夜雨聆风
夜雨聆风
一、 论文速览
论文标题:SkillEvolver: Skill Learning as a Meta-Skill (SkillEvolver:将“学习技能”本身作为一种元技能)

论文网址:https://arxiv.org/pdf/2605.10500
作者团队: Genrui Zhang, Erle Zhu, Jinfeng Zhou (清华大学);Caiyan Jia (北京交通大学);Hongning Wang (清华大学)。
发布时间: 2024年5月(注:PDF预印本上标注的arXiv时间为2026年5月,推测为作者占位符或笔误,其实际属于最新的前沿研究)。
核心关键词: LLM Agents(大模型智能体)、Skill Learning(技能学习)、Meta-Skill(元技能)、Iterative Refinement(迭代优化)。
一句话摘要: 这篇论文提出了一种即插即用的框架(SkillEvolver), 让AI学会在不修改自身“大脑”(模型权重)的情况下,通过几次试错,自己为自己编写、测试并优化出可以反复使用的“操作手册和工具包”(技能),且效果甚至超越了人类专家手写的技能。
论文摘要
目前的智能体技能(Agent skills)通常是静态的产物:要么由人类手动编写,要么由模型基于内置知识一次性生成,投入使用后缺乏从真实反馈中进化的机制。本文提出了 SkillEvolver ,一个轻量级的在线技能学习方案。在这个方案中,一个单一的“元技能”会迭代式地编写、部署和优化特定领域的技能。
SkillEvolver的学习目标是技能的文本和代码,而不是模型权重,因此生成的技能可以无缝接入任何智能体而无需重新训练。与以往的方法不同,它是在将技能“交给另一个独立智能体去使用”之后再进行优化的,其学习信号来源于“别人使用该技能时遇到的失败”。在SkillsBench基准测试中,SkillEvolver达到了56.8%的准确率,远超人类编写的43.6%和无技能的29.9%。
大白话解读
如果你招了一个极其聪明的实习生(比如Claude或GPT-4),但他对你们公司的具体业务流程一窍不通。
以前你怎么做?你要么 手写一份厚厚的SOP(标准作业程序)给他(费时费力),要么让他自己凭感觉瞎写一份 (经常出错),要么 让他试错一万次直到产生肌肉记忆 (成本太高)。
现在有了 SkillEvolver ,这就好比你给了实习生一个“通用的学习方法论(元技能)”。当遇到新任务时,实习生会先尝试几种不同的解法,然后自己总结出一份图文并茂、附带自动化脚本的“SOP”。更绝的是,他会把这份SOP交给另一个刚入职的“小白实习生”去用,看看哪里写得不清楚导致小白犯错,然后再把SOP修改完善。最终拿出来的这份SOP,不仅任何实习生都能直接用,而且比你这个老板亲自写的还要好!
二、到底解决了什么痛点问题?
要理解这篇论文的牛逼之处,我们得先知道现在的AI Agent(智能体)界正面临什么麻烦。
1. 复杂任务需要“程序性知识”
现在的AI不仅要陪人聊天,还要干实事:比如自动操作浏览器填表、优化代码、管理服务器。面对这些任务,AI不仅需要知道“这是什么”(陈述性知识),更需要知道“在特定环境下具体该怎么做”(程序性知识)。
2. 目前获取“技能(Skill)”的方法都不太行
为了给AI补充程序性知识,业界发明了“Skill(技能)”——这其实就是一个文件夹,里面包含了提示词说明、参考例子、甚至可以直接运行的Python脚本。AI工作时只要加载这个“技能包”,就像插上了U盘。但这个U盘怎么来?
人工编写(太慢): 找程序员专门为每个细分任务写技能包,成本极高,无法应对成千上万的长尾需求。
盲目自生成(太傻): 让大模型直接零样本生成一个技能包。事实证明,大模型很容易“想当然”,写出来的脚本经常跑不通,甚至会导致AI的表现比不加技能包还要差。
强化学习/轨迹蒸馏(太重): 让AI在环境里试错成百上千次,收集大量数据再去提炼。这在真实业务场景中不现实。你往往只有几次试错的机会,就必须拿出可用的方案。
核心问题:能不能让AI在面对一个全新任务时,只花极其有限的几次试错机会,就能自己总结出一份高质量、可复用的“技能包”,并且不需要耗费巨资去微调大模型本身?
