 夜雨聆风
夜雨聆风免责声明: 本文系对公开发表学术论文《Research on a Machine Learning-Based Method for Identifying the Distribution of Radioactive Source Terms on the Inner and Outer Walls of Metallic Pipelines》(IEEE Transactions on Nuclear Science, DOI: 10.1109/TNS.2026.3697727)的解读与专业点评,仅供核电子学及辐射探测领域学术交流与科普传播之用。文中涉及的数据、图表及结论归属原作者(Chen Fuquan et al., Chengdu University of Technology)。转载请注明出处,若有技术争议以原论文为准。
成都理工大学陈福权等人近期发表于国际权威期刊IEEE Transactions on Nuclear Science的这项研究,跳出了传统物理特征参数(如峰康比P/C)的窠臼,首次将LaBr₃(Ce)探测器实测γ能谱直接作为高维向量输入,对比SVM、1D-CNN与Transformer三种机器学习范式,实现了核级金属管道内外壁放射性污染源项分布及管厚的联合识别,其中Transformer模型测试集准确率高达96.19%,为该工程难题提供了极具前景的数据驱动解法。核电站在运期间,一回路及辅助系统大量使用不锈钢核级管道输送含放射性介质。管道内壁活化腐蚀产物(如⁶⁰Co)沉积与外壁泄漏裂变产物(如¹³⁷Cs)沾污并存,是现场辐射防护与退役去污策略制定的核心痛点。传统γ能谱法受金属壁衰减与康普顿连续区叠加影响,难以区分污染源在"内"还是"外";康普顿成像虽有空间分辨能力,却因厘米级分辨率不足及管壁屏蔽效应,无法可靠判别紧贴内外壁仅数毫米差异的污染源。
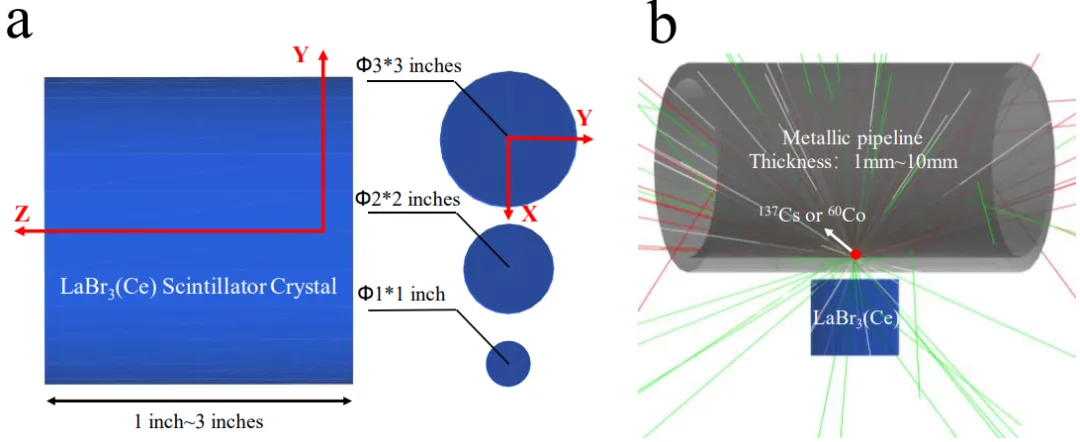
图1. Geant4模拟模型 (a) LaBr3(Ce)晶体模型,(b) 放射性金属管道测量模型。
论文实验体系构建相当扎实。作者采用Geant4模拟¹³⁷Cs(662 keV)与⁶⁰Co(1173/1332 keV)点源,不锈钢管道壁厚梯度变化(1–10 mm),LaBr₃(Ce)晶体尺寸对比(1″/2″/3″),定义了全能量沉积计数C_F与部分能量沉积计数C_P,引出全峰与部分沉积比FPR=C_F/C_P。