 夜雨聆风
夜雨聆风今日相关 / Relevant Today
AI4Protein 前沿追踪
AI 深度解读
该研究提出了一种名为 PCSP 的框架,旨在解决大语言模型(LLM)生成的角色(NPC)行为难以追溯至其原始设定文本的问题。研究首先利用冻结的 Qwen3 嵌入模型将角色文本映射为高维向量,并通过低秩投影(LoRA 结构)将其压缩至 64 维,以平衡职业相似性与性格相似性的表征偏差。随后,设计了一个共享策略网络,采用 FiLM 机制将角色信号注入每一层隐藏单元,并引入一致性损失(InfoNCE)确保轨迹可追溯至特定角色,同时利用多样性损失防止行为坍缩。为验证方法有效性,构建了三层评估体系:第一层 PCSP-D 作为受控诊断环境,在完全可观测且动作空间较小的条件下,证明了 InfoNCE 一致性损失是实现行为因果追溯的关键;第二层与第三层则分别在通用环境和商业游戏引擎约束下验证了方法的泛化性与部署可行性。实验结果表明,该方法显著提升了角色信号在轨迹中的可恢复性,且在不同奖励结构与动作集下均保持稳健,为构建具有明确性格特征且行为可解释的 NPC 提供了有效路径。
中文摘要
摘要:在包含 300 个人设的模拟生活基准测试中,pcsp 实现了高达 17 倍于随机猜测水平的组合式零样本人设识别,Spearman 相关系数约为 0.73,语义 - 行为对齐度良好,且推理速度比基于大语言模型策略的基线快 22 倍。模拟生活类游戏需要数百至数千个非玩家角色(NPC),这些角色需保持行为一致且具备独特个性,同时仍可通过设计师撰写的自然语言进行可控操作。现有方法在诸如人设一致性、可控性或实时推理等约束条件下表现不佳。我们提出了 pcsp(Persona Conditioned Shared Policy,人设条件共享策略),这是一种基于冻结的大语言模型自由形式人设描述嵌入的单一强化学习策略。pcsp 结合了每 NPC 一次的人设编码、低秩人设投影、神经人设条件化,以及 PPO + InfoNCE 一致性 + KL 多样性训练目标。在三种实验设置中,消融实验表明 InfoNCE 轨迹一致性目标是关键支撑:移除该目标会导致零样本人设识别性能降至随机水平。在 Melting Pot 2.4.0 子环境上的外部验证证实,我们的方法能够在多智能体战略环境中产生人设条件化的行为发散。我们区分了两种留置评估的含义:组合式零样本评估和词汇扩展留置评估。最后,在 UE5 引擎中的部署复现了引擎内人设条件化消融实验,在 64 个智能体下实现了低失败率,表明亚帧推理模式能够在商业游戏引擎中稳定运行。这些结果证明,共享强化学习策略能够支持可扩展、实时且具备人设条件化的 NPC 控制。
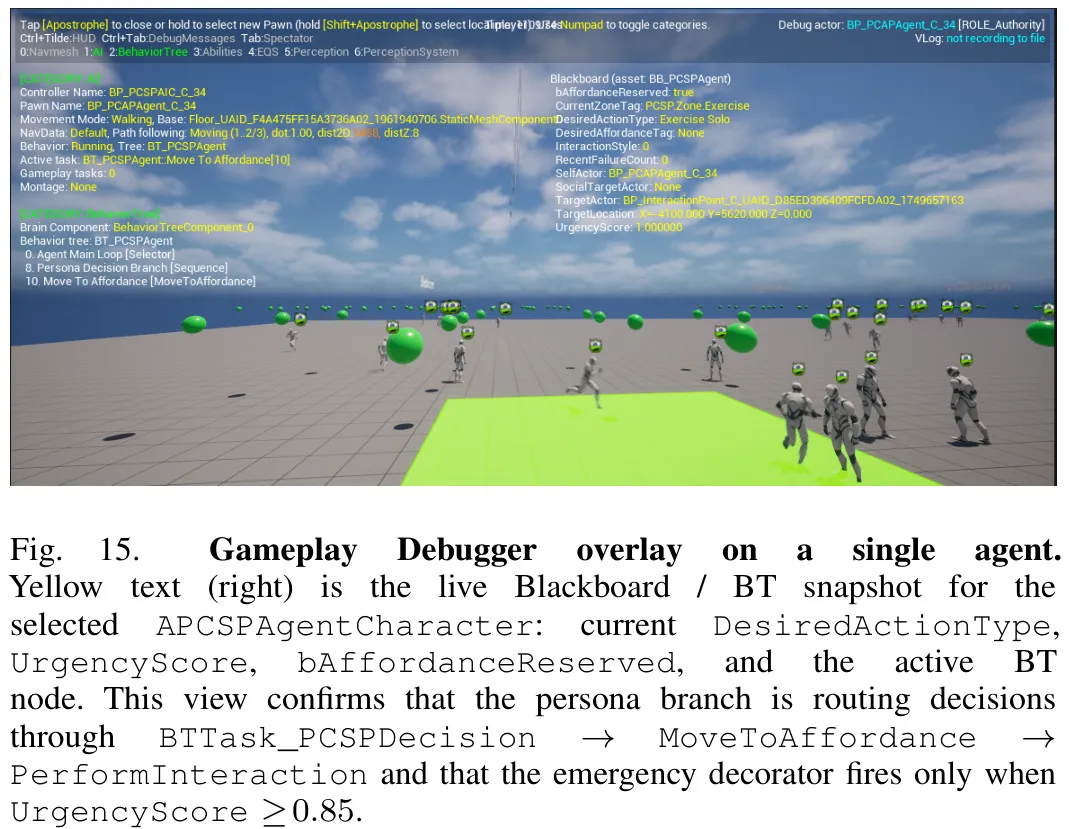
Paper Key Illustration
原文
One Policy, Infinite NPCs: Persona-Traceable Shared RL Policies for Scalable Game Agents
Abstract: On a 300-persona life-simulation benchmark, pcsp achieves compositional zero-shot persona identification up to 17x above chance, Spearman rho approx 0.73 semantic-behavioral alignment, and 22x faster inference than an LLM-as-policy baseline. Life simulation games require hundreds to thousands of non-player characters (NPCs) that behave consistently with distinct personalities while remaining controllable through designer-authored natural language. Existing methods fail on constraints like persona consistency, controllability, or real-time inference. We introduce pcsp (Persona Conditioned Shared Policy), a single reinforcement learning policy conditioned on frozen LLM embeddings of free-form persona descriptions. pcsp combines once-per-NPC persona encoding, low-rank persona projection, neural persona conditioning, and a PPO + InfoNCE consistency + KL diversity training objective. Across three experimental settings, ablations show that the InfoNCE trajectory-consistency objective is load bearing: removing it collapses zero-shot persona identification to chance. External validation on Melting Pot 2.4.0 substrates confirms that our method produces persona-conditioned behavioral divergence in multi-agent strategic environments. We distinguish two senses of held-out evaluation: compositional zero-shot and vocabulary-expansion held-out. Finally, a UE5 deployment reproduces the in-engine persona-conditioning ablation at 64 agents with a low failure rate, showing that the sub-frame inference profile survives in a commercial game engine. These results prove that shared RL policies can support scalable, real-time, persona-conditioned NPC control.
