 夜雨聆风
夜雨聆风Karpathy、Pocock,以及被 AI 编码热潮忽略掉的软件基本功
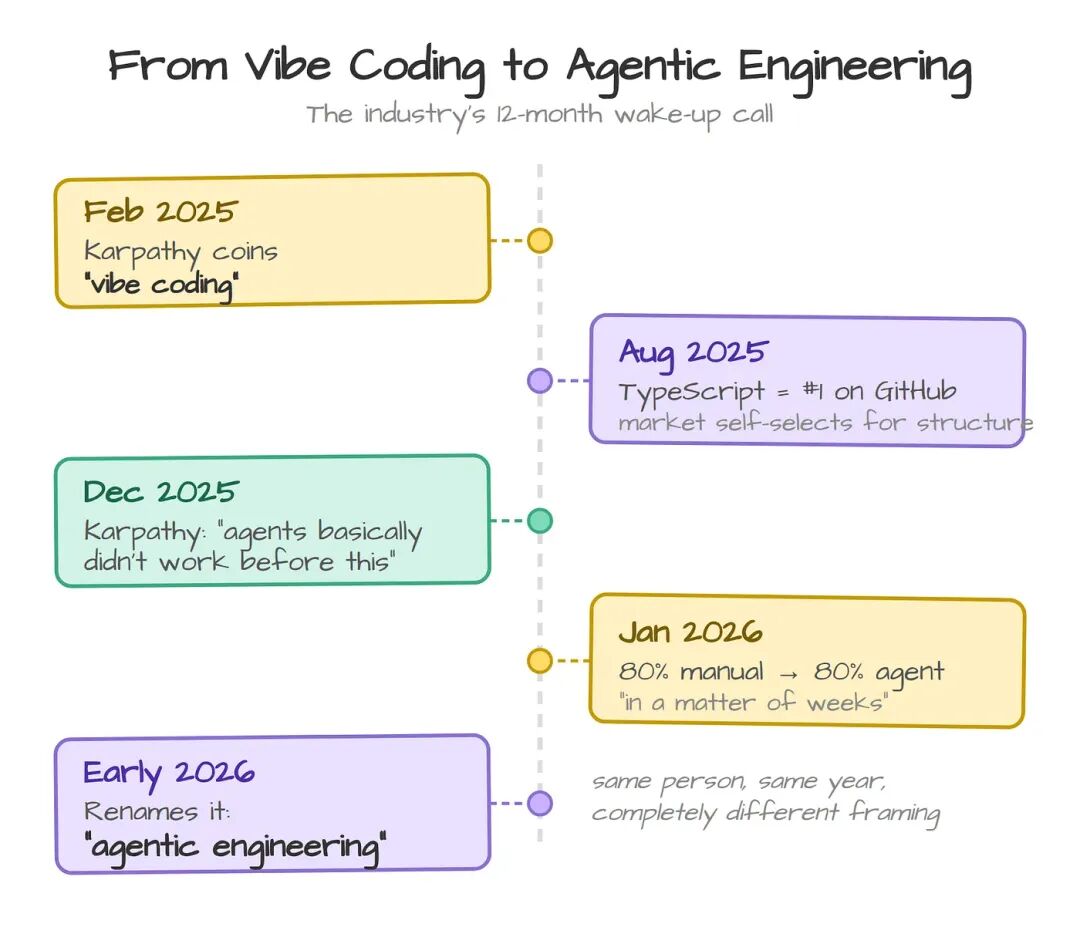
 2025 年 2 月,Andrej Karpathy 造了个词:"vibe coding"——说出你想要什么,让 AI 写代码,然后把代码忘掉。这个说法迅速火了。所有人都愿意相信,写代码已经像说话一样轻松。
2025 年 2 月,Andrej Karpathy 造了个词:"vibe coding"——说出你想要什么,让 AI 写代码,然后把代码忘掉。这个说法迅速火了。所有人都愿意相信,写代码已经像说话一样轻松。
一年之后,Karpathy 给它换了个名字,叫 "agentic engineering"。他的解释一针见血:"用 'engineering',是想强调这里头是有手艺、有科学、有专业门道的。" 他在几周内把手写代码的占比从 80% 翻转成 agent 写代码占 80%,并以一种磕磕碰碰的方式认清了一件事——模型的能力是 "jagged"(参差不齐)的:能啃下硬骨头,却会栽在最显而易见的地方。
数据也站在他这边。GitClear 的 2025 code quality study 显示,AI 协同编写的 pull requests 比纯人工 PR 多出 1.7 倍的问题;2021 到 2024 年间,复制粘贴的代码行从 8.3% 升到 12.3%。与此同时,AI 已经写下 GitHub 全部代码的 41%,Copilot 付费订阅达到 470 万。
我们写的代码比以往任何时候都多,bug 也比以往任何时候都多。这不是生产力大爆发,而是按复利计息的技术债。
Matt Pocock 在他的 AI Hero 大会演讲 里说得很直白:"代码并不便宜。糟糕的代码正贵到史无前例。"
他的推理是:代码库一旦难以修改,AI 的产出就吃不进来。每一个建议、每一个生成函数、每一次自动重构,都会先撞上烂架构带来的阻力。AI 不会替你修结构性问题,只会把它放大。
