AI落地实战:从客服、知识库到工业质检的四大硬核方案2026 年,AI 行业已彻底告别 “通用大模型包打天下” 的阶段,进入 “垂直场景深耕” 的深水区。企业落地 AI 的核心诉求从 “是否能用” 转变为 “如何用得稳、用得省、ROI 更高”。
无论是开发者关心的“模型需要多少算力显存”,还是企业决策者关注的 “哪些场景最易落地”,本质都围绕两个核心:技术底层的可量化指标(算力、QPS、显存等)和业务场景的精准适配(客服、质检、知识库等)。根据最新的市场数据和落地案例,我们梳理了目前最成熟、ROI(投资回报率)最清晰的四个方向:智能客服与营销、企业知识管理(RAG)、工业AI质检以及代码开发与运维,本文将客观整合AI 落地的核心场景、技术参数、实战案例与风险点,为不同角色提供全景式参考。一、AI 落地四大核心场景:成熟度与 ROI 排行榜
结合市场落地案例,以下四大场景的技术成熟度最高、投资回报率最清晰,覆盖企业高频需求:1. 智能客服与营销自动化:降本增效最直观
核心进化:从“FAQ 问答机器人” 升级为 “RAG+Agent 全能业务体”,实现 “咨询 - 办事” 闭环(如用户说 “退货”,Agent 直接调用订单接口完成退款,而非仅提供链接)。金融行业:某国有银行接入金融专属Agent 后,跨境汇款可疑交易识别率从 65% 提升至 92%,响应速度达秒级。电商行业:某美妆品牌3 天搭建促销话术 Agent,转化率提升 23%;某平台 AI 客服使客户等待时间下降 70%,人力成本降低 30%。技术关键:RAG 实时知识库(避免模型幻觉)、多轮对话状态管理(记住上下文)、人工兜底机制(复杂问题转接)。2. 企业知识管理(RAG):唤醒沉睡的私有数据
