 夜雨聆风
夜雨聆风一个 skill 就像一段软件代码,也要迭代。问题是,谁来当那个产品经理?当 Agent 学会自己写工具、测试、修复、进化,开发者开始从「造工具的人」变成「管生态的人」。

01. 刷到一篇论文,然后就失眠了
故事是这样的。
前几天我在用一个叫 MiroFish 的开源项目做实验,让一群 AI 模拟个体在沙盒里各自演化,看能不能自然冒出点「群体智慧」之类的东西。做着做着我发现问题了:每个人物的技能是静态的。
你写在代码里的工具函数,它用一万遍还是那个样子。不会变好,不会因为场景变化自我调整,更不会从失败里学东西。

前天凌晨刷 arXiv,刷到一篇刚出炉的论文,《MUSE-Autoskill: Self-Evolving Agents via Skill Creation, Memory, Management, and Evaluation》。字节跳动和罗切斯特理工学院发的,5月26号上线。一口气读完,读到后面的实验数据直接从椅子上坐起来了。
说白了,这篇论文在回答一个特别朴素的问题:能不能让 AI 在干活的时候,自己发现自己缺啥工具,然后自己写一个,自己测试,自己上线,下次还自己改进?
答案是能。效果有点离谱。
02. Skill 正在变成一种「活的东西」
静态 skill 玩不转了。这是我用 MiroFish 做完实验之后最强烈的感受。
你想想,一个 skill,说白了就是一段让 AI 能调用的工具代码,它跟软件工程里的模块有啥本质区别?没区别。它也要跟着需求迭代,也要修 bug,也要做版本管理。
MUSE-Autoskill 的核心洞察我琢磨了好几遍。最值钱的是这个:把 skill 当成一个有生命周期的资产,而不是一次性生成的废纸。
他们构建了一个五阶段生命周期。我直接翻译成人话:
• 创建:AI 在干活时发现现有工具搞不定当前任务→调用内置的 skill_create工具自己写• 评估:写完了不是直接上线,先跑单元测试,全部通过才能注册入库 • 记忆:每个 skill 绑一个 .memory.md文件,记录这货曾经踩过什么坑、哪个输入格式容易挂• 管理:定期做 Refinement(修订)、Merging(合并功能重叠的技能)、Pruning(剪掉长期废掉的技能) • 自愈:运行时崩了?自动读日志、定位根因、修代码、再测试、再上线
看到这个结构我第一反应:这不就是微服务治理那一套吗。被治理的对象从 Java 服务换成了 LLM 随手生成的一段 Markdown、Python(也许还会是其他语言,如shell、NodeJS等)。
再往深了挖一层。那个 .memory.md 设计其实挺绝的,传统 RAG 只检索代码本身,检索不到这段代码在实际运行中跌过多少跟头。MUSE 给每个 skill 绑了一份「成长履历」,下次谁调用这个 skill,看到的不仅是代码,还有这货在历史上处理边缘 case 时的微调经验。论文管这个叫 技能级记忆(Skill-level Memory),我觉得翻译成「踩坑日记」更贴切。
还有一个设计细节值得说:他们的上下文管理器。长任务跑得越久,上下文越臃肿,LLM 注意力越容易跑偏。MUSE 搞了一套 DAG 对话节点 + 两级压缩。第一级只压缩超大节点的内容,保留轮次结构;第二级在预算吃紧时把连续中间节点合并成一条总结。原始节点信息不丢,随时可以回溯。这个思路跟 MemGPT 异曲同工,工程实现更干净。

