 夜雨聆风
夜雨聆风
摘要:本文系统介绍了基于Python Flask框架与openpyxl库构建企业级Excel数据管理平台的方法。首先阐述了Excel数据管理平台的核心功能,随后构建了包含智能校验、异步处理、操作审计及水印安全的完整系统。通过Flask实现后端逻辑与前端交互,实现了从脚本工具到中台系统的升级。该项目结构清晰、功能强大,具备良好的扩展性,适用于企业级数据治理场景的开发与实践。详细内容请参考下文。
一、系统功能介绍
本系统是一款基于Flask框架深度定制的企业级Excel数据处理平台。针对企业海量数据流转中的痛点,我们创新性地融合了智能校验、异步处理、操作审计与水印安全四大核心引擎,旨在打造一个高安全、高性能且全链路可追溯的数据处理中枢:
l前置化智能校验:将传统的事后纠错转变为事前预防,通过多维度的规则引擎实时拦截异常数据,显著降低返工率,极致提升用户交互体验;
l高性能异步处理:突破大文件处理的性能瓶颈,采用非阻塞异步架构,确保在海量数据并发场景下系统依然保持毫秒级响应与稳定吞吐;
l全维度操作审计:建立细粒度的行为追踪机制,完整记录数据从导入到导出的每一次变更,为企业内控合规与责任界定提供不可篡改的数字凭证;
l防御型水印安全:构建数据防泄露的最后一道防线,通过动态隐形/显性水印技术,实现敏感数据的溯源确权,有效遏制违规外发风险。