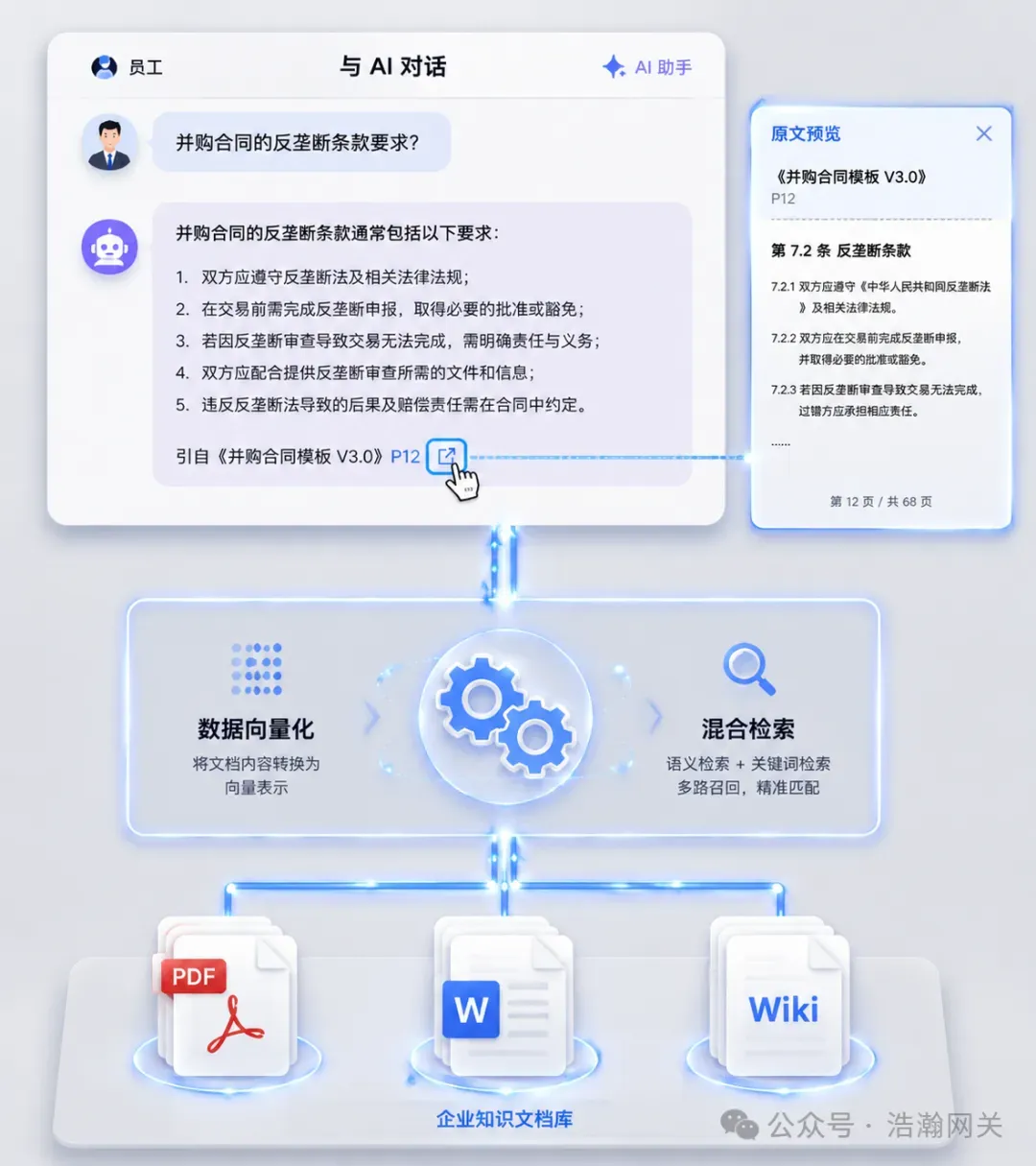
核心价值:解决企业海量文档(合同、SOP、研报)“查找难、用不上” 的痛点,将非结构化数据转化为可对话的 “企业大脑”。法务场景:某跨国企业用Agentic RAG 审查 500 份并购合同的反垄断条款,30分钟完成(原需 5 名法务工作 1 周),准确率 99%。金融/ 政务:某机构智能体 3 分钟生成行业日报(替代 4 人团队);某政务系统 AI 写公文初稿,耗时缩短 90%。技术关键:混合检索(关键词+ 向量检索)、引用溯源(答案标注原文来源)、权限分级控制(敏感数据隔离)。3.工业AI 质检:从 “抽检” 到 “全检” 的跨越
核心逻辑:通过“工业相机 + 边缘计算 + AI 模型”,实现产品瑕疵的毫秒级检测,解决人工质检成本高、易出错的痛点。某系统疵点识别准确率超90%,挡车工工作量降低 30%,专职验布工成本完全节省;每月废布减少 2 万米,实现全流程质量追溯。技术关键:AIGC 数据增强(解决缺陷样本少问题,新布种适配周期从数周缩至 10 小时)、云边协同(边缘端实时检测,云端迭代模型)、小样本学习(少量数据即可建模)。4. 代码开发与IT 运维:DevOps 全流程提效
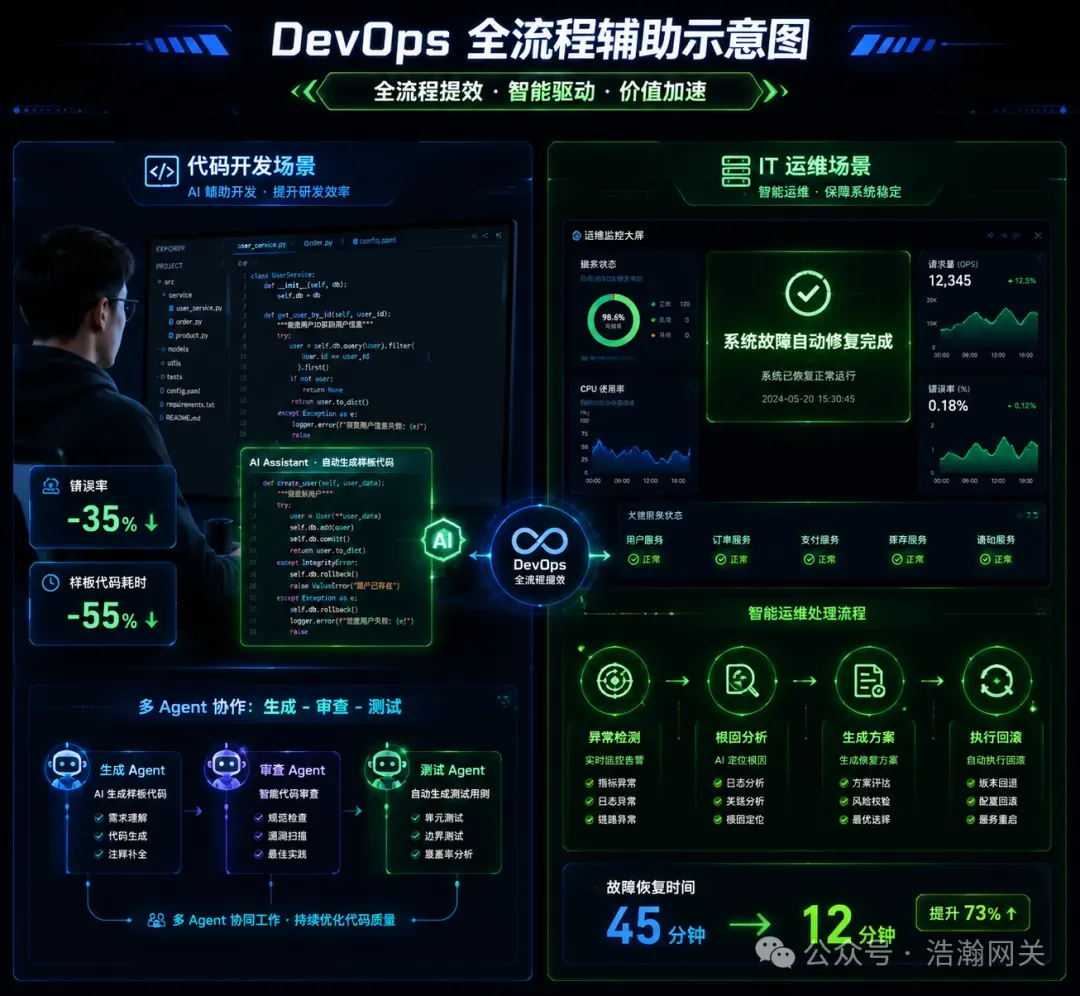