文章的论点是:AI 是一个乘数,不是魔杖。你递给它什么架构,它就把什么架构放大。好结构每交互一次,回报都会再加一层;坏结构每收到一个 prompt,腐烂就会快一层。
把"能从容交付"的团队和"在 AI 生成的意大利面代码里挣扎"的团队区分开来的,是五项软件基本功。这五项没有一项是新东西,但它们的分量比以往任何时候都更重。
1. 先对齐,再动手
Karpathy 总结了 AI 编码 agent 的四种结构性失败模式。第一种是:"模型替你做出错误假设,连个招呼都不打,就这么一路跑下去。" 你以为自己只是要一个简单的 API endpoint,AI 却造出一整套带认证、限流、数据库迁移的 microservice——而这些你压根没提过。
问题不在 AI 的能力,而在你和 AI 对"在做什么"没有共同的心智模型。
Frederick Brooks 在 The Design of Design里写过这件事。他把它叫 "design concept"——你正在创造的东西背后,那套看不见、共享的理论。它不是一份文档,也不是一个 spec 文件,而是协作者之间对"在造什么、为什么造"达成的共同理解。两个人结对编程时,这种共识会随着对话自然长出来;你给 AI 下 prompt 时,这种共识默认是不存在的。
Pocock 的解法是一个 Claude Code skill,他取名叫 "grill me"(拷问我)。完整指令只有两行:
围绕这个计划的每一个方面不停拷问我,直到我们达成共识。沿设计树的每一根分支走下去,把决策之间的依赖一个一个拆清楚。
这个 skill 火了,GitHub 上拿到 97,000+ star。AI 会问 40 个、60 个,有时甚至 100 个问题,直到它觉得问透了为止。它把 agent 变成一个不依不饶的对手,逼你不许跳过思考。
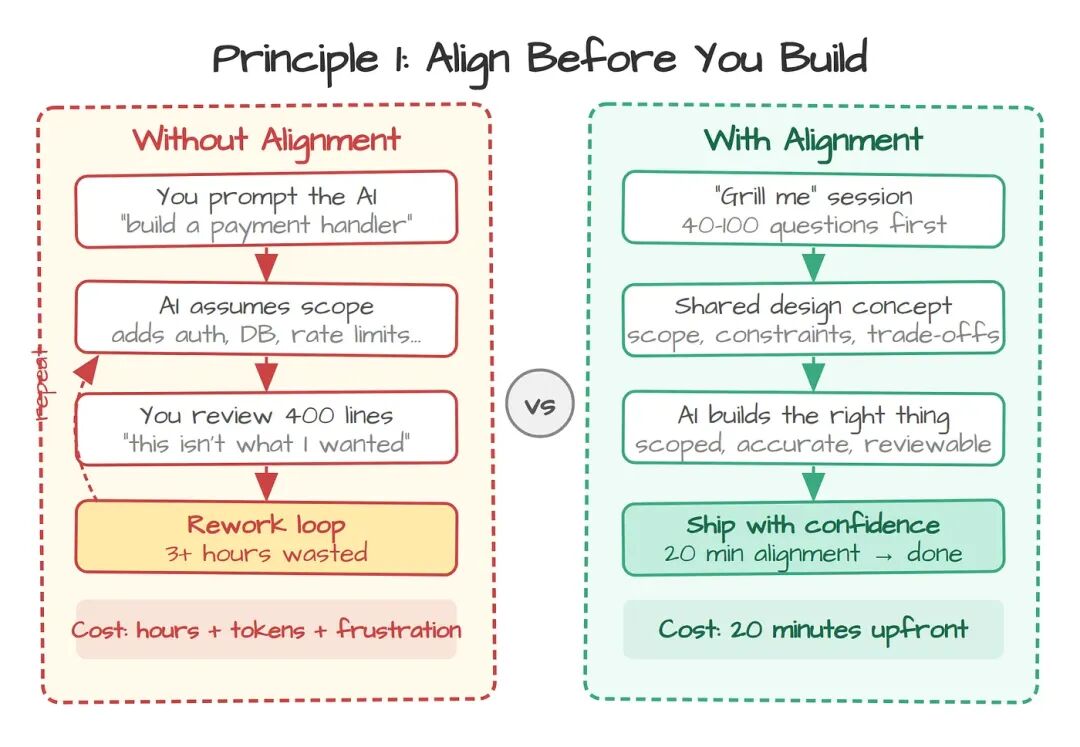