论文读深入了之后,我发现它并不是一个人在战斗。两条学术路线跟它相互补充,值得单独拿出来说。
一条是 CoEvoSkills(2026年4月)。核心思路是:把生成器和验证器拆成两个独立模块,让它们互相较劲、共同进化。 生成器不断产出代码,验证器专门挑毛病,一个攻一个守。这种对抗机制在 SkillsBench 上刷出了目前学术方案中的最高分。更重要的是,它的「分离架构」思路直接启发了后续工程落地时的一个关键选择:代码写好 ≠ 代码好用,功能验证和安全审计必须分开。
另一条是 Memento-Skills(2025年12月)。它走的是强化学习路线,不给 skill 写死调用逻辑,而是让 RL 自己学会「什么场景该用这个函数、参数怎么给、出错怎么兜底」。相当于每个 skill 都在运行时挨个试错,从奖励信号里悟出一套最优调用策略。跟 MUSE 的技能级记忆相比,一个靠「记笔记」积累经验,一个靠「摔跤」学会走路,技术路线不同,目标一致。
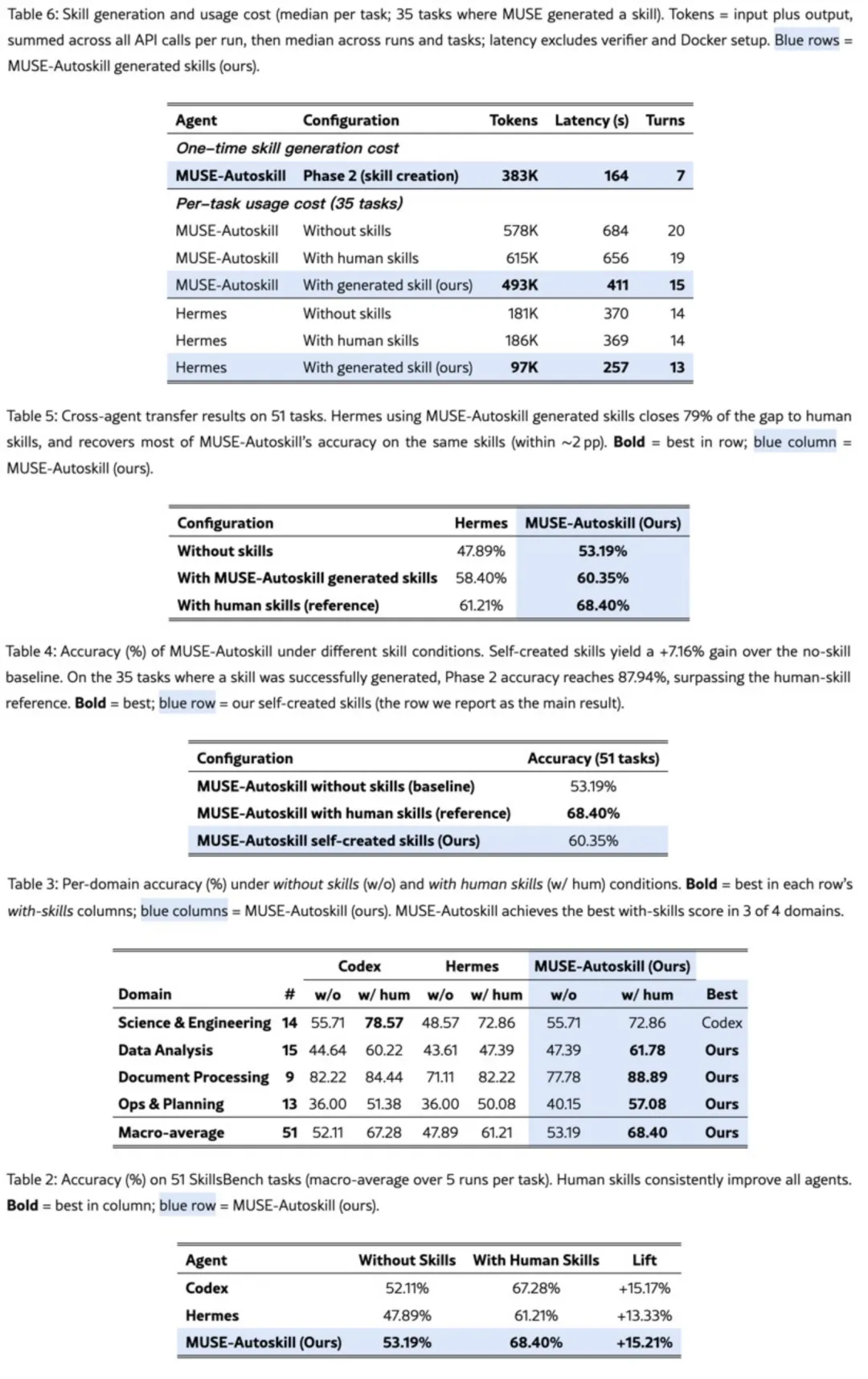
实验数据撑得住这些设计。在 SkillsBench 成功生成技能的 35 个任务上,MUSE 自生成技能达到了 87.94% 的准确率。什么概念?比人类专家手写的 skill 还高。说实话,这些技能不是只能自己用。跨 Agent 迁移测试中,一个 MUSE 系统里长出来的技能注入到另一个 Agent 后,填上了 79% 的性能差距。
你细品 79% 这个数字。Agent A 生成的 skill,Agent B 拿来就用,效果能达到量身定制水平的近八成。Skill 不再是某个 Agent 的私房菜,而是可移植的知识资产。
03. 翻了一圈行业全景,发现都差口气
读论文的兴奋劲过了之后,我打开浏览器把开源的和商业的方案撸了一遍。
一圈看下来,好多项目都在往这个方向拱。各有各的死穴:
• Voyager(NVIDIA, 2023):最早搞技能库的开山之作,在 Minecraft 里让 Agent 探索→写代码→存库→复用。检索只靠向量相似度,没有执行质量评估,错了我也不会修→只会「报错就重试」 • AutoSkill(华东师大, 2026.03):从对话里抽 skill,做成模型无关的插件层。思路不错但偏重个性化风格,不是通用工具生成 • CoEvoSkills(2026.04):上面说过的生成器-验证器对抗进化,SkillsBench 最高分,文档和社区还不够成熟 • EvoSkill(2026.03):通过失败模式分析和帕累托前沿选择来做零样本迁移验证,跟 MUSE 互补,一个重「进化」,一个重「迁移」 • Memento-Skills(2025.12):RL 学状态化提示的路线,另辟蹊径 • SkillForge(云运维场景):这个真值得展开。它用 1883 张真实工单和 3737 个任务做训练,走的是「历史工单→失败分析→诊断→自动改写」的三阶段管线。结果呢,多轮自动演化后的技能,** 超过了专家手工维护的知识 **。这大概是目前离工业落地最近的实战证据。 • ALITA-G(2026.01):把用户操作轨迹直接合成 MCP 兼容的工具,配合 RAG 做自动领域特化。跟 MUSE 比,它更偏「从操作中学」,MUSE 更偏「从任务中学」。 • CrewAI(工程派):讲究类型安全,用 Pydantic 严格校验输入输出,安全隔离做得不错。不过「校验再严代码也不会自己修」