核心进化:从“代码补全” 升级为 “全流程辅助”,AI Agent 接管测试、部署故障自愈等复杂任务。开发提效:某互联网公司需求交付周期缩短40%,代码提交错误率下降 35%;GitHub Copilot 使样板代码处理时间节省 55%。故障自愈:某电商平台运维Agent 实现故障自动检测、根因分析、回滚修复,平均恢复时间从 45 分钟降至 12 分钟。技术关键:NL2SQL(自然语言转数据库查询)、多 Agent 协作(生成 - 审查 - 测试闭环)、人在回路(高风险操作人工审批)。二、技术底层硬核指标:落地前必须算清的“账”
无论是个人开发者部署模型,还是企业采购硬件,以下指标直接决定“能不能跑”“跑不跑得起”,数据均来自实测与行业通用公式:1. 核心指标定义(通俗版)
指标 | 通俗理解 | 核心影响 |
QPS(每秒查询率) | 系统每秒能处理的请求数 | 服务接待能力(如AI 客服并发量) |
延迟(RT) | 从发请求到收响应的时间 | 用户体验(如聊天回复速度) |
并发量 | 同一时刻正在处理的请求数 | 系统承载上限 |
算力(FLOPS) | 硬件计算能力(“马力”) | 模型生成速度(如Token 生成耗时) |
显存 | 硬件存储能力(“仓库大小”) | 模型能否加载(避免OOM) |
2. 模型算力与显存测算(实战公式 + 数据)
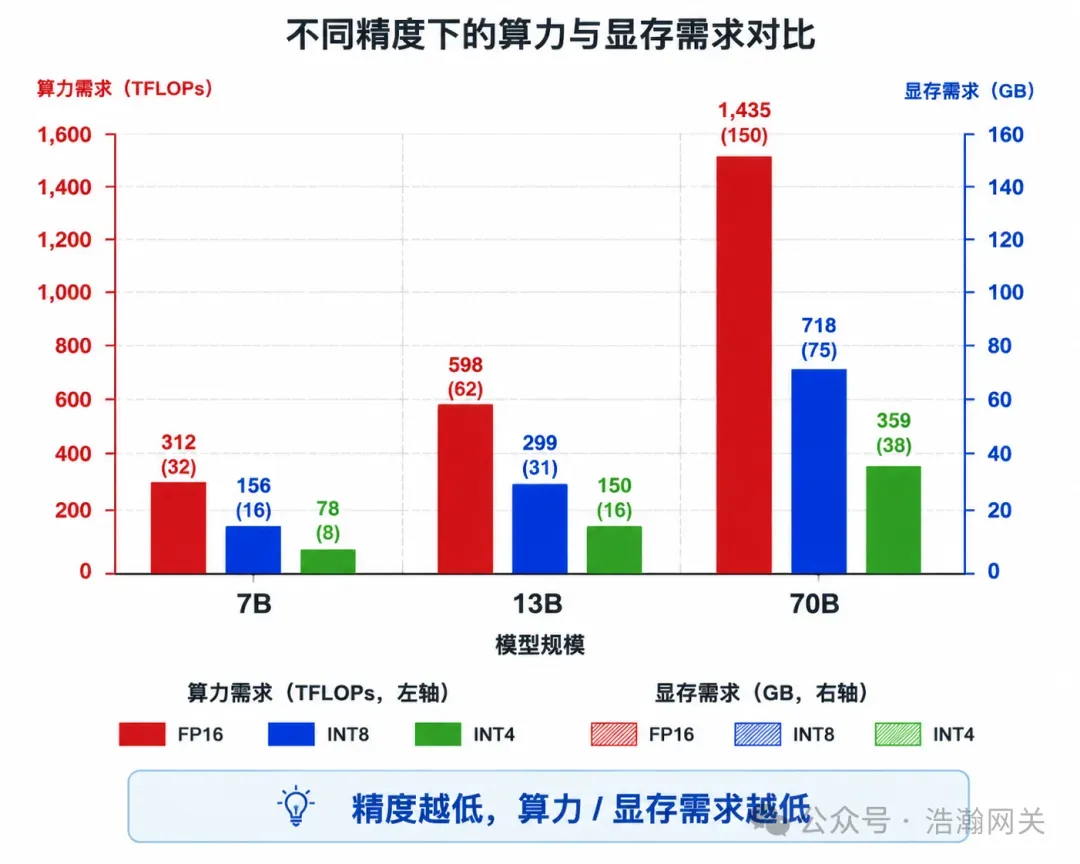
