 夜雨聆风
夜雨聆风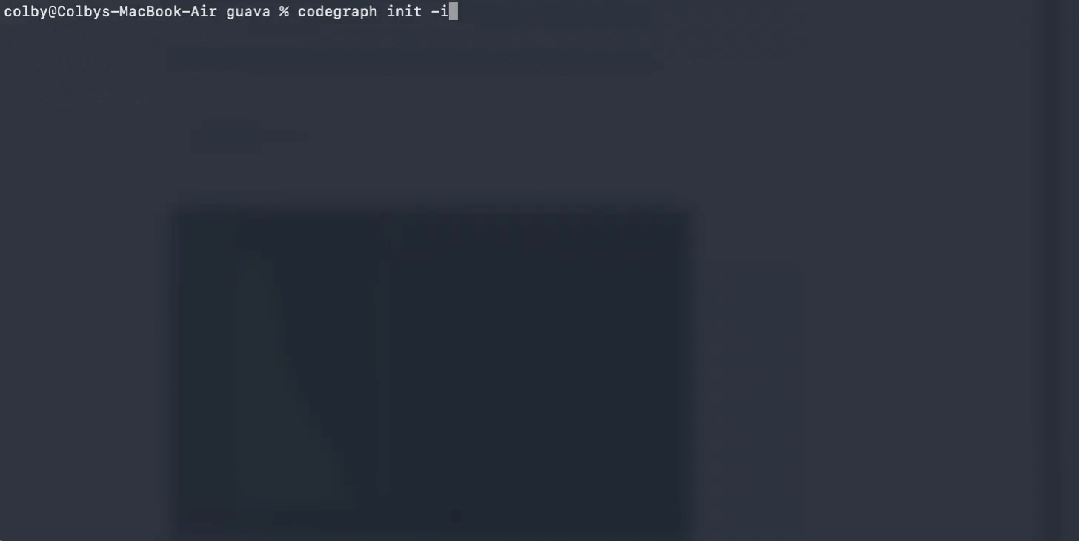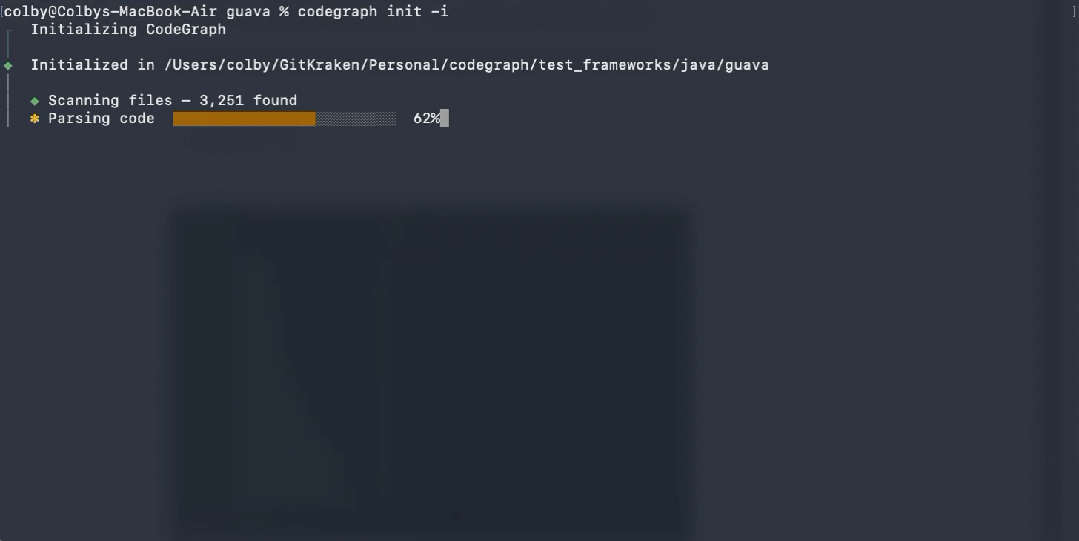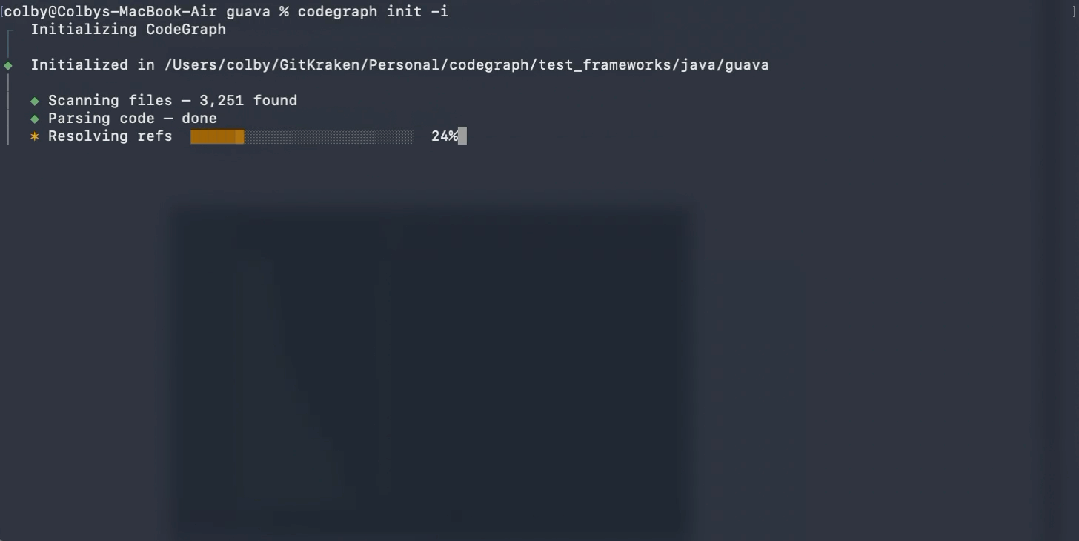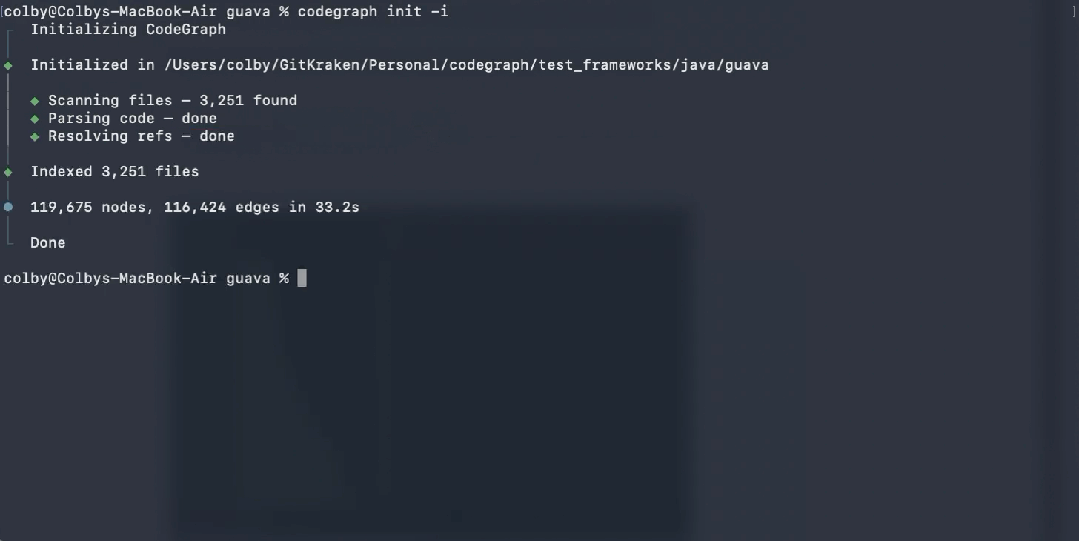
一个本地优先的代码情报工具,把任意代码库变成可查询的“知识图谱”,专门喂给 AI 编程智能体。一行命令上手,数据全程不出本机。
一、AI IDE的共同痛点:慢、贵、还经常“找不准”
用过 Claude Code、Cursor、Codex 这类 AI 编程助手的同学,大概率有过同样的感受:在大代码库里问问题,总是又慢又烧钱。
问题其实不在“思考”阶段,而在“找东西”阶段。 当一个 AI 智能体第一次探索一个陌生代码库时,它要先不断用 grep、glob、Read 这类工具,一个文件一个文件地翻,才能拼出“这段逻辑到底是怎么串起来的”。 仓库越大,这个“摸黑找路”的过程就越费 token、越拖慢响应。
CodeGraph 的思路非常直接:把“找东西”这一步提前做完。
它会预先解析整个代码库,把每一个符号(函数、类、方法……)、每一条关系(调用、引用、继承……)都建好索引,存进一个本地数据库。 之后,AI 智能体不再满仓库乱翻文件,而是像查字典一样直接查索引,几次调用就能拿到答案。
