 夜雨聆风
夜雨聆风大家好,我是柿子👋,这是我写的第36篇原创!感谢大家每一次的阅读与点赞,话不多说,我们开始!
上周我做了一件不可思议的事——把花了一个多月反复打磨的 system prompt 整段删了。
不是因为它写得不好,而是因为换到 GPT-5.5 之后,它反而成了拖油瓶。
把所有「第一步做 X、第二步做 Y、第三步检查 Z」的步骤指令删掉,只留下任务目标和一个验收标准。结果输出质量没降反升,平均延迟也少了三分之一。
那一刻我意识到,OpenAI 在 GPT-5.5 Prompt 指南里说的那句话不是客套:别再手把手教 AI 怎么做了,告诉它你要什么结果就行。
我对OpenAI发布的Prompt 指南进行了详细的拆解,包含 4 个 Outcome-First 要素清单 + 5 步迁移 SOP + 3 个翻车场景反例,下面分享给大家:
一、从 SOP 到 PRD,Prompt 工程的范式跃迁
很多人看完官方指南的第一反应是:那我把以前的长 Prompt 删一半不就行了?
错。
如果你只是删长度,没换思维,结果只会比以前更差——这是过去两周很多人踩的坑,包括我自己。
旧 Prompt 像写代码:精确控制每一步,生怕 AI 理解错了,所以写成了「第一步做 X,第二步做 Y,第三步检查 Z」。
新 Prompt 像写 PRD:定义验收标准,让模型自己规划路径。
这背后是 AI 能力的本质跃迁——GPT-5.5 这一代模型已经具备了真正的「自主规划能力」,你给它一个明确的验收标准,它会自己决定用什么路径到达。
你过去写的那些步骤型长 Prompt,在新模型里反而成了噪音。它会限制模型的搜索空间,或者让输出过于机械。
OpenAI 官方文档里有一句话特别扎心——「从一个全新的基线开始迁移,而不是把旧 Prompt 栈里的每一条指令都搬过来」。
翻译成产品语言就是:以前你在写 SOP,现在你在写 PRD。
这两种思维方式的差别,不在文字长度,而在「我控制什么」。
写 SOP 的人控制过程,写 PRD 的人控制结果。
懂这个差异,下面那套 4 要素清单才用得上。
二、Outcome-First 不是写得短,是写得准——4 个要素清单
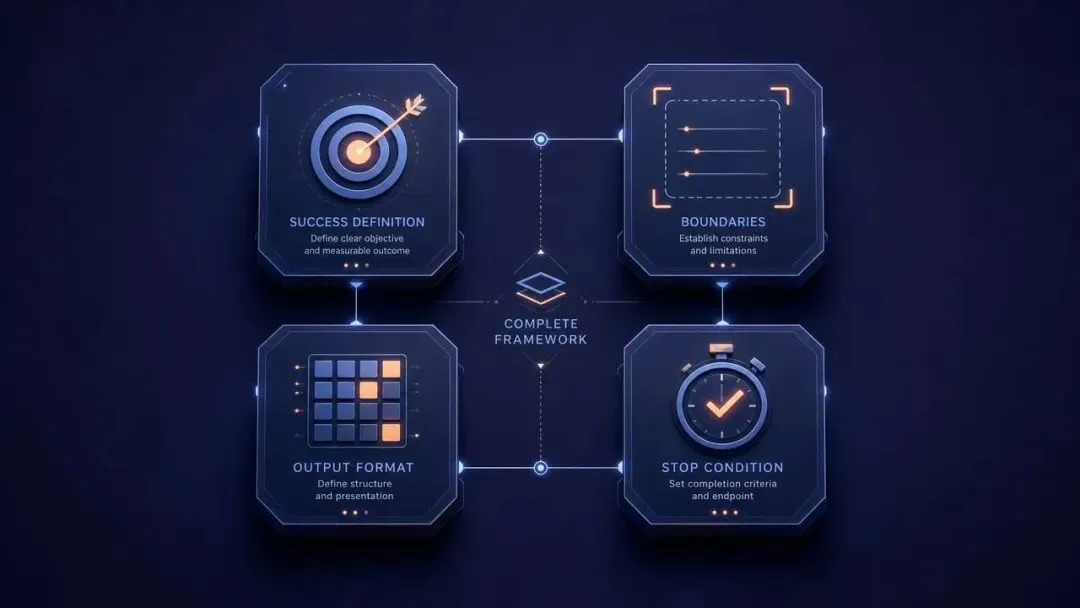
真正的 Outcome-First Prompt,需要把 4 件事写到位。
要素 1:明确的成功定义
反例:「帮我分析这份数据」
正例:「输出一份包含 3 个核心指标趋势、2 条异常预警、1 个决策建议的分析报告,每条建议必须标注优先级和预期影响」
一句话:把「做什么」换成「产出长什么样」。
PM 视角下,这就是 PRD 里最关键的那一栏——「交付物形态」。模糊的成功定义,模糊的交付。
要素 2:清晰的约束边界
什么可以做,什么不能做。
比如「只能基于已提供的数据,不要编造数字」「如果数据缺失超过 20%,必须在开头标注数据质量警告」。
这是 PRD 里的「非功能性需求」——一个产品什么不能做,往往比能做什么更重要。
要素 3:具体的输出格式
是要 JSON 还是 Markdown,是要表格还是列表,字数控制在多少以内。
注意一个反直觉的 OpenAI 官方建议——避免在 Prompt 里写 schema 描述,改用 Structured Outputs API。后者自动校验、提升准确率,比你在文字里啰嗦十遍「请输出 JSON 格式」可靠得多。
这是交付物的形态约定,能机器化的就别用语言再啰嗦。
要素 4:可验证的停止条件
什么情况下可以停止。
搜到能回答问题的信息就停,还是搜满 5 个来源才停,这个要明确。