链接:https://arxiv.org/pdf/2605.23652
AI 深度解读
该研究提出了一种基于确定性常微分方程(ODE)的变分推断框架,旨在解决高斯过程(GP)中深度增加或维度升高时,无条件先验与真实后验之间差距过大的问题。研究首先定义了“香草”FBVI(Vanilla FBVI),即通过学习到的 ODE 将 GP 先验推前至后验的确定性方法,但这会导致优化困难且缺乏数据锚定。为此,论文引入了“桥接路径”(Bridge Path)方法,利用 Doob 桥的噪声侧边缘分布作为采样 ODE 的初始条件,将初始方差减半,从而缩小优化空间。核心创新在于将变分推断从密度空间转向采样器空间,利用 Onsager-Machlup 原理构建 tempered Doob-bridge 路径后验。该方法通过 Girsanov 定理的确定性极限分析,证明了在噪声趋于零时,该路径后验的最大似然估计路径精确对应于 LOM(Onsager-Machlup)路径。最终,论文给出了封闭形式的参考漂移速度场公式,该方法不仅保留了桥接几何结构,还通过数据锚定实现了方差缩减,为高维高深度 GP 推断提供了更稳定的确定性 ODE 解决方案。
中文摘要
摘要:基于诱导变量的近似推断是深度高斯过程(DGPs)的核心计算瓶颈。现有方法要么通过证据下界(ELBO)拟合显式密度 q_φ()(如 DSVI、IPVI、DDVI、DBVI),要么通过马尔可夫链蒙特卡洛(MCMC)进行采样(如 SGHMC)。本文则将 DGP 推断框架化为\emph{后验传输}:学习一个确定性采样器,将易于处理的参考测度映射到与后验相关的诱导变量上,并利用源自 Doob 桥接参考扩散的路径先验进行正则化。我们的实现方法\textbf{OM-Path}(形式上为 FBVI-bridge-Path)将 Song 的概率流 ODE 应用于 DBVI 的 Doob 桥接前向 SDE;其参考漂移项由桥接边缘系数给出解析解(无需分数匹配),而路径正则化项为\textbf{Onsager--Machlup 作用量}。在训练所使用的有限ε值下,目标函数对应于调温 Doob 桥接路径后验的非归一化密度的负对数,定理 1 通过 Freidlin--Wentzell 大偏差原理将其与同一后验的小噪声 MAP 路径等同起来。此外,我们还推导了基于同一桥接骨架的两个严格路径空间 ELBO 变体(FFJORD 行列式对数;OM 正则化 CNF)作为消融实验。在七个 UCI 回归基准测试中,针对 DBVI 进行配对 Wilcoxon 检验(匹配种子),OM-Path 在两个最大规模数据集上取得了具有统计学意义的显著优势(\textit{power}:p=0.014,NLL 为\mathbf{0.012},与 DSVI 基线 0.017 持平;\textit{protein}:p=0.002,RMSE 为\mathbf{0.716} 优于 0.764,NLL 为\mathbf{1.086} 优于 1.149),在\textit{yacht}和\textit{qsar}数据集上与 DBVI 持平,但在小样本N的噪声数据(\textit{boston}、\textit{energy}、\textit{concrete})上略逊于 DBVI。严格 ELBO 变体在所有 UCI 指标上均未超越 DBVI:在此 regimes 下,降低路径目标函数的方差比精确追踪密度更为关键。
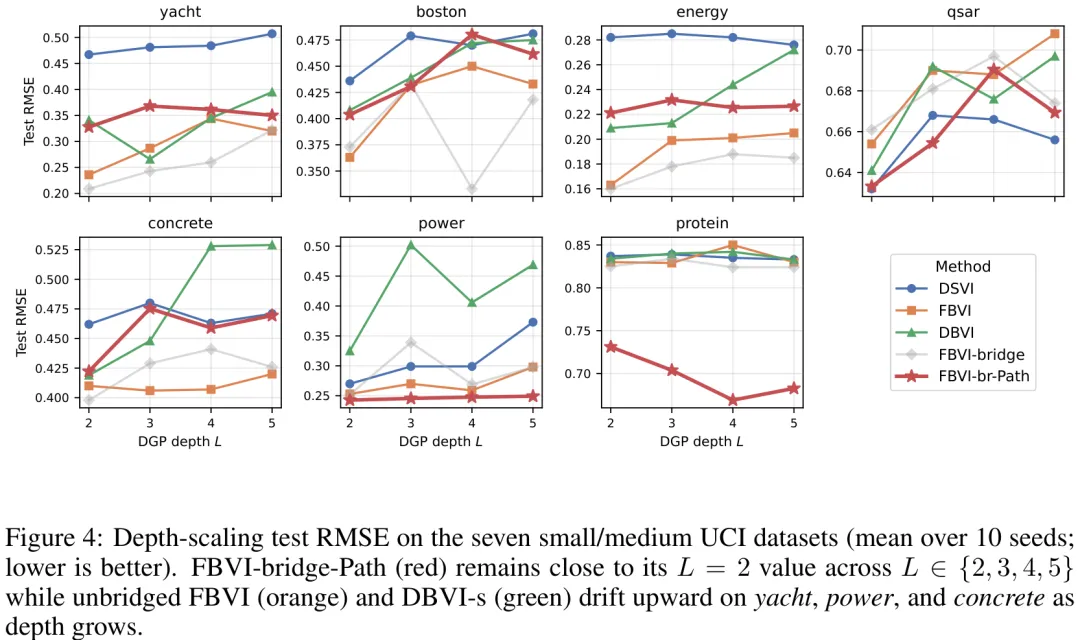
Paper Key Illustration
原文
Onsager-Machlup Posterior Transport for Deep Gaussian Processes
Abstract: Approximate inference over inducing variables is the central computational bottleneck of Deep Gaussian Processes (DGPs). Existing methods either fit an explicit density q_φ() by an ELBO (DSVI, IPVI, DDVI, DBVI) or sample by MCMC (SGHMC). We instead frame DGP inference as \emph{posterior transport}: learn a deterministic sampler that maps a tractable reference measure to posterior-relevant inducing variables, regularised by a path prior derived from the Doob-bridged reference diffusion. Our realisation, \textbf{OM-Path} (formally FBVI-bridge-Path), uses Song's probability-flow ODE applied to DBVI's Doob-bridged forward SDE; the reference drift is closed-form from the bridge marginal coefficients (no score matching) and the path regulariser is the \textbf{Onsager--Machlup action}. At the finite-ε value used at training, the objective is the negative log unnormalised density of a tempered Doob-bridge path posterior, and Theorem 1 identifies it with the same posterior's small-noise MAP path via the Freidlin--Wentzell LDP. Two strict path-space ELBO variants on the same bridge backbone (FFJORD log-det; OM-regularised CNF) are derived as ablations. Under a matched-seed paired Wilcoxon test against DBVI on seven UCI regression benchmarks, OM-Path delivers statistically significant wins on the two largest datasets (\textit{power}: p=0.014, NLL 0.012 matching the DSVI baseline of 0.017; \textit{protein}: p=0.002, RMSE 0.716 vs.\ 0.764, NLL 1.086 vs.\ 1.149), statistical ties on \textit{yacht} / \textit{qsar}, and concedes \textit{boston} / \textit{energy} / \textit{concrete} to DBVI on small-N noisy data. The strict-ELBO variants do not clear DBVI on any UCI metric: in this regime, reducing the variance of the path objective dominates exact-density tracking.
链接:https://arxiv.org/pdf/2605.23434
AI 深度解读
该研究针对连续空间 3D 环肽生成中奖励稀疏、非平滑且依赖拓扑结构的挑战,提出了一种基于奖励对齐的生成框架。研究将环肽设计定义为混合离散 - 连续约束生成问题,旨在生成满足特定宏环化约束(如 stapled、head-to-tail、二硫键及双环结构)的肽分子。方法上,研究构建了一个条件潜扩散模型作为基策略,并通过“奖励加权的扩散对齐”技术,利用拓扑特定的阶梯状距离奖励对去噪更新进行重加权,从而在训练阶段直接优化生成分布以闭合几何约束,避免了通过非平滑约束检查进行梯度计算的问题。此外,研究引入了类型门控机制以防止化学不兼容的锚点获得距离奖励,并采用 FIFO 回放缓冲区在多拓扑结构间进行混合训练,以验证单一对齐生成器支持多种宏环化机制的能力。实验部分在 PepBench、ProtFrag 及 LNR 基准数据集上进行了评估,主要指标为 pass@5 成功率,通过与 PepGLAD、w/EG 及 CP-Composer 等基线对比,验证了该方法在复杂环肽生成任务中的有效性。
中文摘要
摘要:环肽因其闭环拓扑结构能够提高稳定性和靶点特异性,而成为极具吸引力的治疗手段。然而,从头设计环肽对扩散生成模型而言仍具挑战性,因为大环化需要满足稀疏、非平滑且组合式的几何约束。现有的条件约束方法主要依赖推理时的引导,虽然能将样本导向期望的闭环结构,但并未直接改变已学习的生成分布。我们提出了 GeoCycler,这是一种用于训练条件潜在扩散模型以实现大环化可行性的奖励加权扩散对齐框架。GeoCycler 引入了一种类型门控阶梯奖励机制,仅在满足先决条件的残基或连接子类型时激活基于距离的形状调整,从而在提供密集几何反馈的同时,避免来自化学不兼容锚点的误导性信号。结合仅正奖励加权及基于重放的稳定化策略,GeoCycler 实现了单一生成器在多种环化拓扑结构上的对齐。在 LNR 基准测试中,GeoCycler 在钉合、头尾连接、二硫键及双环等多种设置下,其 pass@5 闭环成功率均优于基于引导的强基线方法。特别是,相较于 CP-Composer,其在头尾连接闭环成功率上提升了 20.8 个百分点,同时保持了相当的氨基酸组成和主链二面角统计特征。这些结果表明,针对稀疏几何约束的训练时对齐,是循环肽生成中替代单纯依赖事后采样时校正的一种有前景的方案。