二、Python数据处理库-Openpyxl
Openpyxl 是一个专为 Python 环境设计的开源第三方库,旨在实现对 Excel 2010 及以上版本文件(如 .xlsx、.xlsm 等格式)的底层读写与精细化操作。该库完全脱离了对 Microsoft Excel 应用程序及 Windows 系统的依赖,具备出色的跨平台特性。通过提供符合 Python 编程惯例的对象化接口,开发者能够以代码驱动的方式高效执行各类电子表格任务,包括但不限于新建工作簿、动态修改现有文档结构与数据、以及批量提取和清洗结构化信息。在企业级应用与自动化办公场景中,Openpyxl不但可以实现复杂数据处理任务的自动化流转,还可以对海量 Excel 文档进行批量的内容更新与格式化定制,非常便利实用。
1.Openpyxl的核心功能
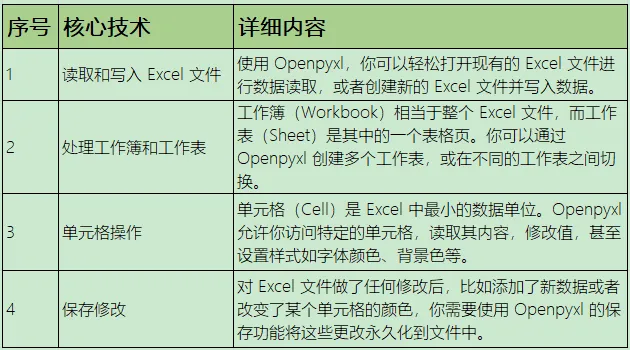
2.Openpyxl的工作流程
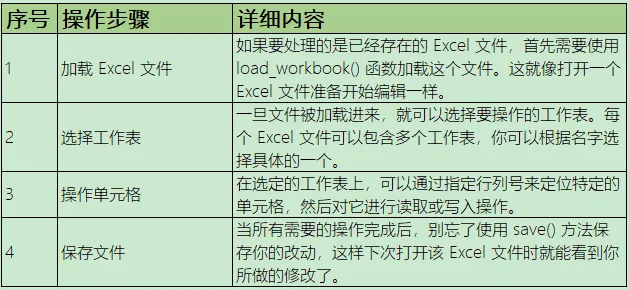
3.举例说明Openpyxl的用法
读取Excel数据
示例:3行代码读取集团人事信息表
from openpyxl import load_workbook