不写清楚停止条件,模型在 agentic 任务里会变成「想太多」型选手——一个简单查询能跑 30 次工具调用,token 烧光,效果反而打折。
这是验收标准里最容易被遗漏的一栏,但也是新 Prompt 时代成本控制的命门。
写好这 4 个要素,你的 Prompt 就有了 PRD 的骨架。下面要补充的,是 GPT-5.5 本身带来的几个隐藏变化。
三、除了写法换了,还有 3 件事必须知道
变化 1: reasoning_effort 默认变成 medium,且新增了 none 档
很多解读文章在这里只提到 4 档,其实 OpenAI 这次实际是给了 5 档:none / low / medium / high / xhigh。
我的实测经验是这样的:
none:极速场景,比如语音对话的轻量回合、快速分类,不需要规划和多步工具调用
low:仍需要一点推理但延迟敏感,比如工具选择、简单规划
medium:80% 的场景用这档就够了,这是新的默认值,性价比最高
high:复杂 Agent 任务、需要硬推理且延迟不太重要的场景
xhigh:最难的异步 Agent 任务,或者测试模型智力上限的场景
关键建议是——不要一上来就开 high。
很多人觉得推理强度越高越好,结果成本飙升、延迟增加,但实际效果提升不到 20%。
如果你的任务本身指令就有冲突、停止条件不清晰,开高档反而会让模型「想太多」,质量倒退。
档位先用 medium 跑通,再针对效果不行的子任务局部上调,是更稳的姿势。
变化 2:默认风格更简洁直接
GPT-5.5 默认的输出风格是「高效、直接、任务导向」。
对很多生产场景这是好事,但如果你在做客服、营销、对话式体验,可能会觉得输出太「冷」。
解决方案是显式加 personality 引导 + 用 text.verbosity 控制详细度。
举个柿子实测有效的写法:
``
用温暖、专业的语气回复
每个建议要解释为什么这样做
避免生硬的列表式回复,用自然的段落表达`
这一段加上去之后,内容创作场景的输出温度肉眼可见地回来了。
text.verbosity 的取值也值得记一下:low 比 GPT-5.4 的 low 还要简洁,medium 是默认;需要详细解释别指望默认,必须在 Prompt 里明确要求。
变化 3:长 context 有个价格陷阱
这条是推文里没提、但 AI 创业者最容易踩的坑——Prompt 输入超过 272K token 时,整轮对话价格变成 2 倍 input + 1.5 倍输出,含 batch 和 flex 模式。
意思是你跑长 context 的评估任务、agent 工作流、文档批处理,预算可能会比预期翻倍。
应对方法是 prompt caching——把稳定不变的内容放请求开头,把动态用户上下文放最后。命中缓存能显著降低长 context 的成本。
具体省多少,得看你的稳定内容占比,不要拍脑袋估。
四、5 步迁移 SOP——不是改个模型名那么简单
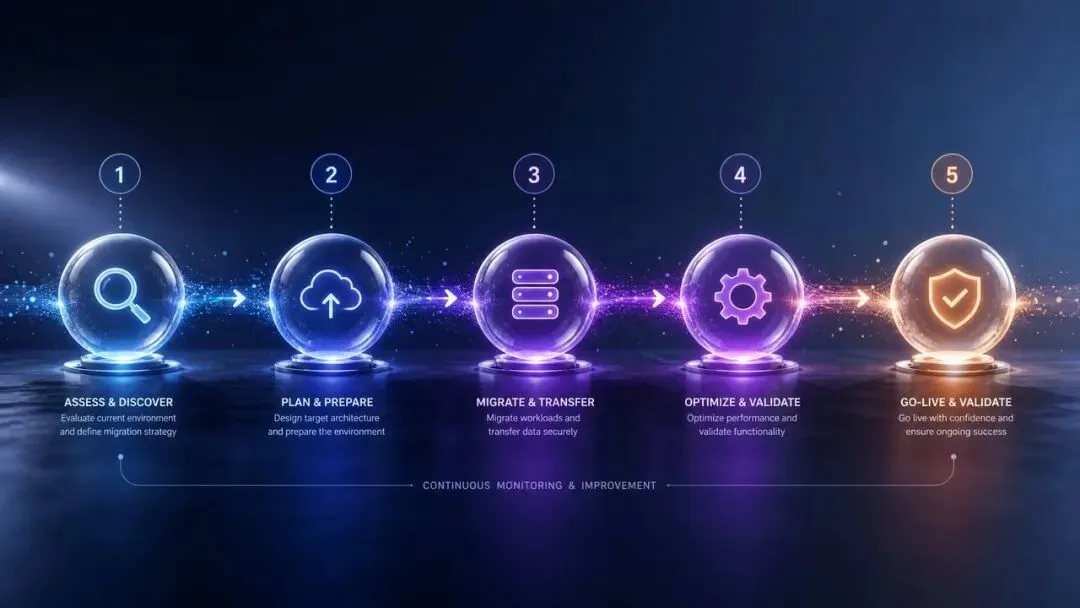
如果你现在用的是 GPT-5.2 或 GPT-5.4,迁移到 5.5 不是直接改个模型名那么简单。
我踩过的坑是:直接切换后,有些任务输出变得过于简洁,有些任务反而想太多导致延迟增加。
下面这套 5 步路径,是踩坑之后整理出来的可执行 SOP。
Step 1:API 参数调整
模型名改为 gpt-5.5
reasoning_effort 显式设置为 medium——虽然是默认值,但显式设置能避免未来默认值变化时被偷袭
如果需要简洁输出,把 text.verbosity 设为 low