商业层面,由 Anthropic 牵头的 MCP(Model Context Protocol) 已经是事实标准,定义了 AI 工具发现、协商、调用的统一协议。值得关注的是正在推进的 SEP-2640(Skills over MCP),要把 skill 包的路由发现标准化。有了这个,MUSE 生成的 skill 可以直接注册成 MCP 资源,任何一个兼容客户端都能调用。
我做了张对比表帮你快速看清格局:
| MUSE-Autoskill | ||||
| Voyager | ||||
| CrewAI | ||||
| AutoGPT | ||||
| CoEvoSkills | ||||
| EvoSkill | ||||
| SkillForge | ||||
| MCP生态 |
看到没?MUSE 是覆盖生命周期最完整的方案,从需求发现到代码生成到测试上线到运行监控到自愈迭代。不过它的沙箱太弱了,Docker 容器而已,没有恶意代码检测,没有权限审计。
04. 三个绕不过去的硬骨头
聊到这儿我得把一些坑摆出来。不是泼冷水。这些坑我自己踩过。
第一个:安全。RCE 级别的。
让 LLM 在运行时直接写 Python 然后执行。你品品这个画面。
我没必要是安全专家也知道这意味着什么。如果 Agent 在处理一个恶意 PDF,攻击者在里面嵌了提示词注入,诱导 skill_create 生成一段 os.system('rm -rf /') 呢?或者更隐蔽的——偷偷把数据库里的表结构打包外发出去?想到这儿,后背有点发凉。
说实话 单元测试拦不住恶意。你需要在沙箱之外再加一套安全审计:静态代码扫描扫出高危 API 调用,动态运行监控检测异常系统调用,网络出方向严格控制。MUSE 论文自己也承认,目前的 Docker 沙箱缺乏恶意代码检测和权限审计,安全边界还很薄弱。
还有个思路,CEDAR 框架走了另一个极端:放弃通用编程语言,把所有 skill 约束在确定性有限自动机(DFA)里,从数学上保证可验证。代价是表达能力大打折扣,你写不了复杂循环和通用算法。安全性和灵活性之间的取舍,目前没有好答案。
第二个:可观测性困难。
技能在运行时动态突变。这句话翻译成人话就是:你没法用传统 APM 工具追踪问题了。
想象一下:一个工作流跑到第 150 步突然炸了,根因是第 12 步自动进化的一个子函数在某个边界条件下返回了脏数据。那段代码现在已经被自愈循环改了三次。你回头看的时候,已经是另一个版本了。我盯着这个场景琢磨了很久,说实话没有特别漂亮的解法。
代码在变形,日志不会变。这种「会变形的代码」让传统链路追踪完全失效。你得记录每次代码演进前后的完整 Git diff、环境变量快照、调用上下文,等于给每个 skill 建一个审计档案。
第三个:Token 黑洞,账单刺客。
MUSE 论文自己报的数据:生成一个 skill 平均耗 383K tokens,约 164 秒。这是一次性生成的成本。如果经历「生成→测试失败→反思→重写→再测试」的循环,按经验估算,这个数字可能翻倍甚至翻三倍。
不过换个角度算一笔账:生成成本大概摊到 3 次复用就能回本。因为 skill 跑起来之后省掉的是每次任务中重复推理那部分 token。你写死一个工具调 100 次,它就赚了 97 次的推理成本。问题是,在回本之前,财务部门先不干了。