wb = load_workbook('集团人事档案.xlsx')
name = wb['Sheet1']['A2'].value
写入和修改Excel
示例:批量修改工资单
ws['C2'] = 10000
ws['D2'] = '=C2*1.1'
wb.save('员工档案_已更新.xlsx')
创建全新Excel文件
示例:自动生成月度报表
from openpyxl import Workbook
wb = Workbook()
ws = wb.active
ws['A1'] = '销售额'
ws['B1'] = '=SUM(A2:A100)'
wb.save('月度报表.xlsx')
三、企业级 Excel 数据管理平台的开发实战
1. 需求分析与架构定位
针对企业在海量电子表格流转中面临的效率与安全痛点,本文基于 Flask 框架从零构建一个高可用、高安全的“企业级Excel数据管理平台”。该平台不仅致力于解决传统办公场景下的数据处理瓶颈,更深度整合了四大核心业务能力:通过规则引擎实现智能校验以拦截脏数据;依托异步架构突破大文件处理的性能极限;建立全链路操作审计以满足内控合规要求;并引入动态水印安全机制构筑防泄露防线。在此基础上,系统进一步集成Celery+Redis分布式任务队列处理大文件的异步导入与导出,同时接入Ollama部署千问大模型,为用户提供智能化的数据清洗建议与业务洞察。