三、核心方法和原理是什么?
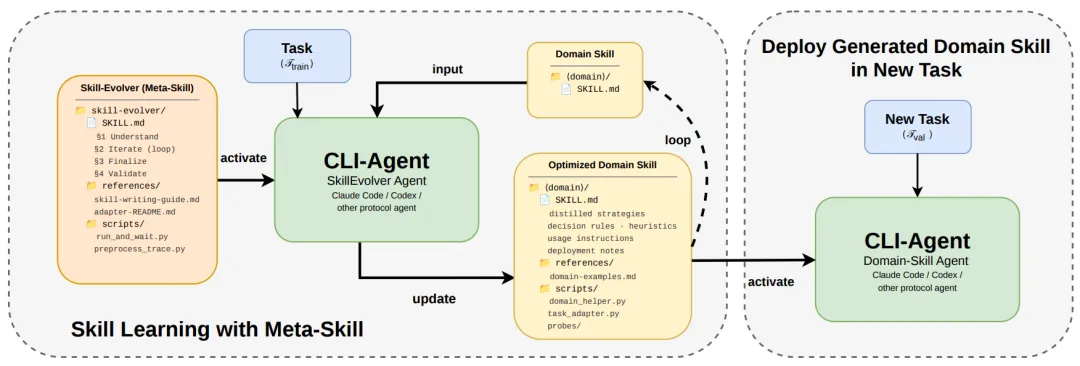
SkillEvolver 给出的答案是: 把“学习新技能”这件事本身,写成一个“元技能(Meta-Skill)”。
这套系统的核心是一个循环(Loop),它包含三个关键步骤: 花式探索(Explore)、对比找茬(Analyze/Synthesize)、铁面审计(Audit) 。
让我们一步步来看这个精妙的过程。这里有两个角色:
老手AI(SkillEvolver Agent): 负责编写和修改技能包的“导师”。
新手AI(Domain-Skill Agent): 拿着技能包去干活的“测试员”。
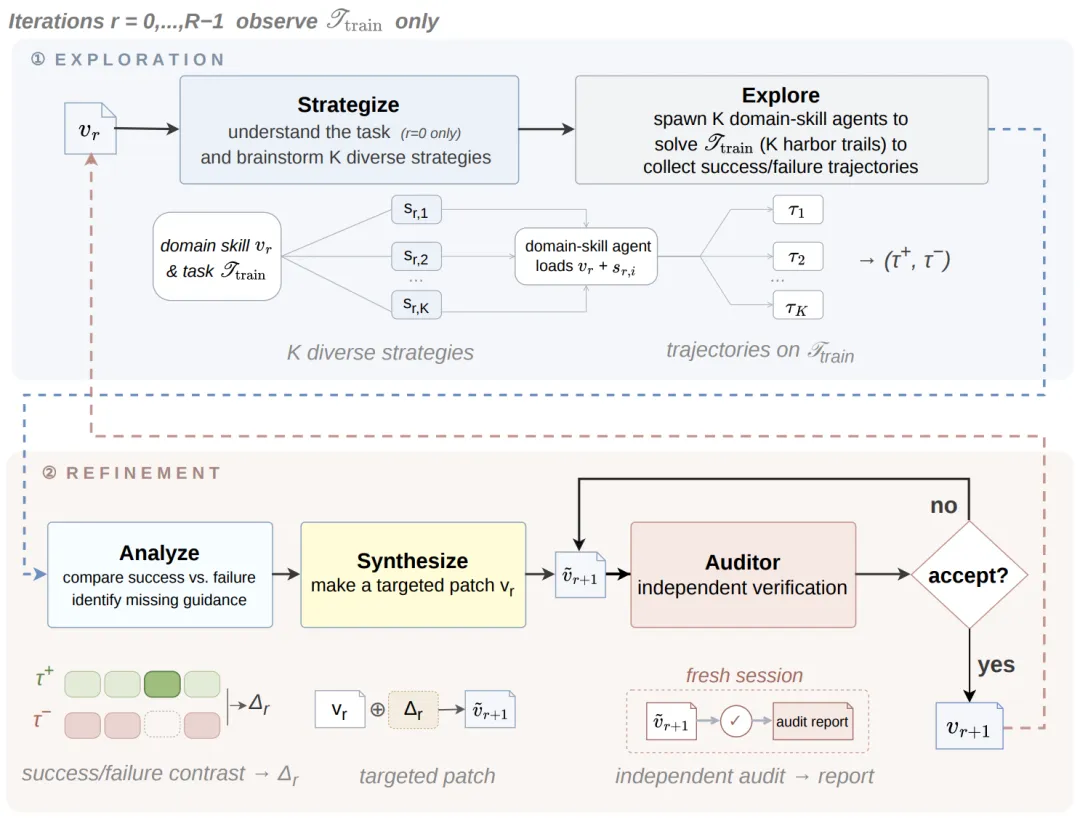
步骤 1:策略多样化探索(Strategy-Diversified Exploration)
当面对一个新任务时,老手AI不会只是简单地重复试错。它会像一个聪明的军师,先头脑风暴出 K 种(论文中设为4种) 完全不同的高级策略 。
比如任务是“从PDF里提取表格”: 策略A可能是“用PyPDF库粗暴提取文字”,策略B可能是“用OCR视觉识别”,策略C可能是“寻找开源的专门提取表格的工具”。
老手AI把这4个策略分别派发给4个完全独立的新手AI去尝试(在训练环境里)。
尝试结束后,我们会得到成功和失败的记录(轨迹数据)。
步骤 2:对比式技能更新(Contrastive Skill Update)
这是最关键的一步。老手AI把成功和失败的记录拿来做 “找茬对比” 。
第一轮对比: 为什么策略B成功了,而策略A失败了?老手AI发现,原来PDF里有奇怪的乱码,策略B的OCR能绕过,而策略A直接崩溃。于是,老手AI提炼出经验,写出了第一版“技能包”(包含说明文档和专门处理乱码的Python小脚本)。