05. 所以我说:应该长这样
症结找到了。学术方案底子好但安全弱、协作乱、可观测黑洞。那解法是什么?
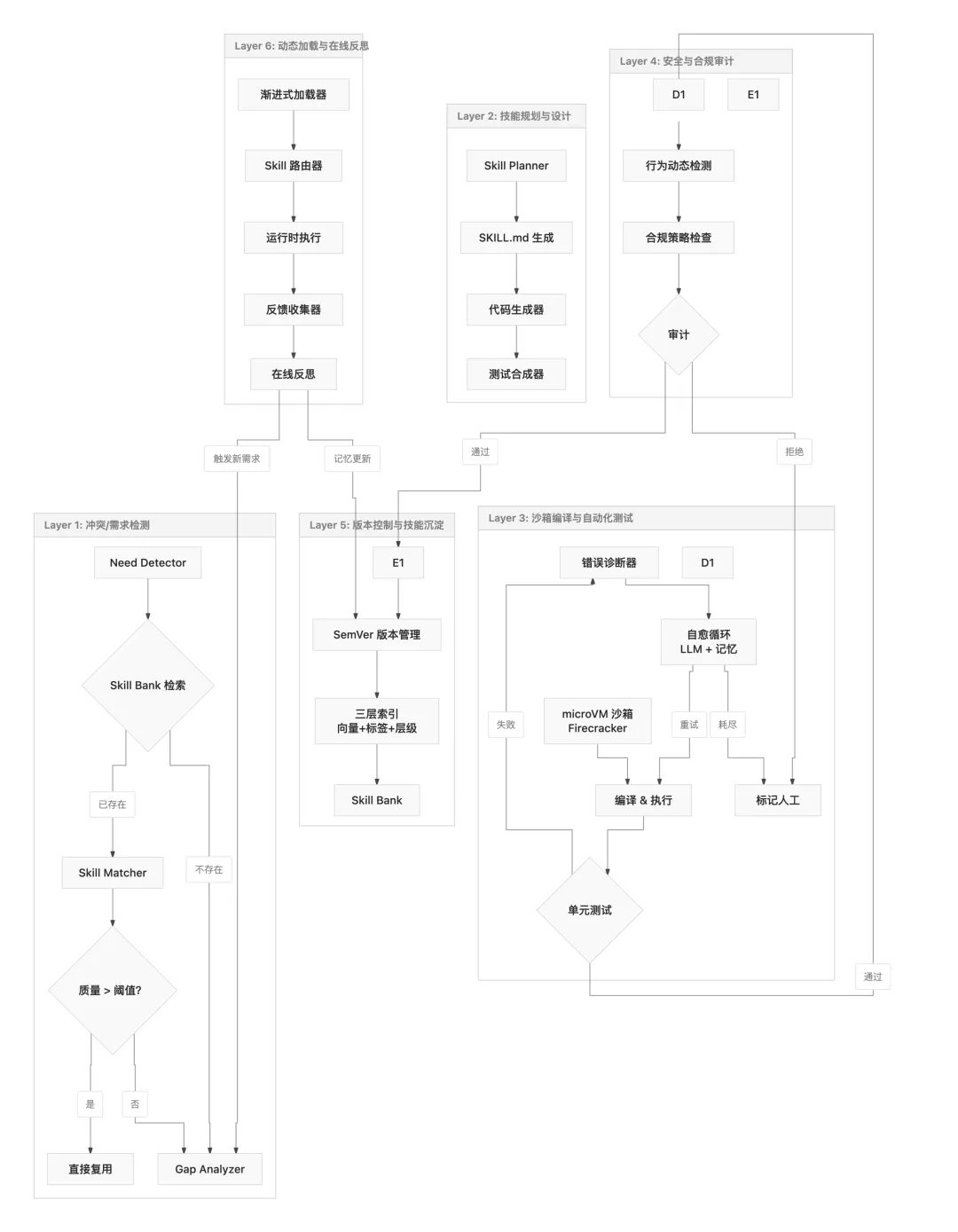
我结合 MUSE 的学术创新 + CoEvoSkills 的生成器-验证器分离 + MCP 的协议标准化 + E2B 的微VM沙箱,画了一个六层架构。我叫它 Evolving Skill Engine(ESE),核心思路就一个字:拆。
检测层和设计层拆开,发现缺工具不急着写代码,先看看能不能复用。沙箱和安全审计拆开,功能正确不等于安全合规,测完了还得审。代码生成和版本控制拆开,每个 skill 都是 Git 仓库,每次进化都是一次 commit,版本可回滚可追溯。
SkillForge 在云运维里的实战验证给了我信心。1883 张工单跑下来的数据说明,只要反馈回路设计对了,自动演化的技能确实能超过专家。ESE 的反馈回路设计沿用了它的「失败分析→诊断→改写」三阶段思路,但加了一层安全审计网关。毕竟企业场景下,光「能用」不够,得「合规」。
下面贴三段我觉得最能体现设计思路的核心代码示例,都是完整的可运行骨架:
SkillGenerator:三阶段生成接口→代码→测试
class SkillGenerator: """将 SkillSpec 转换为符合 Agent Skills 约定的技能包""" def __init__(self, llm: LLMClient, skills_root: Path): self._llm = llm self._skills_root = skills_root async def generate_skill(self, spec: SkillSpec) -> SkillPackage: # 分配目录,防冲突 pkg_dir = self._allocate_package_dir(spec) pkg_dir.mkdir(parents=True, exist_ok=False) skill_pkg = SkillPackage( root_dir=pkg_dir, name=spec.name, version=spec.version_hint ) # 三阶段生成:接口描述 → 执行代码 → 测试用例 await self._generate_skill_md(spec, skill_pkg.skill_md) await self._generate_script(spec, skill_pkg.scripts_dir) await self._generate_tests(spec, skill_pkg.tests_dir) return skill_pkg async def _generate_script(self, spec: SkillSpec, scripts_dir: Path) -> None: scripts_dir.mkdir(parents=True, exist_ok=True) script_path = scripts_dir / "main.py" prompt = f"""Generate a Python 3.11 script implementing skill `{spec.name}`.