 夜雨聆风
夜雨聆风引子:从"一个AI"到"一百个AI"的算力悬崖
2026年5月28日,雷神科技在北京发布了覆盖塔式、桌面迷你、移动三大形态的AI工作站全场景产品矩阵。这场发布会的一个细节,大多数人一晃就过去了,但它可能是整场发布会最重要的那句话:
"Agent时代,每个人可以拥有5个、10个甚至100个Agent。AI从文本预测迈向自主逻辑思考,算力需求结构与消耗模式随之发生根本性变化。"
这句话里藏着一个绝大多数人还没有意识到的算力危机。过去你的电脑只需要同时跑一个Word、一个浏览器、一个音乐播放器——现在,它要同时跑100个自主思考的AI智能体。这不是"性能提升30%"级别的问题,这是整个算力架构需要重新思考的问题。
背景:Agent时代到底改变了什么?
要理解为什么Agent时代对算力的需求是"断崖式"的,你需要先理解Agent和传统AI应用在计算模式上的根本差异。
差异一:从"请求-响应"到"持续思考"
传统AI应用(包括大语言模型的对话应用)是"请求-响应"模式:你发一条消息,模型生成一个回复,然后算力释放。一次交互的算力消耗是"脉冲式"的。
Agent是"持续思考"模式:它要持续监控环境变化(邮件、日历、文件系统、传感器数据),要持续规划下一步动作,要持续调用工具并等待返回结果。一个Agent的算力消耗模式是"常驻式"的——即使它表面上"什么都没做",它也在持续消耗算力来维持其"感知-规划-执行"的循环。
差异二:从"单线程推理"到"多智能体并行"
OpenClaw(龙虾)开源框架在2026年3月的更新中,引入了"Multi-Agent Orchestration"(多智能体编排)功能。这意味着,一个主Agent可以动态地启动多个子Agent并行工作——就像一家公司里,经理同时指派5个员工分别处理不同任务。
这种架构的算力含义是:一次用户请求,可能触发10~20个并发的模型推理任务。而这些推理任务不是"同样的计算重复10遍"——它们是不同的模型、不同的上下文窗口、不同的工具调用链。这意味着算力需求不是线性增长,而是阶梯式跳跃。
差异三:从"云端推理"到"端边云协同"
Agent时代的另一个算力特征是:推理不再全部发生在云端。隐私需求、延迟需求、离线可用性需求,共同推动了一部分Agent能力向"端侧"(你的电脑/手机/工作站)下沉。
联想在5月27日成都发布会上发布的"百应AI 3.0"Token体系,本质上就是在解决这个"端边云协同"的算力度量与调度问题。Token Plan让企业可以按"消耗"来购买AI能力,而不是按"算力规格"来采购——这是算力交付模式的一次重要转型。
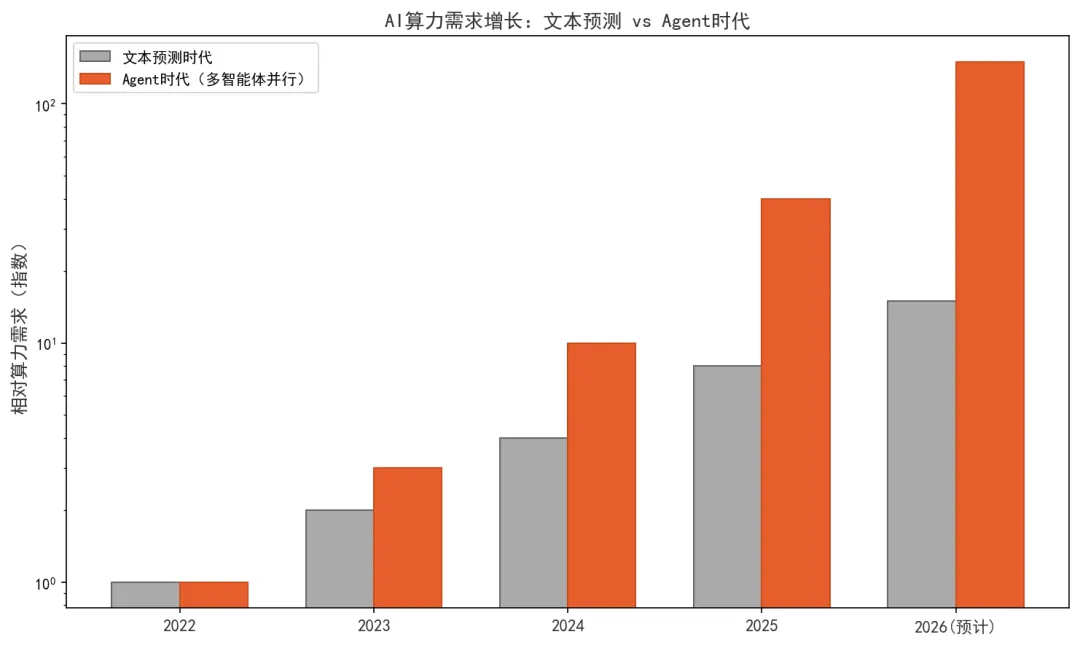
图4-1:AI算力需求增长——文本预测时代 vs Agent时代(数据来源:行业公开数据整理,2026年5月)
技术深度拆解:雷神×AMD AI工作站的"三大形态"意味着什么?
