 夜雨聆风
夜雨聆风随当下 AI 智能体(Agent)的火爆,能自主思考、调用工具、完成复杂任务的Agent,成了科技圈新风口。但很多人不知道,看似靠强大 GPU 运转的 AI 智能体,其实一直被CPU 性能卡了脖子。在今年的GTC大会上,英伟达正式推出全球首款专为 AI 智能体打造的 CPU——Vera,直接补齐短板,让智能体运行效率迎来质的飞跃。

▲Vera CPU
有朋友可能会疑惑:AI 不是靠显卡(GPU)就行么?为啥还要专门做一款 CPU?
其实 AI 智能体的工作流程远比大家想象的复杂。它除了要做模型推理,还要频繁运行沙盒、执行代码、调用各类工具、处理超长文本数据,再把结果回传给 GPU 循环运算。而这些环节大多依赖 CPU 完成。
以往我们使用的传统通用 CPU,对于需要快速、大量计算的Agent来说,它的单核运行速度慢、数据传输带宽不足、延迟偏高。哪怕 GPU 性能再强悍,也只能被迫空转等待,严重拉低整套设备的工作效率。而英伟达这次推出的 Vera,对这一痛点给出了针对性的解决方案。
01
专为 AI 智能体量身打造,硬核实力拉满
Vera 采用英伟达自研Olympus 架构,基于 Arm 设计,单片集成 88 核心、支持 176 线程,从根源减少数据传输延迟。
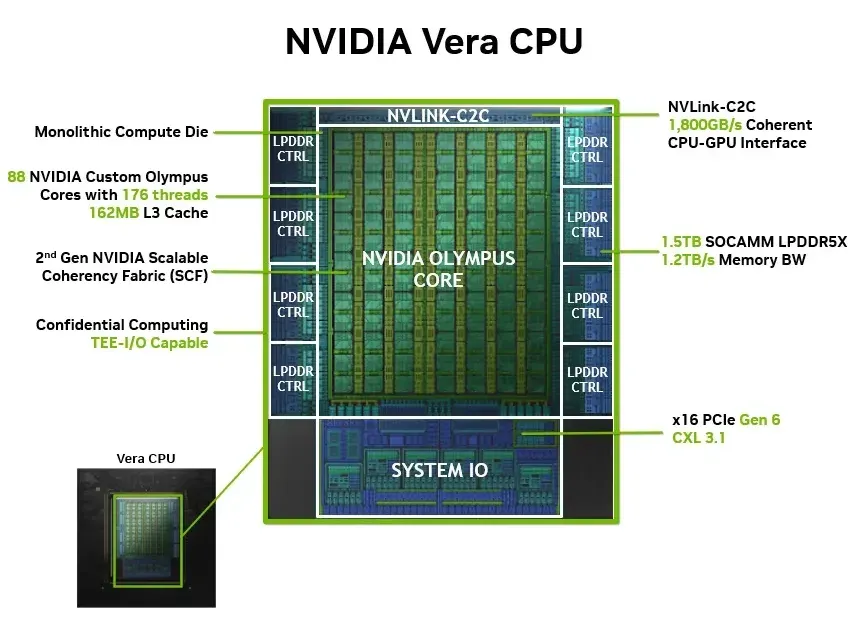
▲Vera CPU架构
同竞争平台相比,它的沙盒性能最高可提升 50%,对于依赖单线程运行的代码执行、工具调用、沙箱任务来说,速度提升感知十分明显。同时它搭配 LPDDR5X 内存,内存带宽达到 1.2TB/s,面对智能体海量数据读写、长上下文处理时,也不会出现卡顿。
在能耗方面,它的表现同样出色。NVIDIA Vera CPU 可提供高达 1.2 TB/s 的内存带宽——是传统 CPU 的两倍带宽和一半的功耗。在部署沙箱任务时,同等空间内的部署密度更是传统 CPU 的 4 倍,算力利用率大幅提升。
02
软硬协同,打造完整 AI 算力组合
Vera 并不是单独使用,英伟达搭配了 Rubin GPU,组成全新算力平台。二者通过 NVLink-C2C和NVIDIA NVlink纵向扩展互联架构,互连带宽高达 1.8TB/s。

▲适用于现代 AI 工厂的 Vera 平台选项
当Vera与 NVIDIA Rubin GPU 配合时,形成统一内存系统,CPU 和 GPU 可以共享数据地址,实现数据零拷贝,彻底打通算力壁垒,让 CPU、GPU 高效协同工作。根据官方实测,搭载这套组合后,AI 智能体整套训练、运行循环,整体速度大幅提升。
03
头部企业抢先落地,规模化时代来临
目前 Vera 芯片已经正式开始批量交付,第一批客户都是全球顶尖的 AI 企业与云厂商,包括 OpenAI、Anthropic、SpaceX AI 等海外巨头,国内阿里、字节跳动也已开启相关合作。
按照规划,今年下半年,戴尔、联想、HPE 等主流硬件厂商,也会陆续推出搭载 Vera 的服务器产品,面向全行业开放。
04
行业迎来新变革,AI 智能体加速普及
在此之前,AI 算力领域基本是 GPU 一枝独秀。而 Vera 的问世,标志着 AI 基础设施正式迈入专用 CPU + 专业 GPU协同发展的新阶段。
长期以来制约 AI 智能体规模化落地的延迟、功耗、运行效率三大瓶颈被逐一打破。未来不管是企业搭建智能体服务,还是各类 AI 机器人、自动化办公工具的研发,成本都会进一步下降,运行体验也会更流畅。
从通用算力到场景化专用算力,AI 硬件的细分赛道正在越来越清晰。这款专为智能体而生的 Vera CPU,也将成为推动下一代 AI 应用走进大众生活的重要基石。