- Provide a `run(inputs: dict) -> dict` entrypoint- Validate inputs against: {json.dumps(spec.input_schema)}- Output must conform to: {json.dumps(spec.output_schema)}- Raise ValueError with clear messages on invalid input- Avoid network access and file I/O outside the skill directoryReturn ONLY Python code.""" code = await self._llm.complete(prompt, temperature=0.2) script_path.write_text(code, encoding="utf-8")Sandbox:隔离执行 + 自愈循环(带重试上限)
class SkillSandbox: """基于子进程的隔离沙箱(生产环境替换为 Firecracker 微VM)""" async def evaluate_with_self_heal( self, skill_pkg: SkillPackage, max_retries: int = 3) -> SkillTestResult: for attempt in range(max_retries): result = await self._run_pytest(skill_pkg) if result.success: return result # 失败 → 收集错误快照 → 调用 LLM 修复 → 再跑 snapshot = self._capture_failure_context(result) await self._self_heal(skill_pkg, snapshot) return SkillTestResult(success=False, stderr="Max retries exhausted")SkillRegistry:版本控制 + 热加载
class SkillRegistry: """支持语义版本和动态热加载的技能注册表""" async def register(self, skill_pkg: SkillPackage) -> SkillRecord: # Git 自动提交,每个版本可追溯 await self._git_commit( skill_pkg.root_dir, f"feat: register {skill_pkg.name} v{skill_pkg.version}" ) record = SkillRecord( name=skill_pkg.name, version=skill_pkg.version, path=skill_pkg.root_dir, status=SkillStatus.ACTIVE ) self._index[skill_pkg.name + "@" + skill_pkg.version] = record # 热加载到当前进程 await self._hot_load_module(skill_pkg) return record代码没有多复杂,核心是 把生成、执行、管理这三个关注点彻底解耦。这也是我认为学术界方案离工业级落地最需要补的课之一。