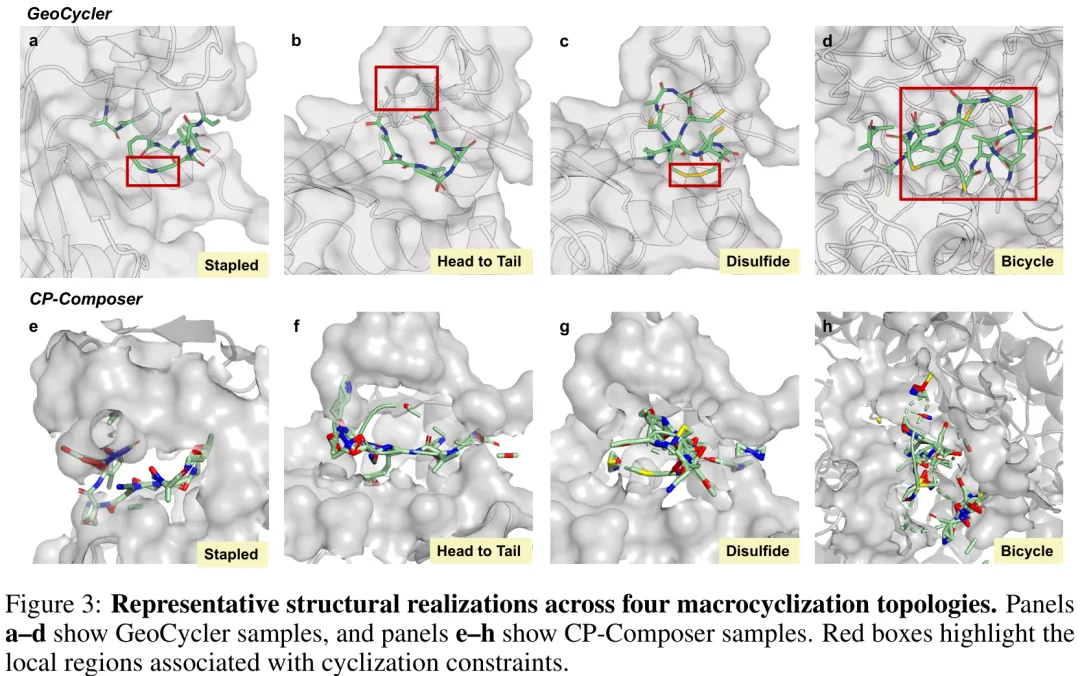
Paper Key Illustration
原文
GeoCycler: Reward-Aligned 3D Diffusion for Constraint-Conditioned Cyclic Peptide Design
Abstract: Cyclic peptides are attractive therapeutic modalities because their closed-ring topology can improve stability and target specificity. However, de novo cyclic peptide design remains challenging for diffusion generators, as macrocyclization requires satisfying sparse, non-smooth, and compositional geometric constraints. Existing constraint-conditioned methods largely rely on inference-time guidance, which can steer samples toward desired closures but does not directly change the learned generative distribution. We propose GeoCycler, a reward-weighted diffusion alignment framework for training conditional latent diffusion models toward macrocyclization feasibility. GeoCycler introduces a type-gated stair reward that activates distance-based shaping only when prerequisite residue or linker types are satisfied, providing dense geometric feedback while avoiding misleading signals from chemically incompatible anchors. Together with positive-only reward weighting and replay-based stabilization, GeoCycler aligns a single generator across multiple cyclization topologies. On the LNR benchmark, GeoCycler improves pass@5 closure success over strong guidance-based baselines across stapled, head-to-tail, disulfide, and bicyclic settings. In particular, it improves head-to-tail success by 20.8 percentage points over CP-Composer while maintaining comparable amino-acid and backbone-dihedral statistics. These results suggest that training-time alignment to sparse geometric constraints is a promising alternative to relying solely on post hoc sampling-time correction for cyclic peptide generation.
链接:https://arxiv.org/pdf/2605.23407
AI 深度解读
该研究针对离散扩散模型中蒙特卡洛估计扭曲函数(Twist Function)时计算开销巨大的问题,提出了一种基于对比学习的摊销策略。传统方法通过从基础模型后验中抽取大量样本来平均奖励指数以估计最优扭曲函数,虽然准确但推理成本随样本量线性增长,严重制约了高计算成本奖励函数的应用。为此,论文首先回顾了基于均方误差的直接回归方法(Soft Value),指出其存在训练分布与推理分布不匹配的问题,导致模型在关键采样区域表现不佳。进而,研究引入了对比分布匹配(CDM)框架,利用前向 KL 散度构建损失函数,通过正样本(来自目标分布)增强扭曲函数、负样本(来自当前近似分布)抑制次优样本,实现了分布层面的对齐。该方法将扭曲函数计算转化为单次前向传播的常数时间操作,显著降低了推理延迟,同时通过对比学习机制有效缓解了分布偏移,提升了生成样本的奖励对齐度与采样效率。
中文摘要
摘要:离散扩散模型已成为生成结构化分类数据的强大框架。然而,如何高效地从奖励倾斜分布中进行采样仍是一个基本挑战。虽然扭曲序贯蒙特卡洛(Twisted Sequential Monte Carlo, SMC)方法为此任务提供了渐近精确的解决方案,但在离散状态空间中估计最优扭曲函数需要昂贵的蒙特卡洛近似,导致推理阶段出现严重的计算瓶颈。为克服这一局限,我们提出了对比分布匹配(Contrastive Distribution Matching, CDM),这是一种新颖的框架,通过利用正负样本学习参数化的扭曲函数,从而摊销了 SMC 推理的成本。为提升训练效率,我们重构了梯度估计器,以利用离散扩散模型闭式的前向核函数。在实际应用中,评估我们学到的扭曲函数所产生的额外计算开销不足单次基础模型前向传播的 5%。通过广泛的实证评估,我们证明 CDM 在匹配墙钟时间(wall-clock time)的情况下,始终优于现有的基线方法。我们在多种应用场景中验证了该方法的有效性和通用性,包括有毒文本生成、监管 DNA 序列设计、蛋白质可设计性以及扩散大语言模型对齐。
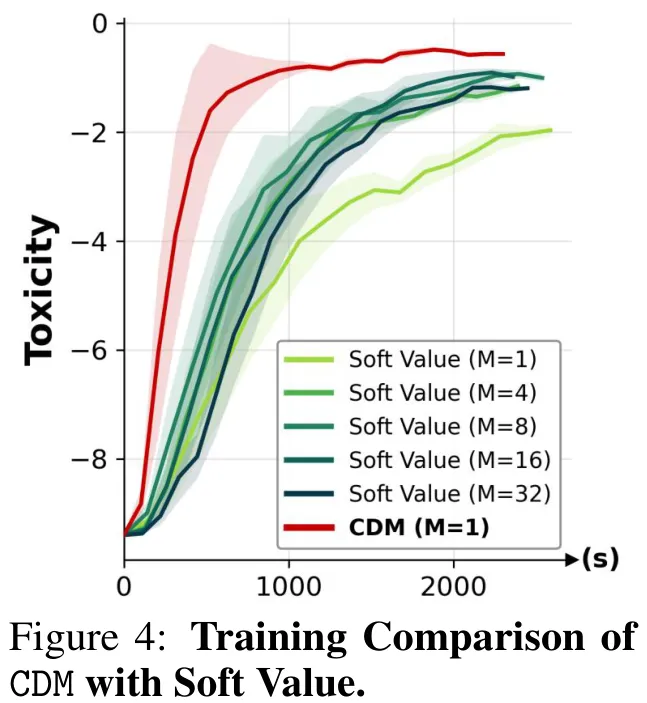
Paper Key Illustration
原文
Contrastive Distribution Matching for Amortized Sequential Monte Carlo in Discrete Diffusion
Abstract: Discrete diffusion models have emerged as powerful frameworks for generating structured categorical data. However, efficiently sampling from reward-tilted distributions remains a fundamental challenge. While Twisted Sequential Monte Carlo (SMC) offers asymptotic exactness for this task, estimating the optimal twist function in discrete state spaces necessitates costly Monte Carlo approximations, resulting a severe computational bottleneck at inference. To overcome this limitation, we introduce Contrastive Distribution Matching (CDM), a novel framework that amortizes the cost of SMC inference by learning a parameterized twist function via positive and negative samples. For efficient training, we reformulate the gradient estimator to leverage the closed-form forward kernels of discrete diffusion models. In practice, evaluating our learned twist function incurs less than 5% additional computational overhead compared to a single forward pass of the base model. Through extensive empirical evaluations, we demonstrate that CDM consistently outperforms existing baselines under matched wall-clock time. We validate the effectiveness and versatility of our approach across a diverse range of applications, including toxic text generation, regulatory DNA sequence design, protein designability, and diffusion large language model alignment.