一句话概括:CodeGraph 就是给 AI 智能体准备的、预先构建好的代码搜索索引。
二、接上 CodeGraph,能省多少成本?
项目作者在 7 个真实的开源代码库上做了测试(每组取 4 次运行的中位数),接入 CodeGraph 后平均表现是这样的:
成本:便宜 35% Token 消耗:减少 57% 速度:提升 46% 工具调用次数:减少 71%
更重要的是:代码库越大,收益越明显。 在一些大型仓库上,智能体甚至可以做到几乎零文件读取——结构性问题全部直接从索引中回答。
(以上数据来自官方自测,仅供参考,实际效果以你的项目和使用习惯为准。)
三、CodeGraph 怎么工作?四步把代码变成“知识图谱”
从工程视角看,CodeGraph 的工作流可以拆成四个阶段:
提取(Extraction) 存储(Storage) 解析(Resolution) 自动同步(Auto-sync)
1. 提取:基于 AST 的确定性解析
CodeGraph 使用 tree-sitter 把源代码解析成抽象语法树(AST),再针对不同语言运行专门的查询,从中提取出:节点(函数、类、方法、类型……)以及边(调用、导入、继承、实现……)。
这一步有一个关键设计:全程不依赖大模型总结,只基于 AST 做确定性分析。 好处是结果稳定、可复现,不会因为“模型状态”不同而出现理解偏差。