原则:在你们共享心智模型之前,不要让 AI 开始写代码。先写 brief、先定约束,把那些难问题先答完。前面花 20 分钟对齐,能省下后面用来撤回错误假设的 3 小时。
2. 说同一种语言
哪怕计划对齐了,如果你和 AI 在用同一个词指不同的东西,仍然不够。
Karpathy 的第二种失败模式是:"过度复杂的解决方案。你要的是 10 行函数,给你的是 200 行的企业级框架。"
AI 不是故意要为难你,它只是不熟悉你的词汇。你说 "handler",指的是 HTTP handler、event handler,还是 log handler?你说 "service",指的是 microservice、background worker,还是一个 class?AI 只能猜,而它会猜错——然后为这个错误的猜测建起一座 200 行的纪念碑。
这是软件工程 20 年前就解决过的问题。Eric Evans 在 2003 年出版了 Domain-Driven Design,核心概念是 "ubiquitous language"——开发者、领域专家和代码库本身共用的一套词汇。每一次对话、每一个变量名、每一个 API endpoint,都用同样的术语,指同样的东西。
Evans 最近对 InfoQ 说:"在一个 bounded context 的 ubiquitous language 上训练语言模型,比直接用通用 LLM 在具体业务上要有用得多。" 你的领域 glossary,如今是一项 prompt-engineering 资产。
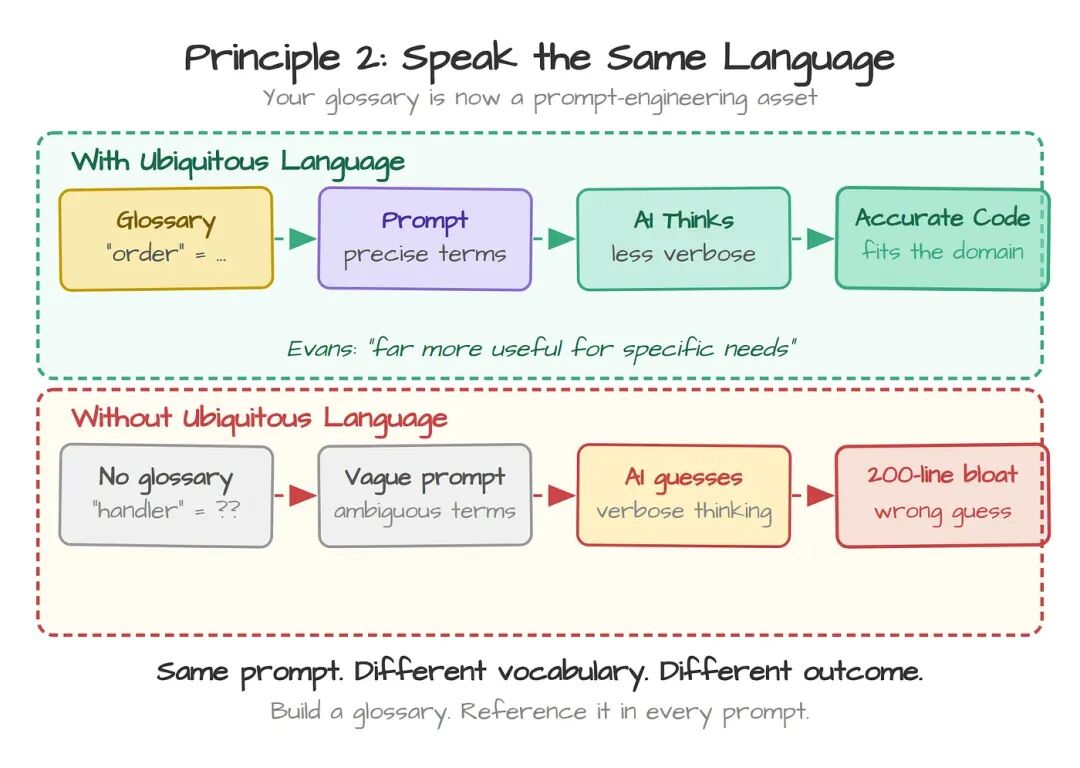
Pocock 也为此做了一个 skill。他的 "ubiquitous language" skill 会扫描你的代码库、抽出术语、生成一份满是定义表的 markdown。他读 AI 的 thinking traces 之后得出结论:ubiquitous language 不光让规划更清晰,还让 AI思考这一步变得更不啰嗦——浪费的 token 更少、实现更精确、最终代码也真的对得上规划。