理解了Agent时代对算力的特殊需求之后,再来看雷神5月28日发布的"三大形态AI工作站全矩阵",就能读出比"又发布了一堆硬件"更深层的东西。
塔式工作站:多Agent并行算力的"主场"
塔式AI工作站的核心优势不是"峰值算力最高"——那是数据中心的活。它的核心优势是"持续多任务并行能力"。Agent时代的典型工作站负载是:同时运行本地知识库检索、3~5个专业化子Agent推理进程、本地向量数据库、代码编译/执行沙箱。这些负载加在一起,对内存带宽、PCIe通道数、多核调度效率的要求,远超过对"单核跑分"的要求。
雷神此次与AMD合作,在塔式工作站上搭载了AMD Ryzen AI MAX+系列处理器(集成NPU)以及可选的独立Radeon RX 7900 XTX AI Edition显卡。这套组合的特别之处在于:CPU、NPU、GPU三方协同来完成AI推理任务。过去这类协同需要模型框架层做大量手动优化,现在AMD的Ryzen AI软件栈已经可以自动完成"算子分配到最优执行单元"的决策。
迷你PC形态:把Agent"放在桌角"
这是三类形态里最值得玩味的一个。过去"迷你PC"和"AI工作站"是两个不交叉的品类——前者追求小巧安静,后者追求极致性能。但Agent时代改变了一个关键假设:你不一定需要一台"看起来很猛"的工作站,但你确实需要一台"一直在线"的AI助手主机。
雷神的AI迷你PC,体积约2.5升(差不多一盒抽纸的大小),但搭载了足够跑13B参数量级本地大模型的算力配置。它的目标使用场景是:24小时开机,常驻3~5个个人Agent,处理邮件分类、日程管理、本地知识库问答、代码辅助等持续型任务。
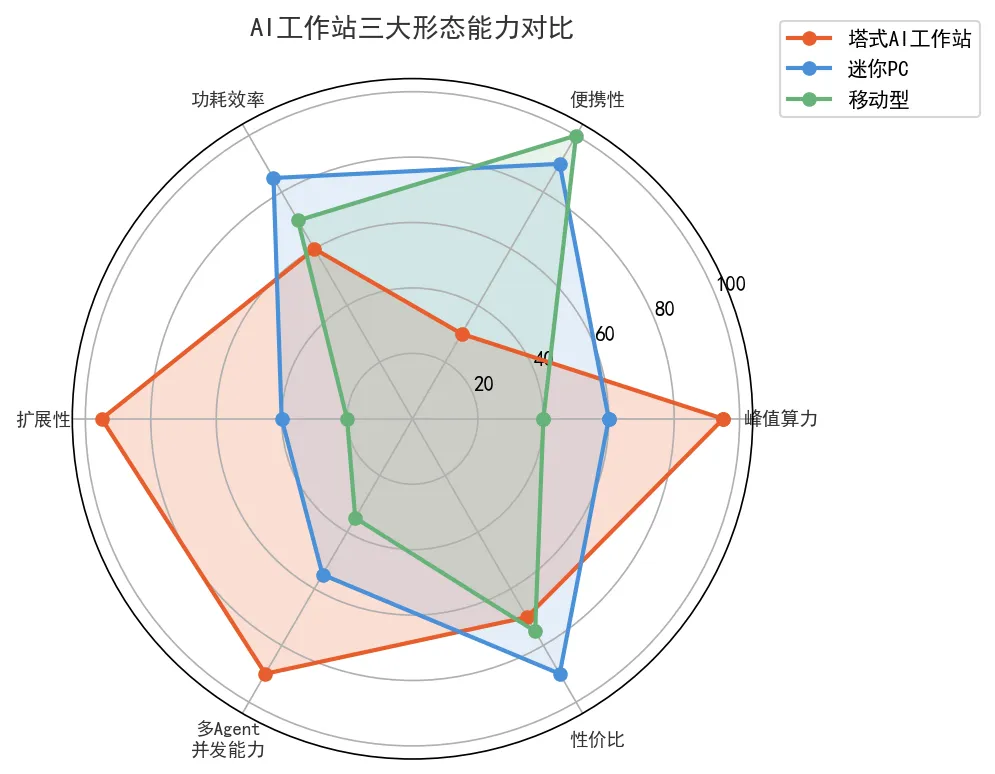
图4-3:AI工作站三大形态能力对比——塔式 vs 迷你PC vs 移动型(数据来源:雷神科技发布会公开资料,2026年5月28日)
移动型工作站:Agent的"移动化身"
移动型AI工作站看上去是"游戏本的另一个马甲"——从硬件规格上看,确实差不多。但它的软件栈是有本质差异的:移动AI工作站预装了"本地Agent运行环境"(包括模型运行时、向量数据库、Agent编排框架的本地版本)。这使得这台电脑在断网状态下,仍然可以运行一个"简化版的个人Agent助理"。