2. 存储:一个本地 SQLite 数据库搞定
所有解析好的数据最终会落到一个本地 SQLite 数据库里:.codegraph/codegraph.db。 它启用了 FTS5 全文检索,既可以按结构查,也可以按文本查。 性能优先使用原生 better-sqlite3,在不支持的环境中会自动回退到 WASM 后端,你可以通过 codegraph status 查看当前后端。
3. 解析:把各种引用“接通”
提取完只是“拆零件”,解析阶段要做的,是把各种引用和调用真正“接通”:
函数调用映射到对应定义 导入映射到源文件 类继承关系梳理清楚 针对一些框架内的特殊模式做补充识别
对于静态分析难以追踪的动态分发场景(回调、观察者模式、React 重渲染、JSX 子组件等),CodeGraph 会利用合成器(synthesizer)来“搭桥”,尽可能把调用链填完整。
4. 自动同步:写代码的同时图谱自动更新
在本地跑 MCP 服务时,CodeGraph 会利用系统原生的文件事件(macOS 的 FSEvents、Linux 的 inotify、Windows 的 ReadDirectoryChangesW)监听项目目录。 文件一旦发生变动,变更会被去抖动处理,只对源代码部分做增量更新,图谱几乎实时保持最新。
你只管写代码,CodeGraph 在后台默默帮你维护最新的“代码知识图谱”。
四、图谱里到底存了什么?