2. 后端架构设计与组件协同
在后端工程实践中,本系统严格遵循“最小依赖”与“最佳实践”的设计原则,采用微服务化的思想进行模块化拆分。各核心组件分工明确且高效协同:
Web 路由层:选用轻量级的 Python Flask 框架,提供敏捷的 Web API 接口与页面渲染能力;
异步计算层:引入 Celery 配合 Redis 消息代理,将耗时的报表解析与生成任务从主线程剥离,彻底消除性能阻塞;
持久化层:采用 SQLAlchemy ORM 框架,保障复杂业务场景下数据的强一致性与可维护性;
文件处理层:深度应用 Openpyxl 库,实现对Excel文档的细粒度读写、样式定制及公式运算等底层操作;
AI 赋能层:通过 Ollama 本地化调用千问大模型,赋予系统自然语言理解与数据分析能力,实现从“自动化”向“智能化”的跨越。
各组件之间通过清晰的接口边界进行解耦通信,既保障了平台在当前复杂业务下的高并发稳定性,也为未来接入更多第三方工具或扩展新功能预留了充足的架构空间。
3.数据库初始化与系统运行
(1)数据库初始化与表结构构建
为确保系统运行环境的完整性,需执行专用的数据库初始化脚本以完成本地 MySQL 数据库的配置。该脚本将自动创建核心业务库 excel_manager_db,并同步实例化系统运行所依赖的全部基础数据表。主要包括:用于用户权限管理的users表、文件元数据存储的upload_files表、字段映射配置的column_definitions表、核心业务数据的data_records表,以及支撑平台四大核心能力的审计日志表(audit_logs)、异步任务调度表(async_tasks)、水印记录表(watermark_records)和全局配置表(system_settings)。
执行数据库初始化脚本 mysql> source /usr/local/program/excel_system_app_perfect/data/init_db.sql
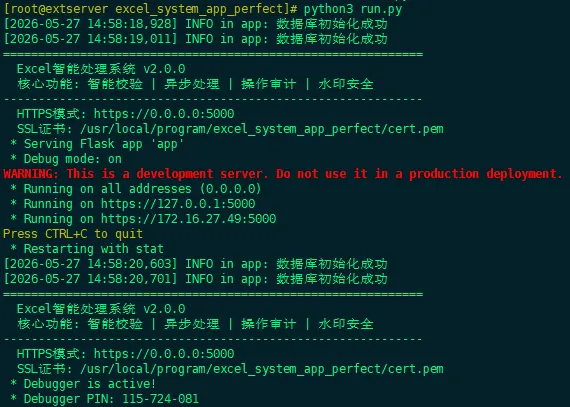
(2) 运行系统
执行python3 run.py标志着系统从代码态进入运行态。作为整个Python Flask 应用的启动入口(Application Entry Point),该脚本不仅是触发 Web 服务的开关,更是串联各核心组件、激活企业级处理能力的“总控枢纽”。程序run.py自动调用底层的 WSGI HTTP 服务器(如 Gunicorn 或 uWSGI),将 Flask 应用绑定至指定的 IP 地址与端口。至此,一个集成了智能校验、异步处理、操作审计与水印安全的企业级现代化数据处理平台正式上线,等待用户的访问与调度。
