 夜雨聆风
夜雨聆风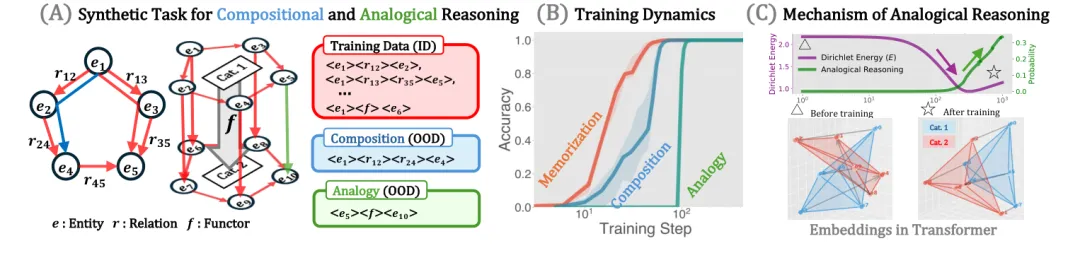
一句话摘要:东大+DeepMind 用合成实验拍下了 Transformer 学会"类比推理"的瞬间——训练到某一时刻,模型表征空间里两个领域的关系图突然几何对齐,准确率从近零跃升到接近满分。机制拆开看其实非常机械:先把两个类别的概念地图"摞"在一起,再让注意力做一次向量加法。同样的现象在 LLaMA-3、Gemma-2 等预训练大模型的 ICL 类比中也存在,只是对齐沿"层深"展开。(原论文题目见文末,点击阅读原文可直接跳转至原文链接,Published on arXiv on 27 May 2026, by The University of Tokyo)
各位小伙伴好,我创建了学术交流群,涵盖大模型Agent/CV/深度学习/多模态AI流行趋势等各个方向,欢迎进群交流,一起进步!

第一阶段:识别核心概念
论文的motivation分析
在人工智能领域,大型语言模型的“组合推理”能力已经得到了广泛的研究。然而,人类认知中更具创造性的一面是“类比推理”,即识别两个完全不同领域(例如太阳系与原子结构)之间共享的结构相似性,并实现概念上的跨越。
尽管当前Transformer模型在各项任务中大放一新,但其内部如何涌现、捕获并实现这种深度的类比推理机制,依然是一个黑盒。本研究试图从数学逻辑和几何表征两个维度,系统解构Transformer在训练和推理过程中,其内部表征空间和注意力机制是如何协同构建出类比映射能力的。
论文主要贡献点分析
主要创新点
• 基于范畴论的类比任务形式化:利用范畴论中的“函子(Functor)”概念,将类比推理严格定义为不同实体类别之间的对应映射,并设计了可精准控制的合成任务。
• 解析类比推理的底层机制:首次将类比推理拆解为两个核心几何现象,即表征空间中的“几何对齐”与注意力层内的“向量平移加法”。
• 层级涌现现象的跨模型验证:发现预训练语言模型(如Gemma-2和LLaMA)通过上下文学习也展现出相同的类比对齐机制,且这一过程在网络深度(层级轴)上 progressive 地展开。
支撑创新的关键技术
• 多维狄利克雷能量(Dirichlet Energy):引入该指标来定量评估不同实体类别的几何结构在表征空间中的重合与对齐程度。
• 类比平行度(Parallelism Measure):设计余弦相似度指标,精确测量模型最后一层输出的实体差值向量与初始函子向量的一致性。
理解难点识别
关键概念与最具挑战性的部分
• 狄利克雷能量在表征对齐中的物理意义:理解高维空间中两个完全不同的实体集合如何通过降低狄利克雷能量,使其在几何拓扑结构上实现近乎完美的重叠,这是理解论文定量分析的最大难点。
• 残差流中的平移机制:Transformer如何通过自注意力机制提取源实体的特征,并通过残差连接将该特征与函子向量相加,从而直接命中目标实体的表征。
重点解释的核心概念
• 几何结构对齐(Structural Alignment)
• 函子应用的向量算术(Vector Arithmetic as Functor)
概念依赖关系
• 基础前提:不同领域内实体之间的关系网络需要满足结构同构性(Isomorphism)。
• 空间准备:通过训练或上下文学习,Transformer在表征空间中对齐这些同构的几何结构(狄利克雷能量下降)。
• 执行映射:通过自注意力机制搬运特征,利用残差连接执行向量加法,最终预测出目标实体。
第二阶段:深入解释核心概念
设计生活化比喻:双子乐园的“地图重合”与“穿梭巴士”
有两个相互独立的主题乐园:一个叫**“魔法城堡乐园”(源类别),另一个叫“科幻未来世界”(目标类别)**。
• 两个乐园在景点设计和布局上完全对称。魔法乐园入口左侧有**“旋转木马”(源实体),高度最高处有“超级过山车”;科幻世界对应的位置则分别是“模拟飞行器”(目标实体)和“星际穿梭机”**。