这个能力的意义,在商务出差场景中尤其明显:你在飞机上写的一份文档,落地后你的本地Agent已经帮你完成了"与历史文档的对比分析"、"待办事项的自动更新"和"相关联系人的智能提醒"——所有这些,不需要在飞行途中联网。
数据支撑:Token经济体系背后的算力账本
联想5月27日在成都发布的百应AI 3.0中,有一个核心产品叫"Token Key"(词元宝)。这个产品的设计逻辑,能够帮助我们理解Agent时代算力经济的底层账本。
数据点一:一个典型知识工作者的AI Token日消耗量,2026年Q1 vs 2025年Q1,增长了约8倍。这个数据来自联想百应平台的内部统计(在发布会材料中引用)。增长的核心驱动力不是"每次交互消耗更多Token"——而是"交互频次呈指数级上升"。当AI从"你主动问它"变成"它主动帮你盯着"之后,Token消耗的自然增长就是8倍这个量级。
数据点二:多Agent并行场景下,Token消耗的峰值是平均值的约15~20倍。这意味着,如果你的AI算力采购方案是基于"平均值"来设计的,那么在实际使用中有很高概率会遇到"Agent排队等待"的问题。雷神AI工作站的"三大形态"策略,本质上就是在提供"按需选择峰值算力"的灵活性——不是每个人都需要的塔式工作站的峰值算力,但每个人需要的峰值算力水平是不一样的。
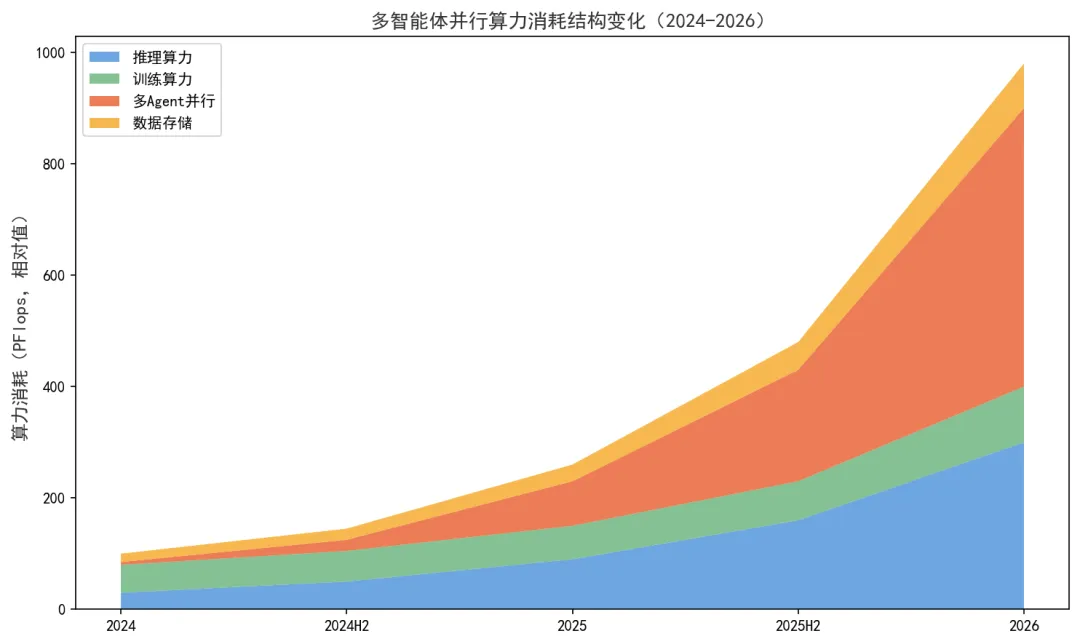
图4-2:多智能体并行算力消耗结构变化(2024-2026)(数据来源:行业分析报告及联想百应发布会材料,2026年5月)
数据点三:GPU+CPU协同的端到端算力组合,在多Agent场景下的能效比,比纯GPU方案高约35%~50%。这个数据的原理很好理解:Agent任务中,有大量"非推理"类的工作——文件读写、网络通信、任务调度、数据库查询——这些工作交给CPU来做,比交给GPU来做,能效高出一个数量级。雷神AI工作站的"GPU+CPU协同"设计,就是在这个认知基础上做的架构决策。
独家观点:Agent时代的算力叙事,正在从"快"转向"持续"
写到这里,我想提出一个可能在当前主流叙事中显得不太一样的判断:Agent时代对算力产业的最大冲击,不是"需要更大的算力",而是"算力的评价体系需要重写"。