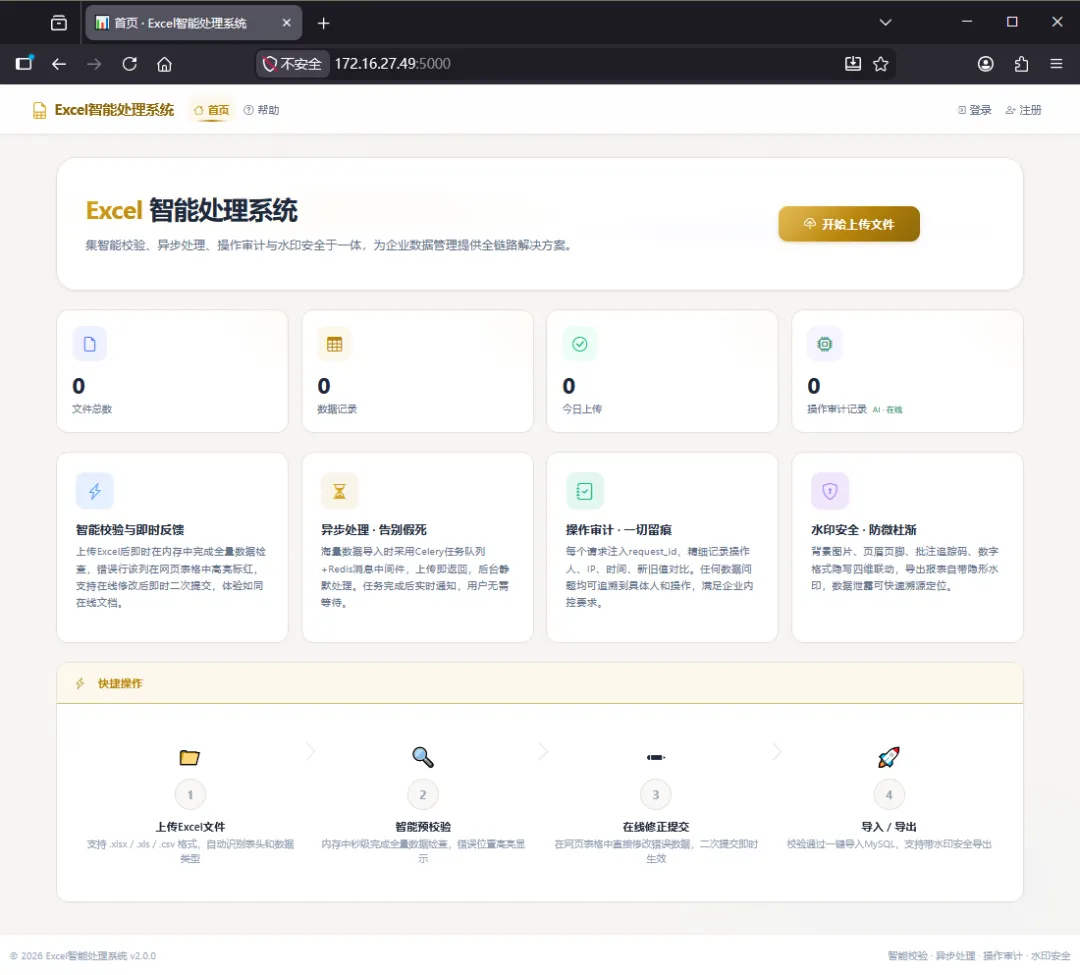
4.系统使用指引
第一步:访问系统
第二步:注册账户
输入账户信息,开始注册。如下图
提示用户注册成功。如下图
第三步:账户登录
使用已经注册成功的用户登录系统。如下图
成功登录系统。如下图
第四步:点击【上传校验】菜单上传文件
为保障海量数据入库的准确性与系统的智能校验效率,本系统实行“模板驱动”的数据接入机制。用户在执行文件上传前,需先获取平台提供的标准化导入模板,严格按照模板定义的字段规范与格式要求完善业务数据,随后再将文件提交至系统进行自动化处理。具体操作步骤如下:
下载标准模板:在数据导入页面点击“下载模板”按钮,获取当前业务对应的最新 Excel 模板文件;
规范填写数据:打开下载的模板,参照表头说明与示例数据,将待导入的业务信息准确填入对应列中(注意保持单元格格式为文本或数字,避免使用公式);
上传并触发处理:确认数据无误后,返回系统页面将填好的 Excel 文件拖拽或选择上传,系统自动接管并启动后续的异步解析与校验流程。
首先是下载“员工表”模板。如下图