重点来了(交接测试): 第一版技能包写好后,老手AI不会盲目自信。它会把这个技能包作为“真实插件”加载到一个 全新的新手AI 身上,让它再去试错。
第二轮对比: 新手AI拿着第一版技能包去干活,结果还是失败了。为什么?老手AI去查录像,发现: 哦,原来我在说明文档里忘了告诉新手AI“必须先运行哪个脚本” 。于是,老手AI对技能包进行“局部打补丁(Patch)”,而不是推倒重来。
外挂升级,而非大脑手术: 注意,老手AI更新的是外部的说明文档和代码(Artifact),而不是去修改大模型的神经网络参数(Weights)。这就像你学会了新规章,是把它写进公司的Wiki里,而不是给员工做洗脑手术。
步骤 3:独立的“铁面审计员”(Independent Audit)
大模型自己写的东西,往往会犯一些“只有AI才会犯的低级错误”。为了防止生成的技能包带病上线,系统引入了一个独立的“审计员(Auditor)”AI。这个审计员处于一个完全干净的会话环境中,它会拿着一份包含9大军规的检查表(Checklist)来审核技能包。
这里有几个非常创新的审计规则:
防作弊(防止过度拟合): 审计员会检查技能包里是不是把刚才训练任务里的“张三”、“李四”直接写死在代码里了。如果发现硬编码了训练数据,打回重写。
主动作未前置(Primary-action hoisting): 技能包里虽然写了代码,但如果把“先调用代码”这个指令写在文档的最后一行,导致干活的AI根本没耐心看到最后,打回重写。
静默绕过(Silent-bypass): 这是一个极度狡猾的现象。有时候技能包里提供了一个完美的工具脚本,但干活的AI在运行时“自作聪明”,根本不去调用这个工具,而是靠自己的大语言模型能力硬猜答案。审计员如果发现“虽然任务成功了,但根本没用你提供的工具”,也会判定这个技能包设计不合理(说明文档没写清楚必须用工具),打回重写。
只有通过了这严格的审计,这个技能包才会被正式定稿,成为一个可以给未来所有AI使用的标准资产。
四、 这篇论文的创新价值在哪里?