算力需求公式(推理阶段):单次生成 Token 算力 ≈ 参数量 × 生成 Token 数 × 架构系数(2.0-2.2)× 精度系数(FP16=2,INT8=1,INT4=0.5)显存需求公式:总显存 ≈ 模型权重(参数量 × 单参数字节数)× 1.3(预留 30% 推理开销:KV Cache + 激活值)模型规模 | 精度 | 理论算力需求 | ·单卡显存需求(含30% 开销) | ·主流硬件实测耗时 |
7B | INT8 | 1.54 TFLOPs | ·9.1 GB | ·RTX 4090:0.04 秒 |
13B | FP16 | 5.72 TFLOPs | ·33.8 GB | ·RTX 4090:0.08 秒 |
70B | INT4 | 7.7 TFLOPs | ·45.5 GB | ·双4090/A100:0.1-0.18 秒 |
- 精度是“减负神器”:同一模型从 FP16 降至 INT4,算力需求砍至 1/4,显存需求也同步大幅降低。
- 参数量决定门槛:70B 模型即使量化到 INT4,也需 45.5GB 显存,单卡 24G 的 RTX 4090 难以跑满并发。
- 硬件选型逻辑:消费级显卡(RTX 3060/4060 12G)适合 7B INT4/INT8;高端消费级(RTX 3090/4090 24G)适合 13B INT8 或 7B FP16;企业级(A100 40G/80G)是 70B 模型的标准配置。
3. 指标联动关系(落地关键)