DDD 的 bounded context 在这里同样适用。在 multi-agent 体系里,术语归属不清会引发 "context bleed":agent 互相踩进对方的领域,重复造逻辑、互相输出矛盾的结果。Evans 20 年前在人类团队里描述过的失败模式,今天又在 agent orchestration 里原样重演。
原则:建一份 glossary,把领域术语精确定义下来,并在项目文档和 prompt 里反复引用。如果 AI 知道 "order" 是 "Order Management context 里的客户承诺",而不是 "排序指令",它就不再瞎猜,开始生成贴合系统的代码。
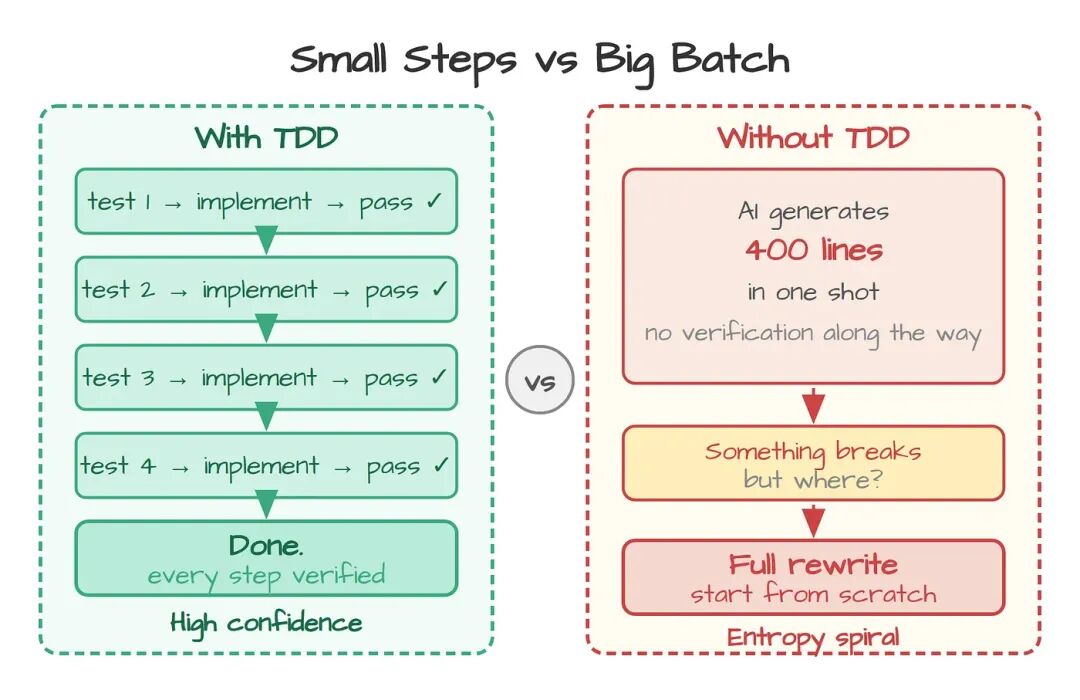
3. 先写测试,小步交付
计划对齐了,语言统一了,AI 也确实按你说的去造了,结果——跑不起来。
这种失败模式最耗时间,因为代码看上去没毛病:读起来挺顺,变量名也合理。但你一运行它就垮——因为 AI 是一口气写出 400 行,中间没验证过哪怕一行。
The Pragmatic Programmer把这种状态叫做 "outrunning your headlights"——开得比车灯能照到的地方还远。反馈节奏决定了你的速度上限,开得超出车灯范围,就一定会撞上你看不见的东西。AI agent 默认就是关着大灯开夜路:先一口气把代码生成出来,然后才(也许)回头想想要怎么验证。
Anthropic 的 best practices 推荐 writer/reviewer 模式:"一个 Claude 写测试,另一个 Claude 写让测试通过的代码。" OpenAI 的 Codex documentation 说得更直白:"没有测试时,Codex 只能靠自己的判断验工作。测试给它一个外部的判别标准。"
两个平台殊途同归地落到同一个答案上:test-driven development。不是当成一种理念,而是当成一种机械上的约束,逼 AI 必须小步走。