06. 回到 MiroFish:当每个人都在成长
聊回我一开始提到的 MiroFish。
我做的那个实验,本质上是让一群 AI 模拟个体在特定场景里互动,看能不能涌现出群体智能。但这个实验一直有一个根本缺陷。每个个体没有成长性。
你让 100 个 Agent 模拟一个社区的日常运作,它们第一天和第 100 天的行为模式不会有本质区别。工具集是固定的,不会从经验中学习,不会在失败后自我调整。
如果每个 Agent 都带着一个自进化的技能引擎呢?
想象一下:Agent A 在处理物流调度时发现了一个高效算法,把它封装成 skill 注册到了共享库。Agent B 在另一个子系统中遇到类似问题,发现了这个 skill,加载适配再用。Agent C 在这个基础上做了优化,提交了 v2。
Skill 就像生物学里的模因,在智能体之间传播、交叉、变异、进化。
这就是 MUSE + MiroFish 结合后的想象空间:群体中的个体不再是静态执行器,而是持续自我学习的「人」。100 个、1000 个这样的个体在一起时,涌现的就不只是行为模式了。那是集体层面的进化能力。机箱的风扇声在深夜格外清晰,我盯着屏幕上的数据流,脑子里翻来覆去就一个念头:这东西如果真跑起来,会变成什么样?
这个想法让我想起刘慈欣在《三体》里描绘的「宇宙社会学」——每个文明是一个节点,在黑暗森林般的博弈中自发形成某种秩序。只不过在这里,每个 Agent 不是互相猜忌的猎人,而是共享技能库的协作者。哪个版本更接近未来?我猜都会发生。
07. 三个最值得关注的应用场景
聊到落地,我觉得自进化技能最先渗透的是这三个领域:
企业工作流自动化。 ERP 升级了接口?CRM 改了字段?以前得等开发排期改代码。如果 Agent 自带技能进化,它自己检测接口变化→自动生成新连接器→测试通过→上线。从「等人改代码」到「自发现自愈」,效率提升不是一个量级。SkillForge 的实践已经证明,在有足够历史工单的场景下,多轮自动演化的技能可以超过专家手写水平。ALITA-G 给这个场景又加了一块拼图:它能把用户操作轨迹直接合成为 MCP 工具,意味着「人做一遍」就是「Agent 学会了」。
DevOps 运维自愈。 半夜收到报警,以前值班工程师被叫起来看日志。如果智能体能自动定位根因、生成修复代码、沙箱验证、推上线,MTTR(平均修复时间)行业预估能降 60%-80%。而且每次修复都被沉淀成一个 skill,下次同类故障不用再造轮子。
异构数据分析。 金融分析师最头疼的是什么?每个数据源格式都不一样。如果 Agent 能根据失败反馈自动生成适配器,不挑食,喂什么数据都能分析。医疗 HIS 接口、上市公司财报、科研论文表格,都让 Agent 自己去读→出错→生成解析器→修复→沉淀。
也要清醒。这些场景目前都处于早期。MUSE 论文自己都说,51 个任务只成功生成了 68.6% 所需要的 skill,还有 16 个任务完全没搞定。某个 HVAC 控制任务的 skill 从 80% 准确率退化到了 20%。跨分布泛化能力还远不够用。
08. 开发者,你的角色正在变
写到这我想抛一个问题给你。
如果一个系统里的 AI 可以自己写工具、自己修 bug、自己迭代升级,而且效果比人写的还好,那开发者干嘛?