核心公式:QPS ≈ 并发量 / 平均延迟;并发量 ≈ QPS × 平均延迟示例:若目标支撑100 QPS,AI 客服平均延迟 2 秒,则系统需承载 200 并发;13B 模型单次推理需 5.72 TFLOPs,按冗余系数 1.5 计算,需总算力 8580 TFLOPs,约 6-10 张 A100 显卡(单卡实际加速后 600-1300 TFLOPs)。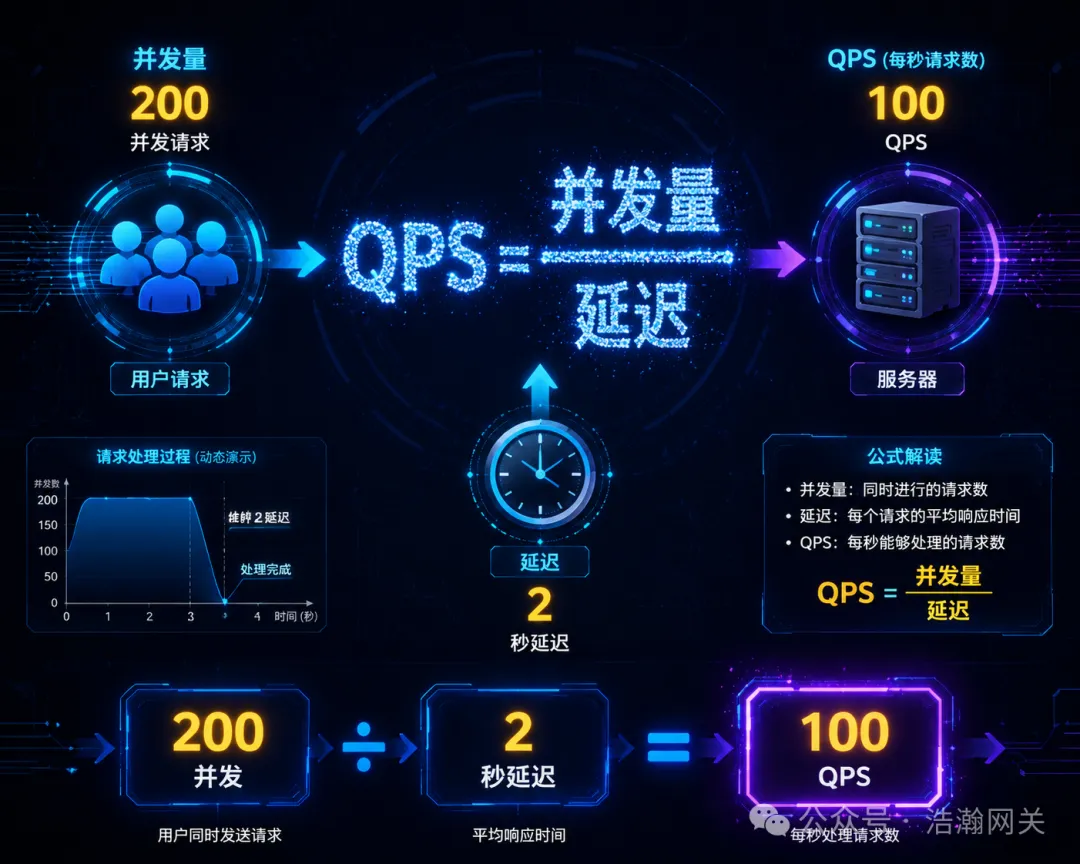
三、AI 落地的五大风险:避开这些 “暗礁” 再启动
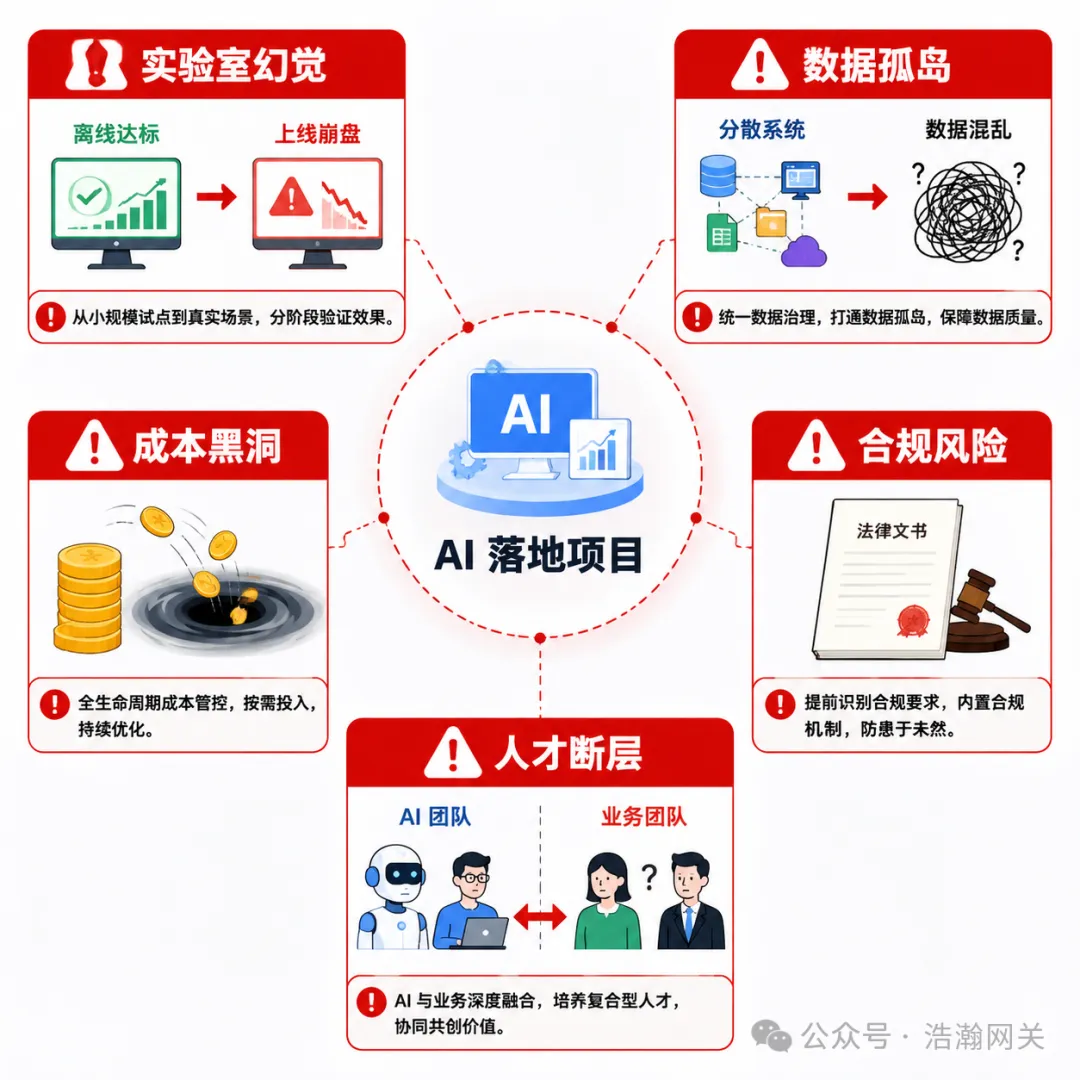
即使场景选对、指标算清,落地过程仍可能因忽视以下风险导致项目烂尾,数据均来自行业真实踩坑案例:1. “实验室幻觉”:离线准确率≠上线可用
模型离线测试准确率95%,上线后因真实场景 “噪音”(如客服场景的方言 ASR 转写、质检场景的光照变化)导致误判率飙升。更建议上线前进行真实场景数据测试,预留10-20% 的误差冗余,避免过度依赖实验室数据。2. 数据孤岛:“垃圾进” 必然 “垃圾出”
基本企业数据都分散在ERP、MES、CRM 等系统,格式混乱、标准不一,导致 RAG “企业大脑” 回答牛头不对马嘴;所以企业在落地AI 前先做数据治理,统一数据格式、结构化处理私有文档,确保数据质量就可以避免此类问题的产生。3. 成本黑洞:隐性支出远超预期
高频调用大模型的Token 费、模型微调与数据清洗的人力成本、试错成本(如 AI 选品失误导致库存积压)这些隐性成本加一起远超想象,所以我们更建议优先选择低参数量+ 高量化精度的模型组合(如 7B INT8),从小场景试点(如某类产品的客服)切入,验证 ROI 后再扩容。4. 合规与信任危机:红线不可碰
