 夜雨聆风
夜雨聆风语言,AI与文明系列文章
前言
当ChatGPT刚出现时,有一个说法广为流传:"中文语料质量差,所以中文AI注定不行。"两年过去,这个说法不攻自破——DeepSeek、Kimi、Qwen等中文模型的表现,已经证明了中文AI完全可以在世界舞台上竞争。
但更深层的问题才刚刚浮出水面:语言本身,在AI时代是否存在先天的优劣? 中文作为世界上使用人数最多的母语,在算力被卡脖子、Token成本成为瓶颈的当下,是否拥有尚未被充分认识的结构性优势?
这个系列尝试回答这些问题。我们从Token效率的硬数据出发,穿过AI之间通信的前沿研究,最终抵达一个更宏大的问题:当AGI真正降临,人类对"强大"的不同想象,会如何塑造未来?
本文是系列的第一篇。在开始之前,需要指出:本系列的讨论均基于截至2026年5月的公开研究。AI领域变化极快,部分结论可能随时间推移而需要修正。同时,本文并非学术论文,而是面向公众的科技深度报道——我们尽可能引用可靠的学术来源,但也包含基于现有证据的推演和判断。
另外,本系列部分术语源自作者此前参与讨论时创造的原创概念(如"葛雷乔伊脸"),为方便新读者,文中的相关性举例均已替换为广泛流传的网络热词,如"内卷"、"躺平"、"爷青回"等,这些高密度表达是中文Token效率最直观的日常体现。

第一篇:中文,被低估的AI母语?
——从Token效率看语言的算力之战
"内卷"两个字,就能描绘一整个社会在存量竞争中疲惫挣扎的图景。"躺平"两个字,就能传达一代年轻人对这套游戏规则的沉默反抗。"爷青回"三个字,能让一整代人的集体记忆和自我调侃在弹幕池里瞬间炸开。
这不是巧合。中文有一种能力——用极少量的符号,打包极其丰富的信息。
但在AI时代,这种能力曾经被系统性低估。2023年,用中文向ChatGPT提问,消耗的Token(词元)比英语多出20%——说同样的事,中文更费算力。到了2024年,这个差距在不同模型上出现了显著分化:在GPT-4o上,中文Token消耗首次逼近甚至局部低于英语;而在国内DeepSeek、Kimi、Qwen等模型上,中文的Token效率已稳定领先英语13%-19%。
中文从"拖后腿的语言"变成了"局部反超的竞争者"。
这背后,是一场尚未被充分讲述的算力暗战。

一、Token是什么,为什么它决定成本?
与AI的每一次对话,背后都有一把"隐形的尺子"在计量成本。这把尺子叫Token。AI不是逐字阅读,而是把文本切成一个个Token——你可以理解为AI的"基本运算单位"。英语里,一个单词大约1-2个Token;中文里,一个汉字通常是1-2个Token。
而每一轮对话的Token总量,直接决定了运算成本、响应速度,以及你能和AI聊多长——上下文窗口是有上限的,Token越省,内容越多。
从产业角度看,Token就是AI时代的"电费"。同样的意思,如果一种语言能用更少的Token表达,使用这门语言的用户就天然享有更低的成本、更快的响应、更充裕的上下文空间。这不是文学修辞的雅俗之争,而是算力经济学问题。
那么,中文在这把尺子下,表现如何?