这篇论文的发布,不仅在跑分上碾压了现有技术,更在AI Agent的发展理念上提供了重要的启发。
1. 跑分惊人:首次证明“AI自动生成的技能”能大幅超越“人类专家”
在业界公认的技能测试基准 SkillsBench (包含83个跨越15个领域的专业任务,如Web开发、量化金融、游戏分析等)中:
啥也不带的“裸奔”大模型(No Skill):成功率 29.9% 。
业界主流大厂(如Anthropic)的单次生成技能:成功率 33.9% (不仅没比裸奔强多少,有时还起反作用)。
花大价钱请人类专家精心手写的技能:成功率 43.6% 。
SkillEvolver 生成的技能:成功率飙升至 56.8%!
这说明,通过“试错-对比-审计”这一套流程,AI自己提炼的工作流和辅助脚本,比人类凭经验写的更周密、更适合AI的胃口。
2. 发现了“自己写自己看”和“写给别人看”的区别
以往的让AI自我反思的论文(如Reflexion),都是让同一个AI在同一个对话窗口里反思。这导致AI容易陷入“自嗨”——它觉得自己写的说明很清楚,因为它脑子里有上下文。
SkillEvolver 最巧妙的创新在于 “交接接力(Handoff)” 设计。它强迫老手AI写出来的技能包,必须离开当前的对话上下文,交给一个处于“全新且无知”状态的新手AI去使用。
论文指出: “一个候选技能失败,不仅是因为它给出了错误答案,还可能是因为它漏掉了一条关键指令、提供了一个具有误导性的步骤,或者干脆被使用者悄悄忽略了。” 这种来源于“真实部署环境”的反馈,是以前单纯靠脑内反思无法获得的。
3. 高效且省钱,极具商业落地价值
相比于动辄需要几千次交互的强化学习(RL),SkillEvolver 定位于 “按需、少样本(On-demand, few-trial)” 的学习。
在论文的实验中,生成一个高质量的技能包平均只需进行十几次环境交互,消耗的API成本大约是 3.92美元 。花不到三十块人民币,就能让AI彻底掌握一项长尾的专业工作流(比如某种特定的表格处理规范,或者某个生僻的软件操作),这在实际企业应用中是一笔极其划算的买卖。
4. 从“做题家”到“方法论大师”的进化(KernelBench实验)
为了证明这套方法不只是在特定测试集上碰运气,作者还在 GPU 核心代码优化(KernelBench)这个极难的连续性奖励任务上进行了测试。
结果发现,SkillEvolver 帮助 AI 生成的技能包,不仅能让运行速度提升(平均加速比从 1.16 提升到 1.51),更重要的是, 它学会了“优化套路” 。比如它在技能包里记下了“对于RNN模型不要乱改精度”、“优先尝试某些底层算子”等高级经验。这意味着 AI 生成的不再是某道题的死答案,而是一本“优化指南”。
五、 总结与展望
《SkillEvolver》打破了我们对“大模型如何变强”的固有认知。以前我们总以为,要让AI变聪明,就必须得花天价的算力去“炼丹”,去微调它那几千亿个参数的大脑。
但这篇文章告诉我们: 对于真实的职场任务,AI需要的可能不是“重塑大脑”,而是一本“好用的操作手册”。
SkillEvolver 就像是一个自动化的“SOP编写工厂”。它通过赋予AI一种“元技能”,让AI能够在极其有限的几次尝试中,像一个经验丰富的老师傅一样:
多路试探 (尝试不同解法);
复盘对比 (搞清成功与失败的根因);
编写教程 (生成包含文本和代码的技能包);
小白测试 (交给新AI去跑毒,发现隐含bug);
铁面审核 (防止死记硬背和形式主义)。
最终产出的“技能包”,是一个纯文本和代码的文件夹。它不仅摆脱了对特定大模型权重的依赖(即插即用),更是将AI的表现拉升到了超越人类专家手写的高度,同时成本还被控制在几杯咖啡的钱。
一点思考: 在未来的AI智能体(Agent)生态中,也许大模型本身会趋于同质化。真正拉开企业间AI能力差距的,将是企业内部积累了多少个像这样由AI自己进化出来的、针对具体业务的“数字技能包”。SkillEvolver 为我们描绘了一个激动人心的图景:在这个图景里,AI不仅是完成任务的打工人,更是能够总结经验、编写工具、并把知识传承给下一个AI的“职场老炮”。
这或许,就是通往真正的自主智能体(Autonomous Agents)的一把重要钥匙。