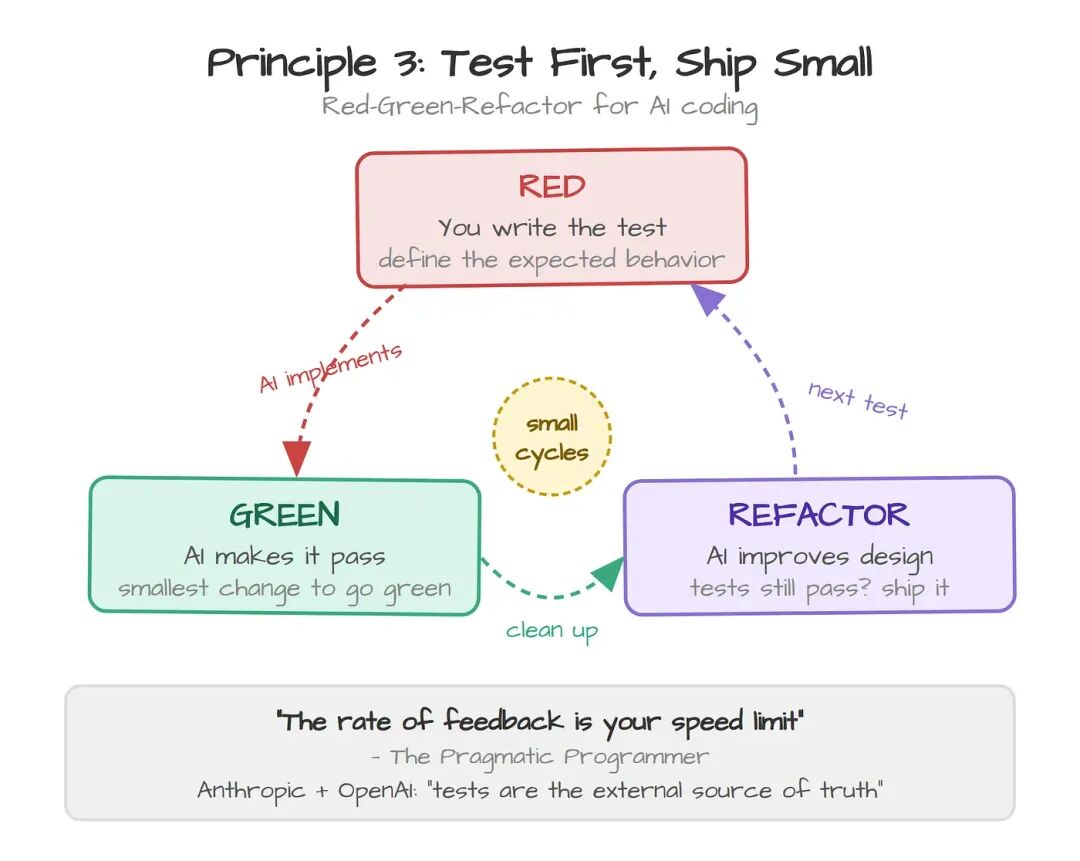
先写测试,让 AI 把测试跑通,再重构。Red-green-refactor 不是 Agile 时代的遗物,它是阻止熵增的那个反馈回路。每一轮消耗的 token、context window 空间和你的 review 时间,都只是一次大批量重写代价的零头。
2025 年 5 月一份关于 AI 生成代码的 arXiv study 发现:当 agent 从孤立脚本走进多模块系统,code smell 密度会上升。没有测试边界,腐烂会跟着代码库一起变大;有了测试边界,每个模块都会被迫保持诚实。
原则:用 AI 写代码时,TDD 不是可选项,而是让产出维持可信度的限速器。写测试,让 agent 实现,验证,再来一轮。小回路,高信心。
4. 往深里做,不要铺得太宽
哪怕测试都通过、做的也是对的事,代码库长大以后还是会遇上一个结构性问题:AI 开始迷路。它找不到正确的文件,误判依赖关系,做出的修改会把三个模块以外的东西弄坏。
John Ousterhout 在 A Philosophy of Software Design里描述过这件事。他把模块分成"深"和"浅"两种:
深模块在一个简单的接口背后藏着大量功能——你不必理解内部实现也能用。 浅模块正相反:功能不多,接口却复杂,逼你把底下的所有东西都搞懂才能用。
AI agent 特别擅长生成浅模块:一堆小文件,每个只做一件小事,每个对外暴露好几个函数,每个又依赖另外三个小文件。看上去清爽,code review 时读起来也挺顺。但它会给下一次 AI session 留下一场找路噩梦——agent 必须穿过几十个互相牵连的小块,才搞得清楚你的代码到底在做什么。
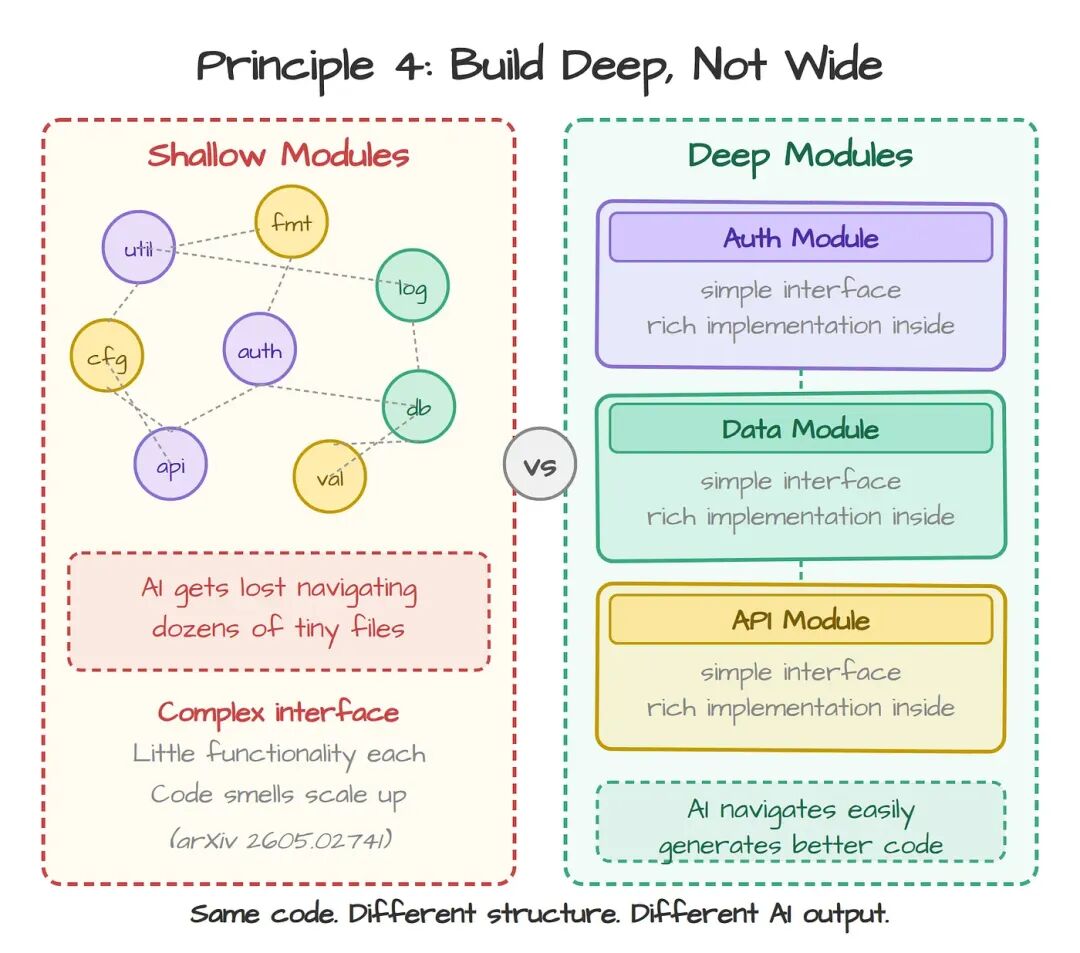