模拟清晰表明:随壁厚增加γ光子在管壁内经光电效应、康普顿散射及电子对产生(>1022 keV)的概率上升,到达闪烁体的全能峰计数下降、康普顿平台抬升,FPR单调递减;且晶体越大FPR越高、更高能γ(⁶⁰Co)的FPR低于¹³⁷Cs——这些规律与图2、图3的蒙特卡洛能谱演化完全吻合,为后续"谱形差异蕴含源分布信息"的假设奠定物理基础。
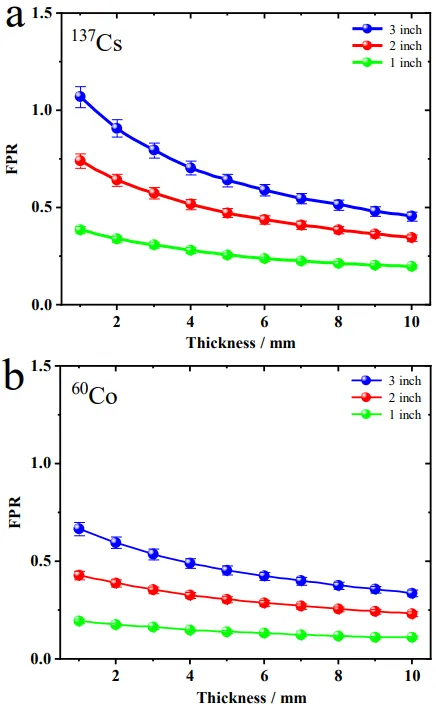
图2. (a) 137Cs源项的假阳性率变化曲线。 (b) 60Co源项的假阳性率变化曲线。
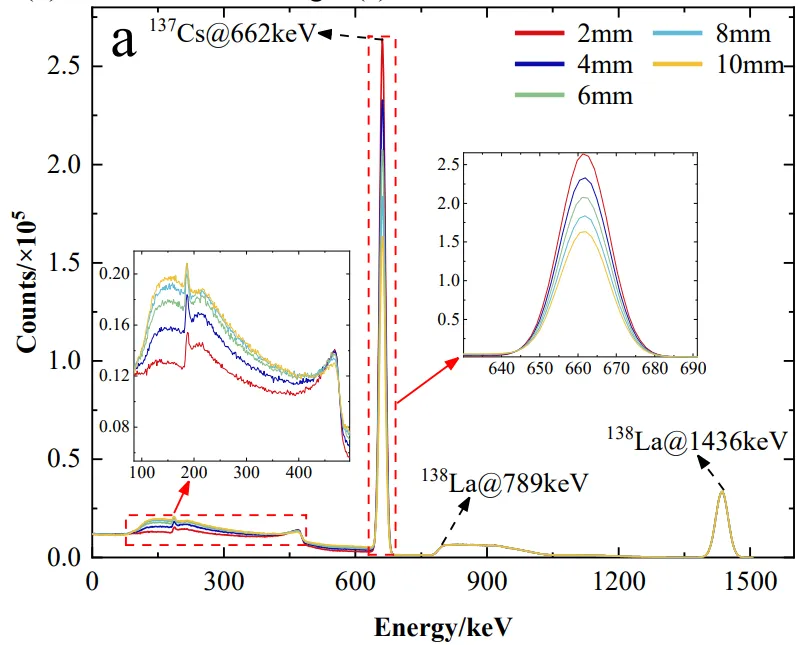
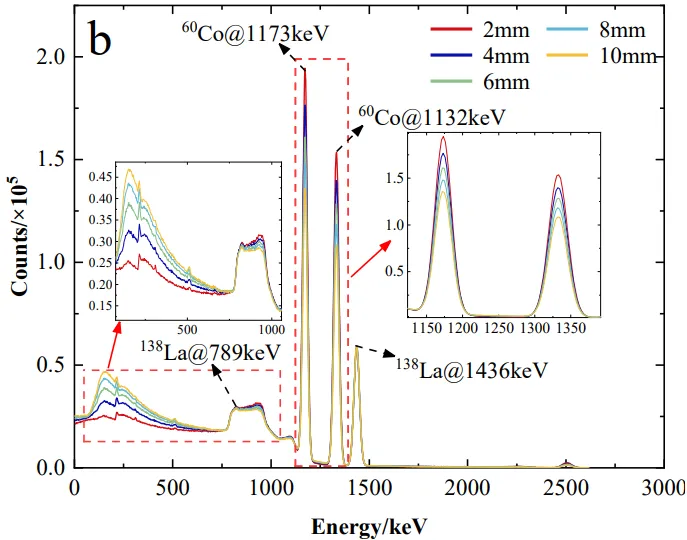
图3. (a) 137Cs源项的Geant4模拟能谱。(b) 60Co源项的Geant4模拟能谱。
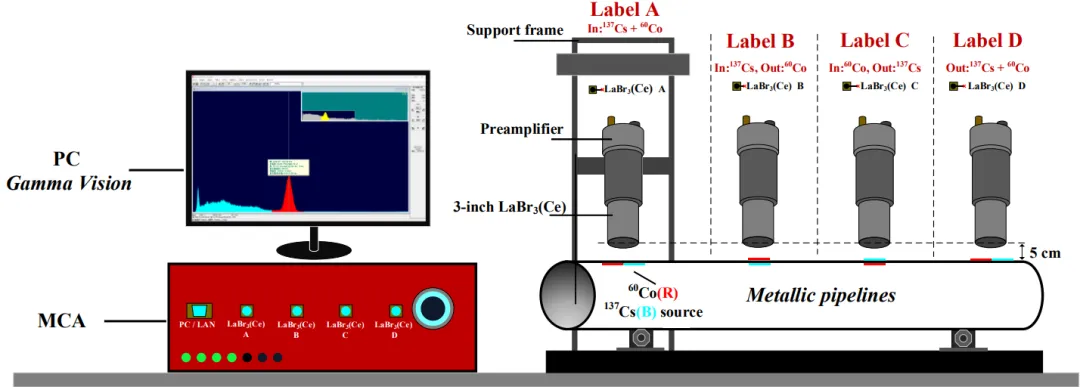
图4. 能谱测量系统设计示意图
实测平台选用φ3英寸LaBr₃(Ce)+Hamamatsu R6231-100 PMT+MCA(自研80MSPS,最高32768道),以实际表面源模拟四种污染源布局:¹³⁷Cs与⁶⁰Co分别置于管内/外壁组合出A(内-内)、B(内-外)、C(外-内)、D(外-外)四类空间分布,配合4种典型核工业管道壁厚(3/4/5/6 mm,对应外径OD 46–92 mm),共构造16个分类标签(A1–D4,见表I)。