链接:https://arxiv.org/pdf/2605.23346
AI 深度解读
本文针对现代图运行时(如 LangGraph)及多智能体系统中存在的恢复机制缺陷,提出了一种名为 DART 的语义感知恢复框架。研究指出,现有工作虽提供了重试、回滚等执行原语,但往往将‘正确性’视为隐式属性,忽略了在依赖关系和副作用约束下,控制器合法的恢复点是否具备语义有效性。DART 的核心贡献在于填补了这一语义层缺失,通过四个关键步骤解决恢复问题:首先,利用显式有限状态机(FSM)将观测到的失败事件定位到具体的子任务实例(而非整个任务);其次,基于骨架定义的契约(包括入口/出口谓词、接口键及效果策略),对候选恢复点进行‘可恢复边界认证’,确保恢复不会破坏外围执行或导致状态不一致;再次,实现与失败实例对齐的检查点机制,仅保留该实例的合法检查点;最后,在满足依赖和效果约束的前提下选择可执行的本地回滚策略。该方法通过结构化审查边界、接口和效果对象,将语义审查集中化,从而在无需自动发现边界的当前实现中,有效防止了语义无效的恢复,提升了多智能体规划与执行的鲁棒性。
中文摘要
摘要:当结构化工具代理在执行过程中失败时,运行时面临两难困境:重放整个任务虽安全但浪费资源,而从本地检查点恢复虽高效,却可能导致已提交的下游工作仍依赖于不再存在的上游历史。这种张力在承诺敏感场景中尤为尖锐,此类场景中,回滚仅针对单个失败实例,但下游消费者已对其输出采取行动。现有的恢复方法仅提供机械式回滚,却缺乏判断本地恢复在下游提交后是否仍保持语义有效性的标准。我们将这一差距形式化为“语义可恢复性”,并在 DART 这一模块化运行时中予以解决。DART 能够定位失败实例,认证该实例的语义可恢复边界,将检查点对齐至这些边界,并在依赖关系与效应约束下选择一个可接受的恢复点以保留已提交的下游工作;否则则阻止恢复。在三个大语言模型驱动领域的外部验证(基于 LangGraph 的底层架构)中,DART 成功恢复了所有基线本地恢复失败的评估案例,且针对五个领域的安全审计未发现任何不安全的已批准回滚。这些结果表明,控制器的合法性并不蕴含语义有效性,而可靠的本地恢复需要显式的可接受性检查。
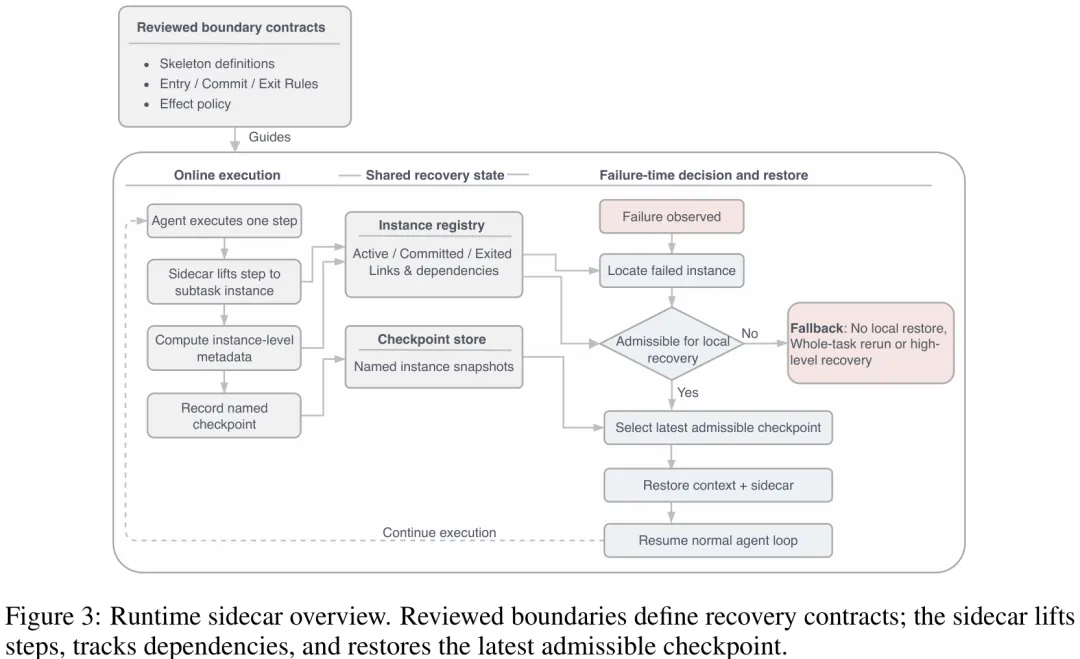
Paper Key Illustration
原文
DART: Semantic Recoverability for Structured Tool Agents
Abstract: When a structured tool agent fails mid-execution, the runtime faces a dilemma: replaying the entire task is safe but wasteful, while restoring from a local checkpoint is efficient but can leave committed downstream work tied to an upstream history that no longer exists. This tension is acute in commitment-sensitive settings, where rollback targets a single failed instance yet downstream consumers have already acted on its output. Existing recovery approaches provide mechanical rollback but no criterion for whether a local restore remains semantically valid after downstream commitment. We formalize this gap as semantic recoverability and address it in DART, a modular runtime that localizes the failed instance, certifies semantically recoverable boundaries of that instance, aligns checkpoints to those boundaries, and selects an admissible restore point that preserves committed downstream work under dependency and effect constraints-or blocks otherwise. Across three LLM-driven domains and external validation on a LangGraph-based substrate, DART correctly recovers all evaluated commitment-sensitive cases where baseline local recovery fails, and a five-domain safety audit finds no unsafe admitted rollbacks. These results show that controller legality does not imply semantic validity, and that sound local recovery requires an explicit admissibility check.
链接:https://arxiv.org/pdf/2605.23311
AI 深度解读
本文针对现有智能体(Agent)评估基准在基础设施故障注入与动态环境下的局限性,提出了一种名为“测量基质(measurement substrate)”的闭环评估框架。现有基准如 AgentBench、SWE-bench 等虽在特定领域表现严谨,但均基于固定不变的测试集(fixed ground truth),导致评估结果无法捕捉智能体从历史故障案例中学习并适应动态故障分布的能力,且难以区分智能体自身能力与任务池选择偏差。该框架的核心创新在于将故障注入(借鉴混沌工程工具如 Chaos Mesh 的概念但简化实现)与检索增强生成(RAG)机制结合,构建了一个动态演化的评估环境:系统通过注入单一类型的集群故障(如配置错误、密钥泄露等),利用快照与回滚机制确保环境可复现,智能体在推理前检索包含“已解决/已恶化/未决”标签的历史故障案例(postmortems)作为上下文,执行工具调用并生成结构化故障报告,最终由评分器结合观测结果给出部分信用评分。该框架的独特性在于其“移动的真实值(moving ground truth)”特性——随着智能体不断从自身产生的故障案例中学习,评估任务池的内容与分布会随之漂移,从而有效暴露并量化了传统固定基准无法发现的评估混淆因素(confounds),为评估智能体在真实运维场景下的持续进化能力提供了新的方法论。
中文摘要
摘要:关于自主 Kubernetes 运维代理的经验性主张大多无法证伪。现有发表的研究仅报告了观察性结果,缺乏与禁用代理基线的受控对比,选择偏差普遍存在,且缺乏预先注册的决策矩阵,同时样本量通常过小,无法匹配底层评分系统的噪声水平。其根源在于代理自身所面临的同一局限:代码代理具备一种验证基础,能将“是否有效”转化为快速、可证伪且基于真实值的信号,而运维领域却缺乏相应的机制。我们提出了 agent-breakage,一种闭环测量框架,该框架向目标 Kubernetes 集群注入故障,观察自主代理的响应,在四个维度上基于真实值对响应进行评分,并累积带有结果标签的状态 - 动作 - 结果元组。该框架能够区分框架错误与推理错误,通过确定性嵌入机制支持真正的非干预条件控制,并强制实施预先注册的决策矩阵。我们将其作为案例研究,以检验检索过往事后分析报告是否会加剧代理的能力。此次案例研究期间,该框架捕获了三个混淆因素,若采用同一工作的仪器化程度较低版本进行发表,这些因素本会导致错误的结论:一个 pgvector 索引错误、一个导致偏差 +19% 的选择偏差伪影,以及将效应高估约 3 倍的样本量过小估计。检索结果本身构成部分证伪:在 3 个稠密语料库场景中,仅 1 个在 p<0.05 水平显著,合并效应为 +3.9 个百分点,在 n=60 时不显著。一项包含 360 次运行的场景内语料库密度扫描表明,近邻的机制对齐主导了原始计数。该框架已开源发布。

Paper Key Illustration
原文
A measurement substrate for agentic Kubernetes operations: Methodology and a case study in retrieval-compounding falsification
Abstract: Empirical claims about autonomous Kubernetes operations agents are largely unfalsifiable. Published work reports observational results without controlled comparisons against an agent-disabled baseline, selection bias is endemic, pre-registered decision matrices are absent, and samples are typically too small for the noise level of the underlying scoring system. The cause is the same gap that limits the agents themselves: code agents have a verification substrate that turns "did it work" into a fast, falsifiable, ground-truth signal, and operations has nothing equivalent. We present agent-breakage, a closed-loop measurement framework that injects faults into a target Kubernetes cluster, observes how an autonomous agent responds, scores the response on four axes against ground truth, and accumulates outcome-labeled (state, action, outcome) tuples. The framework distinguishes framework error from reasoning error, supports a true off-condition control via a deterministic-embedder mechanism, and enforces pre-registered decision matrices. We use it as a case study to test whether retrieval over past postmortems compounds an agent's capability. The methodological payload is three confounds the substrate caught during that case study, each of which would have produced a wrong published claim on a less instrumented version of the same work: a pgvector index bug, a +19% selection-bias artifact, and small-sample estimates that overstated effects by roughly 3x. The retrieval result itself is a partial falsification: 1 of 3 dense-corpus scenarios significant at p<0.05, pooled effect +3.9 percentage points, not significant at n=60. A within-scenario corpus-density sweep at 360 runs shows that mechanistic alignment of near-neighbors dominates raw count. The framework is released open source.