Pocock 在演讲里把这件事用图画了出来。一个堆满浅模块的代码库,像是散落一地的点,点和点之间还连着乱成一团的箭头;同一份代码重组成深模块之后,画面变成几个大块,块与块之间只剩几根干净的连线。AI 在第二种结构里走得游刃有余,写出来的代码也更好——因为它可以围绕接口推理,不必把每一处实现细节都塞进 context window。
那篇关于 AI 生成代码 code smell 的 arXiv paper 从经验上印证了这一点:随着 agent 从单脚本进入多模块系统,code smell 密度上升。LLM 在推理阶段不会自己维护架构复杂度,模块越是碎片化,AI 的输出退化得就越厉害。
这里还有一个市场信号。TypeScript 在 2025 年 8 月成为 GitHub 上排名第一的语言,原因之一就是:带类型、结构清晰的代码,能让 AI 辅助开发更可靠。开发者正在用脚投票,主动选向那种能把 AI 收益越滚越大的架构——就像分散得当的投资组合会复利地吃下市场回报。还在死守无类型、碎片化代码库的人,每天都在用返工偿还这笔账。
原则:把代码库扫一遍,找出浅模块,用简单的接口把相关代码包成深模块,在边界处加测试。AI 不需要看见所有东西,只需要看见正确的接口。
5. 设计接口,把实现交出去
如果前四条原则保护的是 AI 输出的质量,这一条保护的是你自己。
自从 AI 编码工具进入工作流以来,谁觉得自己比以前更心累的,请举手。你不是一个人。Pocock 在他的演讲现场也问过这个问题,台下几乎所有人都举了手。
这种疲惫,来自你试图把所有东西都 review 一遍:每一个生成函数、每一个被重构的 class、agent 新建的每一个文件。你交付的代码比以前多得多,但理解这些代码的瓶颈,依然是你的大脑。
Kent Beck 的建议是:"每天都在系统设计上投入。"
specs-to-code 风潮反其道而行——它从设计上抽资走人,把代码库当成一种从 prompt 中随时再生的一次性产物。结果就是:你坐在那儿,对着 400 行不是你写的、又看得似懂非懂的代码做 review。