高敏感行业如金融、医疗行业的AI 决策(如拒贷、质检合格判定)需可解释性,否则会面临处罚;然而现实中37% 的用户反感企业隐瞒 AI 客服,复杂售后纠纷由 AI 处理更易激化矛盾,所以敏感行业在使用AI的时候要确保AI 决策可追溯、可解释;客服场景明确告知用户 AI 身份,保留人工兜底通道。5. 人才断层:懂AI 不懂业务,懂业务不懂 AI
目前市场上复合型人才稀缺,导致技术方案与业务需求“两张皮”(如 AI 质检模型忽略车间 PLC 周期限制),花费一定时间组建“AI 工程师 + 业务专家” 联合团队,让业务人员深度参与模型需求定义与测试。总结:2026 AI 落地的 “黄金三原则”
l场景收敛优先:不追求“全能助手”,聚焦垂直场景(如专门审合同的法务 Agent、专门检测布匹的质检模型),降低落地难度。l数据与硬件匹配:数据质量决定AI 上限,硬件选型需同时满足算力(快不快)和显存(能不能跑),避免 “重算力轻显存”。l人机协作共赢:AI 负责重复劳动(如海量文档检索、高频客服咨询、全检产品),人负责关键决策(如高风险运维、复杂纠纷处理),最大化效率与体验平衡。无论是开发者还是企业决策者,落地AI 的核心逻辑都是 “先算清指标,再选对场景,最后避开风险”,如何在核心业务流中嵌入Agent是企业目前最核心的问题,从客服、知识库这些高频场景切入,往往是ROI最高的选择—— 没有绝对最优的方案,只有最适配自身资源与需求的选择。 夜雨聆风
夜雨聆风