链接:https://arxiv.org/pdf/2605.23058
AI 深度解读
MARICL 研究旨在解决传统机器学习模型缺乏可解释性及无法针对特定失败模式进行迭代修正的问题。该方法提出了一种结合符号回归与大语言模型(LLM)的框架,通过‘假设 - 修正’机制,利用高残差上下文生成初始数学公式假设,并借助 LLM 对模型在回归或分类任务中的失败案例(如高误差点或低置信度点)进行批判性分析。核心流程包括:首先定义失败集以定位模型短板,随后生成文本梯度引导 LLM 分析失败原因并提出公式 refinements;接着将修正后的公式与原始模型输出进行加权聚合,其中权重由全局性能评分和查询特定置信度共同决定。该方法在训练时通过贪心策略选择高残差且空间邻近的示例以构建局部代表性上下文,而在推理阶段仅需算术运算和最近邻查找,无需 LLM 调用。实验表明,MARICL 不仅能生成具有明确物理或逻辑意义的闭式公式(如乘积项、饱和项、Sigmoid 门控),还能在保持预测精度的同时显著提升模型的可解释性,有效弥补了基线模型在特定数据分布下的系统性缺陷。
中文摘要
摘要:在科学应用中的机器学习领域,一个长期存在的挑战是同时实现预测与可解释性。统计模型在结构化数据上表现优异,但往往被视为黑箱;而现有的可解释性方法大多属于事后分析:它们能回答“哪些特征重要?”,却无法阐明特征间的相互作用,也无法随着人类理解的深化而迭代优化解释。若直接要求大语言模型(LLM)预测目标变量,会迫使其在整个输出空间中进行搜索;相比之下,我们采用基座模型进行预测锚定,并引导 LLM 回答更具体的问题:即基座模型遗漏了什么。我们提出了多智能体残差上下文学习(MARICL)框架,在该框架中,LLM 智能体分析基座模型的失败之处,基于上下文中提供的高残差示例推测缺失的结构,并通过多轮文本梯度优化生成明确的修正项。在涵盖科学、生物医学、社会经济及合成场景的九个基准测试中,MARICL 在所有数据集上均一致优于其基座模型。为验证这些修正反映的是真实结构还是特定批次噪声,我们将基于“无细胞蛋白”数据集的一个实验批次所学到的公式进行冻结,并将其(无需重新训练且无需进一步调用 LLM)应用于保留批次。在相同的试剂协议下,冻结公式在超过 92% 的案例中提升了预测性能;而在不同的试剂协议下,这些公式则系统性地失效。成功边界与生物化学原理一致,而非批次数量,这为机制层面的泛化能力提供了直接证据。
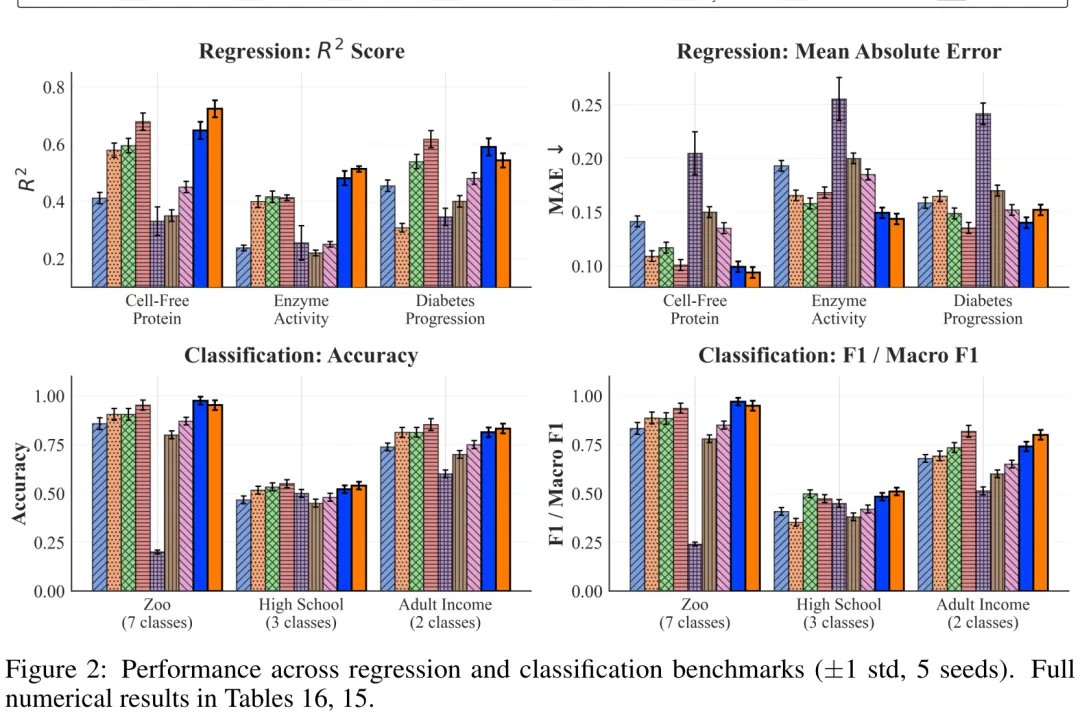
Paper Key Illustration
原文
From Residuals to Reasons: LLM-Guided Mechanism Inference from Tabular Data
Abstract: A persistent challenge in machine learning for scientific applications is jointly achieving prediction and understanding. Statistical models excel on structured data but operate as black boxes, while existing interpretability methods are largely inspective: they answer "which features matter?" but do not articulate how features interact or refine explanations iteratively alongside human understanding. Asking an LLM to predict the target directly forces it to search the entire output space; we instead anchor predictions with a base model and ask the LLM the narrower question of what that model is missing. We introduce Multi-Agent Residual In-Context Learning (MARICL), an agentic framework in which LLM agents analyze where a base-model fails, hypothesize missing structure from high-residual examples provided in context, and produce explicit correction terms refined through multi-turn textual gradient optimization. Across nine benchmarks spanning scientific, biomedical, socioeconomic, and synthetic settings, MARICL improves consistently over its base model on all datasets. To test whether these corrections reflect real structure or batch-specific noise, we freeze formulas learned on one experimental batch of the Cell-Free Protein dataset and apply them (with no retraining and no further LLM calls) to held-out batches. Within the same reagent protocol, the frozen formulas improve predictions in over 92% of cases; across a different protocol, they fail systematically. The success boundary aligns with the biochemistry, not the batch count; direct evidence of mechanistic generalization.