另一个选择是灰盒模型。接口归你,边界处的测试归你,模块内部交给 AI。对非关键模块,你不需要逐行 review 实现,你只需要验证契约是不是成立。
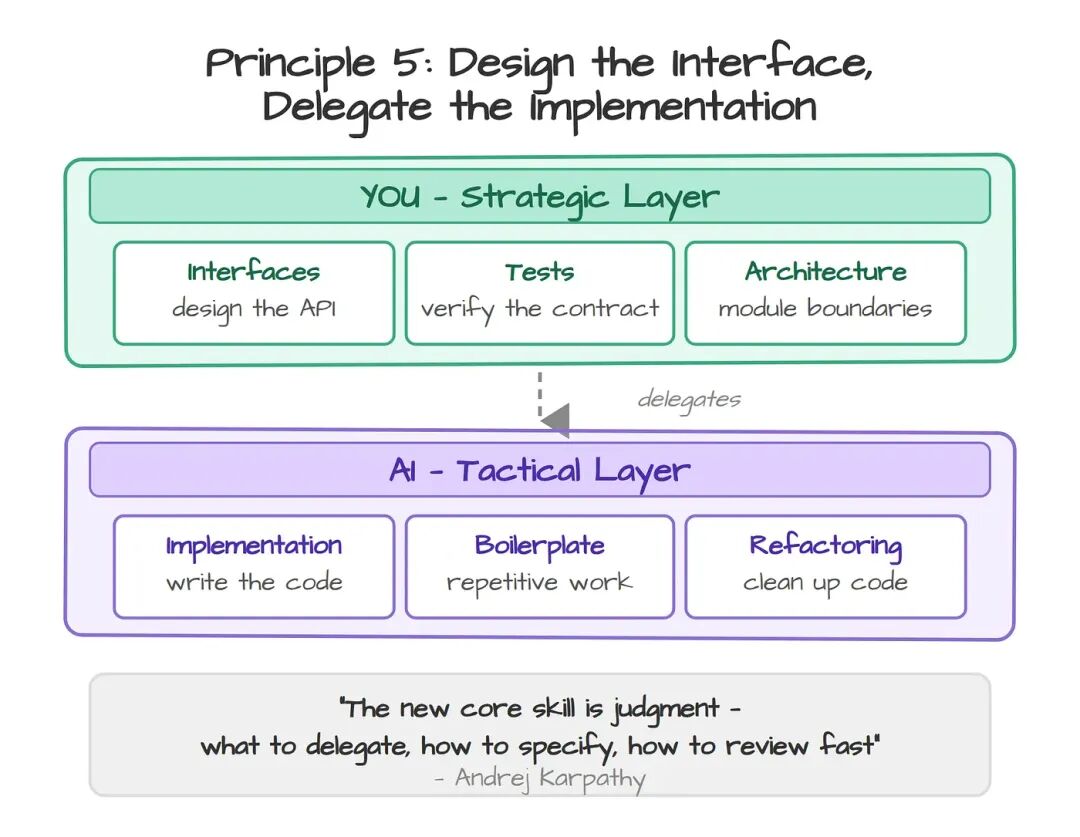
这正是 Karpathy 所说的新核心能力:"判断力——什么该委派、怎么把事情交代清楚、怎么快速复核。" 你写得少,不是因为你偷懒;你写得少,是因为时间被花在了架构、接口和验证上,也就是战略层。
Pocock 把这个区分称作战术型程序员和战略型程序员的差别。AI 是战术型,是一线动手改代码的士兵;而你是那个思考系统设计、模块边界、各部分如何咬合的人。这不是降级,这是升职。
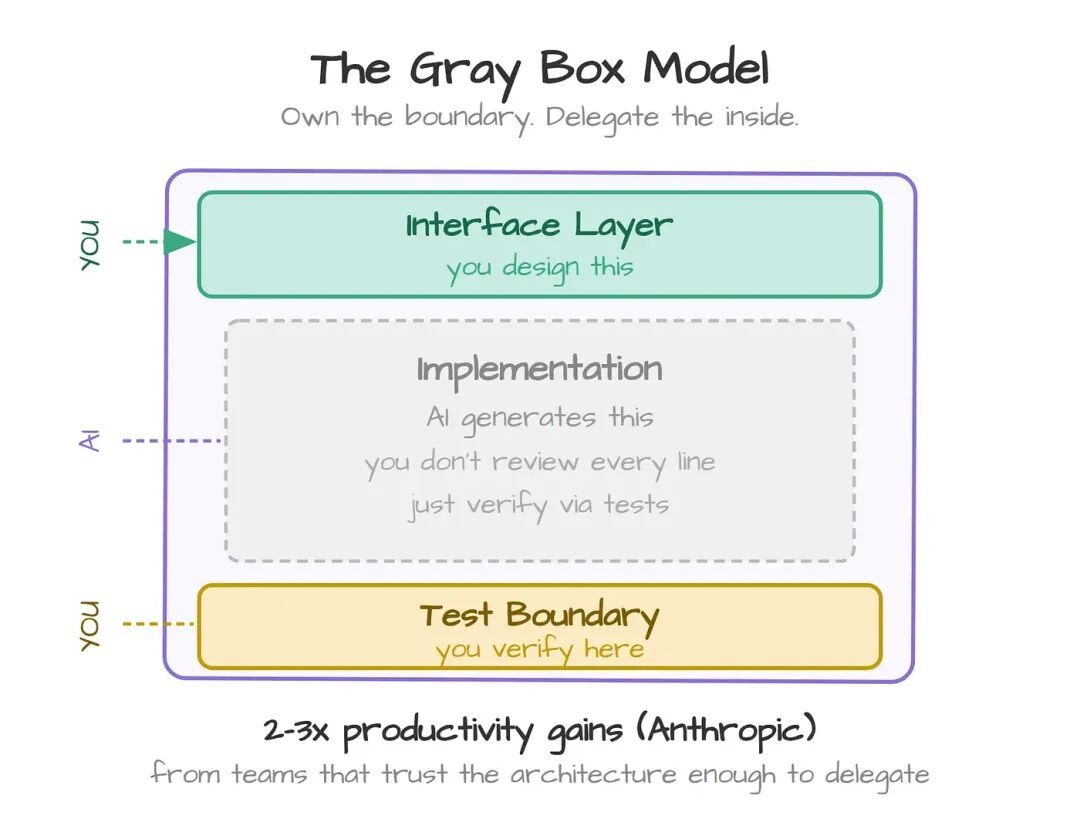
Anthropic 的内部数据显示,在大型重构任务上有 2–3 倍的生产力提升。但这些提升来自那些足够信任架构、敢放心委派的团队,而不是那些每一行都要 review 的团队。
原则:把接口写出来,把契约定下来,把实现交给 AI。通过测试验证,而不是逐行 code review。你的工作是系统设计,剩下的交给 agent。
工具箱:从原则到落地
没有工具的原则只是建议。下面这些,是你今天就能装上手的。
Pocock 把他的 skills 做成了一个 开源 repo,每一个都直接对应上面的一条原则:
- grill-me
:在 AI 动笔之前,先逼出共识(原则 1) - ubiquitous-language
:扫描代码库,建出领域 glossary(原则 2) - tdd
:在每个模块上强制走 red-green-refactor 循环(原则 3) - improve-codebase-architecture
:识别浅模块,把它们包进深模块(原则 4) - writer-prd
:在 PRD 里就把模块改动和接口契约写清楚(原则 5)
但这些原则不是某一个开发者的私见。主流平台不约而同地搭出了一整套基础设施,来落实同一组想法。