从概念上讲,CodeGraph 存了三类核心信息:
节点(Nodes):符号和文件 边(Edges):节点之间的关系 文件(Files)
每个节点和边都有一个精确的 kind 类型,来自一套固定的词汇表,这样跨语言查询时语义可以保持一致。
常见节点类型包括:file、module、class、struct、interface、function、method、property、variable、enum、namespace、route、component 等。 常见边类型包括:contains(包含)、calls(调用)、imports(导入)、extends(继承)、implements(实现)、references(引用)、returns(返回)、instantiates(实例化)、overrides(覆写)、decorates(装饰)等。
另外一个细节是来源标记(Provenance):大多数边都来自 AST 解析,极少数在动态分发边界被“合成”的边会标记为 provenance: 'heuristic',并附带对应的“接线点”。 在 trace、node、context 这类命令输出中,AI 智能体可以清楚看到每一条连接是怎么来的。
五、支持哪些语言?主流后端 + 前端框架基本都覆盖
语言识别是自动的,基于文件扩展名,不需要手动配置。 目前 CodeGraph 已经完整支持 20+ 种语言,包括:
TypeScript / JavaScript(含 .ts.tsx.js.jsx.mjs)Python、Go、Rust、Java、C#、PHP、Ruby C、C++、Swift、Kotlin、Scala、Dart Svelte、Vue(含 Svelte 5 runes、SvelteKit 路由、Nuxt 页面/API/中间件路由) Liquid、Pascal / Delphi、Lua、Luau(含 Roblox require)等。
值得一提的是,针对很多框架里的“非标准结构”,比如 Svelte / Vue / Nuxt 的路由、Delphi 的可视化表单,CodeGraph 也做了专门适配,这对前后端混合的大型仓库非常实用。
六、三步上手:从安装到查询
如果你想快速试用,可以按下面三步走:
第一步:安装 CodeGraph
可以按自己的环境选择方式。
方式一:无需 Node.js,一行命令自动获取适配版本(macOS / Linux / Windows,详见官方文档) 方式二:已有 Node 环境,直接用 npm: npx @colbymchenry/codegraph零安装直接跑或 npm i -g @colbymchenry/codegraph全局安装
CodeGraph 自带运行时,不需要编译、没有原生构建步骤,跨平台行为一致。 交互式安装器会顺带帮你配置常见 AI 助手(Claude Code、Cursor、Codex CLI、opencode、Hermes Agent)。
第二步:在项目中初始化并建图
进入你的项目目录后,执行一条命令即可完成初始化和索引构建:
codegraph init -i:在当前项目创建.codegraph/目录并立即建立索引。后续如需重建或增量更新: codegraph index:完整重建索引codegraph sync:仅增量更新变动文件
第三步:检查状态 + 开始查询
常用检查和查询命令可以这样用:
codegraph status:查看节点/边/文件数量、后端类型、journal 模式等健康信息codegraph query UserService:按名字查找符号codegraph callers handleRequest:谁调用了这个函数codegraph callees handleRequest:这个函数调用了谁codegraph impact AuthMiddleware:改动这个符号会影响什么codegraph context "fix the login flow":为某个任务构建聚焦上下文
当你的项目里存在 .codegraph/ 目录,且 AI 助手已经配置好之后,智能体就会自动使用 CodeGraph 的工具,不需要你再做额外操作。
七、MCP 服务:给智能体准备的 10 个“超能力”
CodeGraph 以 Model Context Protocol(MCP)服务的形式向 AI 暴露能力,你可以通过:codegraph serve --mcp 手动启动,也可以交给安装器自动管理。
目前对外暴露了 10 个工具,包括:
codegraph_search:在整个代码库按名字查符号codegraph_context:为某个任务构建相关上下文(一次调用组合搜索 + 节点 + 调用方 + 被调方)codegraph_trace:追踪两个符号之间的调用路径codegraph_callers/codegraph_callees:找调用方/被调方codegraph_impact:分析改动影响范围codegraph_node:查看某个符号详情codegraph_explore:一次返回多个相关符号的源码及关系图codegraph_files:获取已索引的文件结构codegraph_status:检查索引健康度和统计信息
官方的使用理念很明确:对于“X 是怎么工作的”“架构是什么样”“某某在哪”这类问题,智能体应该优先用几次 CodeGraph 调用解决,而不是到处 grep + Read 文件。
八、CLI 命令速查小抄(适合收藏)
除了前面提到的命令,CodeGraph 还有一批高频 CLI,可以当作“开发者小抄”使用:
安装与卸载: codegraph:运行交互式安装器codegraph install:显式运行安装器codegraph uninstall:从智能体中移除 CodeGraph项目级操作: codegraph init [path]:初始化项目(--index同时建索引)codegraph uninit [path]:从项目里移除 CodeGraph(--force跳过确认)codegraph index [path]:完整重建索引codegraph sync [path]:增量更新codegraph status [path]:显示统计信息高级查询与集成: codegraph query/callers/callees/impact:都支持--json输出,方便二次开发codegraph files:支持--format/--filter/--max-depth/--jsoncodegraph affected [files...]:找出受改动影响的测试文件,非常适合用在 CI 里只跑“受影响测试集”。
在持续集成场景下,合理利用 affected 可以显著缩短流水线时间,尤其适合大型单体仓库。
九、支持哪些 AI 助手?如何手动接入 Claude / Cursor
交互式安装器会自动检测并配置以下助手,帮你接好 MCP 服务、写好指令文件:
Claude Code Cursor Codex CLI opencode Hermes Agent
对于 Claude,你也可以手动配置,在全局安装 CodeGraph 后,在 ~/.claude.json 中加入类似配置,让 Claude 以 stdio 的方式调用 MCP 服务;可选地在 ~/.claude/settings.json 中放行只读工具,免去每次确认。
需要注意的是:Cursor 在启动 MCP 子进程时容易用错工作目录,官方安装器会自动注入 --path 参数帮你处理。如果你选择手动配置,记得显式传入项目路径即可。
十、隐私与安全:100% 本地,无外部依赖
对于很多团队来说,“代码不出本机”是硬性红线。CodeGraph 在这一点上非常“干净”:
不需要 API key,不依赖任何外部服务 所有数据都存在本地 .codegraph/目录下的一个 SQLite 数据库中提取过程完全基于 AST,不依赖大模型“总结”代码
这意味着,从隐私到稳定性,CodeGraph 都比较容易通过团队的合规审查。
十一、它适合谁?几个典型使用场景
CodeGraph 解决的是一个非常具体、又非常普遍的痛点:AI 编程助手在大代码库里“找路”太慢太贵。
如果你符合下面任意一条,它都值得你至少试一次:
日常重度使用 Claude Code / Cursor / Codex 等 AI 助手,且代码库不小 在意 AI 助手的 token 成本和响应速度 希望改动前快速搞清楚“影响范围”(谁调用了它、改了会炸哪) 希望在 CI 中只跑受影响的测试,缩短流水线时间 对代码隐私有硬性要求,不希望代码被传到外部服务
CodeGraph 免费、开源(MIT 许可证),一行命令上手,自带运行时,跨平台表现一致。 对许多团队来说,这基本是一个“装上就能回本”的工具。
项目链接
官网文档: https://colbymchenry.github.io/codegraph/ GitHub: https://github.com/colbymchenry/codegraph npm: https://www.npmjs.com/package/@colbymchenry/codegraph 许可证:MIT
本文基于 CodeGraph 官方文档整理,功能与数据可能会随项目演进发生变化,请以官方最新文档为准。