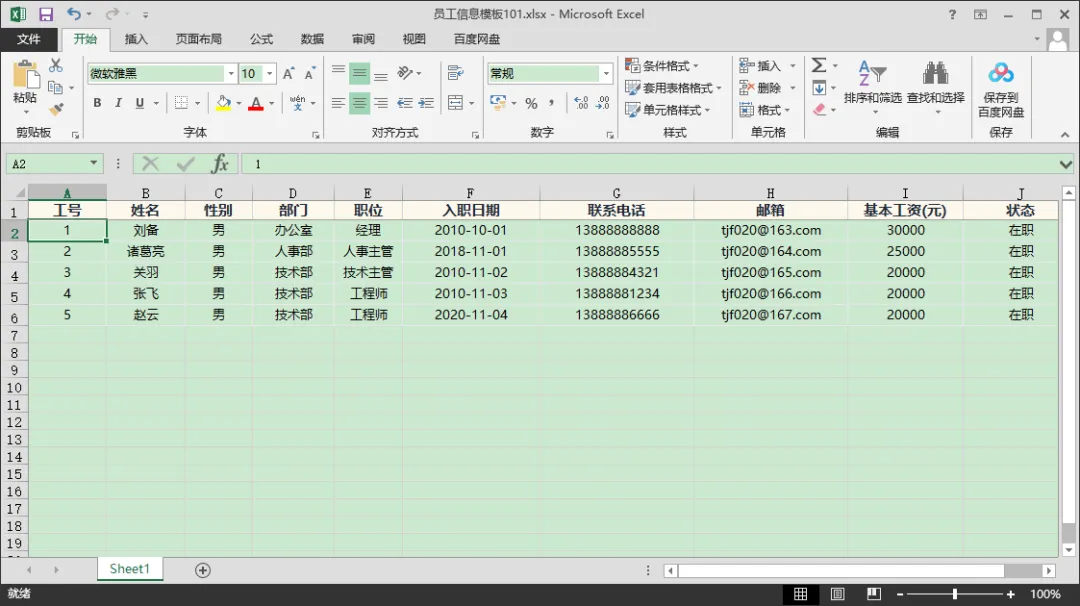
下载到本地磁盘,打开模板进行编辑。其内容如下:
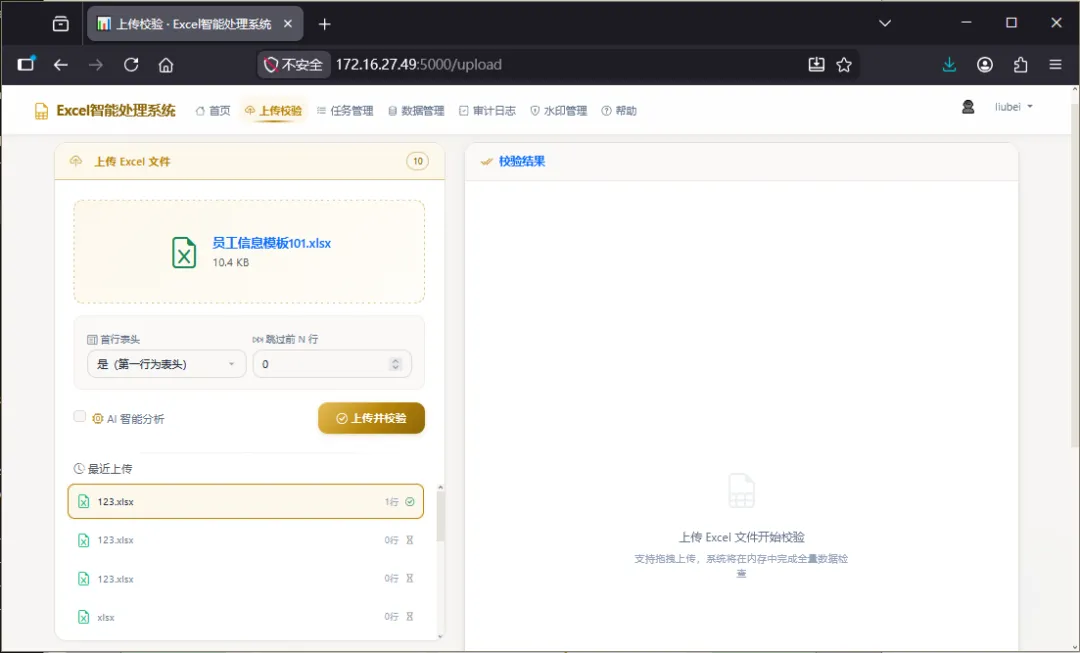
然后是编辑并将文件上传到系统。如下图
开始进行数据校验(校验成功会在页面显示表单内容)。如下图
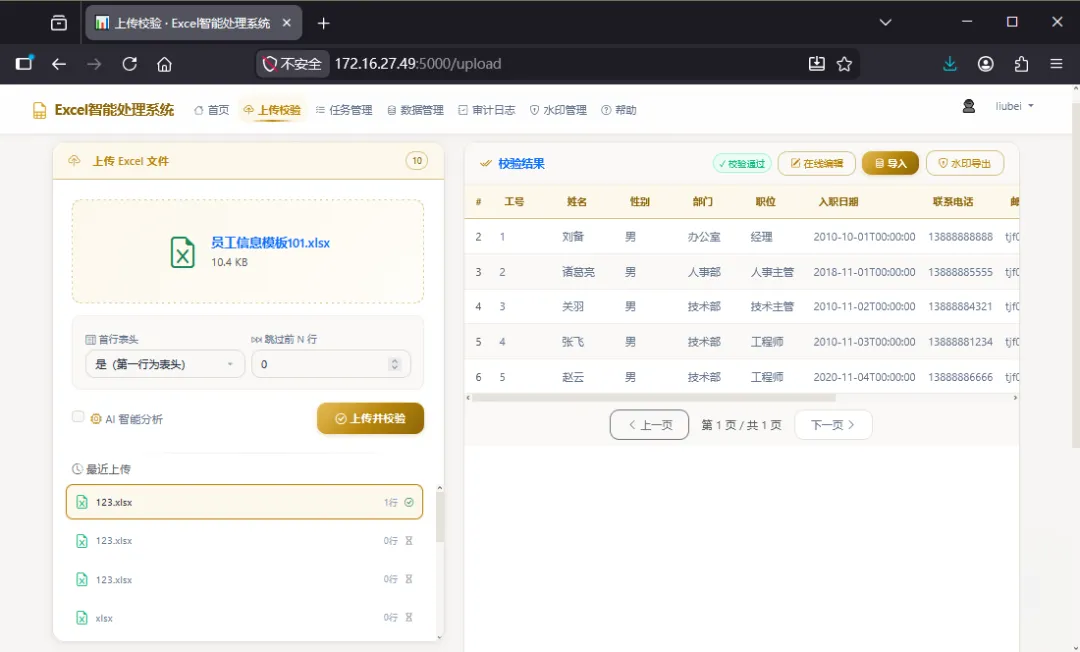
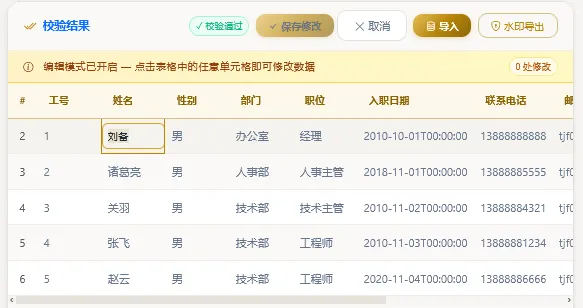
点击【在线编辑】可以对表单内容进行修改、导入、水印导出等操作。如下图
备注:系统的“任务管理”、“审计日志”以及“水印管理”的功能类似,由于篇幅所限,这里不再赘述。
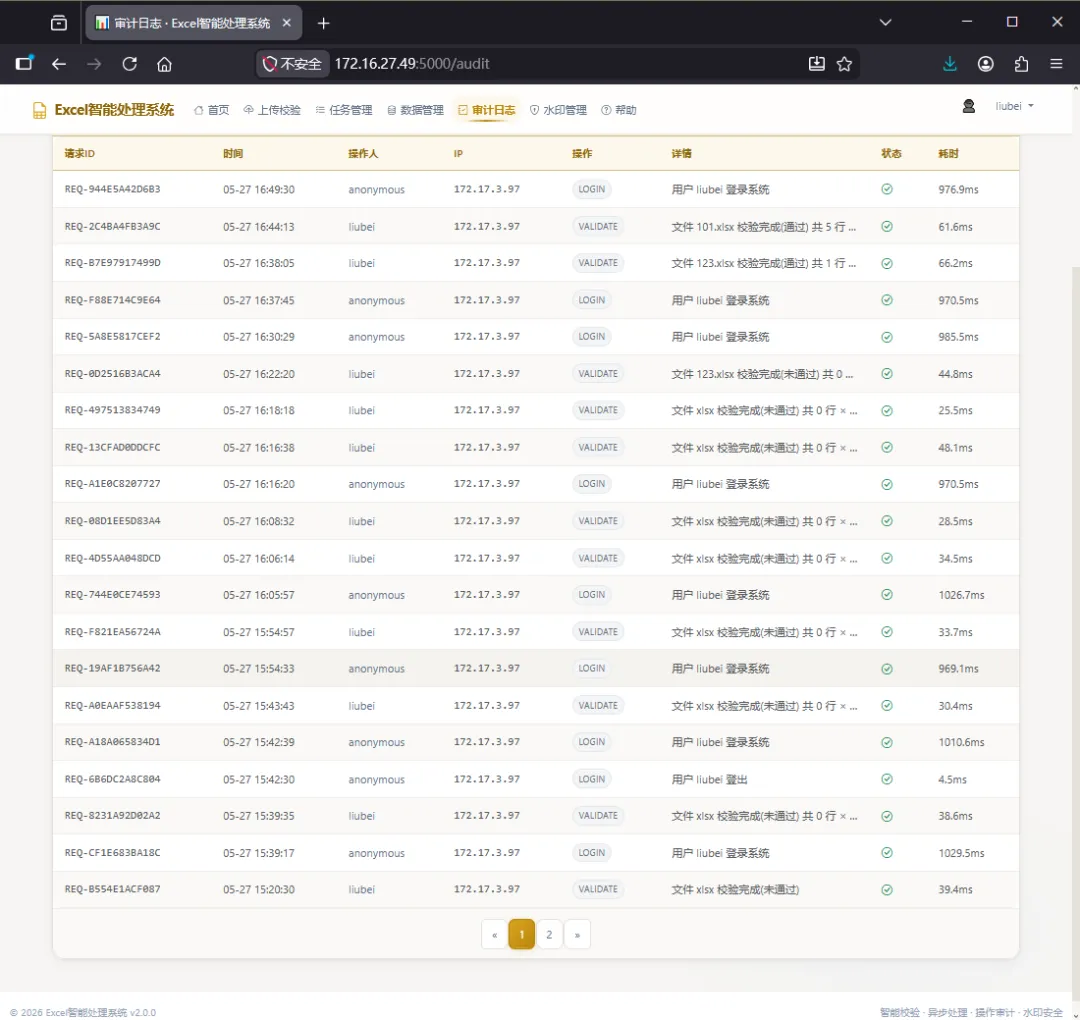
第五步:查看审计日志信息
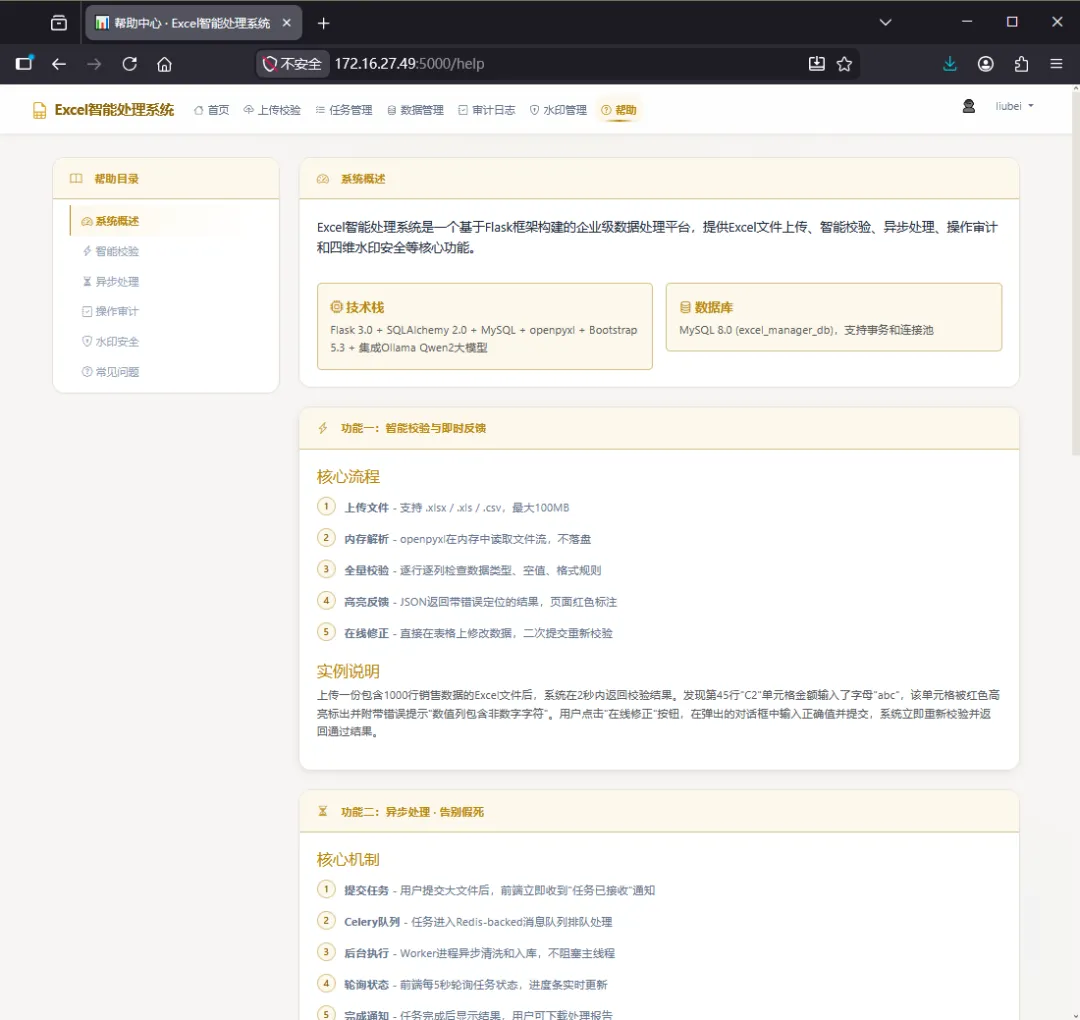
第六步:查看系统的帮助信息
📢互动与分享
如果本文对您有帮助,欢迎:
👍 点赞,让我知道您的认可。 💬 留言,说说您最感兴趣的模块或任何建议。 🔄 转发分享给您的技术团队或社区朋友,共同提升运维效率。 👉 关注我,即可查看并下载完整项目代码,亲手打造属于您的自己的Excel智能数据管理平台。