• 这两个乐园之间通过一条专用轻轨连接,轻轨上运行着一辆**“跨园穿梭巴士”(函子)**。
当游客身处魔法乐园的“旋转木马”时,想要类比出科幻世界里哪个设施和它扮演相同的角色:
• 第一步(地图重合):将两张印在透明胶片上的乐园地图叠放在一起。如果两张地图方向相反,叠在一起时景点位置会杂乱交织。只有通过旋转、移动,使两张地图边界完全对齐(狄利克雷能量降至最低),这时“旋转木马”和“模拟飞行器”就会重合在同一个平面坐标上。
• 第二步(穿梭巴士):在地图对齐后,从魔法乐园的任何景点去科幻世界的对应景点,只需要乘坐那辆固定行驶方向和距离的穿梭巴士。这种固定的空间位移,就是向量加法操作。
比喻与实际技术的对应关系
| 比喻元素 | 实际技术概念 | 合理性解释 |
|---|---|---|
| 主题乐园 | 范畴(Category) | 包含了实体及其内部关系的完整知识域(Domain)。 |
| 游乐设施 | 实体(Entity) | 表示空间中的高维节点特征向量。 |
| 景点之间的相对位置关系 | 关系(Relation) | 两个实体向量之间的空间差值或变换矩阵。 |
| 地图边界完全重合 | 降低狄利克雷能量(Dirichlet Energy) | 降低能量意味着具有类比映射关系的实体在多维空间中的物理距离最小化。 |
| 跨园穿梭巴士的行驶路线 | 函子(Functor) | 跨越两个范畴时,表现为一个方向和长度固定的平移向量。 |
深入技术细节
公式 1:多维狄利克雷能量(Dirichlet Energy)
为了量化不同类别实体在空间中的对齐程度,引入图信号处理中的狄利克雷能量:
符号替换版本:
原理解释:
• 代表邻接关联。如果实体 与实体 具有类比对应关系,其值为 ,否则为 。
• 衡量两个实体在 Transformer 嵌入空间中的欧氏距离平方。当对应实体的表征结构在空间中完美对齐时,它们之间的距离最小,总狄利克雷能量降至最低。
公式 2:类比平移实现(Functor Application)
当嵌入空间的几何结构完全对齐后,跨类别的映射在数学上被简化为恒定的向量叠加:
符号替换版本:
原理解释:
• 是源实体(旋转木马)在嵌入层输入端的向量表示。
• 是代表类比变换的特殊 Token(穿梭巴士)在表示空间中的偏移向量。由于空间已对齐,在源实体的基础上加上这一固定的平移量,就能精确定位到目标实体的表征区域。
公式 3:类比平行度(Parallelism Measure)
为了定量验证神经网络是否真的在使用平移操作执行推理,计算实际输出差值与函子向量之间的夹角余弦值:
符号替换版本:
原理解释:
• 该值范围在 到 之间。当其余弦相似度趋近于 时,证明模型确实是通过在源实体上叠加一个方向与 高度平行的向量,来实现目标实体预测的。
将技术细节与比喻相互映射
• 地图对齐与狄利克雷能量:降低狄利克雷能量在物理上就等同于旋转、缩放并叠合两张透明地图。只有当能量处于极低水平时,地图上的景点坐标才能在投影上精确重合,为后续的向量算术奠定几何基础。
• 穿梭巴士与向量加法 :地图对齐后,不管游客从魔法城堡的哪个景点(源实体)出发,想要到达科幻世界的对应景点,所需要行进的距离和方向(平移向量 )都是一模一样的,直接进行加法运算即可。
• 比喻的局限性:在实际的自然语言或复杂的图关系中,两个领域的关系网络很难达到完全理想的同构对称(完美等距映射)。因此,在处理噪声和部分重叠的领域时,两张地图无法做到处处对齐,狄利克雷能量会残存一些无法消除的背景噪声。
第三阶段:详细说明流程步骤
完整方案处理流程
1. 输入文本 Token 化与特殊标记定位
系统接收表示类比关系的输入 Prompt。