二、2023到2024:一场静悄悄的分化
知乎用户chenqin在2024年做了一个精妙的测试。他用了100份联合国文件——这些文件由各国使节逐条审定,确保不同语言版本承载的语义完全一致,是测试Token效率最理想的对齐语料[1]。
结果耐人寻味。
在2023年的GPT-4上,中文Token消耗是英语的1.2倍——说同样的事,中文更费算力。但到了2024年5月的GPT-4o,这个比值首次逼近1.0。在Claude-Opus-4.6上,中文表现与英语持平。而在国内的DeepSeek、Kimi、Qwen等模型上,中文的Token消耗已稳定在英语的0.81-0.87倍区间[1]。
中文,从劣势变成了局部优势。
但需要指出一个重要限定:这个优势并非在所有模型和所有场景下都成立。根据2026年5月36氪的报道,在GPT-4o的o200k分词器上,中文/英文Token比值"多数落在1.0到1.35倍之间,部分场景低于1"[1]。也就是说,中文的Token优势目前主要体现在国产模型上,在海外模型上则取决于具体分词器和任务类型。
反观其他语言:法语、西班牙语Token消耗略高于英语,俄语更高,而阿拉伯语——因为其复杂的屈折形态变化——Token消耗达到了英语的三倍以上。一个阿拉伯语用户,和AI说同一件事,需要支付相当于中文用户数倍的成本[1]。
这不是语言本身的优劣,而是分词器算法在"偏袒"谁。
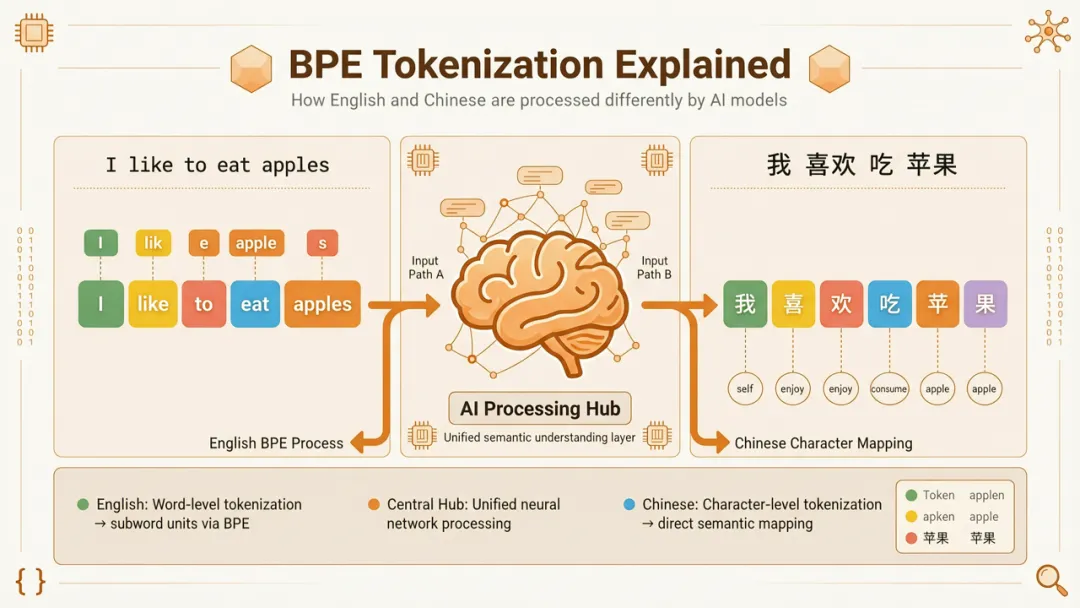
三、谁在偏袒英语?BPE算法的不公平密码
当前所有主流大模型使用的分词算法,核心都是BPE——Byte-Pair Encoding,字节对编码。
它的原理听起来公平:从字符开始,反复统计哪些符号组合出现频率最高,然后把它们合并成新的符号。比如"t"和"h"经常一起出现,合并成"th";"th"和"e"合并成"the"。这套逻辑对英语极其友好——英语本来就是字母拼接成词根、词根拼接成单词的结构,BPE就像是为它量身定做的。高频单词"the"、"and"、"weather"被完整保留为单个Token,低频词也能拆成高频碎片。
但中文不是这样构成的。中文是表意文字,每个汉字本身就是独立的意义单元。"氵"和"工"拼成"江"——这个组合过程在中文里携带了"水+声旁"的双重信息,但BPE完全看不见这层结构。它只能机械地在字符边界切分,好坏全看训练语料里词语的共现频率。