Anthropic 的 Claude Code 用 CLAUDE.md 充当对齐契约,支持每个 subagent 拿着干净的 context window 处理孤立任务,并推崇 writer/reviewer 模式:一个 agent 写测试,另一个 agent 写实现。OpenAI 的 Codex 用 AGENTS.md 做同样的事,并引入明确的 "done when" 标准,逼着 agent 在认定任务完成之前先通过测试验证。GitHub Copilot 的 agent mode 会给你的 repo 建出一份 semantic index(检索准确率比 2025 年初提升了 37.6%),并支持把 custom agents 和 prompt files 当作可复用的蓝图。
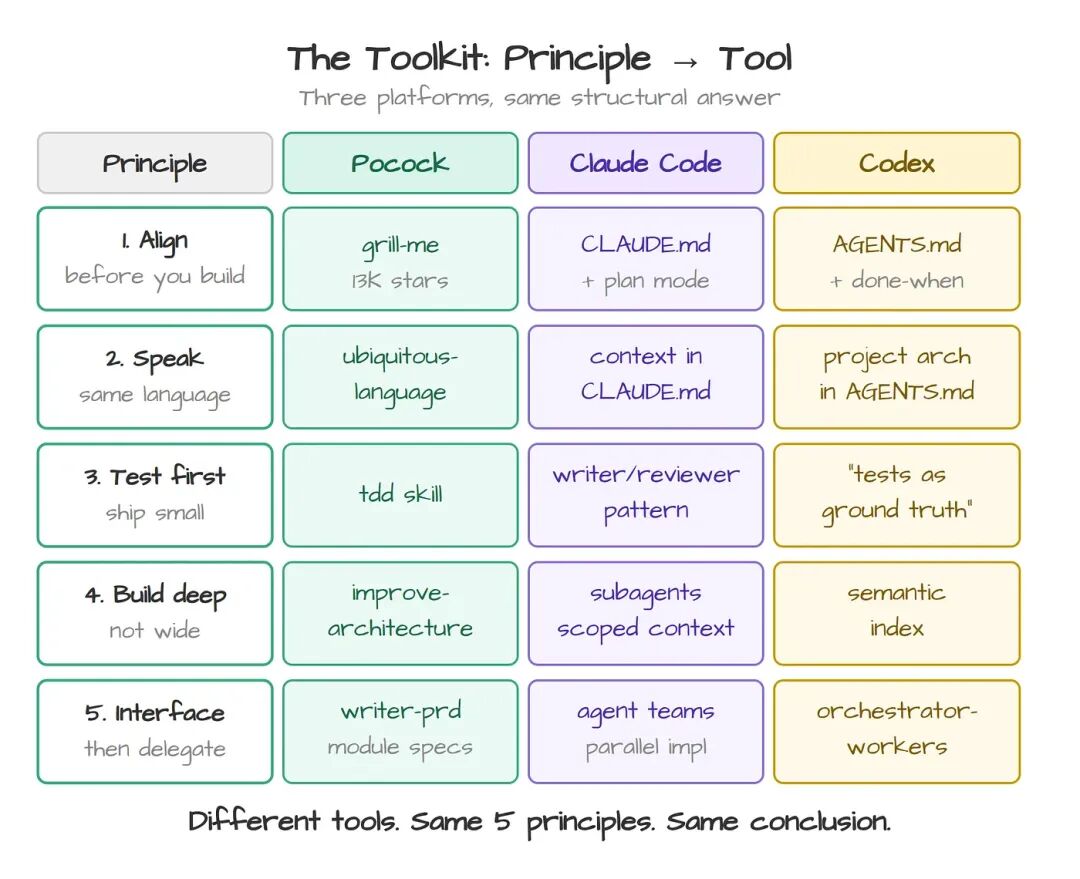
三个平台,同一套结构性答案:对齐文档、测试回路、模块边界。它们殊途同归,是因为撞上了同一堵墙——瓶颈不在模型能力,而在代码架构。
一条贯穿始终的线
Brooks 在 1975 年就写过 shared design concept。Evans 在 2003 年发布 ubiquitous language。Ousterhout 在 2018 年画出深模块那张图。Beck 几十年来一直在重复:"每天都投入系统设计。"
Karpathy 在压力之下、用地球上最强的 AI 模型亲手造系统,几周之内就把同样的功课重新走了一遍。Pocock 把这些功课提炼成几个 skill,结果火遍社区——因为成千上万的开发者从中认出了自己的痛点。
这里没有一条是新知识。重点恰恰在这里。

一个聪明的 prompt 给你一次好输出;一个结构良好的代码库给你一千次。每一个清晰的接口、每一处被守住的测试边界、每一个深模块,都让此后每一次 AI 交互的价值继续复利。跳过架构,你复利的就只剩债务。
代码并不便宜。你的架构,就是你的 AI 战略。