• 例如:<e1> a <e2>, <e1> b <e3>. <e6> a <e4>, <e6> b <e7>. <e1> ~ <e6>, <e3> ~ <e
• 文本序列通过分词器映射为一维整型 Token ID 序列,其中 ~ 对应代表函子平移操作的特殊占位符。
2. 嵌入空间投影与几何对齐
Token ID 序列进入模型的嵌入层。
• 实体 Token(如 )和关系 Token 映射为多维稠密向量。
• 经过训练调整后的嵌入空间已经使得属于不同乐园(类别)的实体簇在空间中保持平行的几何拓扑排布。
3. 自注意力特征路由
向量化后的序列送入 Transformer 层的注意力机制。
• 在当前位置(即待预测位置之前的函子 Token 处),自注意力头计算查询向量与前文所有键向量的点积。
• 注意力机制将大比例的权重分配给代表源实体 的特征通道,将 的多维隐藏层表示抽取并路由至当前的输出节点。
4. 残差流特征叠加与向量平移
注意力层的输出通过残差连接与函子 Token 本身的初始表征向量进行叠加。
• 在物理机制上,该步骤直接在源实体表示向量上执行了一个恒定的位移加法:
• 产生的输出向量 在对齐的高维几何空间中,正好被推移到了目标实体 向量所在的精确坐标范围。
5. 解耦层投影与目标预测
平移后的高维特征向量输入最终的线性解耦层(Unembedding Layer)。
• 输出特征通过解耦权重矩阵投影至全词表维度,产生对数概率值(Logits)。
• 对数概率通过 Softmax 激活函数计算,最终在对应的目标实体 位置上输出最大概率,模型顺利完成类比推理。
具体流程伪代码逻辑
# 输入:Token ID 序列 [e1, a, e2, e1, b, e3, e6, a, e4, e6, b, e7, e1, f, e6, e3, f, blank]# 输出:预测的目标实体概率分布1. 嵌入投影:X_embed = embedding_lookup(token_ids) # 包含已经降能对齐的实体簇2. 注意力计算:Q = X_embed * W_qK = X_embed * W_kV = X_embed * W_vattn_weights = softmax(Q * K.T / sqrt(d))# 函子 Token 处的注意力权重精准汇聚到源实体 e3 的表征上context_vector = attn_weights[functor_index] * V3. 残差叠加(实现平移):residual_out = context_vector + X_embed[functor_index] # 等价于 e_s + f4. 解耦投影与输出:logits = residual_out * W_unembedprediction_probabilities = softmax(logits) # 目标实体 e7 获得最大概率值
第四阶段:实验设计与验证分析
主实验设计解读:核心论点的验证
• 核心主张:Transformer 可以通过降低表征空间的狄利克雷能量来实现不同领域实体之间的几何结构对齐,进而实现类比推理。
• 实验设置:
◦ 数据集:构建合成的关系图谱结构,通过调节实体数量()、关系数量()来模拟不同复杂度的任务域。
◦ 评价指标:分布外测试集(OOD)上的类比预测准确率和组合推理准确率。
◦ 基线对比:在训练时间轴上持续追踪训练准确率、组合推理 OOD 准确率和类比推理 OOD 准确率的爬升曲线。同时引入 Gemma-2 和 LLaMA 等真实的预训练大模型进行上下文类比测试。
• 合理性分析:
◦ 合成数据能够彻底规避语言先验带来的偏差,从而在纯净的结构化环境中揭示 Transformer 的几何规律。
◦ 引入真实的超大规模预训练语言模型进行一致性验证,则确保了这些几何机制并非局限于玩具模型,而是广泛存在于复杂真实模型的底层逻辑中。