我的判断是:开发者正在从「造工具的人」变成「管生态的人」。
你不会再去写具体的 skill 函数了。但你要设计 skill 的进化策略,定义安全边界和合规规则,在技能冲突时做仲裁。就像你不再写操作系统内核了,但你在配置 Kubernetes 的调度策略。
怎么说呢,这个转变让我有点兴奋也有点不安。
论文还没合上。MiroFish 还在跑。我摸了摸键盘上那个已经被磨平的 E 键。这些年写了多少代码才把它敲成这样。以后可能不需要我亲自敲了。但我得决定什么代码该让它敲、什么不该。
说到底,「skill 像软件一样迭代」这件事不是技术问题。它最终是个治理问题。
屏幕上的代码还在跑。我有答案吗?说实话,还没有。
说实话,你对「AI 自己给自己造工具」这事怎么看?兴奋更多还是不安更多?评论区聊聊,我在看。
觉得不错就「一键三连」
局限性说明:本文对 MUSE-Autoskill 论文的解读基于 arXiv 预印本(arXiv:2605.27366),尚未经过同行评审。文中提出的 ESE 六层架构是笔者基于行业调研的个人设计构想,尚未在生产环境中完整验证。Performance 数据引用自论文原文 SkillsBench 评测,但 51 个任务的覆盖范围有限,不能代表全部工业场景复杂度。MiroFish 项目的实验描述基于笔者的个人项目经验,尚未公开发表。对 Multi-Agent 涌现效应的讨论包含大量推测成分,属于「我觉得应该会这样」级别的判断,读者请自行拿捏。
延伸阅读:
• MUSE-Autoskill 论文 (arXiv 2605.27366)[1] — [必读] 字节跳动+罗切斯特理工最新论文,本文所有分析的基础 • Voyager: 具身智能体技能探索 (NVIDIA)[2] — [奠基作] 第一个在 Minecraft 中实现技能库持续积累的工作 • Model Context Protocol 官方文档[3] — [行业标准] 理解 MCP 协议是理解 AI 工具生态的基础 • AutoSkill: 对话驱动的终身技能学习 (ECNU)[4] — [对照阅读] 从交互轨迹中自动提炼技能的学术方案 • CoEvoSkills: 生成器-验证器共进化[5] — [架构参考] 生成器和验证器分离的设计思路,ESE 的重要灵感来源 • Memento-Skills: 基于强化学习的技能状态化提示[6] — [对照阅读] 用 RL 替代手工记忆,与 MUSE 技能级记忆的不同技术路线 • EvoSkill: 零样本迁移与帕累托技能进化[7] — [补充阅读] 失败模式分析驱动的技能进化,与 MUSE 互补 • CEDAR: 反例驱动的确定性 Agent[8] — [安全视角] 放弃通用语言换取形式化验证,安全性的另一种极端解法
相关标签:#AI智能体 #自进化系统 #LLM #MCP #技术架构 #MiroFish #群体智能
引用链接
[1] MUSE-Autoskill 论文 (arXiv 2605.27366): https://arxiv.org/abs/2605.27366[2] Voyager: 具身智能体技能探索 (NVIDIA): https://arxiv.org/abs/2305.16291[3] Model Context Protocol 官方文档: https://modelcontextprotocol.io/[4] AutoSkill: 对话驱动的终身技能学习 (ECNU): https://arxiv.org/abs/2603.01145[5] CoEvoSkills: 生成器-验证器共进化: https://arxiv.org/abs/2604.01687[6] Memento-Skills: 基于强化学习的技能状态化提示: https://arxiv.org/abs/2603.18743[7] EvoSkill: 零样本迁移与帕累托技能进化: https://arxiv.org/abs/2603.02766[8] CEDAR: 反例驱动的确定性 Agent: https://openreview.net/pdf?id=IyMoawG676