Step 2:从零开始写 Prompt 基线(不要复制旧 Prompt)
这一步是最关键也最反直觉的。
具体动作:
只保留「任务目标」和「成功标准」
删除所有「第一步、第二步」式的过程指导
删除 Prompt 里的 output schema 定义,改用 Structured Outputs API
不要心疼,那些花心思打磨的步骤指令,是给上一代模型用的。
Step 3:在小规模测试集上跑一版对比
选 10-20 个核心场景,新旧输出并排看:
哪些变好了
哪些变差了
哪些格式变了
这一步别跳。如果跳过直接全量切换,你会被零散的体感反馈带着走,最后判断不清是 Prompt 的问题还是模型的问题。
Step 4:针对性补充约束
不要一次性把所有约束都补上,而是看测试集里哪类问题最多,对应补哪一类约束:
输出不稳定 → 加 output_contract 明确格式
输出太简洁 → 加 personality 和详细度引导
任务完成度不够 → 加明确的停止条件和验证规则
每加一条都跑一遍测试集,看新增的约束有没有副作用。
Step 5:最后调整 reasoning_effort
注意,这一步是最后。
只有在 Prompt 结构稳定后,才根据任务复杂度调节这个参数:
简单提取、格式转换 → low
复杂 Agent、多步推理 → 保持 medium 或升到 high
如果你 Prompt 还没稳定就先调档位,永远分不清效果变化是 Prompt 改的还是档位改的。
5 步走完,你才算真正完成了一次 GPT-5.5 迁移。
五、Outcome-First 也有翻车的时候——3 个反例

结果导向听起来很美好,但有 3 种情况下会翻车。
翻车 1:创意类任务过度约束
如果你要的是一篇有趣的科幻短篇,纯结果导向会让输出变得套路化。
因为你定义了太多「成功标准」,模型反而不敢发挥。
这时候要反过来——给一些过程自由度。比如说「情节必须有 2 次反转」「主角性格要立体,不要脸谱化」,但不要规定具体怎么转。
创意需要留白,验收标准只画外框。
翻车 2:多轮对话中的指令漂移
如果用户中途改了需求,GPT-5.5 可能记不清之前的约束。
解决方案是每次指令更新时,明确说「这条新指令覆盖之前的 XX 规则」或者「这条新指令是补充,之前的规则依然有效」。
不要假设模型自己知道你想覆盖还是想叠加。
翻车 3:低质量输入
如果你的输入数据本身就很乱,比如 OCR 识别错误很多的文档,再好的「验收标准」也救不回来。
这时候需要先加一层输入质量检查:
`在开始分析前,先检查:
数据完整性是否 > 80%
关键字段是否缺失
文本可读性是否达标
如果质量不达标,返回具体的质量问题清单,不要强行分析``
垃圾进,垃圾出。
让模型先判断输入能不能用,比让它强行处理一堆烂数据再返工,要省得多。
写在最后:产品经理在 AI 时代反而更值钱了
GPT-5.5 的能力天花板很高,但要真正用好它,靠的不是少写几个字,而是更清晰地定义问题。
这也是为什么我说,产品经理思维在 AI 时代反而更值钱了。
你越懂如何定义需求、如何写验收标准、如何设计契约,就越能让 AI 发挥出最大价值。
以前 PM 在大厂常被开发说一句话——你只动嘴不动手。AI 时代反过来了:你嘴里能说出来的那套「定义需求 / 写验收标准 / 拆解交付契约」的能力,就是 AI 工程师再多代码也补不来的。
这不是 Prompt 技巧的变化,是我们和 AI 协作方式的根本转变。
那些花几个月精心打磨的长 Prompt,没有白写——它们训练的不是 AI,是你自己的产品思维。这套能力放到 GPT-5.5 上反而开花了。