为逼近现场几何不确定性,探测器距管外壁分别取3/5/8/10 cm采集,每类110条谱(含不同测量距离与活度统计涨落),总计数经调整确保全能峰可辨——这一数据集设计同时编码了源位置、管厚、探测距离与统计噪声多维耦合信息,比单纯用MC模拟训练模型更贴近工程真实,是该文方法学上的一大亮点。
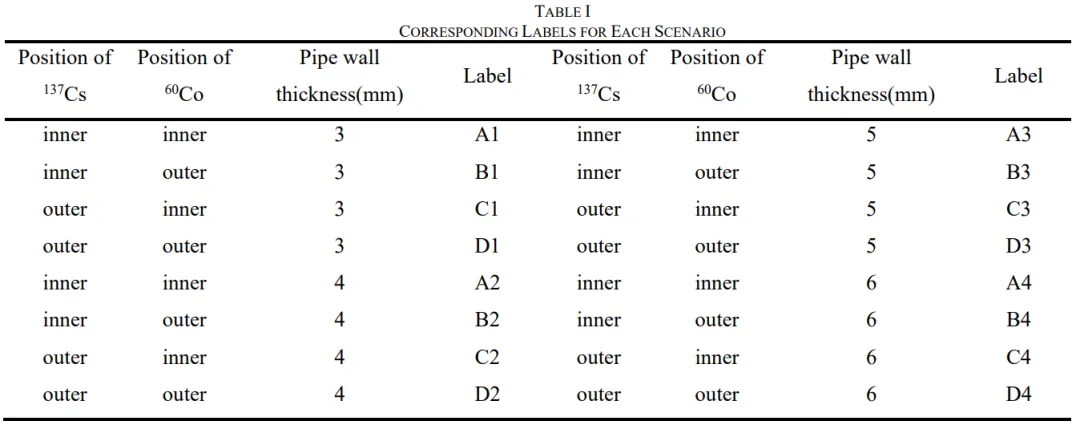
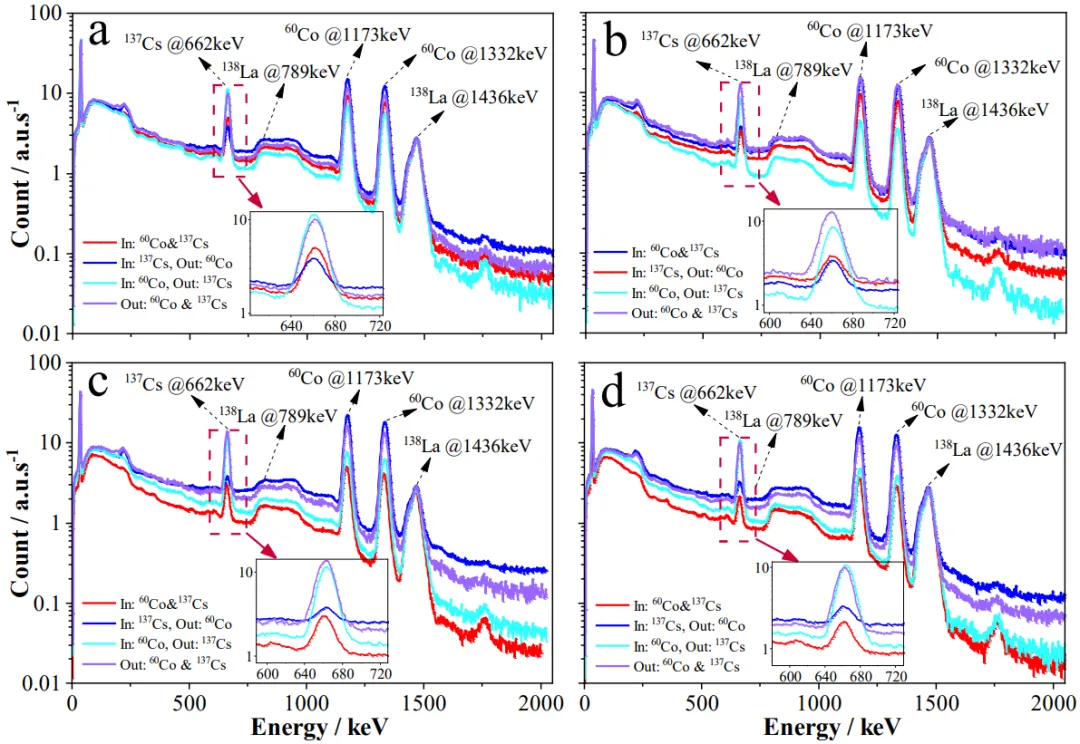
图5. 不同测量对象的典型能量谱对比。(a) 管壁厚度3毫米。(b) 管壁厚度4毫米。(c) 管壁厚度5毫米。(d) 管壁厚度6毫米。
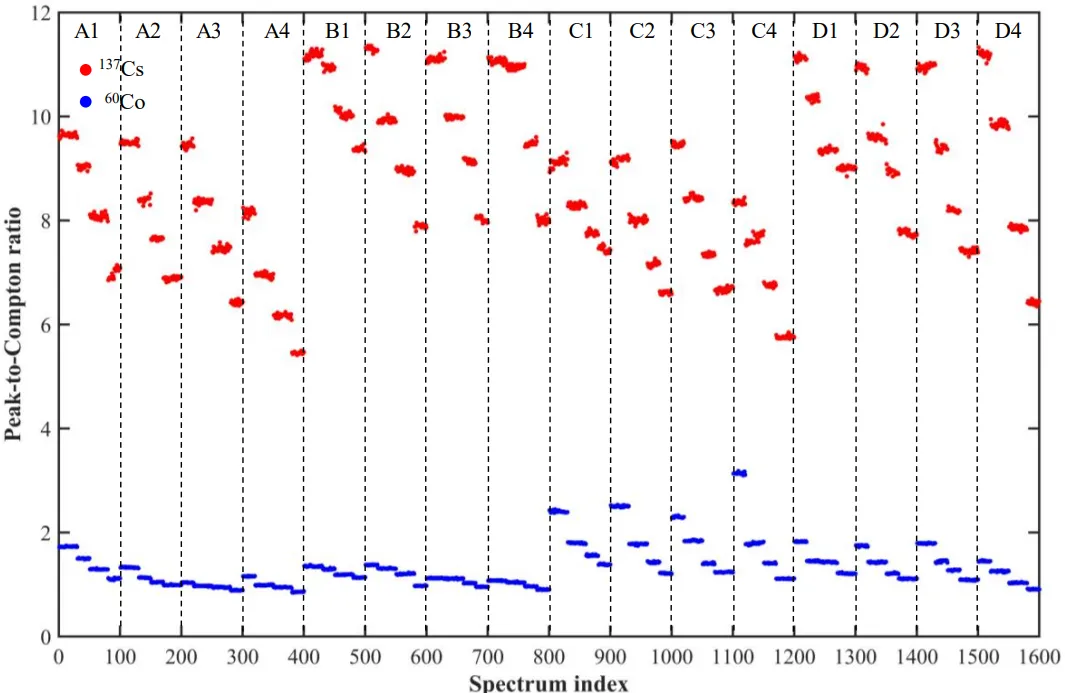
图6. 测量能量谱的峰康普顿比分布。
考虑到核现场不宜长期大剂量照射与海量标注数据采集困难,作者设计了基于实测谱的概率重采样"能谱反演扩增算法"(图7):以少量实测谱各道计数占比为采样概率P(i)=C(i)/C_total,随机生成N条bootstrap重采样谱,每条保留原始谱的噪声特征、能量分辨率展宽及本底影响。相比理想化MC模拟,此法用极少实测样本即可扩充出分布匹配的训练集(每类100条×16类),巧妙解决了小样本下深度学习过拟合风险,体现了核电子学"以实测为本"的务实思路。