• 主实验结论支撑:
◦ 如图 2 所示,在训练过程中,模型首先掌握基础事实的记忆,随后在极短时间内涌现出组合推理能力,最后才缓慢涌现出高阶的类比推理能力。这直接证明了类比推理在表征演进上具有更高级别的抽象性与延迟涌现特征。
消融实验分析:内部组件的贡献
结构同构性的破坏(Functor Noise Ratio,图 22)
• 消融手段:通过随机替换不同乐园(类别)之间对应的关系标签,引入非对称性结构噪声(Noise Ratio 范围从 变动到 )。
• 消融结论:随着噪声比例提升,OOD 类比预测准确率呈现出近乎线性的退化。当噪声为 时,类比能力完全丧失。这定量且有力地证实了类比推理必须依赖于底层的结构对称性。
显式函子标记的移除(Implicit Functor Variant,图 24)
• 消融手段:隐藏专门的 ~ 函子 Token,直接使用双重元组结构对模型进行隐式 Query。
• 消融结论:即使没有显式的标记,模型依然可以依靠注意力机制去对齐隐式的结构关系并涌现类比能力,但其对齐速度明显变缓且最终准确率略微降低,说明显式函子在模型内部起到了强有力的引导加速作用。
关系图稀疏性消融(Graph Sparsity,图 13)
• 消融结论:移除部分训练数据增加关系图稀疏度。实验表明组合推理对数据稀疏极具鲁棒性,而类比推理在图稍微稀疏化后即告破产。这佐证了类比推理高度依赖于全局图谱表征的稠密和完整性。
深度/创新性实验剖析:洞察方法的内在特性
实验一:预训练模型中的层级狄利克雷能量骤降与性能跃迁(图 9、图 21)
• 设计目的:验证在大模型未进行该合成任务微调的情况下,是否在参数内部原生存在这种几何对齐推理机制。
• 巧妙设计:在 LLaMA-3 和 Gemma-2 等预训练大模型上通过 ICL 提示类比,应用 Logit Lens 探测技术提取网络中间各层的激活向量,同时追踪狄利克雷能量与类比预测概率随网络深度的变化。
• 探究结论:实验展示出极其优雅的一致性趋势:在前十几层中,狄利克雷能量极高且目标实体预测概率近乎为零。而在特定的中后部层级,狄利克雷能量急剧下坠,与之伴随的是正确实体的预测概率同步实现指数级暴涨。这表明:在真实 LLM 中,上下文学习通过在深层网络(深度轴)执行 progressive 的对齐,重演了合成模型在训练时间轴上的涌现过程。
实验二:高维实体表征对齐的 PCA 降维演变(图 10、图 15、图 20)
• 设计目的:直观、无损地还原表征空间在对齐前后的几何相貌变化。
• 巧妙设计:提取不同训练轮数(图 15)和 LLM 不同网络层(图 20)下的实体特征表示,运行主成分分析(PCA)降维,在 2D 空间中连接两个类别相对应的各个实体顶点。
• 探究结论:可视化结果呈现出震撼的秩序涌现:初期空间完全无序杂乱。随着训练深入或层数变深,两个类别的实体点阵自发地发生了整体平移和刚体旋转,最终在空间中对称分布,对应节点之间的物理连线实现了高度的平行一致。这从最直观的视觉层面上证实了“平移对齐”这一机制假说。
实验三:双线性探针与平移空隙验证(Appendix T,图 27)
• 设计目的:排除其他非线性、非加法的潜在映射假说。
• 巧妙设计:在训练好的实体表征上训练一个双线性映射分类器(判定 ),并追踪关系权重矩阵 与函子平移方向 之间的“零空间比例(Null-Space Ratio)”。
• 探究结论:实验发现,在类比推理成熟后,函子方向 与关系变换矩阵之间的干涉极小,Null-Space Ratio 下降至 。这强有力地排除了非加法的变换假说,证明函子向量在几何上确实表现为一个干净的、不干扰内部固有关系的单纯平移量。
本文题目:Emergent Analogical Reasoning in Transformers
欢迎Deep Learning同好与我交流、讨论、合作!
