能完成什么任务、如何学习进化这三个层次清晰地分开了。用同样的框架审视你之前写过的TradingAgents和FinAgent,会发现它们的差异不只是在表面功能上,而是在这三个维度上都有不同的设计选择。
五、为什么这么惨:八类典型的实验陷阱
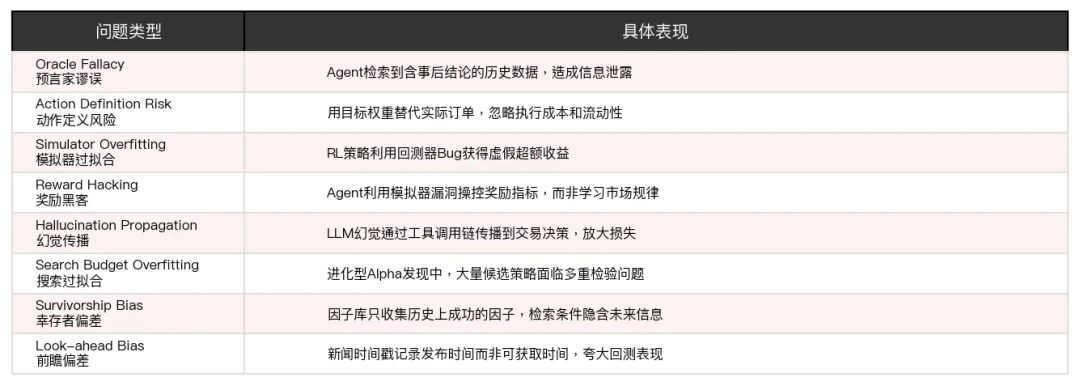
研究团队从77篇论文的审计中提炼出了八类反复出现的典型问题,这些问题不是某篇论文特有的,而是整个领域的设计通病。
图2AI 交易 Agent 领域的八类典型问题
三个最致命的问题
最致命的问题是预言家谬误,就是Agent在回测中检索到了含有事后结论的历史文本。举个例子,如果Agent读到一条新闻说某公司明天将裁员导致股价暴跌,但这条新闻在回测时间点根本没有发布,Agent却在做交易决策时用到了,那回测出来的收益率全是假的。论文建议实施所谓结果禁运,也就是在历史回测中,凡是记录于某个时间点的情绪总结,在该时间点之后的一段时间内不能暴露其结果字段。
其次是模拟器过拟合,RL策略可能利用回测器或成本模型中的细微Bug来获取虚假的超额收益,在接近实盘的环境中表现会急剧下降。
第三是幻觉传播,在Agent工作流中,LLM的一个幻觉可以通过工具调用链传播到下游动作。虚构的财报会导致错误建仓,错误建仓可能触发止损连锁反应,止损又会被信心缩放放大损失。每一步的误差都在累积。
其他几个问题也不是小事。搜索过拟合是进化型Alpha发现中评估了数千个候选策略但只报告了表现最好的,这本质上是一个多重检验问题,发现的盈利轨迹可能纯属偶然。幸存者偏差是因子库只收集了历史上成功的因子,检索条件隐式依赖未来结果。前瞻偏差是新闻和研报的时间戳记录的是发布时间而不是真正可获取的时间,Agent在历史数据上训练时会看到本来还没发布的信息,从而夸大回测表现。
六、解药:一份最低报告清单 MR-1 到 MR-7
研究团队没有止步于批评,他们给出了一份实用的最低报告清单,把反复出现的协议缺口整理成了7条硬性要求。
·MR-1(数据与股票池):必须报告资产类别、股票池构建方式、幸存者偏差处理和交易时间戳
·MR-2(时间一致性分割):训练集、验证集、测试集的时间边界必须明确,walk-forward协议和禁运规则必须说清楚
·MR-3(动作语义):订单类型和投资组合I/O必须明确,是市价单还是限价单,什么时间执行的
·MR-4(执行与成本):手续费、价差、滑点、市场冲击模型必须建模,并做敏感性分析
·MR-5(泄漏审计):显式检查特征拟合泄漏、文本事后之明泄漏和标签泄漏
·MR-6(制品与日志):代码和数据可用性、随机种子、不可变日志。目标至少达到R2可复现
·MR-7(多Agent评估):在多Agent系统中,角色权限、消息协议、共识机制和共享状态必须报告
其中MR-1到MR-4被标记为强制要求,适用于所有端到端交易研究。MR-5到MR-7是推荐或可选要求。这份清单不需要论文作者做额外实验,只需要把本应该记录但大部分论文没有记录的关键信息补上。如果未来每篇AI交易Agent论文都按这份清单报告,这个领域的实验才能真正互相比对。
七、总结:这个领域需要的是基建,不是更多的造火箭
这篇审计论文的价值不在于告诉你谁的收益率更高,而是告诉你一个令人不安的事实:目前绝大多数AI交易Agent论文的实验结果,别人根本无法验证。
这让我想起一句话:如果你不能衡量它,你就不能改进它。在AI交易Agent这个领域,目前的状态是,大家都忙着造火箭,但连量火箭飞多高的尺子都还没有统一。
但这篇论文不是来砸场子的。它给出的A-C-A框架和MR-1到MR-7清单,实际上是为这个领域搭建了一套评价和比较的基础设施。对于做这个方向的研究者和工程师来说,这套框架比任何单篇实验论文都更有长期价值。
而对普通读者来说,看懂这篇审计至少能帮你做到一件事:下次再看到一篇AI交易论文说自己年化收益50%的时候,你可以直接翻到它的实验设置部分,检查一下它有没有报告时间分割、交易成本和可复现的代码。如果这三样缺了任何一样,那个50%的数字就要打个问号了。