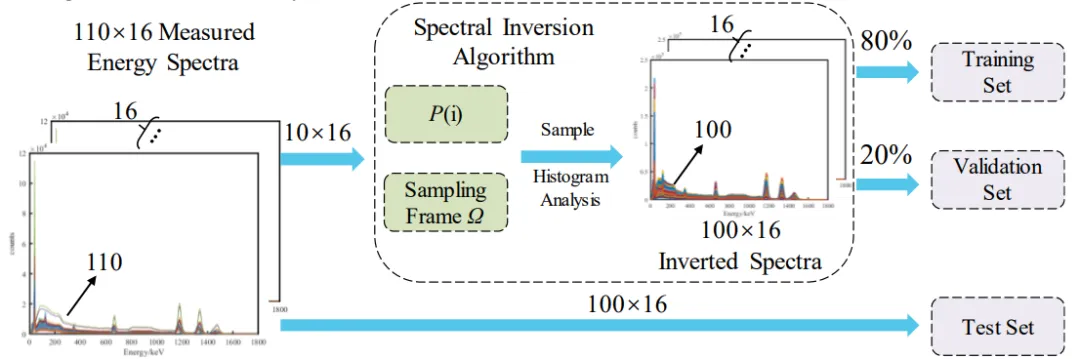
图7. 能量谱采样反演算法示意图
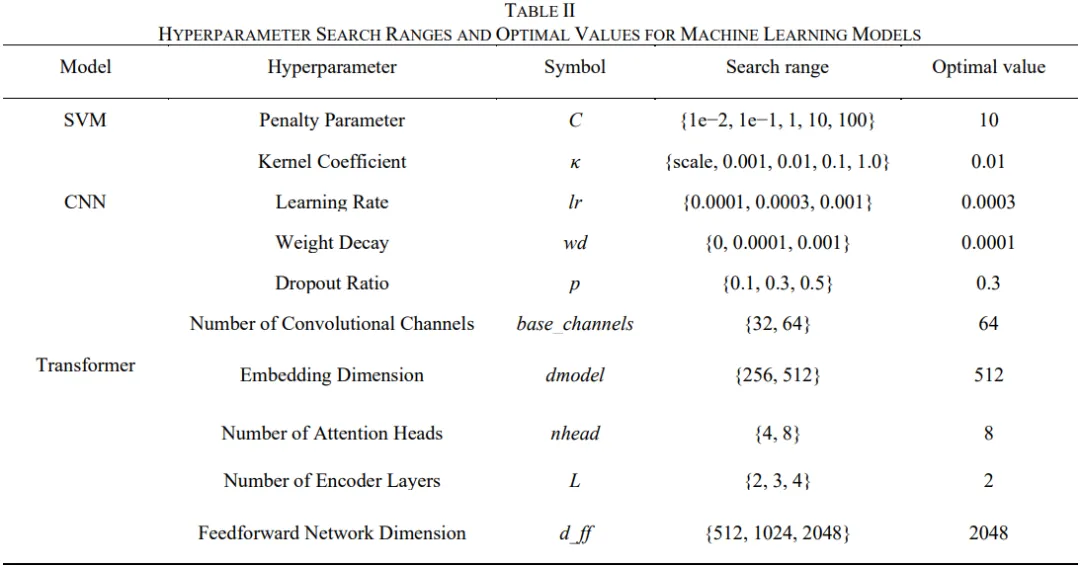
三类模型架构与超参寻优值得细品。SVM选用RBF核+OvR多分类,网格搜索得C=10、κ=0.01,适合高维谱向量但在本任务非线性边界捕捉力有限;1D-CNN由三组卷积块(64→128→256通道,含BN+ReLU+MaxPool)接全局平均池化与Dropout(p=0.3)双FC层,Softmax输出,两阶段粗–细网格搜得lr=3e-4、weight_decay=1e-4,侧重提取能谱局部形状(峰、谷、平台)的平移不变特征;Transformer Encoder则引入多头自注意力(d_model=512, n_head=8, L=2层, d_ff=2048),通过位置编码使各能量道相互"关注",能够建模全能峰、康普顿边缘、多核素峰间相对关系等全局谱形依赖——这恰是区分"内壁源经厚壁衰减"与"外壁源少屏蔽但经空气衰减"两种相似谱形的关键物理信息。 训练采用AdamW+早停,验证集加权F1为导向做两阶段超参搜索,流程规范严谨。
图8. SVM模型分类示意图。