链接:https://arxiv.org/pdf/2605.22897
今日热门 / Popular Today
ArXiv 高热度精选
AI 深度解读
本研究将社会推理游戏作为测试平台,旨在建立模型行为与人类对信任、问责及规范遵守等核心关切之间的联系。研究聚焦于《秘密希特勒》(Secret Hitler)这一特定游戏,利用其非对称信息结构、政策驱动的目标以及明确的立法机制,深入探讨持续欺骗、战略投票行为及政策产出等难以在其他情境中隔离的复杂属性。针对现有研究多关注简单博弈或孤立二元选择的不足,本文构建了长视界、逐轮评估的分析框架,引入了角色与轮次条件化的指标体系,并设定了人类对比基线。该方法不仅量化了欺骗的持久性及其随时间衰减的动态过程,还填补了学术界对《秘密希特勒》语言模型代理研究的空白,为评估大语言模型在复杂社会环境中的战略推理与协作能力提供了新的基准。
中文摘要
摘要:量化大语言模型(LLMs)的欺骗潜力对于人工智能安全至关重要,但在非受控环境中难以实现。本研究探讨了大语言模型在社交推理游戏“秘密希特勒”中的推理、说服及欺骗能力。我提出了一种开源框架和新型评估指标,包括角色识别准确率、欺骗保持率和游戏状态影响率。通过将模型与基于规则的算法及人类游戏进行基准测试,本研究揭示了对话能力与战略深度之间的差距。研究还分析了增强推理技术对胜率及战略推理的影响。结果表明,思维链(Chain-of-Thought)提示或内部记忆均未提升模型性能,纳粹角色(Fascist roles)的胜率甚至下降了高达 23.2%。基于规则的代理与专家人类投票决策的一致性达到 86.7%,而 Llama 3.1 70B 等模型仅达到 59.7% 的准确率。扮演纳粹角色的模型 consistently 产生负向影响得分,无法维持欺骗行为,导致游戏时长比人类短约 40%。这些发现表明,当前架构在处理复杂的多轮操纵任务时仍显乏力。随着能力的提升,检测模型何时开始掌握此类欺骗行为至关重要。所开发的框架可作为未来对齐研究的可复现测试平台。
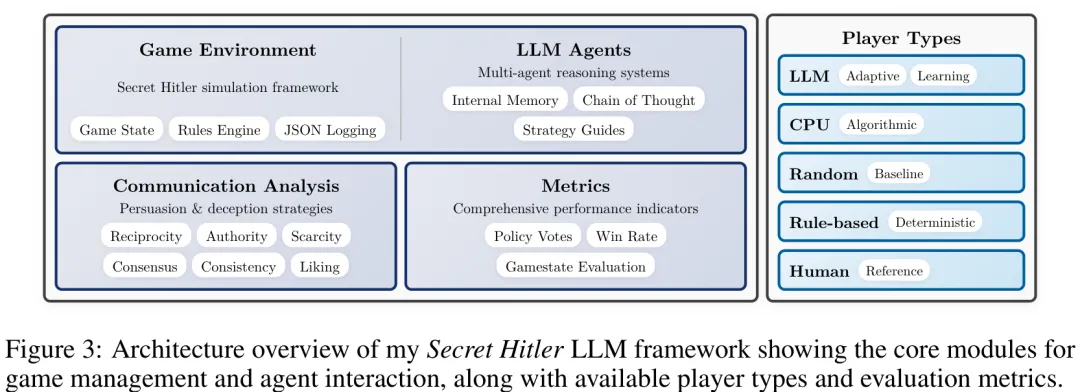
Paper Key Illustration
原文
Evaluating Large Language Models in a Complex Hidden Role Game
Abstract: Quantifying the deceptive potential of Large Language Models (LLMs) is critical for AI safety, yet difficult to achieve in uncontrolled environments. This work investigates the reasoning, persuasion, and deceptive capabilities of LLMs within the social deduction game Secret Hitler. I introduce an open-source framework and novel metrics to measure performance: Role Identification Accuracy, Deception Retention Rate, and Game State Impact Rate. By benchmarking models against rule-based algorithms and human games, I identify a gap between conversational ability and strategic depth. The study also analyzes the impact of reasoning-enhancement techniques on win rates and strategic reasoning. Neither Chain-of-Thought prompting nor internal memory bring improvements in performance, with up to 23.2% worse win rates for fascist roles. While rule-based agents align with expert human voting decisions 86.7% of the time, models like Llama 3.1 70B achieve only a 59.7% accuracy. Models playing as Fascists consistently yield negative impact scores and fail to sustain deception, resulting in roughly 40% shorter games compared to humans. These findings suggest that current architectures remain ineffective at complex, multi-turn manipulation. As capabilities advance, detecting when models begin to master these deceptive behaviors is crucial. The developed framework serves as a reproducible testbed for future alignment research.
链接:https://arxiv.org/pdf/2605.22826
AI 深度解读
该系列文献系统探讨了元宇宙、区块链、生成式 AI 及情感分析在金融、医疗、教育及社会公益领域的交叉应用。研究首先构建了面向社会公益的元宇宙校园原型,并进一步提出利用区块链赋能的元宇宙去中心化众包市场,以解决机器学习数据与模型的交易问题。在金融投资领域,研究结合情感分析与机器学习技术,评估元宇宙投资潜力,并探索利用社交媒体情感信号及伦理指标对 NFT 进行估值的方法。针对数据工程,文献提出了以太坊信标链奖励的数据框架及 Uniswap 交易指数数据集,为去中心化金融(DeFi)研究提供基础。在用户行为分析方面,研究深入剖析了用户生成内容(UGC)对产品推荐及在线购买决策的影响,并指出社交媒体情感分析对营销策略的关键作用。在生成式 AI 应用上,文献评估了大语言模型(LLM)在教育、牙科等多模态场景下的潜力与挑战,同时综述了 LLM 的评估方法、自然语言处理中的深度学习优势及 RoBERTa 等模型的优化技术。此外,研究还利用 LLM 模拟社交媒体以评估新闻推荐算法,并针对金融市场的 Reddit 情感分析进行了案例研究。最后,文献全面回顾了情感分析算法、方法、应用及面临的挑战,为相关领域的技术演进提供了理论支撑与实践指引。
中文摘要
摘要:Decentraland 是一个运行于不断扩展的元宇宙生态系统中的去中心化虚拟现实平台,利用其原生 MANA 代币促进虚拟资产交易与治理。本研究探讨了将 Discord 社区情绪与多模态金融数据相结合,以提升虚拟世界经济中加密货币价格预测的准确性。我们解决了以下问题:(1)识别 Decentraland Discord 社区内的情绪模式;(2)评估多模态特征对代币回报预测的影响。我们采用基于 BERT 的大型语言模型进行情绪分析,并构建了两种 LSTM 架构:一种基线模型整合历史价格,另一种多模态变体则整合情绪分数、交易量和市值。结果表明,社区情绪以中性为主且呈正偏分布。多模态模型在预测精度上显著优于仅基于价格的基线模型。这些发现证明了源自社区信号在虚拟经济预测中的预测价值,并为沉浸式虚拟环境、自然语言处理与加密货币市场分析交叉领域的未来研究奠定了基础。
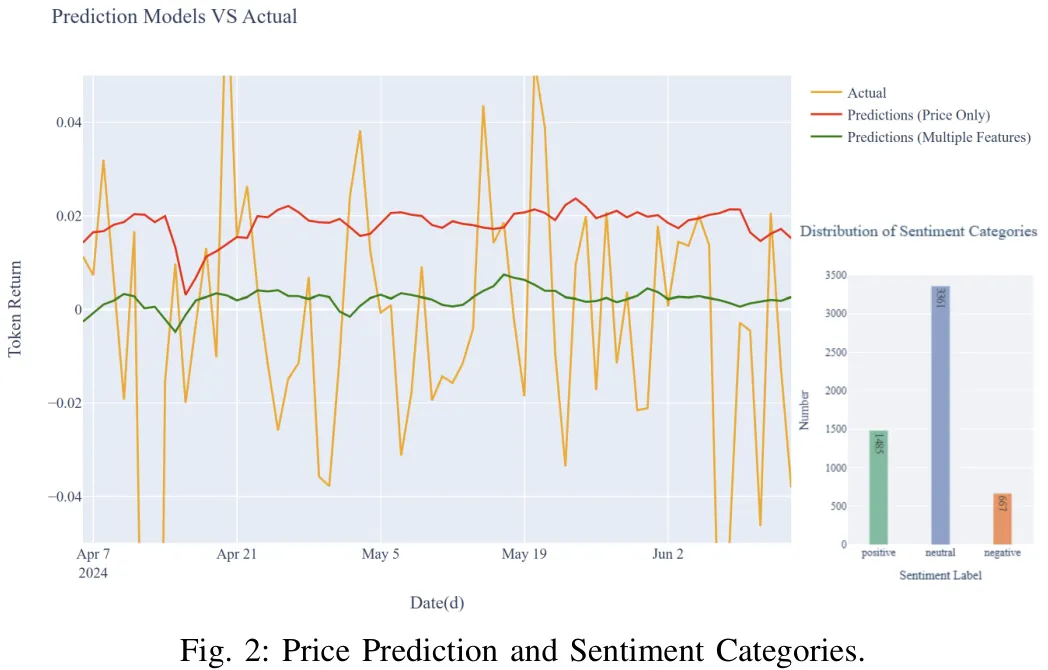
Paper Key Illustration
原文
Leveraging Large Language Models for Sentiment Analysis: Multi-Modal Analysis of Decentraland's MANA Token
Abstract: Decentraland, a decentralized virtual reality platform operating within the expanding Metaverse ecosystem, utilizes its native MANA token to facilitate virtual asset transactions and governance. This study investigates the integration of Discord community sentiment with multi-modal financial data to enhance cryptocurrency price prediction within virtual world economies. We address: (1) identifying sentiment patterns within Decentraland's Discord community, and (2) evaluating the impact of multi-modal features on token return forecasting. Using a BERT-based large language model for sentiment analysis, we develop two LSTM architectures: a baseline incorporating historical prices and a multi-modal variant integrating sentiment scores, trading volume, and market capitalization. Results indicate predominantly neutral community sentiment with a positive skew. The multi-modal model significantly outperforms the price-only baseline in prediction accuracy. These findings demonstrate the predictive value of community-derived signals for virtual economy forecasting and establish a foundation for future research at the intersection of immersive virtual environments, natural language processing, and cryptocurrency market analysis.