这不是中文的"缺点",而是度量衡的尺子本身就是为英语造的。
学术界早已注意到了这种系统性不公。2026年发表的《反思极性检测:当BPE跨文字失败》直指BPE对非拉丁文字产生"碎片化表示",尼泊尔语的macro-F1分数比英语低27分[2]。2025年的《Parity-aware BPE》论文提出改造算法——在每一步合并时,优先照顾当前压缩最差的语言,以少量全局压缩率为代价换取跨语言公平[3]。
NeurIPS 2025的一篇Workshop论文提出了一个新指标:STRR(Semantic Token Relatedness Ratio,语义Token关联比率)。结果直白:英语被系统性优先处理,中文也获得了较强支持——但印地语、阿拉伯语等语言,大面积碎片化[4]。
尺子是歪的。但歪尺子下面,中文依然跑赢了。这意味着,如果尺子被扶正,中文的领先幅度还有巨大释放空间。

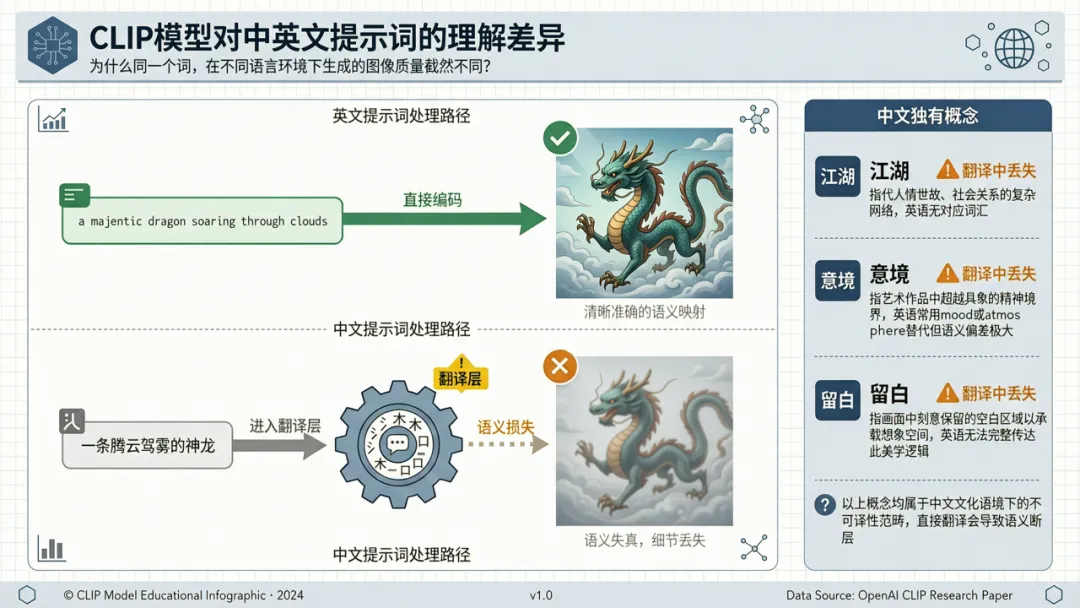
四、那为什么生图时英文提示词更好用?
这是另一个常被问到的困惑。如果你用Stable Diffusion或Midjourney生成图像,会发现英文提示词的效果往往更好——尤其是涉及到亚洲元素时,中文提示词出图总是"差点意思"。
问题不在中文,而在CLIP——大模型用来"看懂"文字和图像的文本编码器。CLIP是用英文图文对训练的。当它阅读"a majestic dragon"时,直接匹配了训练数据中的语义空间。当它阅读"一条威武的龙"时,需要先翻译成英文,再在英文语义空间中检索。翻译这一步,天然存在信息损耗。更有甚者,中文独有的概念——"江湖"、"意境"、"留白"——在翻译后丢失了整个文化语境。这不是中文不行,是CLIP不会中文。
2025年Meta发布的CLIP 2论文坦白承认了这一点:原始CLIP存在"多语言诅咒"——多语言版本的英语性能反而不如纯英语版本,因为低质量的多语言数据拖累了全局。Meta CLIP 2通过新的训练策略实现了反转[5]。但目前为止,开源生图社区仍然以英文CLIP为主流。
所以,中文提示词在生图时"差点意思",不是因为中文低人一等,而是因为当前的视觉AI还没有学会说中文。这是一个正在被修复的技术问题,不是一个文明优劣的判决。
五、算力被卡脖子时,中文的优势是什么?