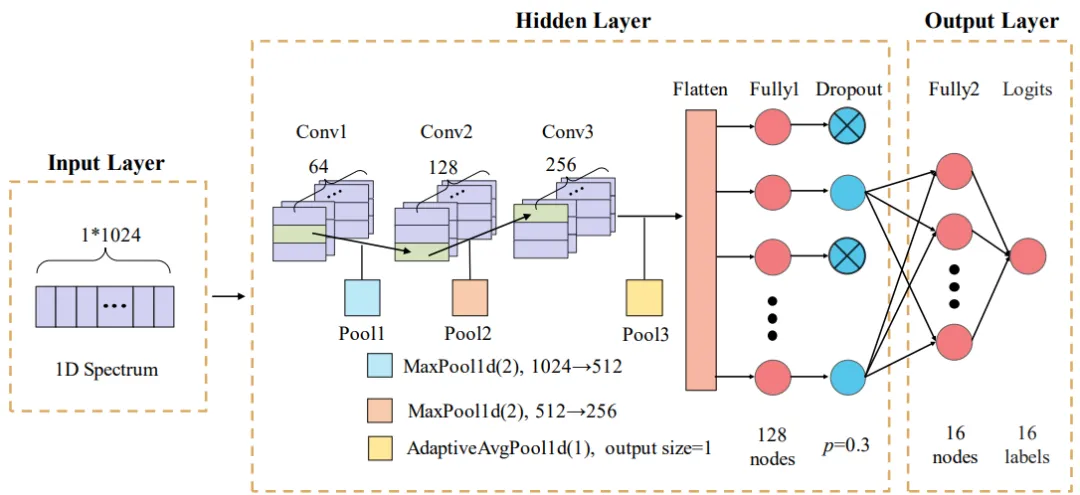
图9. CNN模型架构。
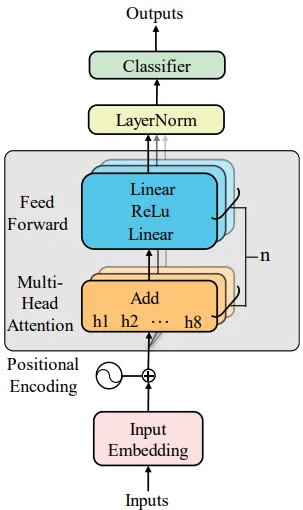
图10 Transformer模型架构。
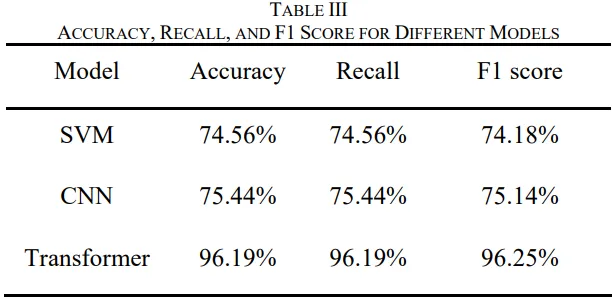
结果部分最具冲击力。Transformer在独立测试集上Accuracy=96.19%、Recall=96.19%、F1=96.25%,显著优于CNN(75.44%/75.14%)与SVM(74.56%/74.18%);混淆矩阵(图12c)显示其几无类别混淆,不仅能判断污染物在内/外壁(A/B/C/D),还能同步正确识别管道壁厚(1–4子类),即一次测量完成"源项分布+管厚校准"双重任务。 尤其对于工程中常见的混合分布(B类:¹³⁷Cs内+⁶⁰Co外,C类反之),Transformer单独分类精度仍达96.00%,而SVM/CNN仅约64–70%,证明自注意力机制成功解耦了多源康普顿叠加引起的谱形纠缠。训练动态曲线(图11)亦显示Transformer收敛更快、验证损失更平滑、泛化间隙更小,整体稳定性最佳。
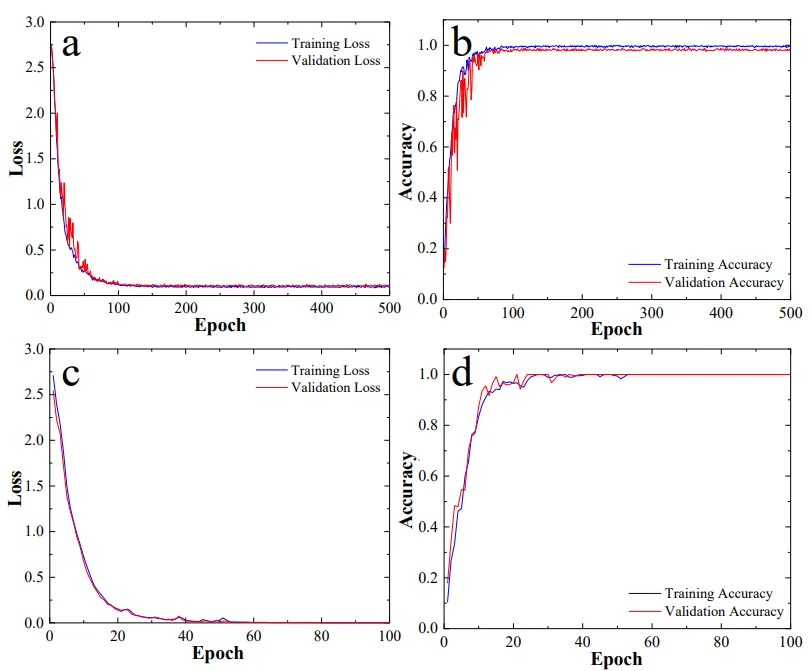