过去40年,从PC时代到移动互联网时代到云计算时代,我们评价算力的核心指标一直是"峰值性能"——CPU主频是多少、GPU的TFLOPS是多少、手机SoC的安兔兔跑分是多少。这个评价体系在"请求-响应"模式下的应用里,是基本合理的。
但Agent时代的核心算力需求是"持续多任务并行能力"——这包含五个维度:(1)多核调度的公平性,(2)内存带宽的持续性,(3)功耗控制的稳定性(你的工作站不能因为跑了10个Agent就变成一个散热器),(4)端边云协同的流畅性,(5)Token经济下的算力计量精度。
这五个维度,在当前的算力评价体系里,要么是缺失的,要么是次要指标。雷神AI工作站的"三大形态"策略,某种程度上是在用产品定义来"倒逼"行业重新思考这个问题——不是先有了新指标再来设计产品,而是先做出了产品,让市场在使用中体会到"原来持续并行能力才是关键"。
展望:你的下一台电脑,会不会是"Agent主机"?
如果把时间轴拉长到2030年,回过头来看2026年5月28日这场发布会,它最可能被记住的定位是:这是"个人AI算力基础设施"这个产品品类第一次被认真定义。
过去我们的"个人计算设备"经历了四个阶段:(1)大型机时代(计算在远处,终端只是录入工具);(2)PC时代(计算在本地,但只有一台);(3)移动互联网时代(计算在口袋里,但算力受限);(4)云计算/AI助手时代(计算在云端,终端是窗口)。
Agent时代正在开启第五个阶段:"个人AI算力中心"时代。你的桌面(或桌角)有一台常驻设备,它24小时运行着你的多个个人Agent,它们知道你的邮件、你的日程、你的项目文件、你的健康数据——所有数据全程不出你的家(或你的办公室)。你需要的时候,可以从手机、从平板、从汽车、从AR眼镜随时接入这个"个人AI算力中心"。你的数据,不发给任何人;你的Agent,只听你的指令。
这个图景,不一定在2026年实现。但2026年5月28日雷神发布的这三款AI工作站,是这个图景第一次有了可购买、可部署的实体形态。从这个角度看,这场发布会的意义,可能比它在当天的传播声量要大得多。
数据来源备注:本文引用的雷神科技发布会信息来自光明网、36氪等媒体的公开报道(2026年5月28日);联想百应AI 3.0相关信息来自新浪财经对联想中小企业合作伙伴大会的报道(2026年5月27日)。