芯片禁售是客观现实。高端GPU的获取受限,直接约束了中国AI产业的训练和推理算力。
在这种背景下,Token效率不再只是语言学的谈资。但需要区分:Token效率的优势主要体现在推理环节——也就是用户每次与AI对话时的计算成本。在模型训练环节,需要大量GPU进行前向+反向传播,Token效率的帮助相对有限。然而,在一个AI应用大规模普及的时代,推理成本占总算力消耗的比例正在快速攀升,Token效率的意义也在同步放大。
假设一个企业每天要处理100万次AI调用,每次调用消耗1000个Token。如果中文比英语节省15%的Token,那就意味着:同样的算力,同样的电量,可以多服务15%的用户。或者反过来:同样的服务量,运营成本降低15%。
对一个AI创业公司,15%的推理成本是生与死的距离。对一个算力受限的生态,推理环节的效率提升就是战略级别的竞争力。
这不是"中文优越论",是算力经济学。在电力、芯片、冷却成本持续走高的今天,谁的语言在推理环节能用更少的Token传递更多的信息,谁就在底层拿到了结构性折扣。
中文天然拥有这个折扣。中文是表意文字,每个汉字是独立的意义载体,不依赖于字母拼写。在最少音节/字符中传递最大信息——这是中文被千年文明打磨出的效率优势。AI时代的到来,第一次把这种优势从文学领域转移到了算力账本上。

六、这不是民族自豪感,是技术事实
本文讨论中文Token效率,不是为了证明"中文天下第一"。更不是为了给"西方技术霸权"扣帽子。
我们是在陈述一组被数据验证的事实:当前所有主流AI的分词算法,在底层逻辑上偏向英语。但在这个不公平的尺子下,中文模型在国产模型上已经实现了Token效率的稳定反超。在海外模型上,这个优势尚不普遍,但趋势向好——从2023年的1.2倍劣势到2024年的逼近持平,不过用了一年多时间。
如果尺子被扶正——如果算法不再以英语为默认最优——中文的领先幅度还有巨大释放空间。
与此同时,我们要警惕一种隐形的话术:把"技术投入差距"伪装成"语言能力差距"。一个小语种国家,投入几百万欧元做语料训练,模型效果当然不如投入千亿级的英语模型。这不是语言"不行",是投入不够。而中文,恰好是唯一有能力、有投入、有数据去挑战英语AI霸权的竞争者。
算力可以被卡脖子,但语言的效率是刻在文明基因里的,谁也卡不走。
尺子是歪的。但我们已经量出了真实身高的锋芒。

参考文献
[1] chenqin (2024). "同样表达一个意思,英语要60秒,汉语5秒就够了"是否有过誉?知乎. 使用联合国六种官方语言100份平行文件进行Token效率测试. 注意:此为个人用户研究,非同行评审学术论文. 另参见36氪(2026年5月)关于GPT-4o分词器中文Token效率的相关报道,该报道指出中文/英文Token比值在不同场景下差异显著.
[2] K H, Manodyna & De Nardi, Luc (2026). "Rethinking Polarity Detection: When BPE Fails Across Scripts." Proceedings of the 2nd Workshop on NLP for Languages Using Arabic Script (AbjadNLP), pp. 6–14.
[3] Foroutan, N., et al. (2025). "Parity-Aware Byte-Pair Encoding: Improving Cross-lingual Fairness in Tokenization." arXiv:2508.04796.
[4] Nayeem, M.T., et al. (2025). "Beyond Fertility: Analyzing STRR as a Metric for Multilingual Tokenization Evaluation." NeurIPS 2025 Workshop.
[5] Meta (2025). "Meta CLIP 2: A Worldwide Scaling Recipe." arXiv:2507.22062.
(第一篇完。第二篇、第三篇将随后发布。)