图11(a)CNN模型训练和验证损失曲线。(b)CNN模型训练和验证准确率曲线。(c)Transformer模型训练和验证损失曲线。(d)Transformer模型训练和验证准确率曲线。

此工作最大价值在于将"核物理先验(屏蔽衰减、康普顿散射改变谱形)"隐含于数据驱动模型中,用Transformer全局建模替代人工设计特征(如P/C、峰面积比),突破了传统单参数法在内外壁判别时分布严重重叠的瓶颈。方法不依赖昂贵成像阵列,仅需常规高分辨LaBr₃(Ce)谱仪+离线训练模型即可现场推断,工程落地门槛低。当然需指出局限:当前仅覆盖¹³⁷Cs/⁶⁰Co两种核素、特定管道规格与距探距离范围,复杂现场本底(天然γ、中子活化干扰)及非均匀沾污模式有待拓展;另外能谱反演扩增虽好,其保真度仍锚定于初始少量实测谱的代表性。未来若引入多核素、现场本底混入训练,并结合迁移学习适配不同管径材质,该方法有望成为核设施运行监督与退役前污染排查的标准辅助手段。
总体而言,这是一篇核辐射探测与机器学习交叉领域少见的"物理问题定义清晰—实验设计贴合工程—数据处理巧妙—模型对比系统—结论经得住细看"的好文章,Transformer在γ能谱多分类任务上的压倒性优势也给核电子学同行提了个醒:别低估谱形中蕴藏的高维信息,合适的AI架构能让老探测器焕发新生命力。
以上。