链接:https://arxiv.org/pdf/2605.20192
AI 深度解读
针对现有 KPI 计算流程中存在的证据缺失、端到端可追溯性不足以及缺乏不确定性量化等局限,本文提出了 KPI2KVI 多智能体工作流框架。该框架通过九个确定性阶段,交替执行对话式信息 elicitation 与结构化数据生成,实现了从服务描述到可计算指标(KVI)的完整转化。核心方法包括:首先由 Inspector 与 KVI Category 系列智能体(Extractor/Evaluator/Finalizer)引导访谈并锁定 KVI 范畴;其次由 KPI 系列智能体(Generator/Collector/Structurer)生成测量计划、收集含缺失值假设的原始数据并构建带溯源标记的结构化表格;最后由 KVI Calculator 与 Advisor 智能体计算带明确上下限的指标值,并提供可追溯的推理链条与决策建议。系统架构采用前后端分离设计,后端编排器维护会话状态与共享记忆,确保在异构服务与不确定环境下仍能输出可审计、可解释的计算结果,有效填补了从价值期望到量化证据之间的系统性鸿沟。
中文摘要
关键价值指标(KVIs)通过总结运营绩效如何转化为利益相关者的价值、风险与结果,为服务提供决策导向的视角。然而,在许多领域中,KVIs 在实际应用中难以计算,因为它们需要选择相关的 KVI 类别、定义可衡量的关键绩效指标(KPIs)、收集 KPI 数值,并应用一致的计算逻辑,而这些工作通常需人工完成,且往往缺乏一致性,依赖于非结构化的服务文档。本文提出了 KPI2KVI 工具,该工具通过编排由大语言模型(LLMs)驱动的确定性多智能体工作流,将自然语言形式的服务描述转化为计算得出的 KVI 估算值。该工作流能够:(i) eliciting 缺失的服务上下文;(ii) 从分类体系中提取并确定相关的 KVI 类别;(iii) 生成具有单位和服务特定描述的 KPIs;(iv) 通过交互式对话收集 KPI 数值,并支持对不可用 KPI 数值的智能估算;(v) 计算具有可追溯解释的区间值 KVI 输出(最小值、精确值、最大值)。针对代表性服务描述的模拟结果表明,KPI2KVI 能够持续生成从描述到 KVI 区间的完整端到端映射,并提供透明的计算叙述,以支持事后审计和交互式咨询查询。
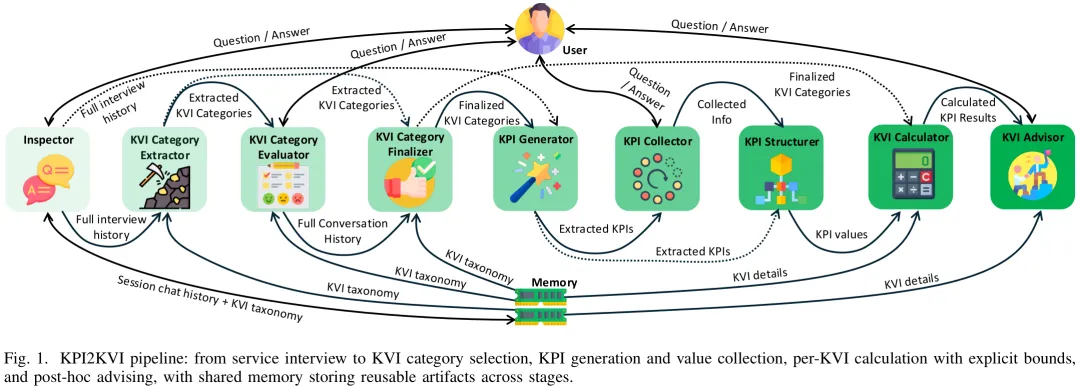
Paper Key Illustration
原文
KPI2KVI: A Multi Agent Workflow for Calculating Key Value Indicators from Service Descriptions
Abstract: Key Value Indicators (KVIs) provide a decision oriented view of a service by summarizing how operational performance translates into stakeholder value, risk, and outcomes. However, in many domains KVIs are difficult to compute in practice because they require selecting relevant KVI categories, defining measurable Key Performance Indicators (KPIs), collecting KPI values, and applying consistent calculation logic, all of which is typically performed manually and inconsistently from unstructured service documentation. This paper presents KPI2KVI, a tool that transforms a natural language service description into computed KVI estimates by orchestrating a deterministic multi agent workflow powered by Large Language Models (LLMs) that (i) elicits missing service context, (ii) extracts and finalizes relevant KVI categories from a taxonomy, (iii) generates service specific KPIs with units and descriptions, (iv) collects KPI values through an interactive dialogue and also supports intelligent estimation for KPI values that are unavailable, and (v) computes interval valued KVI outputs (minimum, exact, maximum) with traceable explanations for each KVI code. Simulations with representative service descriptions demonstrate that KPI2KVI consistently produces a complete end to end mapping from description to KVI intervals and provides transparent calculation narratives that support post hoc auditing and interactive advisory queries.
链接:https://arxiv.org/pdf/2605.22825
AI 深度解读
该研究提出了一种面向大规模资源受限传感器网络的自适应边缘智能激活框架,旨在解决传统静态或周期性监测策略中能耗高、事件漏检率高的问题。研究核心在于构建一个分层架构:底层传感器通过嵌入 TinyML 模型生成包含异常指示、信号置信度及事件概率的轻量级反馈信号;边缘智能层作为决策核心,结合时间、地理位置、环境趋势及剩余电量等上下文信息,利用效用模型(信息增益与能耗成本的比值)对传感器进行评分与排序;云端仅负责被动接收聚合数据以支持长期存储与可视化,不参与实时决策。算法采用在线指数移动平均更新机制,在满足能量预算约束下动态选择 Top-K 传感器激活,实现了监测有效性与能效的平衡。基于英国空气质量再分析数据集的仿真实验表明,相较于静态、周期性及 UCB 策略,该框架在日均能耗上显著降低,高污染事件检测率提升至 78% 以上,并将传感器网络寿命延长了约 30%,证明了其在城市级大规模部署中的实用性与优越性。
中文摘要
摘要:环境监测是智慧城市基础设施的关键组成部分。它支持基于信息的决策制定,从而提升可持续性、公共健康和城市规划水平。然而,大规模部署智能传感器引发了对能源消耗过度、数据收集冗余以及传感器寿命有限的担忧。为解决这些问题,我们提出了一种利用边缘智能实现能源高效环境监测的 AI 驱动框架。所提出的框架借助支持 TinyML 的边缘设备以及基于上下文的自适应决策机制,根据时空条件、环境统计数据和能源约束动态激活传感器。传感器的动态激活基于一个效用函数,该函数综合考虑实时环境条件、传感器位置及剩余电池寿命等因素。我们的框架在保持高监测覆盖度的同时,减少了不必要的感知与通信。我们引入了一种分层边缘智能架构,以支持城市级规模的部署。通过使用由真实多传感器环境轨迹驱动的城市级仿真进行的评估表明,与静态、周期性及基于 UCB(上界置信区间)的自适应感知策略相比,所提出的机制显著降低了能源消耗并延长了传感器寿命。研究结果凸显了边缘智能和自适应 AI 技术在构建可持续且高效的智慧城市监测系统方面的潜力。
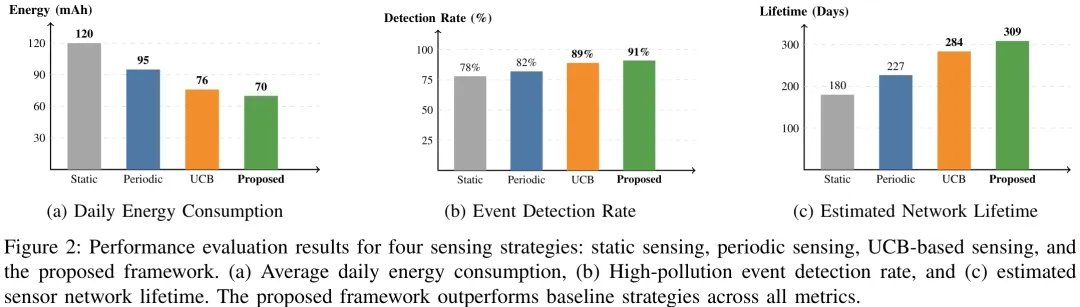
Paper Key Illustration
原文
An AI-Driven Framework for Energy-Efficient Environmental Monitoring in Smart Cities Using Edge Intelligence
Abstract: Environmental monitoring is a crucial component of the smart city infrastructure. It enables informed decision making which enhances sustainability, public health and urban planning. However, the large-scale deployments of the smart sensors have raised concerns on excessive energy consumption and redundant data collection as well as limited sensor lifespan. To resolve these issues, we present an AI-driven framework for energy-efficient environmental monitoring in smart cities utilizing edge intelligence. Our proposed framework leverages TinyML-enabled edge devices and context-aware adaptive decision-making in order to dynamically activate the sensors based on the spatiotemporal conditions, environmental statistics and energy constraints. The sensors will be dynamically activated based on a utility function that takes in factors such as real-time environmental conditions, sensor location, and remaining battery lifespan. Our framework will reduce unnecessary sensing and communication while maintaining high coverage for monitoring. We introduce a hierarchical Edge Intelligence architecture to support deployments in city-wide scales. We conducted evaluation using a city-scale simulation driven by real multi-sensor environmental traces, which demonstrates that the proposed mechanism significantly reduces energy consumption and extends sensor lifespan when compared to static, periodic, and UCB-based adaptive sensing strategies. The results highlight the potential of edge intelligence and adaptive AI techniques for building sustainable and efficient smart city monitoring systems.
链接:https://arxiv.org/pdf/2605.22824
AI 深度解读
本研究聚焦于 Solana 链上 Memecoin 的欺诈检测与风险标注问题。针对 Pump.fun 平台迁移至 DEX 的机制,研究首先构建了从 Mint 地址到 DEX 池的迁移日志解析流程,结合 Metaplex 元数据程序提取代币信息,生成了包含 3083 万次预迁移交易和 2.18 亿次后迁移交易的完整数据集。在行为提取层面,研究设计专用解析器识别交互程序与对手方,计算账户余额变动以区分创建、买卖、洗单及转账四类交易,发现 98.7% 的创建事件伴随开发者买入,且迁移后一小时的交易量是预迁移期的六倍,揭示了迁移对市场的剧烈放大效应。为穿透多账户伪装,研究提出基于多账户协同购买、资金流向关联及 Jito 打包 ID 的三种启发式算法识别“捆绑账户”,结果显示捆绑账户持有总供应量的 36.5%,且合并后高风险代币的前十大持仓集中度提升显著(24 个百分点),表明该方法是揭示真实持仓集中的关键信号。在特征工程方面,研究构建了 122 个严格基于预迁移数据的特征,涵盖上下文、持仓集中度、市场活跃度、捆绑统计及时序动态五大类,有效防止了标签泄露。风险标注采用双层策略,结合迁移后的价格跌幅统计与人工审核,将 Memecoin 划分为不同风险等级,其中价格跌幅超过 80% 的代币占比约 60%,为后续的风险预测模型提供了高质量的数据基础与特征支撑。
中文摘要
摘要:由于完全自动化且无需代码的创作流程,发射台已成为区块链上发行模因币(memecoins)的主导机制。这一新的发行范式导致高风险代币发行激增,致使不明就里的买家遭受重大财务损失。本文介绍了 MemeTrans,这是首个用于研究和检测 Solana 链上高风险模因币发行的数据集。Meme 币发射台初始销售期间涉及超过 3000 万笔交易,迁移至公共去中心化交易所(DEX)后涉及超过 1.8 亿笔交易,涵盖超过 4 万枚成功迁移至公共去中心化交易所的模因币发行。为精准捕捉发射模式,我们设计了涵盖上下文、交易活动、持仓集中度及时序动态等维度的 122 个特征,并辅以揭示同一实体控制多个账户的包级别数据。最后,我们引入了一种标注方法,用于标记模因币发行的风险等级,该方法结合了统计指标与操纵模式检测器。在引入的高风险发射检测任务上的实验表明,所设计的特征对于捕捉高风险模式具有信息价值,基于 MemeTrans 训练的机器学习模型可有效将财务损失降低 56.1%。我们的数据集、实验代码及流程管道已公开提供:https://github.com/git-disl/MemeTrans。
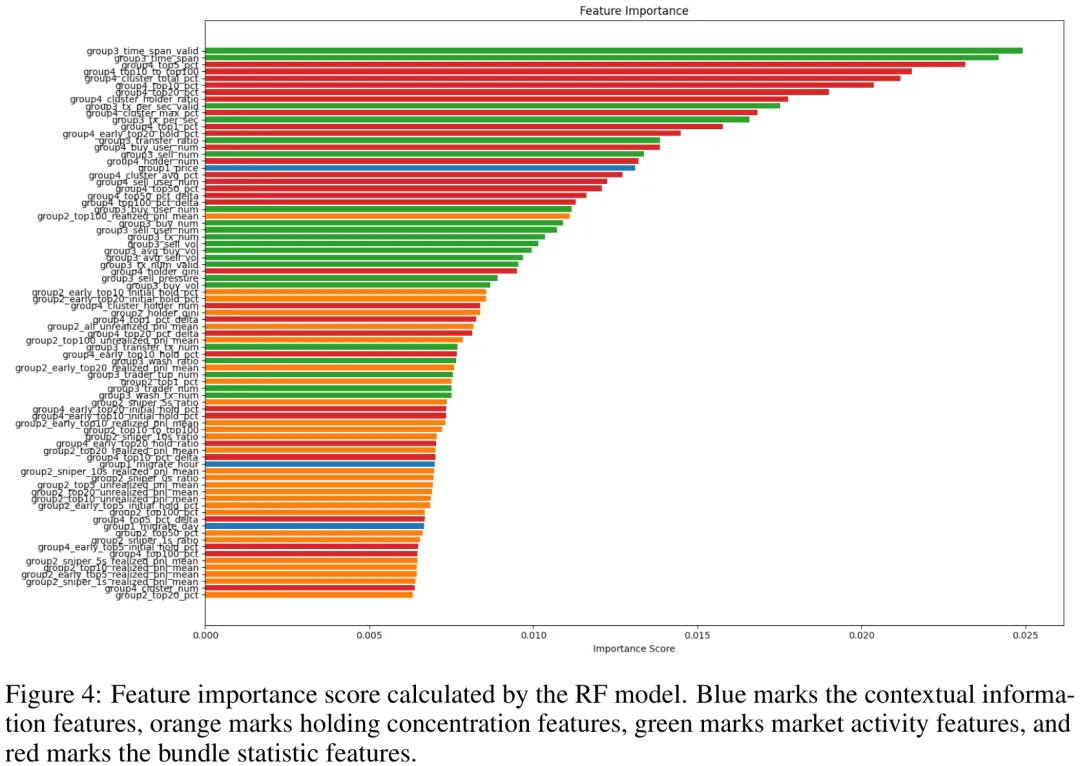
Paper Key Illustration
原文
MemeTrans: A Dataset for Detecting High-Risk Memecoin Launches on Solana
Abstract: Launchpads have become the dominant mechanism for issuing memecoins on blockchains due to their fully automated, no-code creation process. This new issuance paradigm has led to a surge in high-risk token launches, causing substantial financial losses for unsuspecting buyers. In this paper, we introduce MemeTrans, the first dataset for studying and detecting high-risk memecoin launches on Solana. MemeTrans covers over 40k memecoin launches that successfully migrated to the public Decentralized Exchange (DEX), with over 30 million transactions during the initial sale on launchpad and 180 million transactions after migration. To precisely capture launch patterns, we design 122 features spanning dimensions such as context, trading activity, holding concentration, and time-series dynamics, supplemented with bundle-level data that reveals multiple accounts controlled by the same entity. Finally, we introduce an annotation approach to label the risk level of memecoin launches, which combines statistical indicators with a manipulation-pattern detector. Experiments on the introduced high-risk launch detection task suggest that designed features are informative for capturing high-risk patterns and ML models trained on MemeTrans can effectively reduce financial loss by 56.1%. Our dataset, experimental code, and pipeline are publicly available at: https://github.com/git-disl/MemeTrans.
链接:https://arxiv.org/pdf/2602.13480
Subscribe to arXiv's Daily Preprint Notifications
